目录
[3.1 项目的基本架构图](#3.1 项目的基本架构图)
[3.2 用户生命周期流程](#3.2 用户生命周期流程)
[4.1 登陆注册](#4.1 登陆注册)
[4.1.1 功能流程](#4.1.1 功能流程)
[4.1.2 核心代码实现](#4.1.2 核心代码实现)
[前端:Canvas 验证码与登录逻辑](#前端:Canvas 验证码与登录逻辑)
[后端:JWT 认证 (基于 django-rest-framework-jwt)](#后端:JWT 认证 (基于 django-rest-framework-jwt))
[4.2.1 功能流程](#4.2.1 功能流程)
[4.2.2 核心代码实现](#4.2.2 核心代码实现)
[前端:ECharts 集成与数据聚合](#前端:ECharts 集成与数据聚合)
[4.3.1 功能流程](#4.3.1 功能流程)
[4.3.2 核心代码实现](#4.3.2 核心代码实现)
[4.4.1 功能流程](#4.4.1 功能流程)
[4.4.2 核心代码实现](#4.4.2 核心代码实现)
[4.5.1 功能流程](#4.5.1 功能流程)
[4.5.2 核心代码实现](#4.5.2 核心代码实现)
[后端:调用 Dify 文本生成](#后端:调用 Dify 文本生成)
一.背景和项目介绍
在数字化教育飞速发展的今天,个性化学习与智能化辅导已成为教育技术的重要趋势。传统的在线考试系统往往缺乏互动性,且对主观题的批改依赖人工,效率较低;同时,学生在面对海量的错题时,缺乏有效的整理与针对性分析工具。此外,高考/考研志愿填报对于许多学生而言是一个信息不对称的难题,急需智能化的数据分析支持。
基于上述痛点,本项目旨在构建一个集智能对话考试 、自动化错题管理 、个性化志愿分析于一体的综合性教育辅助平台。通过引入大语言模型(LLM)能力,实现像真人导师一样的交互式辅导体验,帮助学生提高学习效率,科学规划升学路径。
本项目名为"智能教育辅助平台",是一个基于 Django 5 + Vue 3 前后端分离架构的全栈应用,深度集成了 Dify AI 工作流,为用户提供智能化的学习服务。
核心功能模块
-
在线考试中心 (Exam Center):
- 智能出题与批改:支持上传试卷文档(PDF/TXT),利用 AI 对话能力进行实时出题或整卷测验。
- 流式交互体验:采用 SSE (Server-Sent Events) 技术,实现类似 ChatGPT 的打字机式流畅对话。
- 自动归档:考试结束后,系统自动解析 AI 返回的结构化数据,记录总分、科目及详细的答题情况。
-
智能错题本 (Smart Mistake Book):
- 自动收集:无需手动录入,系统自动从考试记录中筛选错题并归档。
- 详细解析:每道错题均包含用户错解、正确答案及 AI 生成的评分要点。
- 薄弱点追踪:记录错题次数,帮助用户识别知识盲区。
-
院校志愿分析 (School Report):
- AI 咨询顾问:基于用户的专业、分数及目标地区,生成个性化的录取概率分析报告。
- 复习建议:提供针对性的备考策略与复习方向。
-
用户个人中心 (User Profile):
- 全方位画像:管理用户的基本信息、专业背景、目标院校等,为 AI 分析提供数据支撑。
- 数据可视化:展示近期成绩走势与学习进度。
技术亮点
- 双轨数据处理机制:后端创新性地实现了 AI 响应的"展示-存储"分离,前端展示清洗后的纯净文本,后台保留完整的 JSON 数据用于业务逻辑处理。
- 低代码 AI 编排:通过 Dify 平台编排复杂的 Prompt 工作流,降低了 LLM 应用的开发门槛,同时保证了输出内容的结构化与稳定性。
- 现代化技术栈:使用 Django 5 的异步特性与 Vue 3 的组合式 API,构建了高性能、易维护的系统架构。
二.项目准备
2.1前端准备
npm create vue@latest frontend 创建项目工程
cd 进入当前项目工程目录之后输入指令 npm i 安装项目所需要的包
2.2后端准备
pip install Django 安装django包后输入命令指令:
-
django-admin startproject 项⽬名称 -- 创建项目主应用
-
startapp 子应用名称 -- 创建子应用
2.3dify本地部署
Github 开源地址: https://github.com/nashsu/FreeAskInternet
点击Tags后选择版本下载zip在本地
命令提示符:
python
cd dify
cd docker
cp .env.example .env
docker compose up -d若安装时出现问题,可能是镜像的问题,可以搜索dify本地部署观看具体安装教程。
2.4知识库准备
下载影刀RPA进行数据的爬取,存入知识库来进行精确的查询与分析
本项目中主要是爬取各学校的各专业的近几年考研分数线
2.5数据库配置
后端django中的setting.py文件中的DATABASE连接本地的mysql数据库,并且创建子应用,在子应用中的model.py文件中设计数据库字段。最后使用指令 "makemigrations 子应用名称 " 创建迁移文件后使用指令"migrate 子应用名称"成功迁移
三.项目流程
3.1 项目的基本架构图
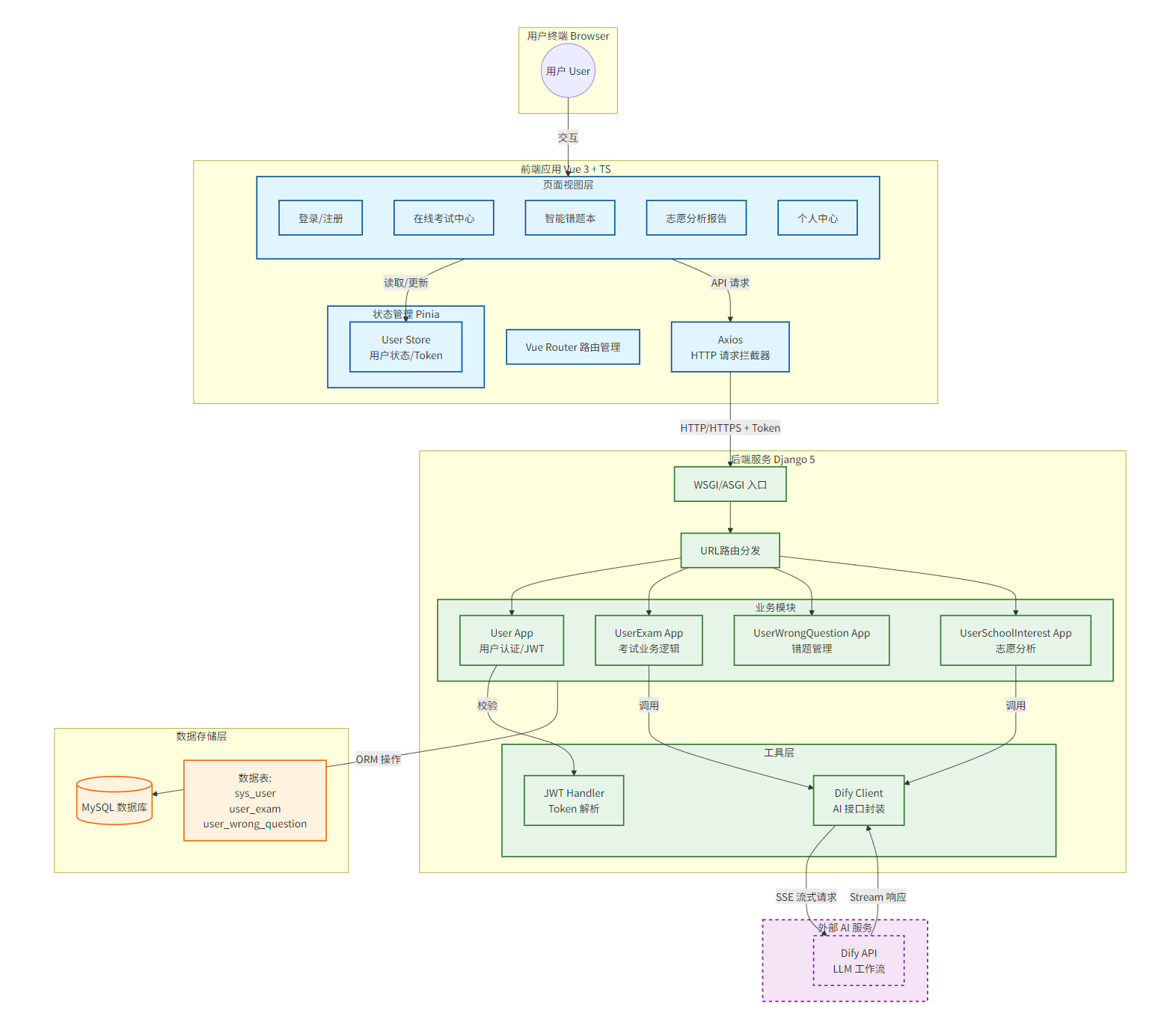
本项目围绕用户的学习闭环展开,从入学评估(注册/画像) 到学习检测(考试) ,再到问题反馈(错题本) ,最后进行升学规划(志愿分析)。
3.2 用户生命周期流程
-
用户注册与画像构建:
-
用户注册账号,完善个人信息(专业、目标院校)。
-
系统建立初始用户画像,为后续 AI 个性化服务提供上下文。
-
-
在线模拟考试:
-
用户进入考试中心,上传试卷或直接开始对话。
-
系统调用 AI 进行出题或批改。
-
用户获得即时反馈与分数。
-
-
错题自动归集:
-
系统自动识别考试中的错题。
-
生成详细解析并存入错题本。
-
-
针对性复习:用户查看错题本,进行针对性训练。
-
升学志愿规划:基于累积的考试成绩与专业和地区选择,AI 生成录取概率分析报告与复习建议。
3.3具体功能流程图
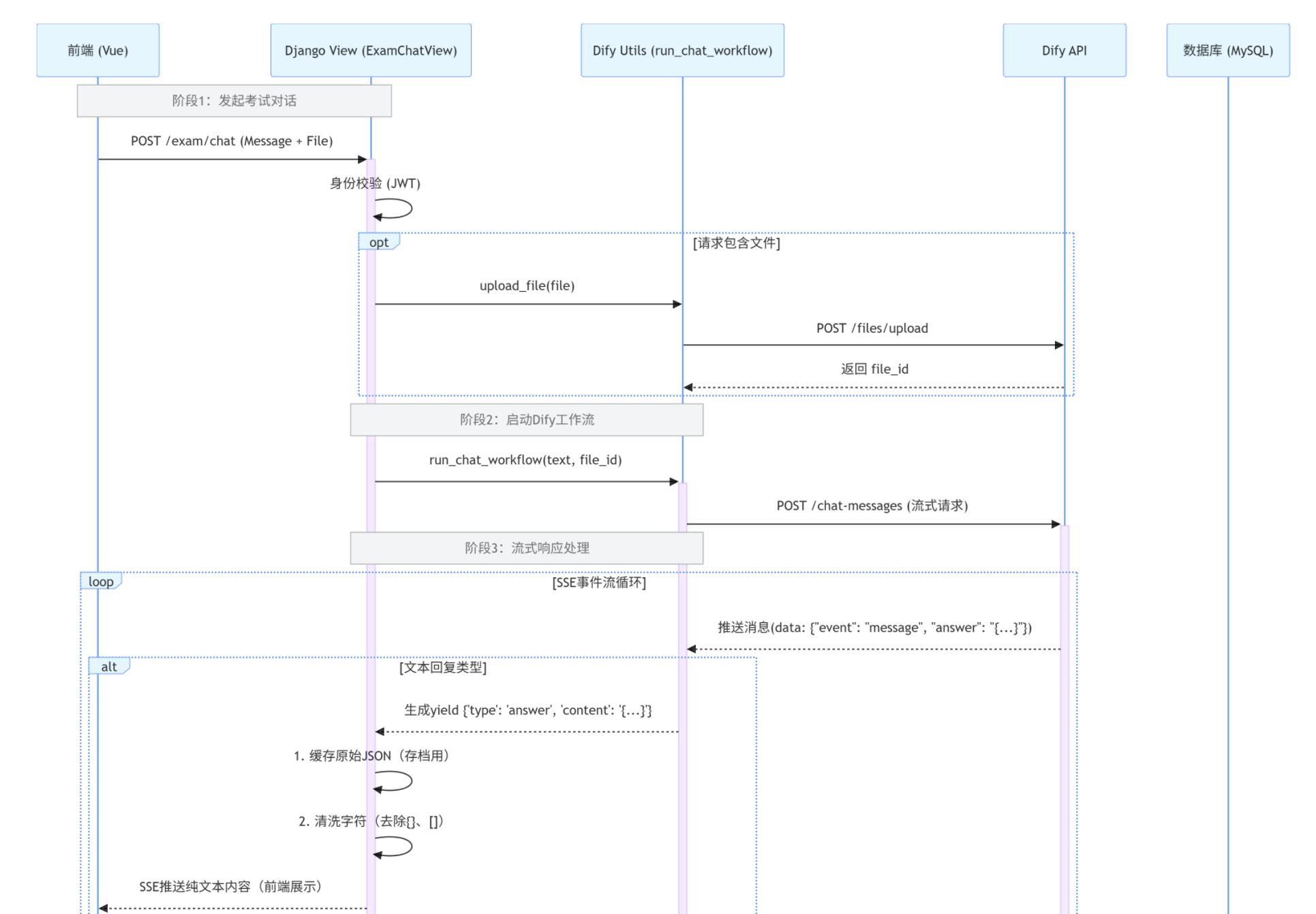
针对具体的功能步骤分析:
阶段1:用户进入模考中心模块,在输入框进行输入,传送出去的信息会传入后端dify接口,并且识别传送的数据是纯文本还是附带文件。然后进行JWT身份校验验证token,验证成功就能使用。
阶段2:dify工作流启动开始运行,携带两个参数:文本和文件,并且对接流式输出接口,信息流式返回到前端显示
阶段3:流式输出接口接收到数据,yiled返回出去到前端,并且提炼出dify返回中的数据中需要的内容,缓存原始JSON并使用SSE流式输出
四、具体模块实现
4.1 登陆注册
4.1.1 功能流程
-
用户进入 :访问
/login或/register页面。 -
验证码生成:前端本地通过 Canvas 绘制算术验证码(如 "12 + 5 = ?"),减少对后端的非必要请求。
-
信息提交:用户输入账号、密码及验证码,点击提交。
-
后端验证:Django 接收请求,校验账号密码(使用 JWT)。
-
状态持久化 :验证通过后,前端接收 JWT Token 并存储于
localStorage或sessionStorage,同时利用 Pinia 更新全局用户状态。 -
路由跳转:成功登录后跳转至首页;若 Token 失效则被路由守卫拦截回登录页。
4.1.2 核心代码实现
前端:Canvas 验证码与登录逻辑
TypeScript
// 1. 生成算术验证码
const generateCaptcha = () => {
const num1 = Math.floor(Math.random() * 10)
const num2 = Math.floor(Math.random() * 10)
// ... 随机选择运算符 ...
captchaCode.value = result.toString() // 保存正确结果用于比对
drawCaptcha(expression) // 绘制到 Canvas
}
// 2. 登录处理
const handleLogin = async () => {
// 本地校验验证码
if (captchaInput.value !== captchaCode.value) {
errors.value.captcha = '验证码错误'
return
}
// 发送请求
const response = await post('/user/login/', { ... })
if (response.data.code === 200) {
const token = response.data.data.token
// 存储 Token
localStorage.setItem('token', token)
// 更新 Pinia 状态
userStore.login(response.data.data)
router.push('/')
}
}后端:JWT 认证 (基于 django-rest-framework-jwt)
后端主要依赖 DRF 的 JWT 插件进行 Token 签发与验证,在 views.py 中通过装饰器或中间件保护需要登录的接口,添加登陆与注册路由到白名单。
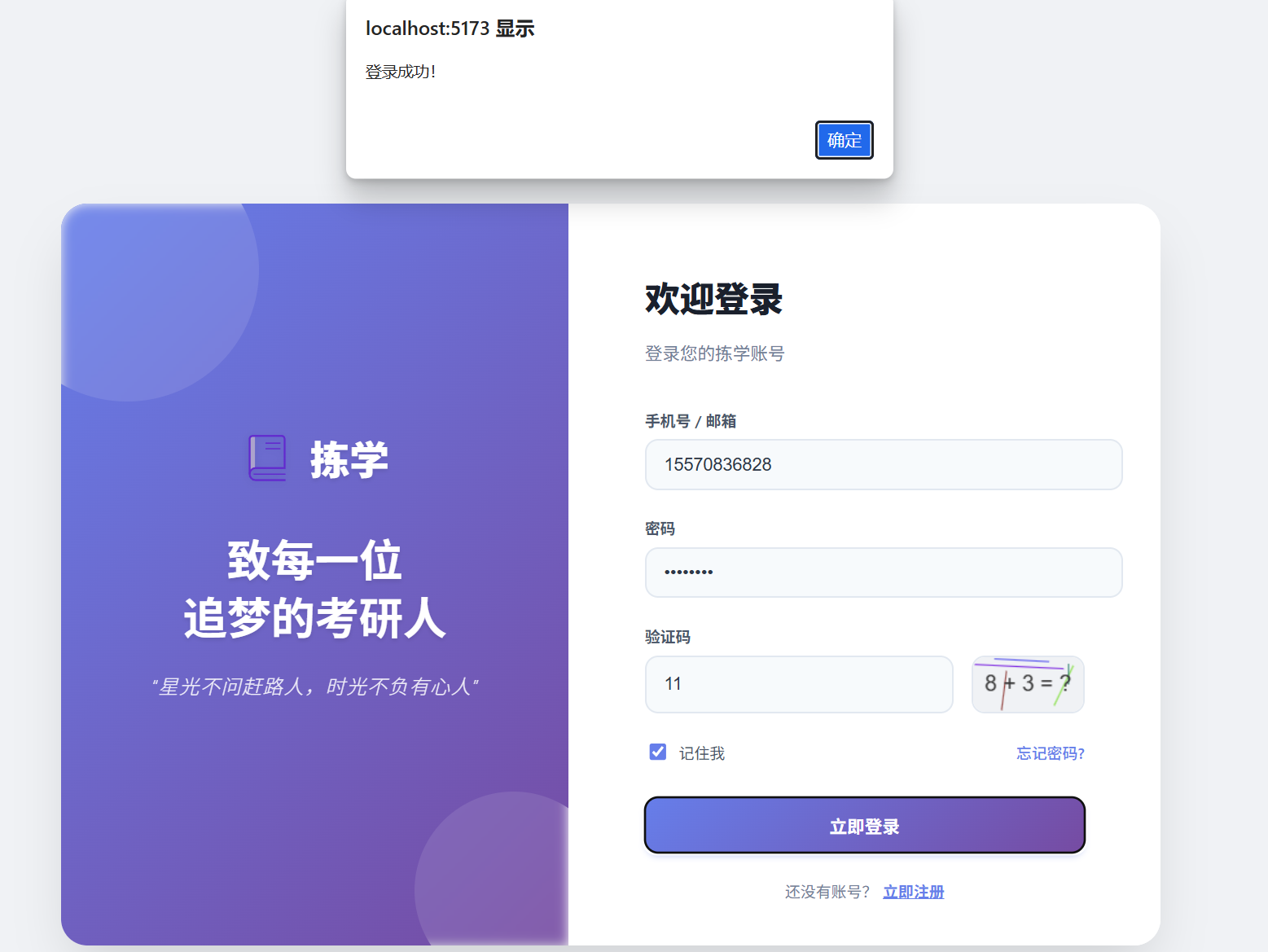
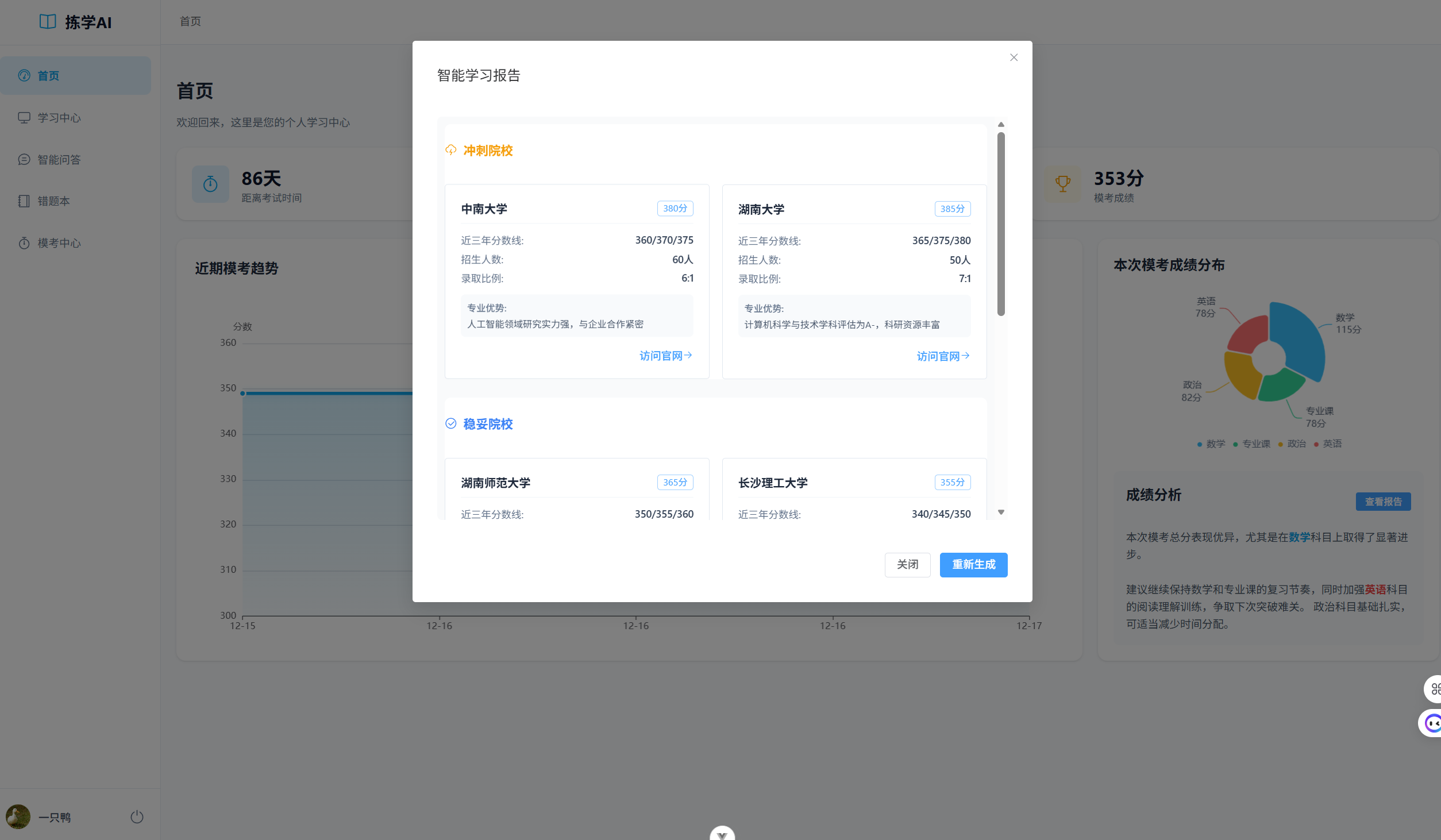
4.2首页仪表盘
4.2.1 功能流程
-
数据加载 :页面挂载 (
onMounted) 时,并发请求多个 API 获取数据:-
/exam/trends/:获取近期模考分数趋势。 -
/exam/latest-score/:获取最新一次专业课成绩。 -
mistakeStore.fetchMistakes():获取错题数量。
-
-
图表渲染:使用 ECharts 渲染折线图(模考趋势)和南丁格尔玫瑰图(学科分布)。
-
智能分析:根据当前分数,前端通过简单的规则逻辑生成一段"成绩分析"文案。
4.2.2 核心代码实现
前端:ECharts 集成与数据聚合
TypeScript
// 并发获取数据
onMounted(() => {
fetchExamTrends() // 获取折线图数据
initPieChart() // 初始化饼图
fetchLatestScore() // 更新饼图中"专业课"的分数
mistakeStore.fetchMistakes() // 更新错题数
})
// ECharts 配置示例 (折线图)
const initChart = (data) => {
const option = {
xAxis: { data: data.dates },
series: [{
type: 'line',
data: data.scores,
areaStyle: { ... } // 渐变填充效果
}]
}
chartInstance.setOption(option)
}后端:数据聚合接口
python
class ExamTrendsView(View):
def get(self, request):
# 获取当前用户最近5次考试
recent_exams = UserExam.objects.filter(user_id=user_id).order_by('-create_time')[:5]
# 翻转为时间正序用于图表展示
recent_exams = reversed(recent_exams)
# 构造 ECharts 所需的数组
dates = [exam.create_time.strftime('%m-%d') for exam in recent_exams]
scores = [exam.score + 275 for exam in recent_exams] # 示例分数修正
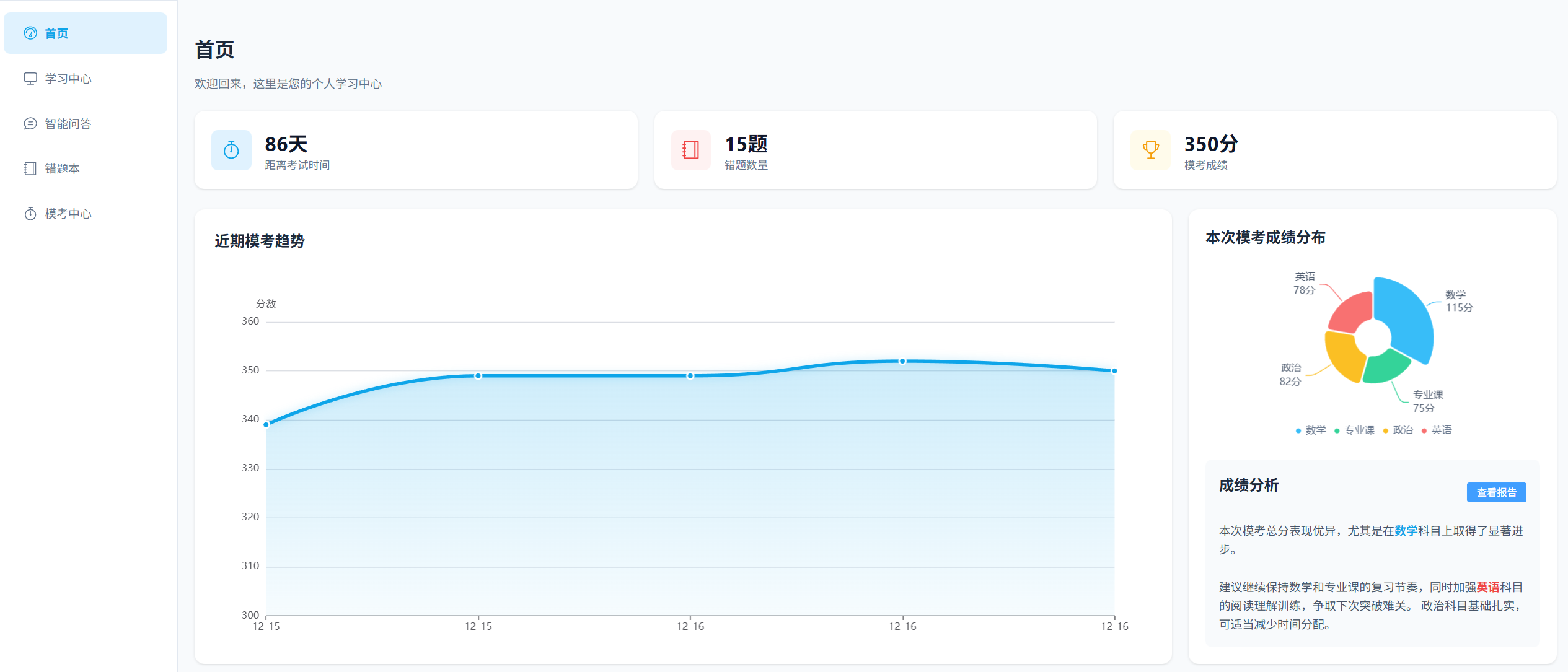
return JsonResponse({"data": {"dates": dates, "scores": scores}})4.3模考中心
4.3.1 功能流程
-
文件上传/输入:用户上传试卷(PDF/Word)或直接输入题目文本。
-
流式交互:
-
前端将文件/文本发送至后端
/exam/chat/。 -
后端调用 Dify API 处理文件并进行对话。
-
Dify 返回流式数据 (SSE)。
-
-
双轨数据处理:
-
前端流 :后端将 Dify 的响应实时转发给前端,前端实时清洗 JSON 符号(
{,}),只展示纯文本给用户。 -
后端流:后端同时累积完整的 JSON 数据。
-
-
自动归档 :对话结束时,后端解析累积的 JSON,提取"总分"存入
UserExam表,提取"错题"存入UserWrongQuestion表。
4.3.2 核心代码实现
后端:双轨处理与自动入库
python
def process_and_save(self, generator, user, exam_name):
full_response = ""
for item in generator:
# item 是从 Dify 拿到的数据片段
if isinstance(item, dict) and item.get('type') == 'answer':
content = item.get('content', '')
full_response += content # 1. 后端留底:累积完整 JSON
# 2. 前端展示:清洗掉 JSON 格式符号,只给用户看内容
clean_content = content.replace('{', '').replace('}', '').replace('"', '')
yield clean_content
# 流结束后,解析 full_response 进行入库
try:
data = json.loads(extract_json(full_response))
# 保存考试记录
UserExam.objects.create(user=user, score=data['总分'], ...)
# 保存错题
for q in data['result']:
if not q['是否正确']:
UserWrongQuestion.objects.create(...)
except:
pass前端:流式接收
TypeScript
const sendMessage = async () => {
const response = await fetch('/exam/chat/', { ... })
const reader = response.body.getReader()
while (true) {
const { done, value } = await reader.read()
if (done) break
// 实时将清洗后的文本追加到对话框
assistantMessage.content += new TextDecoder().decode(value)
}
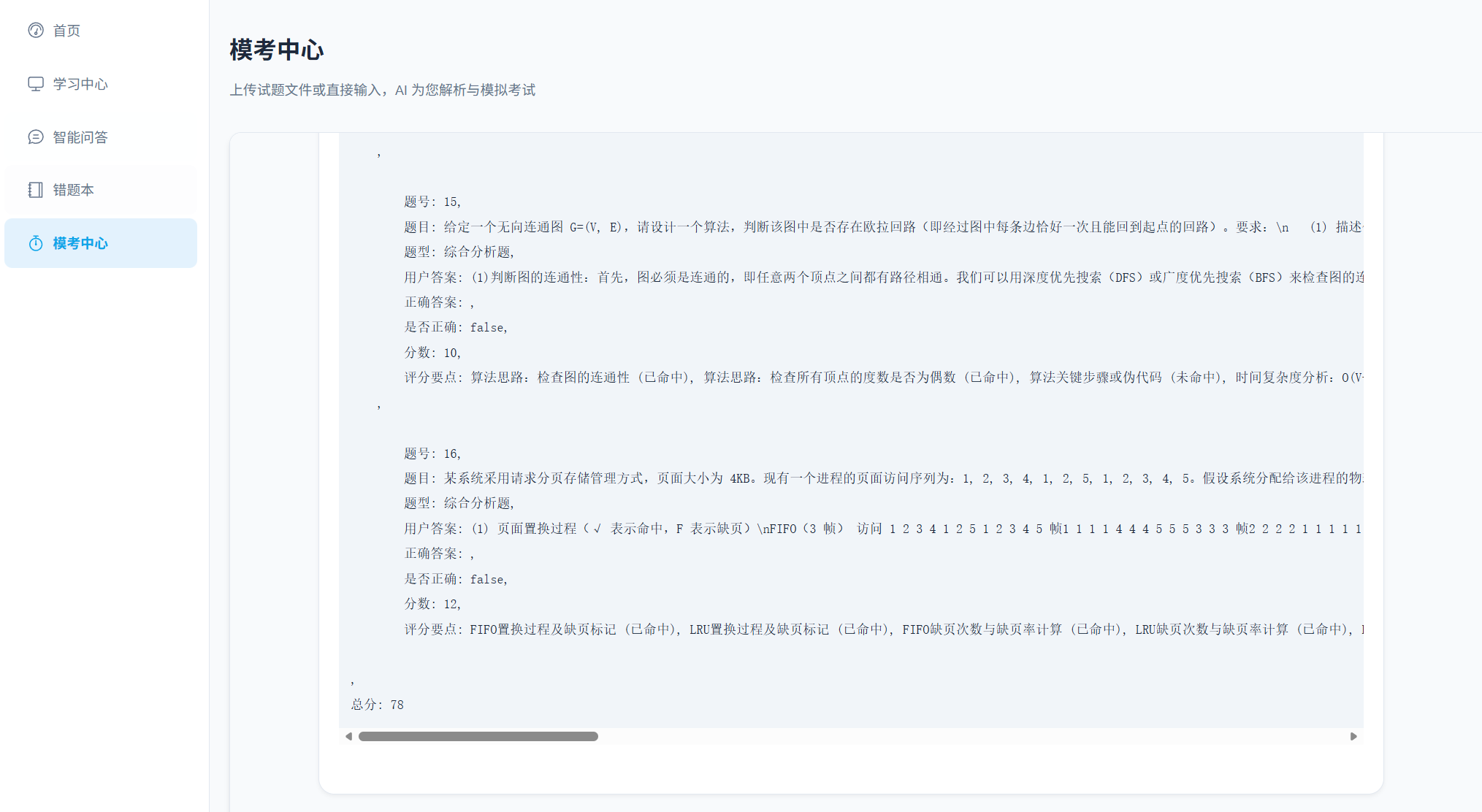
}4.4错题本
4.4.1 功能流程
-
数据来源 :如上所述,完全由模考中心自动触发存入,用户无需手动录入。
-
列表展示 :
MistakeBookView从 Pinia Store (mistake.ts) 获取错题列表。 -
筛选与搜索:支持按"题型"(选择/简答)和"关键字"过滤。
-
详情查看:点击卡片,弹窗展示"您的答案"与"正确答案"的对比。
-
去重机制 :后端在保存错题时使用
update_or_create,如果同一题再次做错,只增加"错误次数"并更新最新错误答案,避免重复记录。
4.4.2 核心代码实现
后端:去重逻辑
python
# 检查该用户是否已存在该错题
existing_wrong = UserWrongQuestion.objects.filter(
user=user,
question_text=question_text
).first()
if existing_wrong:
# 存在则更新:错误次数 +1,更新最新错误答案
existing_wrong.error_count += 1
existing_wrong.user_answer = new_wrong_answer
existing_wrong.save()
else:
# 不存在则创建
UserWrongQuestion.objects.create(...)4.5择校报告
4.5.1 功能流程
-
参数收集:从用户画像中获取"专业"、"模考总分",用户补充"目标地区"。
-
Prompt 构建 :后端将这些参数拼接成一段 Prompt:
"专业:计算机,分数:350,目标:北京。请分析..."。 -
AI 生成:调用 Dify 的文本生成型应用。
-
结果展示:前端接收流式文本,支持 Markdown 渲染或结构化卡片展示(如果 AI 返回 JSON)。
4.5.2 核心代码实现
后端:调用 Dify 文本生成
python
# 构造 Prompt
message = f"请根据以下学生情况生成一份分析报告:\n专业:{major}\n模考总分:{score}\n目标地区:{target_place}..."
# 调用 Dify 并流式返回
return StreamingHttpResponse(
run_dify_workflow(message),
content_type='text/event-stream'
)前端:展示逻辑
TypeScript
// 简单的流式读取与 Markdown 渲染
const generateReport = async () => {
// ... fetch ...
while (true) {
const { done, value } = await reader.read()
reportResult.value += decoder.decode(value)
}
}
// 使用 computed 属性实时渲染 Markdown
const renderedReport = computed(() => md.render(reportResult.value))五、项目演示
注册页面:
登陆页面:
首页:
模考中心页面:
错题本页面:
择校报告:
六、总结与收获
技术整合经验
通过本项目,深刻理解了 Django + Vue3 全栈开发的配合模式,特别是如何处理 JWT 认证 、跨域资源共享 (CORS) 以及 SSE 流式传输。成功打通了业务系统与 AI 大模型(Dify)的连接,探索了 LLM 在垂直领域(教育)落地的可行路径。
全栈开发心得
-
数据驱动设计:在开发错题本时,先设计好数据库模型(Model),再反推前端展示需求,能够有效避免逻辑漏洞。
-
用户体验优先:为了解决 AI 响应慢的问题,采用了流式输出(Streaming),极大缓解了用户的等待焦虑,这是提升 AI 应用体验的关键一环。
-
模块化思维:将 Dify 调用封装为独立的 Utils 工具类,使得代码复用性极高,后续扩展新的 AI 功能非常便捷。