概述
官网,Raft是分布式系统开发首选的共识算法,通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。
在Raft出现前,Paxos一直是分布式一致性算法(共识算法)的标准,但难以理解更难以实现。Raft的设计目标是简化Paxos,使分布式一致性算法容易理解和实现。两者区别在于选举的具体过程不同。
角色
任何时候,任何一台节点都只会处于三种状态中的一种:
- 跟随者(Follower):普通群众,默默接收和来自领导者的消息,当领导者心跳信息超时时,就主动站出来,推荐自己当候选人
- 候选者(Candidate):候选人将向其他节点请求投票RPC消息,通知其他节点来投票,如果赢得大多数投票选票,就晋升领导者
- 领导者(Leader):处理写请求、管理日志复制和不断地发送心跳信息
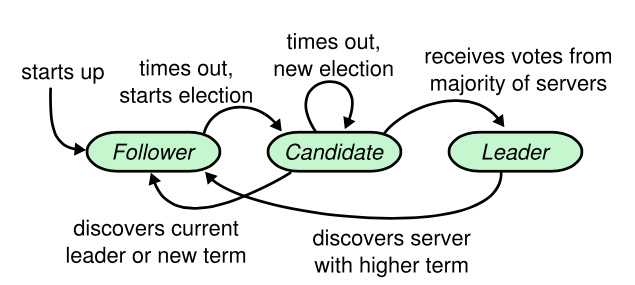
解读: - 跟随者只响应来自其他服务器的请求。在一定时限内,若跟随者接收不到消息,就会转变成候选者,并发起选举;
- 候选者向跟随者发起投票请求,如果获得集群中半数以上的选票,就会转变为领导者;
- 一个Term内,领导者始终保持不变,直到下线。领导者需要周期性向所有跟随者发送心跳消息,以阻止跟随者转变为候选者。
客户端只能从主节点写数据,从节点里读数据。
任期
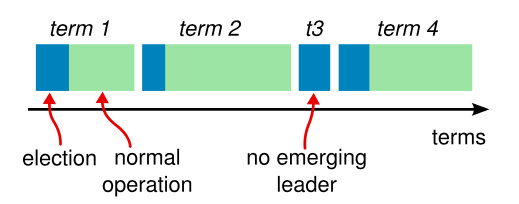
Raft不依赖系统时间,把时间分割成任意长度的任期(Term,选举周期),任期用连续的整数标记,每一段任期从一次选举开始。Raft保证在一个给定的任期内,最多只有一个领导者:
- 如果选举成功,领导者会管理整个集群直到任期结束;
- 如果选举失败,这个任期就会因为没有领导者而结束。
不同服务器节点观察到的任期转换状态可能不一样:
- 服务器节点可能观察到多次的任期转换;
- 服务器节点也可能观察不到任何一次任期转换。
任期在Raft算法中充当逻辑时钟的作用,使得服务器节点可以查明一些过期信息(如过期的领导者)。每个服务器节点都会存储一个当前任期号,这一编号在整个时期内单调的增长。当服务器之间通信时会交换当前任期号。
- 如果一个服务器的当前任期号比其他人小,则更新自己的编号到较大的编号值;
- 如果一个候选者或领导者发现自己的任期号过期,则立即恢复成跟随者状态;
- 如果一个节点接收到一个包含过期的任期号的请求,则直接拒绝这个请求。
RPC
Raft算法中服务器节点之间的通信使用RPC,基本的一致性算法只需要两种RPC:
- RequestVote RPC:请求投票RPC,由候选者在选举期间发起;
- AppendEntries RPC:附加条目RPC,由领导者发起,用来复制日志和提供一种心跳机制。
技术原理
将分布式一致性算法,拆解为三个子问题:领导选举、日志复制,安全性。
| 子问题 | 核心目标 | 要解决的问题 |
|---|---|---|
| 领导选举 | 确保集群中在任何时候至多有一个有效的领导者 | 如何发现领导者失效?如何选出新领导者?如何避免多个领导者同时存在(脑裂)? |
| 日志复制 | 使集群所有节点上的日志顺序和内容最终保持一致 | 领导者如何将客户端请求复制到多数节点?如何定义一条日志被"提交"?如何处理节点间日志不一致? |
| 安全性 | 保证已提交的日志绝对正确且不可更改,是算法的底线(生命线) | 如何防止新领导者覆盖已提交的日志?如何保证状态机以相同顺序执行相同指令? |
领导选举
初始时,所有节点都处于跟随者状态。如果跟随者节点不再能接收到领导者节点的消息,状态就会变成候选者,候选者节点会向其他节点发起投票请求。
如果收到消息的节点在这一个周期还没有投过票,则需要给候选者投一票,并重置他的选举超时时间。如果候选者收到大多数节点的投票,就会成为领导者。领导者此时会在心跳检测的周期内,给所有跟随者发送Append Entries messages。检测频率是通过心跳超时时间设置的。然后每个跟随者也会给Append Entries message发送响应。选举周期会一直持续直到某个跟随者停止心跳消息接收变成候选者。
选举超时:假设两个节点同时从跟随者状态变成候选者,此时两者都会升级Term,并请求其他节点给自己投票。此时两者的Term其实是相同的,在同一个Term内其他节点只会投出一票,因为没有超过「大多数」,所以都不能成为领导者。在选举超时后,这些节点就会等待新一轮的选举;跟随者会变成候选者开始一个新的任期,同时会给自己投一票,并且给其他节点发送请求投票的消息。
选举超时,是Raft实现故障检测和领导者切换的核心。每个跟随者节点都会维护一个选举计时器。工作流程:
- 计时开始:当一个跟随者收到领导者有效的心跳或日志消息时,会重置这个计时器。
- 计时耗尽:如果在计时器到期前,没有收到来自当前领导者的任何消息,跟随者就会假定领导者已经失效。
- 发起选举:该跟随者会立即增加任期号,转换为候选人状态,并向集群发起新一轮的领导者选举。
随机值:Raft要求每个节点的选举超时时间在一个区间内随机选取。可有效防止多个跟随者同时因超时而成为候选人,导致选票分散,从而快速选出唯一的领导者。
心跳超时 (Heartbeat Timeout):领导者用来维持统治的机制。领导者会周期性地向所有跟随者发送不包含日志内容的心跳消息。收不到心跳消息的话,节点的状态会从跟随者变成候选者,节点在各自的选举超时时间设置内会改变状态,先超时的节点会先开始新一轮选举。
工作流程:
- 领导者启动后,会按照心跳间隔周期性地发送心跳。
- 跟随者收到心跳后,会将其视为来自领导者的有效消息,并重置自己的选举计时器。
- 只要领导者正常运行且网络通畅,就能持续阻止跟随者因选举超时而触发新的选举。
总结一下,Raft里的两个超时时间设置:
- 选举超时:跟随者变成候选者的等待时间,值是150ms到300ms间的一个随机值。
- 心跳超时:每个节点等待领导者节点心跳信息的超时时间间隔是随机的。
| 类型 | 主要目的 | 触发角色 | 典型值范围(参考值) | 关键特性 |
|---|---|---|---|---|
| 选举超时 | 触发领导者选举,确保在无主时能选出新领导者 | 跟随者 | 150-300毫秒 | 随机化,防止同时发起选举 |
| 心跳超时 | 领导者定期发送心跳,维持其权威并阻止新的选举发生 | 领导者 | 远小于选举超时(如50毫秒) | 固定间隔,远短于选举超时 |
Raft论文中有一个重要的时间不等式需要遵循:广播时间 (broadcastTime) << 选举超时 (electionTimeout) << 平均故障间隔时间 (MTBF)。
解读:
- 广播时间 << 选举超时:意味着一次RPC通信所需的时间必须远小于选举超时。这样可确保领导者有足够的时间发送心跳来重置跟随者的计时器,避免因网络偶尔延迟就误触发选举。
- 选举超时 << MTBF:意味着选举超时必须远小于服务器的平均无故障运行时间。这样在领导者真正崩溃时,系统只会经历短暂的选举期(约一个选举超时时间),然后迅速恢复服务,不会对整体可用性造成太大影响。
因此,在实际配置时,心跳间隔通常会设为选举超时的1/5~1/10,以满足这个不等式。
集群中断与恢复:当集群之间的部分节点失去通讯时,主节点的日志不能复制给多个从节点就不能进行提交。当集群恢复之后,原来的主节点发现自己不是选票最多的节点,就会变成从节点,并回滚自己的日志,最后主节点会同步日志给从节点,保持主从数据的一致性。
Raft算法选举过程图示。
日志复制
Log Replication,每次Client的变更请求到达领导者时,都会视为一个Entry,先添加到节点的日志(Log)里。这个新增的Log Entry,目前还并没有提交,所以不会真的更新节点里X的值。领导者首先会在下一次心跳检测时,复制Log Entry给所有跟随者节点。领导者会等待,直到多数节点都写入Entry。在收到多数节点的写入响应之后,领导者节点会将Entry提交,然后领导者会在下次心跳时通知跟随者节点自己的Entry已经提交,此时各个跟随者节点也会将之前收到的Entry进行提交。
日志格式
日志由含日志索引(Log Index)的日志条目(Log Entry)组成。每个日志条目包含它被创建时的Term号(下图中方框中的数字),和一个复制状态机需要执行的指令。如果一个日志条目被复制到半数以上的服务器上,就被认为可以提交(Commit)。
日志条目中的Term号被用来检查是否出现不一致的情况。
日志条目中的日志索引(一个整数值)用来表明它在日志中的位置。
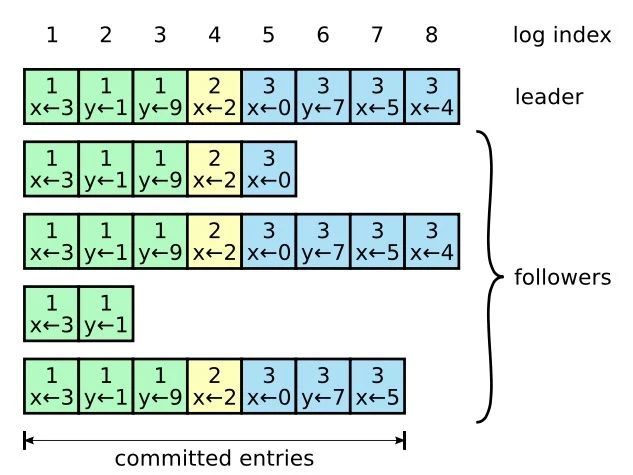
Raft日志同步保证如下两点:
- 如果不同日志中的两个日志条目有着相同的日志索引和Term,则它们所存储的命令是相同的。这个特性基于这条原则:领导者最多在一个Term内、在指定的一个日志索引上创建一条日志条目,同时日志条目在日志中的位置也从来不会改变。
- 如果不同日志中的两个日志条目有着相同的日志索引和Term,则它们之前的所有条目都是完全一样的。
这个特性由AppendEntries RPC的一个简单的一致性检查所保证。在发送AppendEntries RPC时,领导者会把新日志条目之前的日志条目的日志索引和Term号一起发送。如果跟随者在它的日志中找不到包含相同日志索引和Term号的日志条目,就会拒绝接收新的日志条目。
安全性
Raft算法语境下的安全,并非指网络安全、数据安全...,而是指算法在任何情况下都必须遵守的核心正确性保证,即永不返回错误的结果;即算法的首要任务是:防止数据损坏和逻辑错误。
核心承诺:一旦一条日志条目被提交(复制到多数节点),那么它在所有后续领导者的日志中都必须存在,并且状态机最终会执行它。
Raft通过一系列精巧的规则,在领导选举和日志复制的过程中,嵌入五个关键的安全约束:
- 选举限制:规定候选人必须拥有比集群中多数节点更新的日志,才能赢得选举成为领导者。
- 领导人完全:一旦一个日志条目在某个任期被提交,那么之后所有任期号更高的领导者的日志里都会包含这个条目。
- 日志匹配特性:Raft通过两条特性维护日志的一致性,为安全地复制和修复日志提供基础
- 如果不同日志中的两个条目拥有相同的索引和任期号,那么它们存储的命令相同。
- 如果不同日志中的两个条目拥有相同的索引和任期号,那么它们之前的所有日志条目也完全相同。
- 提交之前任期的日志条目限制:领导者只能提交当前任期的日志条目。避免已被复制到多数节点但尚未提交的旧任期日志,在新领导者上台后被武断提交,从而可能覆盖掉更新的日志。
- 状态机安全指令应用:Raft规定,只有已提交的日志条目才能被应用到状态机。保证所有节点状态机的最终一致性。
过半原则
每个服务器都预先知道集群的总节点数,通过配置在集群启动或成员变更时确定;获取到的集群成员列表信息,包含:
- 所有节点的ID,如
IP:Port或唯一标识符; - 集群的总节点数。
Raft通过两阶段配置变更(如Joint Consensus)避免脑裂:
- 旧配置和新配置并存阶段,需要同时满足两个配置的多数票;
- 切换完成后,节点使用新配置的N计算多数票。
节点无需实时感知当前总节点数,因为Raft假设:
- 配置是集群范围的共识:所有节点在同一时刻使用相同的配置;
- 配置变更通过日志同步:配置变更作为一个特殊日志条目,复制到多数节点后才生效,确保配置一致性。
节点下线情况:
- 部分(少于半数)节点临时下线:集群仍能正常工作,因为剩余在线节点仍能形成多数派;
- 永久性下线:领导者通过特殊的日志条目来更新集群成员,日志被复制到多数节点(按旧配置的多数),生效后集群使用新配置,故障节点被排除;
- 但如果超过半数节点下线:剩余节点无法选举出新领导者,集群会完全停止服务;CAP理论,选择C舍弃A。
节点增删
对于分布式系统,节点增删是一个很常见的场景。添加节点其实是比较困难的操作,最常见的做法是先更改配置中心,然后将新的配置同步到旧的节点。不过这样在同步配置时,就需要停止外部服务。
Raft采用一种动态的成员节点变更,它会将新的节点到当作Raft Log通过领导者传递给其他节点,这样其他节点就知道这个新的节点的信息。不过这个过程中有可能会在某一阶段出现2个领导者的情况,为了避免这种情况就要每次只变更一个节点,而不进行多节点变更。
Raft也提供一种多节点变更的算法,它是一种两阶段提交,领导者在第一阶段会同时将新旧集群的配置同时当成一个Raft Log发送给其他旧集群节点,当这些节点接收到数据后就会和新的集群节点进入join状态,所有的操作都要进过新旧集群的大多数节点同意才会执行,然后在新的join状态内重新提交新的配置信息,在配置被committed后新的节点会上线,旧的节点会下线。
优化
日志压缩
在实际中,不能让日志无限膨胀。Raft采用快照来解决,快照之前的日志都可丢弃。每个副本独立地对自己的系统状态生成快照,只能对已经提交的日志条目生成快照。快照包含以下内容:
- 日志元数据。最后一条已提交的日志条目的日志索引和Term。这两个值在快照之后的第一条日志条目的AppendEntries RPC的完整性检查的时候会被用上。
- 系统当前状态。
当领导者要发送某个日志条目,落后太多的跟随者的日志条目会被丢弃,领导者会将快照发给 跟随者。新上线一台机器时,也会发送快照给它。
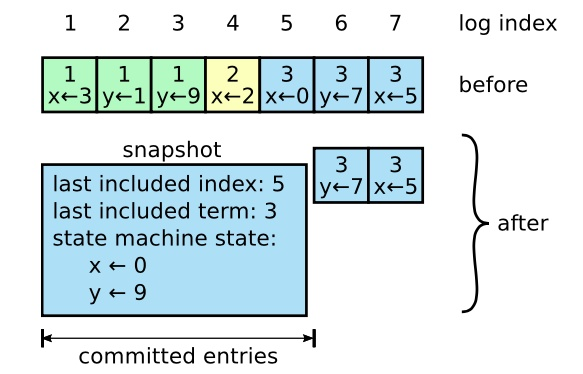
生成快照的频率要适中,频率过高会消耗大量IO带宽;频率过低,一旦需要执行恢复操作,会丢失大量数据,影响可用性。推荐当日志达到某个固定的大小时生成快照。
生成一次快照可能耗时过长,影响正常日志同步。可通过使用copy-on-write技术避免快照过程影响正常日志同步。
Pre-Vote
预投票机制,在正式选举前先进行预投票,防止网络隔离的节点不断增大Term值,需要获得多数预投票同意才能发起正式选举。
在Follow处于网络抖动无法接受到领导者的消息时,就会变成候选者并且Term加一,但其他集群其实还是在正常工作。Pre-Vote机制会在Follow没有接收到领导者的消息并且开始投票之前进入PreCandidate状态,在想其他节点发送投票请求,并获得同意后才会进入候选者状态。
其他
- Pipeline
正常的Raft流程中,客户端事先给领导者写入数据,领导者处理后会追加到log中,追加成功后Replication到其他节点中,当领导者发现Log被整个集群大多数节点接收后就会进行Apply。
这样的一个过程其实是非常低效的,所以就需要引入Pipeline,它可以将多个请求进行并发处理,有效提高效率。
- Batch
通常情况下接收到的客户端请求都是依次过来的,而当有一批请求过来的时候,就可通过Batch将这些请求打包成一个Raft Log发送出去。
应用
在分布式组件里面经常会看到使用Raft协议的实现。
Etcd
多一种节点状态:PreCandidate。
当领导者节点异常时,跟随者节点会接收领导者的心跳消息超时,当超时时间大于竞选超时时间后,会进入PreCandidate状态,不自增任期号,仅发起预投票(民意调查,防止由于节点数据远远落后于其他节点而发起无效选举),获得大多数节点认可后,进入候选者状态;进入候选者状态的节点,会等待一个随机时间,然后发起选举流程,自增任期号,投票给自己,并向其他节点发送竞选投票信息。
Consul
RocketMQ
DLedger
论文,GitHub。分布式日志复制技术,使用Raft协议,在多个副本之间安全地复制和同步数据。
TiDB
拓展
Multi-Raft
当目前的Raft Group无法支撑所有的数据的时候,就需要引入Multi-Raft处理数据,第一种做法是将数据切分成多个Raft Group分担到不同的机器上。
为了应对更复杂的情况就需要使用动态分裂的方法,假设最开始的只有3台机器以及一个Region,这个Region就布置在一台机器上,所有的数据都写入这台机器,当数据量达到某个预值后Region就产生分裂,得到的新的Region就可以移植到新的机器上。