2.子任务二:Hadoop完全分布式安装配置(任务一)
在 主 节 点 将 Hadoop 安 装 包 解 压 到/root/software目录下
bash
tar -zxvf hadoop-3.2.1.tar.gz -C /root/software/依次配置hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和workers配置文件
在修改配置文件之前先进入path/to/hadoop/etc/hadoop目录:
所有的配置文件都在path/to/hadoop/etc/hadoop下面,如下图:

(1)hadoop-env.sh配置文件
在文件里面输入hadoop的路径
bash
export JAVA_HOME=/root/software/jdk1.8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(2)core-site.xml配置文件
xml
<!-- 在configuration标签内添加以下内容 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 临时文件存放位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/software/hadoop-3.2.1/hadoopDatas/tempDatas</value>
</property>(3)hdfs-site.xml配置文件
xml
<!-- 在configuration标签内添加以下内容 -->
<!-- 设置副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode存放的位置,老版本是用dfs.name.dir -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/software/hadoop-3.2.1/hadoopDatas/namenodeDatas</value>
</property>
<!-- datanode存放的位置,老版本是dfs.data.dir -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/software/hadoop-3.2.1/hadoopDatas/datanodeDatas/</value>
</property>
<!-- 关闭文件上传权限检查 -->
<property>
<name>dfs.permissions.enalbed</name>
<value>false</value>
</property>
<!-- namenode运行在哪儿节点,默认是0.0.0.0:9870,在hadoop3.x中端口从原先的50070改为了9870 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- secondarynamenode运行在哪个节点,默认0.0.0.0:9868 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>(4)mapred-site.xml配置文件
xml
<!-- 在configuration标签内添加以下内容 -->
<!-- 设置mapreduce在yarn平台上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配了上面这个下面这个也得配, 不然跑mapreduce会找不到主类。MR应用程序的CLASSPATH-->
<property>
<name>mapreduce.application.classpath</name>
<value>/root/software/hadoop-3.2.1/share/hadoop/mapreduce/*:/root/software/hadoop-3.2.1/share/hadoop/mapreduce/lib/*</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>(5)yarn-site.xml配置文件
xml
<!-- 在configuration标签内添加以下内容 -->
<!-- resourcemanager运行在哪个节点 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- nodemanager获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>(5)workers文件
删掉里面的localhost,添加以下内容
bash
master
slave1
slave2(3)在master节点的Hadoop安装目录:
下依次创建hadoopDatas/tempDatas 、 hadoopDatas/namenodeDatas 、hadoopDatas/datanodeDatas、hadoopDatas/dfs/nn/edits、hadoopDatas/dfs/snn/name 和hadoopDatas/dfs/nn/snn/edits目录
进入hadoop安装目录下执行下面命令:
bash
mkdir -p hadoopDatas/tempDatas
mkdir -p hadoopDatas/namenodeDatas
mkdir -p hadoopDatas/datanodeDatas
mkdir -p hadoopDatas/dfs/nn/edit
mkdir -p hadoopDatas/dfs/snn/name
mkdir -p hadoopDatas/dfs/nn/snn/edits(4)在master节点上使用scp命令将配置完的Hadoop安装目录直接拷贝至slave1和slave2
bash
scp -r /root/software/hadooproot@slave1:/root/software/
scp -r /root/software/hadoop root@slave2:/root/software/(5)三台节点的"/etc/profile"文件中配置Hadoop环境变量HADOOP_HOME和PATH的值,并让配置文件立即生效;
bash
vi /etc/profile
export HADOOP_HOME=/root/software/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile生效之后可以在每一个节点上查看hadoop的安装版本:


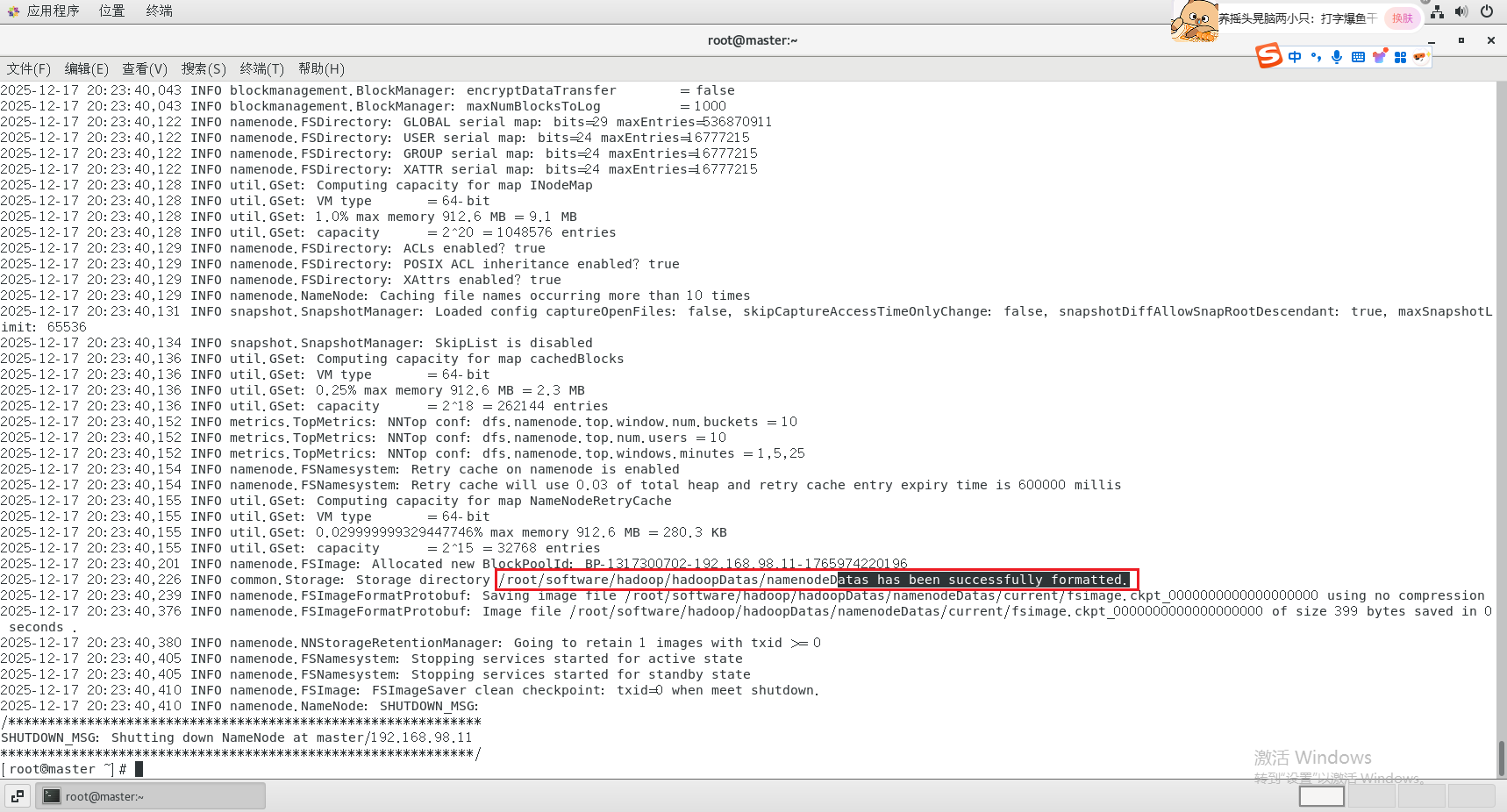
(6)在主节点格式化集群
bash
hdfs namenode -format
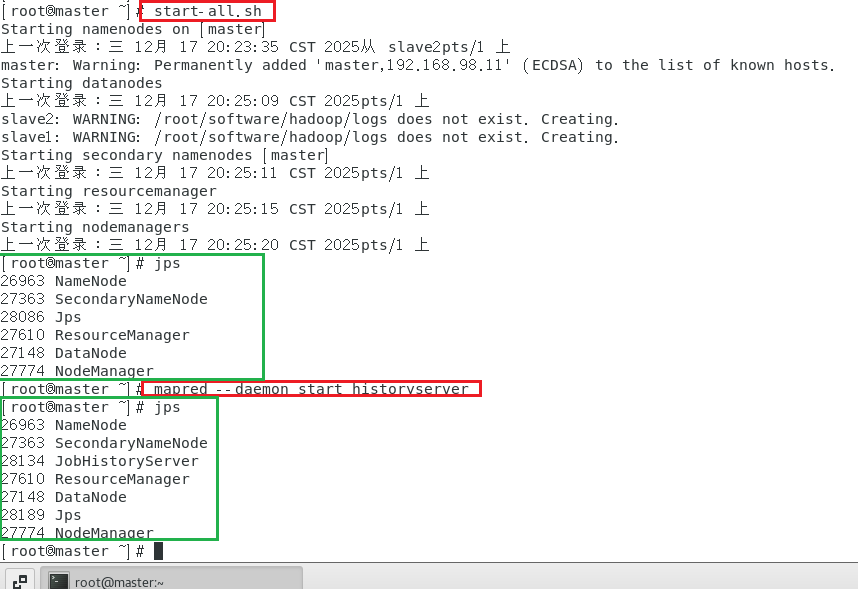
(7)在主节点依次启动HDFS、YARN集群和历史服务
bash
# 在master节点上进行
start-all.sh
mapred --daemon start historyserver(mr-jobhistory-daemon.sh start historyserver)jps是查看进程的命令
在master节点上输入jps
 在slave1节点上输入jps
在slave1节点上输入jps

在slave2节点上输入jps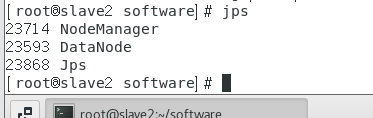
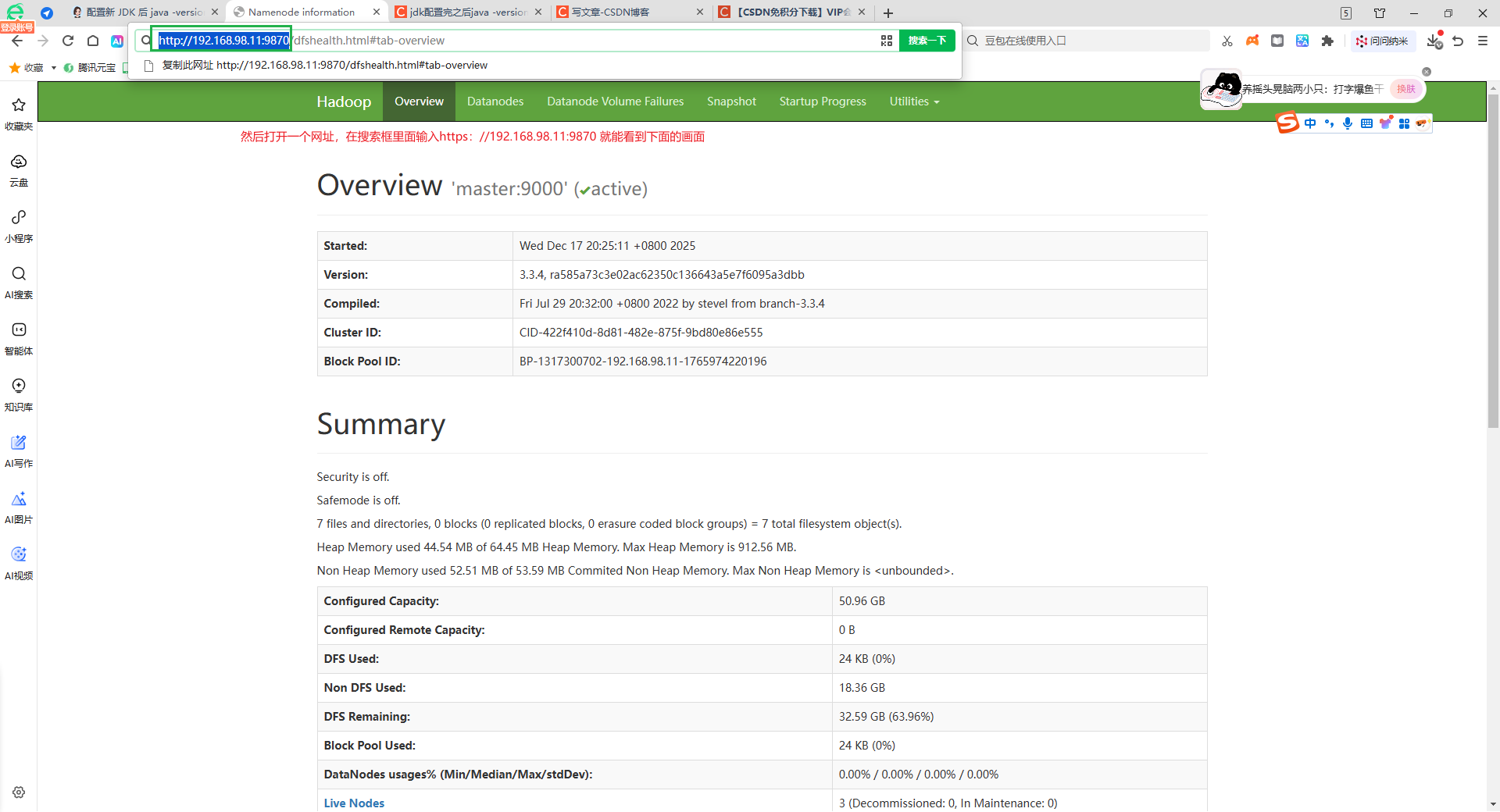
补充说明------各组件 Web UI 访问方式(核心)
- HDFS Web UI(文件系统监控)
默认端口:Hadoop 3.x 为9870(Hadoop 2.x 为50070,需注意版本差异);
访问地址:http://主节点主机名/IP:9870(例:http://master:9870、http://192.168.1.100:9870);
核心查看内容:
左侧「Browse the file system」:查看 HDFS 文件目录;
「Datanodes」:查看从节点 DataNode 是否正常在线;
「Overview」:查看 HDFS 容量、已用空间等状态(验证 HDFS 集群正常)。
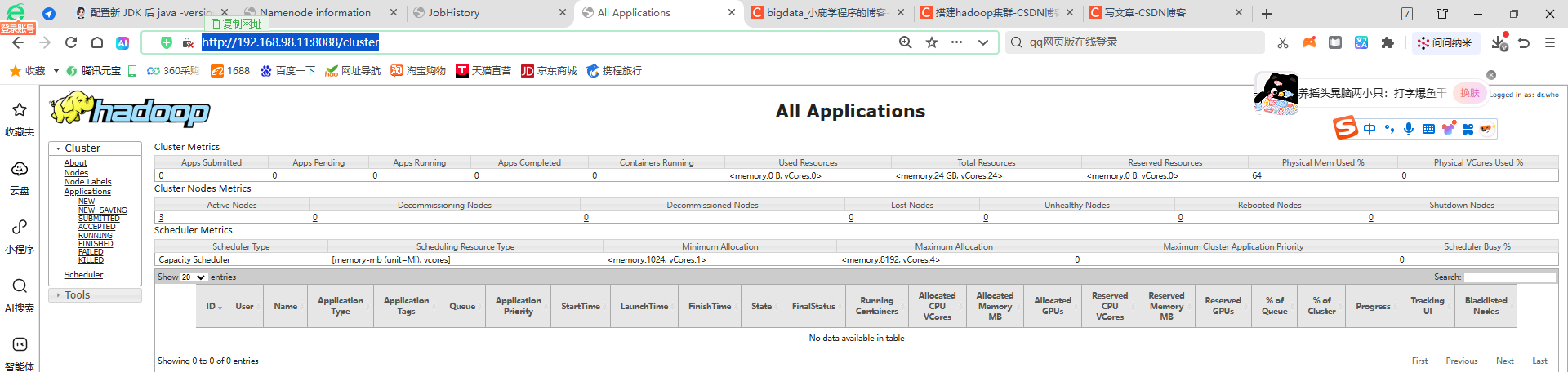
- YARN Web UI(资源调度监控)
默认端口:8088(3.x/2.x 通用);
访问地址:http://主节点主机名/IP:8088(例:http://master:8088);
核心查看内容:
「Cluster Overview」:查看集群总内存、CPU 核数、NodeManager 数量(验证 YARN 集群正常);
「Applications」:查看已提交 / 运行 / 完成的 MapReduce/Spark 任务(大赛中提交 WordCount 后可在此验证任务状态);
「Nodes」:查看从节点 NodeManager 是否在线。
- MapReduce 历史服务 Web UI(任务日志查看)
默认端口:19888(3.x/2.x 通用);
访问地址:http://主节点主机名/IP:19888(例:http://master:19888);
核心查看内容:
「Completed Applications」:查看已完成的 MapReduce 任务详情、日志(大赛中评委重点检查项,验证任务可追溯);
「Job History Configuration」:查看历史服务配置是否正常。