
Fun-ASR 是一个由通义实验室推出的开源语音识别大模型,能把语音快速准确地转成文字,支持多语言、多方言,还能在嘈杂环境下保持高识别率,适合教育、金融、会议等场景
Fun-ASR 基于庞大的训练数据量(数千万小时的真实语音),因此它不仅能听懂,还能理解上下文,避免"幻觉"式错误。它的目标是做到"听得清、懂得准、写得对"。一段嘈杂环境下的会议录音,AI 也能毫秒级输出文字,绕口令、RAP、背景音乐干扰,照样精准识别!
作为通义百聆推出的端到端语音识别大模型,Fun-ASR 基于数千万小时真实语音数据训练,已在钉钉"AI听记"、视频会议等场景中大规模落地。本次,我们对 Fun-ASR 的核心能力进行了全面升级,重点优化了嘈杂环境鲁棒性、多语言自由混说、中文方言与口音覆盖、歌词识别、定制化能力,并将流式识别模型的首字降低到 160ms。
在远场拾音或高噪声环境(如会议室、地铁、车载)中,Fun-ASR 的识别准确率可达到 93%。新增对歌曲与说唱的识别能力,优化音乐背景噪声干扰下的语音识别能力,提高模型的抗噪能力。
Fun-ASR 全面支持 31 种语言的自由混说,无需预先指定语种,系统可自动切换识别,重点优化了日语、越南语等东亚与东南亚语种,并能准确处理语种混说类句子。在中文方面,模型覆盖 7 大方言(粤语、吴语、闽南语、客家话、赣语、湘语、晋语)与 26 种地方口音,从东北话到港台腔,从四川话到河南腔,都能精准识别。
下载地址:点此下载
核心特点
高精度识别:在远距离拾音或嘈杂环境(会议室、车内、工厂)仍能保持约 93% 的准确率。
多方言支持:覆盖 7 大方言(如吴语、粤语、闽南语、客家话等)和 26 种地方口音。
多语言能力:支持 31 种语言,尤其优化了东南亚语言,还能自由切换和混合识别。
行业定制:在教育、金融等专业领域能准确识别术语和行业表达。
音乐背景识别:即使在有音乐干扰的情况下,也能识别歌词内容。
功能丰富:除了语音识别,还提供语音活动检测(VAD)、标点恢复、说话人验证、分离和多说话人识别等功能。
应用领域
教育场景:课堂录音转写、在线课程字幕生成。
金融行业:电话客服、会议纪要,准确识别专业术语。
会议与办公:实时会议转写,支持多人发言分离。
媒体娱乐:歌词识别、视频字幕生成。
多语言交流:跨国会议、跨境电商客服,支持多语言混合识别。
使用教程: (建议N卡,显存4G起,支持CPU生成,支持50系显卡)
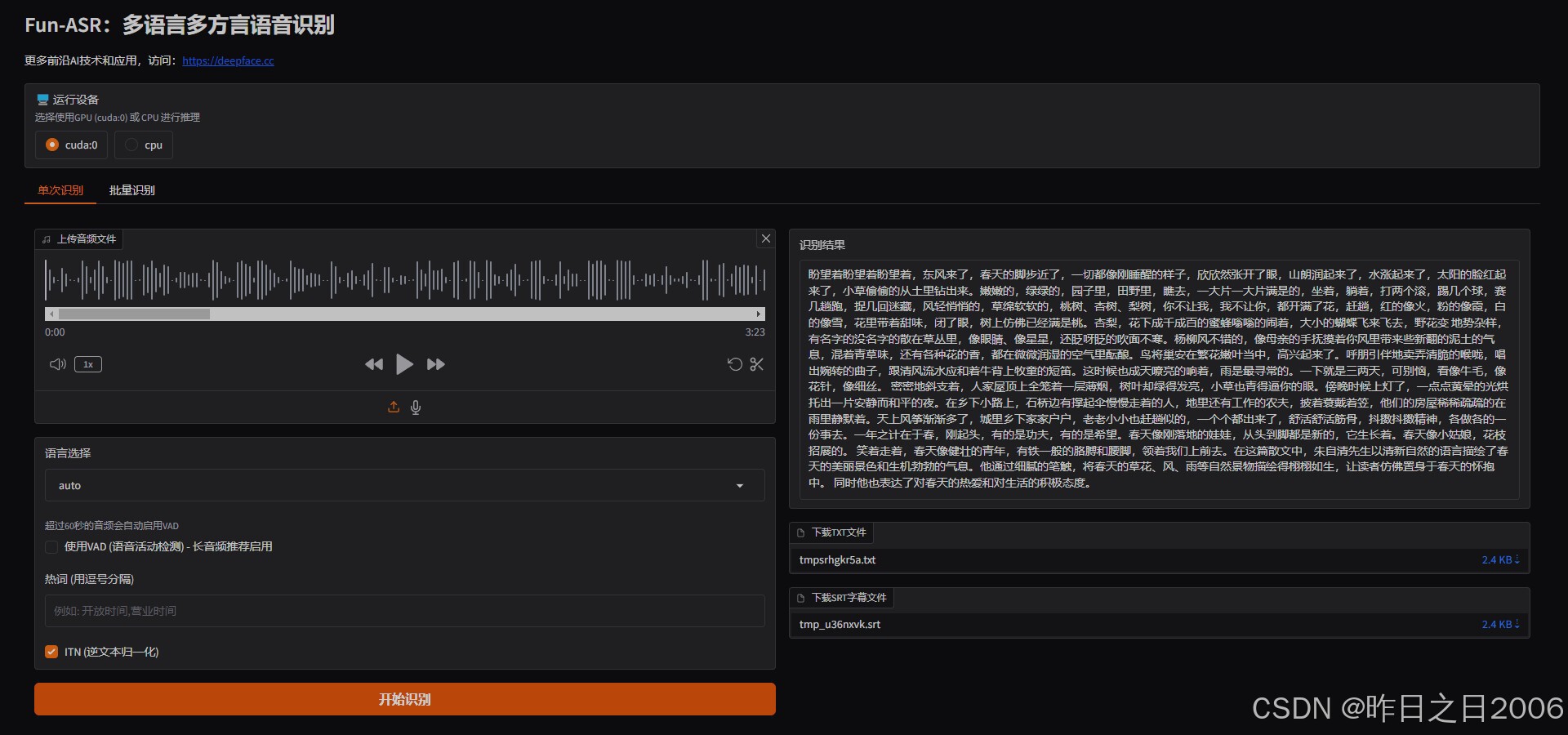
上传需要识别的音频文件,识别即可。支持批量,一次上传多个音频文件,批量识别。
支持导出txt和srt字幕文件,当前字幕文件为预留功能,等待官方模型支持返回时间戳,再完善srt字幕更精准的时间戳支持。
支持独显(CUDA)和无显卡(CPU)两种模式,如有条件,建议使用独显模式,识别速度更快,CPU识别略慢。
支持热词,这意味着金融、医疗、教育等领域的专业术语、品牌名、人名,均可被高召回、高精度识别,满足工业级落地要求。