【医学影像 AI】FunBench:评估多模态大语言模型的眼底影像解读能力
-
- [0. 论文简介](#0. 论文简介)
-
- [0.1 基本信息](#0.1 基本信息)
- [0.2 论文速览](#0.2 论文速览)
- [0.3 摘要](#0.3 摘要)
- [1. 引言](#1. 引言)
- [2. FunBench 的构建](#2. FunBench 的构建)
-
- [2.1 数据集构建](#2.1 数据集构建)
- [2.2 2.2 针对性评估模式](#2.2 2.2 针对性评估模式)
- [3. 基于FunBench的多模态大语言模型评估](#3. 基于FunBench的多模态大语言模型评估)
-
- [3.1 模型选择](#3.1 模型选择)
- [3.2 实验结果](#3.2 实验结果)
- [4. 结论](#4. 结论)
- [7. FunBench项目介绍:](#7. FunBench项目介绍:)
- [8. 参考文献](#8. 参考文献)
0. 论文简介
0.1 基本信息
2025 年 Qijie Wei 等在 MICCAI 2025 发表论文 "FunBench: Benchmarking Fundus Reading Skills of MLLMs(FunBench:评估多模态大语言模型的眼底影像解读能力)"。
本文提出 FunBench 这一新型视觉问答基准,专为评估多模态大型语言模型(MLLMs)的眼底图像解读能力而设计,其核心特点是四级分层任务架构(模态感知、解剖结构感知、病变分析、疾病诊断)和三种针对性评估模式(基于线性探针的视觉编码器评估、知识提示的语言模型评估、整体评估),数据集涵盖 16,348 张眼底图像和 91,810 个视觉问题;通过对 9 个开源 MLLMs 及 GPT-4o 的测试发现,现有模型眼底解读能力存在显著不足,尤其在偏侧识别等基础任务上表现不佳,且模型性能更依赖语言模型(LLM)而非视觉编码器(VE),领域特定训练和模块优化对提升性能至关重要。
论文标题: FunBench: Benchmarking Fundus Reading Skills of MLLMs
论文下载: miccai, arxiv
项目地址 :Github-FunBench
引用格式: Q. Wei, K. Qian, and X. Li, "FunBench: Benchmarking Fundus Reading Skills of MLLMs," in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. (MICCAI), 2025.

0.2 论文速览
研究背景
本文旨在评估多模态大型语言模型(MLLMs)在解读眼底图像方面的眼底阅读技能,这对于眼科学至关重要。
本研究的动机在于填补眼科学相关基准的空白,促进领域特定训练的改进,并推动更强大的MLLMs在医学图像分析中的发展。
FunBench构建
一种新基准,旨在通过结构化的方法评估多模态大型语言模型(MLLMs)的眼底阅读技能。
-
分层任务组织
根据眼底阅读技能的复杂性将任务组织为四个层级:
- 层级1 (L1):模态感知(识别成像技术)。
- 层级2 (L2):解剖感知(识别解剖结构和侧别)。
- 层级3 (L3):病变分析(识别和定位病变)。
- 层级4 (L4):疾病诊断(根据病变和解剖结构做出综合判断)。
-
针对性评估模式
三种不同的评估模式用于评估MLLMs:
- E模式 I:基于线性探针的视觉编码器(VE)评估
评估视觉编码器在使用线性探针技术从眼底图像中提取视觉特征的有效性。 - E模式 II:知识提示的大型语言模型(LLM)评估
将任务特定标签转换为间接描述,使用专家知识数据库,然后将这些描述与问题一起提交给LLM。 - E模式 III:整体评估
通过向模型提交多模态问题进行端到端评估,并将模型的答案与真实值进行比较以获得二元输出。
- E模式 I:基于线性探针的视觉编码器(VE)评估
-
数据集策划
利用14个公共数据集创建一套全面的视觉问题和答案(VQA)以供基准使用。

0.3 摘要
多模态大型语言模型(MLLMs)在医学图像分析中展现出显著的潜力。然而,它们在解读眼底图像方面的能力,这对于眼科学至关重要,仍然未得到充分评估。现有基准缺乏细致的任务划分,未能对其两个关键模块,即大型语言模型(LLM)和视觉编码器(VE)进行模块化分析。
本文提出 FunBench,一个新颖的视觉问答(VQA)基准,旨在全面评估MLLMs的眼底阅读能力。FunBench在四个层次上具有分层任务组织(模态感知、解剖感知、病变分析和疾病诊断)。它还提供三种针对性的评估模式:基于线性探测的VE评估、知识提示的LLM评估和整体评估。
通过对九个开源模型及GPT-4o的实验发现,现有模型在眼底阅片能力上存在显著缺陷,尤其在左右眼识别等基础任务中表现欠佳。实验结果揭示了当前多模态大语言模型的局限性,并强调亟需开展领域针对性训练,同时提升大语言模型与视觉编码器的专业能力。
1. 引言
多模态大语言模型凭借其在通用视觉内容理解方面的强大能力,正深刻变革着医学图像分析领域,并由此重塑了基于医学影像的疾病诊断研究范式。以人工智能赋能眼科学为例,远程多模态大语言模型与本地部署的非侵入式眼底成像设备(如彩色眼底照相)相结合,使得在社区诊所实现高质量的初级糖尿病眼病照护成为可能。尽管针对医学领域的多模态大语言模型研究正快速增长,但我们注意到眼科专用基准测试的开发仍相对滞后。
为此,本文提出FunBench------一个用于评估开源多模态大语言模型在不同难度眼底阅片任务中效能的全新基准测试体系,其框架如图1所示。
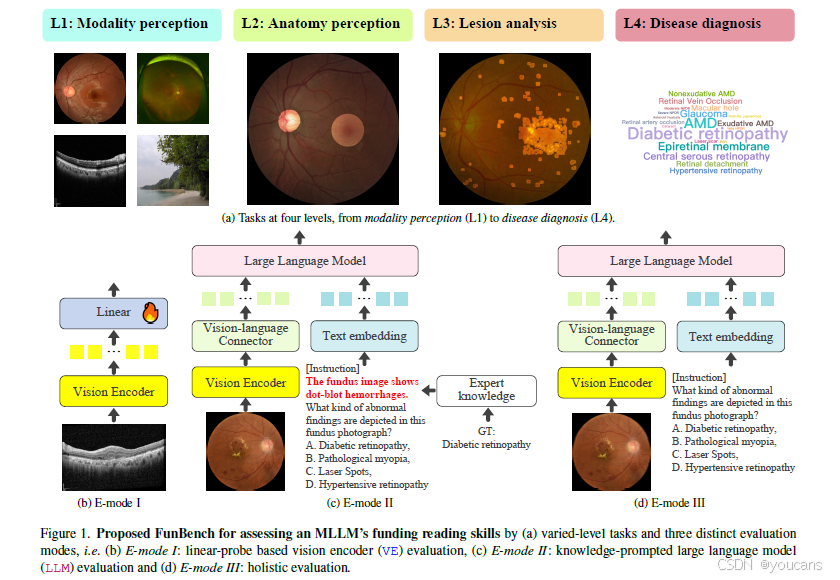
图 1:提出的FunBench,通过(a) 多级任务和三种不同的评估模式来评估MLLM的资助阅读能力,即(b) E模式I:基于线性探针的视觉编码器(VE)评估,© E模式II:知识提示的大语言模型(LLM)评估,以及(d) E模式III:整体评估。
尽管现有医学基准测试(如OmniMedVQA与GMAI-MMBench)已包含视网膜图像任务,但它们仅将基于视网膜图像的视觉问答视为单一任务。这些通用基准测试自然无法对特定模型解读视网膜图像的能力进行细致化、结构化的评估。为填补这一空白,LMOD应运而生,其可评估多模态大语言模型在识别眼底主要解剖结构(如视杯、视盘、黄斑)以及诊断两种疾病(青光眼与黄斑裂孔)方面的性能。因此,相较于OmniMedVQA与GMAI-MMBench,LMOD能实现更精细化的评估。本文提出的FunBench在技术上区别于LMOD,主要体现在其层次化的任务体系与靶向化的评估模式。
FunBench的构建源于我们对两个基础性问题的探索:如何系统评估多模态大语言模型的眼底阅片能力,具体包括"评估什么"与"如何评估"。
针对第一个问题,我们构建了涵盖四个层级的任务体系------从低层级的模态与解剖结构感知,到高层级的病灶分析与疾病诊断。这种任务组织方式能够全面评估多模态大语言模型掌握眼底阅片技能的深度与广度,而现有基准测试均未充分支持此类评估。
针对第二个问题,我们的评估不仅面向整体模型,同时关注其两大核心模块------视觉编码器与大语言模型。这一设计实现了整体性与模块化兼备的联合评估,其分析方法在既往研究中尚未被采用。
综上所述,本文的主要贡献包含以下三个方面:
-
数据集:提出FunBench------一个用于评估多模态大语言模型眼底阅片能力的新型基准测试。
-
评估体系:对HuggingFace平台于2023年10月至2025年1月期间发布的九款开源多模态大语言模型进行全面评估。这些模型涵盖五种视觉编码器与七种大语言模型,同时纳入GPT-4o作为商业模型基线,DIVOv2作为视觉编码器基线。
-
研究发现:现有模型对内部大语言模型依赖严重,其眼底阅片能力存在显著局限。特别值得注意的是,这些模型甚至缺乏如左右眼识别等基础技能。
2. FunBench 的构建
2.1 数据集构建
2.1.1 层次化任务体系
根据所需专业眼底阅片技能的深度,我们将任务划分为四个层级,从基础模态感知到高级眼底图像解析:
- 层级1(L1):模态感知。
具备L1能力的模型应能识别生成眼底图像所采用的成像技术。基础场景下,模型需从"自然图像""绘画""遥感"等多选项中识别"眼底图像"。进阶场景则需区分不同眼底成像模态(如彩色眼底照相、光学相干断层扫描、超广角眼底照相)及其他医学影像(如X光、磁共振成像)。我们将这两种设定分别命名为粗粒度模态感知(L1a)与细粒度模态感知(L1b)。

-
层级2(L2):解剖结构感知。
视盘与黄斑是视网膜的两大核心解剖结构。其视觉特征相对明确:在彩色眼底图像中,视盘通常呈现为明亮的椭圆形区域,而黄斑则位于视盘颞侧最暗区域的中心。此外,眼底图像的左右眼属性可根据视盘在图像中的相对位置进行判定。因此,具备L2能力的模型应能判断视盘-黄斑相对位置关系(L2a)并识别左右眼(L2b)。

-
层级3(L3):病灶分析。
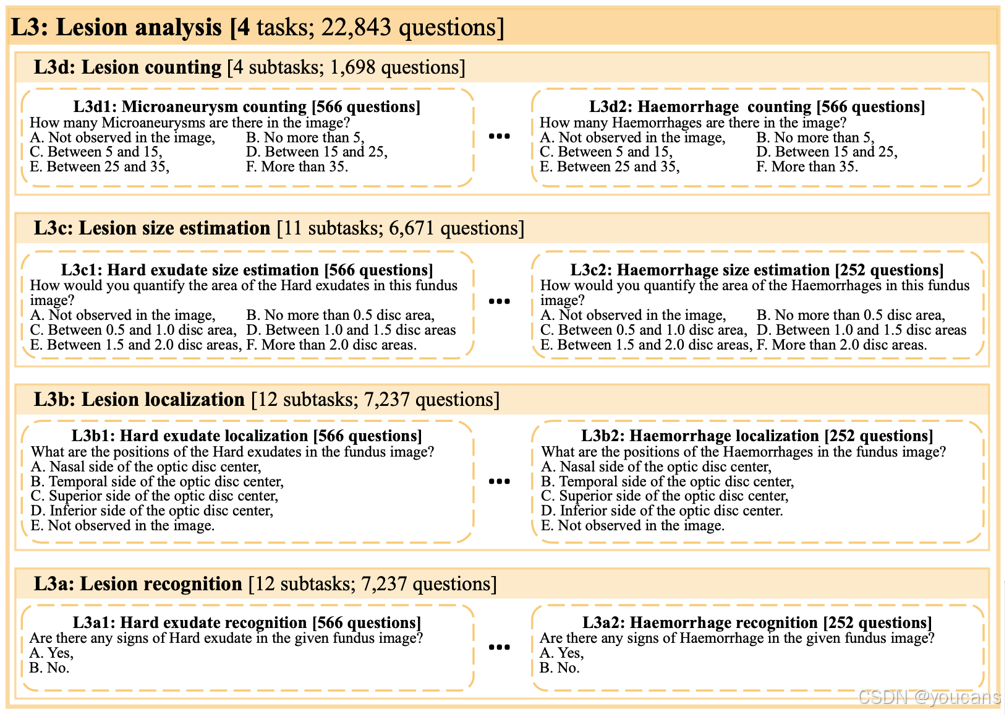
病灶是各类疾病引起的病理性改变,可通过特定眼底成像技术(在一定程度上)观测。识别病灶类型、位置、大小及数量是实现可靠、可解释疾病诊断的关键。以糖尿病视网膜病变分级为例,诊断重度非增殖性糖尿病视网膜病变的充分标准是眼底鼻侧、颞侧、上方、下方四个象限均出现超过20处出血点。因此,掌握L3技能的模型需具备病灶识别(L3a)、定位(L3b)、尺寸估算(L3c)及计数(L3d)能力。
- 层级4(L4):疾病诊断。
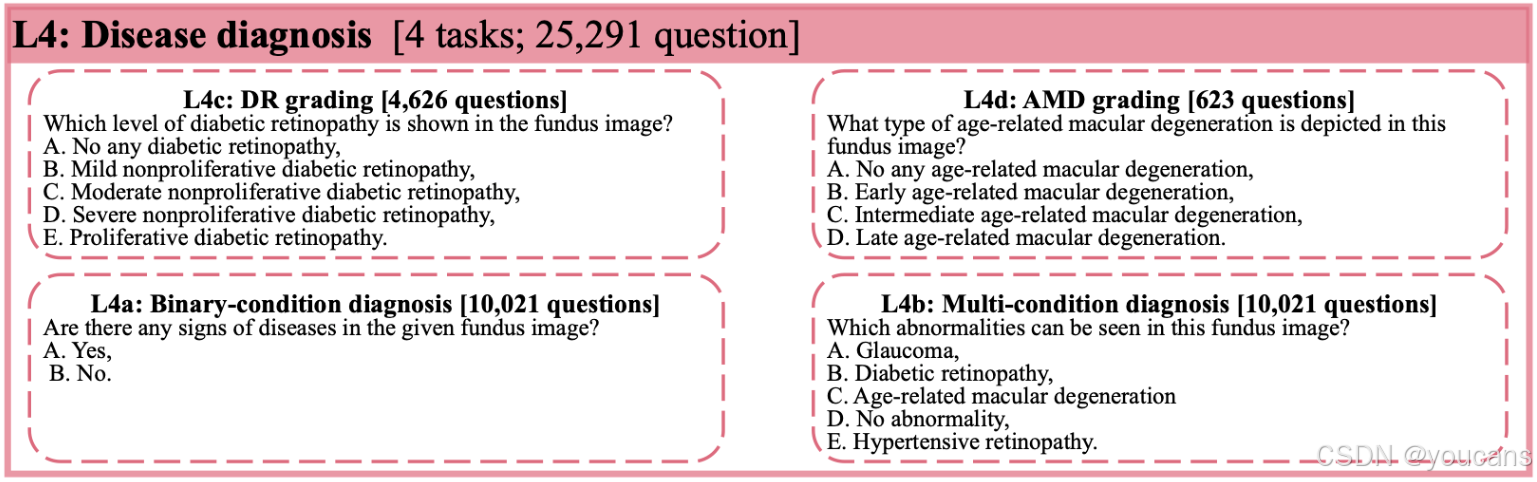
疾病诊断通常需要综合病灶表现、解剖结构变化及眼底整体外观进行综合判断。此类要求使L4技能自然居于最高层级,通常需要医学生经过多年训练才能掌握。
2.1.2 数据来源
为实现上述四层级任务,我们整合了以下14个公开数据集:1)6个彩色眼底照相数据集:IDRiD、DDR、JSIEC、RFMiD、OIA-ODIR与Retinal-Lesions;2)5个光学相干断层扫描数据集:OCTDL、NEH、OCTID、UCSD与RETOUCH;3)1个超广角眼底照相数据集:TOP1;4)2个多模态数据集:MMC-AMD(彩色眼底照相+光学相干断层扫描)与DeepDRiD(彩色眼底照相+超广角眼底照相)。
根据原始标注特性,各数据集在具体任务中的应用详见表1。需要说明的是,我们选取各数据集的测试集分割构成FunBench基准,剩余部分保留作为未来开发集(如监督微调)。基于四个病灶标注数据集(DDR、IDRiD、Retinal-Lesions、RETOUCH),我们将四项L3任务按不同病灶类型进一步细分为39个子任务。借助多疾病标注数据集,我们将L4技能具体实例化为4项任务:二分类(正常/异常)诊断(L4a)、多病症诊断(L4b)、糖尿病视网膜病变分级(L4c)以及细粒度年龄相关性黄斑变性分类(L4d)。
表1. FunBench的统计数据:共计10个任务,包含16,348张视网膜图像和91,810个视觉问题。

2.1.3 从标注到视觉问答四元组
与OmniMedVQA方法类似,我们通过自动填充预定义的、针对具体任务的问题模板,将给定图像及其关联标签转换为多项选择形式的视觉问答四元组(图像、问题、选项、答案)。具体示例参见表1。
为确保多模态大语言模型直接从给定选项中选择答案,我们在每个问题前添加了特定指令。对于单选题,指令为"请根据图像和问题选择最合适的选项,直接回答选项字母"。对于多选题,指令为"请根据图像和问题选择所有合适的选项,直接回答选项字母,如需多个答案请用逗号分隔"。
2.2 2.2 针对性评估模式
为全面评估给定多模态大语言模型及其两大核心模块(大语言模型与视觉编码器),我们以自底向上的方式提出三种针对性评估模式。
-
评估模式一:基于线性探测的视觉编码器评估。
为评估视觉编码器从眼底图像中提取视觉特征的有效性,我们采用广泛使用的线性探测技术。如图1(b)所示,该方法利用任务特定的开发数据集,为每个(子)任务训练基于线性层的分类头。因此,我们排除了无法直接转化为分类问题的任务(如L3b、L3c、L3d)以及线性探测处理过于简单的任务(如L1a、L1b)。通过比较不同多模态大语言模型所使用的视觉编码器,有助于揭示哪种编码器更适合眼底特征提取。
-
评估模式二:知识提示驱动的大语言模型评估。
由于大语言模型模块经过重新训练以处理多模态标记,直接提交文本问题评估该模块存在缺陷。为降低视觉编码器的影响,我们提出一种简单的知识提示评估策略:给定测试图像及其任务相关标签,通过查询专家知识数据库将标签转换为间接描述,并按任务特定格式进行重构。以L2b左右眼识别为例,左眼图像可描述为"黄斑位于视盘右侧"。对于L3a的硬性渗出物识别子任务,对应描述为"边界清晰的白色或黄色沉积物"。如图1©所示,通过将描述置于问题之前,即可实现知识提示驱动的大语言模型评估。需注意,该评估模式将省略部分任务(如L1、L2a、L4a),因为提供的提示会使任务变得过于简单。
-
评估模式三:端到端整体评估。
该模式提供对多模态大语言模型的端到端评估(图1(d))。通过向模型提交多模态多选项问题,并将模型答案与真实答案进行字符串比对,可获得二元评估结果。在初步实验中发现,部分模型无法遵循"生成单字符响应"的指令,倾向于生成更开放的扩展文本。为此,我们采用预训练的Sentence-BERT模型进行文本语义匹配,将语句编码为384维嵌入向量,以选择与生成文本最匹配的选项。
2.2.1 性能指标
人工智能辅助疾病诊断系统自然追求更少的漏检与误报,这可通过灵敏度与特异度分别衡量。我们报告二者的调和平均数(即F1分数)作为综合指标。对于多分类任务(如糖尿病视网膜病变分级),任务级F1分数通过计算所有类别F1分数的平均值获得。
3. 基于FunBench的多模态大语言模型评估
3.1 模型选择
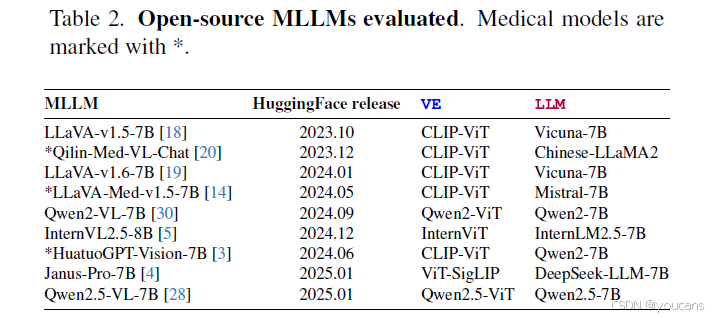
为确保研究的可复现性,我们聚焦于开源多模态大语言模型。根据GPU算力条件,我们筛选出参数量为70亿/80亿规模的模型,最终选定六个通用模型与三个医疗专用模型(见表2)。此外,我们将GPT-4o作为商业模型基线纳入比较,同时采用高性能视觉基础模型DINOv2-large作为视觉编码器基线。
*
表2. 评估的开源MLLMs。医学模型用"*"符号标记*
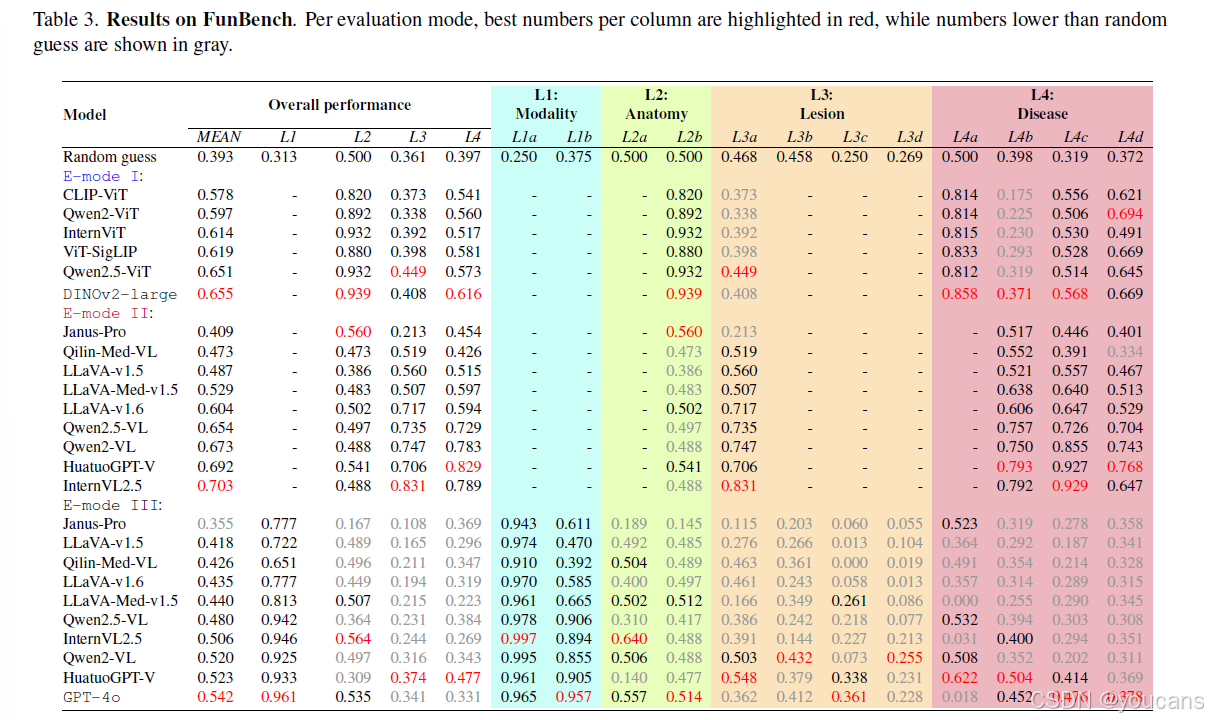
3.2 实验结果
-
视觉编码器对比。
不同视觉编码器的性能表现见表3的评估模式I部分。DINOv2表现最佳,但并未被现有模型采用。相比之下,最流行的CLIP-ViT编码器平均得分仅为0.578,被证明是效果最差的。通过分析其各任务表现,发现在L4b多病症诊断任务上差距最为显著(0.175 vs Qwen2.5-ViT的0.319)。需知CLIP系列模型是在大规模网络数据上针对图文语义匹配任务预训练的,因此其提取的特征可能缺乏区分数十种眼底疾病所需的细粒度细节------这些疾病通常存在较高的类间相似性。我们确实注意到,对于长尾分布的许多疾病,基于各视觉编码器构建的线性探测分类器均无法有效识别,导致灵敏度为零且F1分数归零。由此可见,在L4b任务上视觉编码器的表现甚至低于随机水平。这一结果揭示了纯视觉解决方案在眼底图像分析中的局限性。
-
大语言模型对比。
大语言模型评估结果见表3的评估模式II部分。InternVL2.5、HuatuoGPT-V和Qwen相对于视觉编码器的卓越表现表明,这些大语言模型具备与眼底阅片相关的眼科先验知识。同时值得注意的是,它们在各项任务中的表现存在显著差异(例如L4c糖尿病视网膜病变分级与L4d年龄相关性黄斑变性分类任务)。大语言模型在L4c任务上表现明显更优。我们推测,与年龄相关性黄斑变性相比,网络上糖尿病视网膜病变相关的资料更为丰富,使得大语言模型对糖尿病视网膜病变更为"熟悉"。支持该假设的另一实证证据是:大语言模型在L2b左右眼识别任务上的表现接近随机水平。此类基础技能因过于基础而鲜少被讨论,导致相关训练数据稀缺,从而使其成为大模型的"陌生"任务。这些结果表明当前数据驱动范式存在根本性局限:其训练出的强大模型缺乏基础的眼底阅片技能。
-
多模态大语言模型对比。
各模型整体性能汇总于表3最后部分。在开源模型中,HuatuoGPT-Vision表现最佳,其次为Qwen2-VL与InternVL2.5。值得注意的是,HuatuoGPT-Vision与Qwen2-VL采用相同结构的大语言模型,但前者的视觉编码器表现弱于后者。这种差异凸显了领域特异性微调的重要性。同时需关注HuatuoGPT-Vision在定位相关任务上的相对劣势。根据评估结果,我们认为若采用更强的视觉编码器,其性能有望得到提升。
总体而言,现有模型表现出相当有限的眼底阅片能力。如表4所示,多模态大语言模型与其对应大语言模型之间的高度等级相关性明确显示:前者在执行眼底阅片任务时严重依赖后者。虽然视觉编码器与大语言模型均至关重要,但相关性分析结果强调了开发强大眼科领域大语言模型的迫切需求。

4. 结论
基于全新FunBench基准对多种多模态大语言模型的评估,我们得出以下结论:
- 首先,现有模型在解剖结构感知、病灶分析与疾病诊断等眼底阅片任务上仍表现薄弱;
- 其次,模型对其内部大语言模型的依赖程度远高于视觉编码器;
- 再者,当前采用的视觉编码器性能普遍弱于DINOv2;
- 最后,HuatuoGPT-Vision的整体最优表现印证了领域特异性训练的重要性。
未来的训练流程设计需着眼全局考量,否则我们可能面临开发出缺乏基础眼底阅片能力的多模态大语言模型的风险。
7. FunBench项目介绍:
项目地址 :Github-FunBench,huggingface-FunBench
准备工作
-
下载 FunBench 数据集
FunBench数据集可通过以下链接获取:https://huggingface.co/datasets/AIMClab-RUC/FunBench
-
下载图像数据
FunBench整合了14个公开数据集。请根据提供的链接下载图像文件,并统一存放在指定目录中。
- 六个彩色眼底照相数据集:IDRiD、DDR、JSIEC、RFMiD、OIA-ODIR、Retinal-Lesions
- 五个光学相干断层扫描数据集:OCTDL、NEH、OCTID、UCSD、RETOUCH
- 一个超广角眼底照相数据集:TOP
- 两个多模态数据集:MMC-AMD、DeepDRiD
-
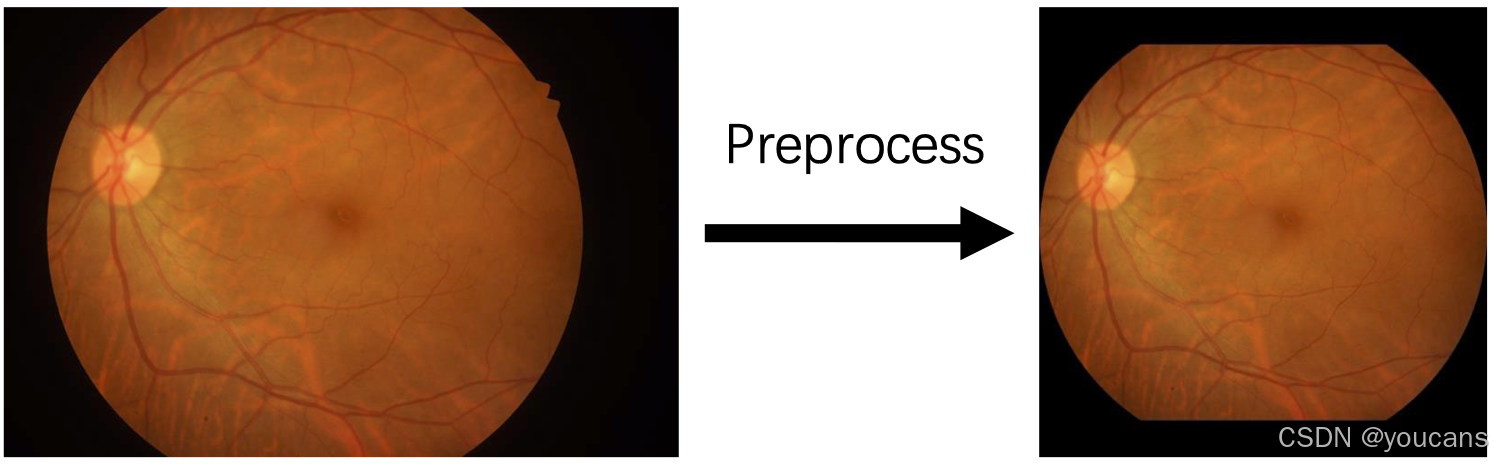
图像预处理
运行 preprocess.py 脚本对RETOUCH数据集及彩色眼底照相图像进行预处理:
- 对于RETOUCH数据集:从原始数据中提取图像与掩码
- 对于彩色眼底照相图像:裁剪视网膜区域并确保图像为正方形
特别说明:Retinal-Lesions数据集中的部分图像将进行180度旋转,以确保其左右眼标签与图像内容的一致性
预处理过程预计耗时1-2小时。
评估流程
运行 predict.py 获取多模态大语言模型的预测结果,随后执行 evaluation.py 计算评估指标。predict.py 中的预测器类针对不同模型进行了定制化适配。
8. 参考文献
bash
[1] Hrvoje Bogunovi´c, Freerk Venhuizen, et al. RETOUCH: Theretinal OCT fluid detection and segmentation benchmark andchallenge. TMI, 38(8):1858--1874, 2019. 3
[2] Ling-Ping Cen, Jie Ji, Jian-Wei Lin, Si-Tong Ju, Hong-JieLin, Tai-Ping Li, Yun Wang, Jian-Feng Yang, Yu-Fen Liu,Shaoying Tan, et al. Automatic detection of 39 fundus diseasesand conditions in retinal photographs using deep neuralnetworks. NComms., 12(1):4828, 2021. 3
[3] Junying Chen, Chi Gui, et al. HuatuoGPT-Vision, towardsinjecting medical visual knowledge into multimodal LLMsat scale. arXiv, 2024. 4
[4] Xiaokang Chen, Zhiyu Wu, et al. Janus-Pro: Unified multimodalunderstanding and generation with data and modelscaling. arXiv, 2025. 3, 4
[5] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, ZhangweiGao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian,Zhaoyang Liu, et al. Expanding performance boundaries ofopen-source multimodal models with model, data, and testtimescaling. arXiv, 2024. 4
[6] Zhuo Deng, Weihao Gao, Chucheng Chen, Zhiyuan Niu,Zheng Gong, Ruiheng Zhang, Zhenjie Cao, Fang Li, ZhaoyiMa, Wenbin Wei, et al. OphGLM: An ophthalmologylarge language-and-vision assistant. Artificial Intelligence inMedicine, 157:103001, 2024. 1
[7] Peyman Gholami, Priyanka Roy, Mohana KuppuswamyParthasarathy, and Vasudevan Lakshminarayanan. OCTID:Optical coherence tomography image database. Computers& Electrical Engineering, 81:106532, 2020. 3
[8] Runlong He, Mengya Xu, Adrito Das, Danyal Z Khan,Sophia Bano, Hani J Marcus, Danail Stoyanov, Matthew JClarkson, and Mobarakol Islam. PitVQA: Image-groundedtext embedding llm for visual question answering in pituitarysurgery. In MICCAI, 2024. 1
[9] Yutao Hu, Tianbin Li, et al. OmniMedVQA: A newlarge-scale comprehensive evaluation benchmark for medicalLVLM. In CVPR, 2024. 1, 3
[10] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman,Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda,Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv, 2024. 4
[11] Daniel S Kermany, Michael Goldbaum, et al. Identifyingmedical diagnoses and treatable diseases by image-baseddeep learning. cell, 172(5):1122--1131, 2018. 3
[12] Mikhail Kulyabin, Aleksei Zhdanov, et al. OCTDL: Opticalcoherence tomography dataset for image-based deep learningmethods. Scientific data, 11(1):365, 2024. 3
[13] Xin Lai, Xirong Li, Rui Qian, Dayong Ding, Jun Wu, andJieping Xu. Four models for automatic recognition of leftand right eye in fundus images. In MMM, 2019. 2
[14] Chunyuan Li, Cliff Wong, et al. LLaVA-Med: Training alarge language-and-vision assistant for biomedicine in oneday. NeurIPS, 2024. 1, 3, 4
[15] Jiajia Li, Zhouyu Guan, et al. Integrated image-based deeplearning and language models for primary diabetes care. Naturemedicine, 30(10):2886--2896, 2024. 1
[16] Ning Li, Tao Li, Chunyu Hu, Kai Wang, and Hong Kang.A benchmark of ocular disease intelligent recognition: Oneshot for multi-disease detection. In BMO, 2021. 3
[17] Tao Li, Yingqi Gao, Kai Wang, Song Guo, Hanruo Liu, andHong Kang. Diagnostic assessment of deep learning algorithmsfor diabetic retinopathy screening. Information Sciences,501:511--522, 2019. 3
[18] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee.Improved baselines with visual instruction tuning. In CVPR,2024. 4
[19] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, YuanhanZhang, Sheng Shen, and Yong Jae Lee. LLaVA-NeXT: Improvedreasoning, OCR, and world knowledge, 2024. 4
[20] Junling Liu, ZimingWang, Qichen Ye, Dading Chong, PeilinZhou, and Yining Hua. Qilin-Med-VL: Towards Chineselarge vision-language model for general healthcare. arXiv,2023. 3, 4
[21] Ruhan Liu, Xiangning Wang, Qiang Wu, Ling Dai, Xi Fang,Tao Yan, Jaemin Son, Shiqi Tang, Jiang Li, Zijian Gao, et al.DeepDRiD: Diabetic retinopathy---grading and image qualityestimation challenge. Patterns, 3(6), 2022. 3
[22] Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, HuyVo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez,Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al.DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal,pages 1--31, 2024. 1, 4
[23] Samiksha Pachade, Prasanna Porwal, Dhanshree Thulkar,Manesh Kokare, Girish Deshmukh, Vivek Sahasrabuddhe,Luca Giancardo, Gwenol´e Quellec, and FabriceM´eriaudeau.Retinal fundus multi-disease image dataset (RFMiD): Adataset for multi-disease detection research. Data, 6(2):14,2021. 3
[24] Prasanna Porwal, Samiksha Pachade, Ravi Kamble, ManeshKokare, Girish Deshmukh, Vivek Sahasrabuddhe, and FabriceMeriaudeau. Indian diabetic retinopathy image dataset(IDRiD): a database for diabetic retinopathy screening research.Data, 3(3):25, 2018. 3
[25] Zhenyue Qin, Yu Yin, Dylan Campbell, Xuansheng Wu, KeZou, Yih-Chung Tham, Ninghao Liu, Xiuzhen Zhang, andQingyu Chen. LMOD: A large multimodal ophthalmologydataset and benchmark for large vision-language models. InNAACL, 2025. 1
[26] Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentenceembeddings using siamese BERT-networks. InEMNLP, 2019. 3
[27] Saman Sotoudeh-Paima, Ata Jodeiri, Fedra Hajizadeh, andHamid Soltanian-Zadeh. Multi-scale convolutional neuralnetwork for automated AMD classification using retinalOCT images. Computers in biology and medicine, 144:105368, 2022. 3
[28] Qwen Team. Qwen2.5-vl, 2025. 4
[29] Cheng-Hao Tu, Zheda Mai, andWei-Lun Chao. Visual querytuning: Towards effective usage of intermediate representationsfor parameter and memory efficient transfer learning.In CVPR, 2023. 3
[30] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan,Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, WenbinGe, et al. Qwen2-VL: Enhancing vision-language model'sperception of the world at any resolution. arXiv, 2024. 4
[31] WeisenWang, Xirong Li, Zhiyan Xu,Weihong Yu, JianchunZhao, Dayong Ding, and Youxin Chen. Learning two-streamCNN for multi-modal age-related macular degeneration categorization.IEEE Journal of Biomedical and Health Informatics,26(8):4111--4122, 2022. 3
[32] ZhiruiWang, Xinlong Jiang, Chenlong Gao, Fan Dong,WeiweiDai, Bingyu Wang, Bingjie Yan, Qian Chen, WuliangHuang, Teng Zhang, et al. Eyegraphgpt: Knowledge graphenhanced multimodal large language model for ophthalmicreport generation. In BIBM, 2024. 1
[33] Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, YongpengZhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, DayongDing, et al. Learn to segment retinal lesions and beyond. InICPR, 2021. 3
[34] Zhuoya Yang, Xirong Li, Xixi He, Dayong Ding, YantingWang, Fangfang Dai, and Xuemin Jin. Joint localization ofoptic disc and fovea in ultra-widefield fundus images. InMLMI@MICCAI, 2019. 2
[35] Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, WeiLi, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su,Benyou Wang, et al. GMAI-MMBench: A comprehensivemultimodal evaluation benchmark towards general medicalAI. In NeurIPS, 2024. 1
[36] Chun-Hsiao Yeh, JiayunWang, Andrew D Graham, Andrea JLiu, Bo Tan, Yubei Chen, Yi Ma, and Meng C Lin. Insight: Amulti-modal diagnostic pipeline using llms for ocular surfacedisease diagnosis. In MICCAI, 2024. 1
[37] Tiantian Zhang, Manxi Lin, Hongda Guo, Xiaofan Zhang,Ka Fung Peter Chiu, Aasa Feragen, and Qi Dou. Incorporatingclinical guidelines through adapting multi-modal largelanguage model for prostate cancer PI-RADS scoring. InMICCAI, 2024. 1版权说明:
本文由 youcans@xidian 对论文 "A Foundation Language-Image Model of the Retina (FLAIR): encoding expert knowledge in text supervision" 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式: Q. Wei, K. Qian, and X. Li, "FunBench: Benchmarking Fundus Reading Skills of MLLMs," in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. (MICCAI), 2025.
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】FunBench:评估多模态大语言模型的眼底影像解读能力
(https://youcans.blog.csdn.net/article/details/155647655)
Crated:2025-12