ceph分布式存储
课程目标
-
了解分布式存储与ceph相关的组件
-
了解文件存储、块存储、对象存储
-
完成ceph集群搭建
-
基于ceph集群完成文件存储、块存储、对象存储
课程实验
-
存储相关概念及分布式存储介绍
-
ceph集群搭建实验
-
ceph文件存储实验
-
ceph块存储实验
-
ceph对象存储实验
课堂引入
- 之前我们学习的存储主要是磁盘分区、逻辑卷、磁盘阵列,都是单台机器文件存储,如果是不同的机器的硬件要组成一个大的存储空间,就需要使用到分布式存储了
授课进程
一、存储相关概念
1、概述
在现代计算机系统和网络中,数据存储是至关重要的。随着数据量的爆炸式增长,如何高效、可靠地存储和管理数据成为了一个重要的挑战。文件存储、块存储和对象存储是三种主要的数据存储方式,它们各自具有独特的特性和适用场景。本文将详细探讨这三种存储方式的定义、架构、原理和应用场景,帮助读者更好地理解和选择合适的数据存储解决方案。
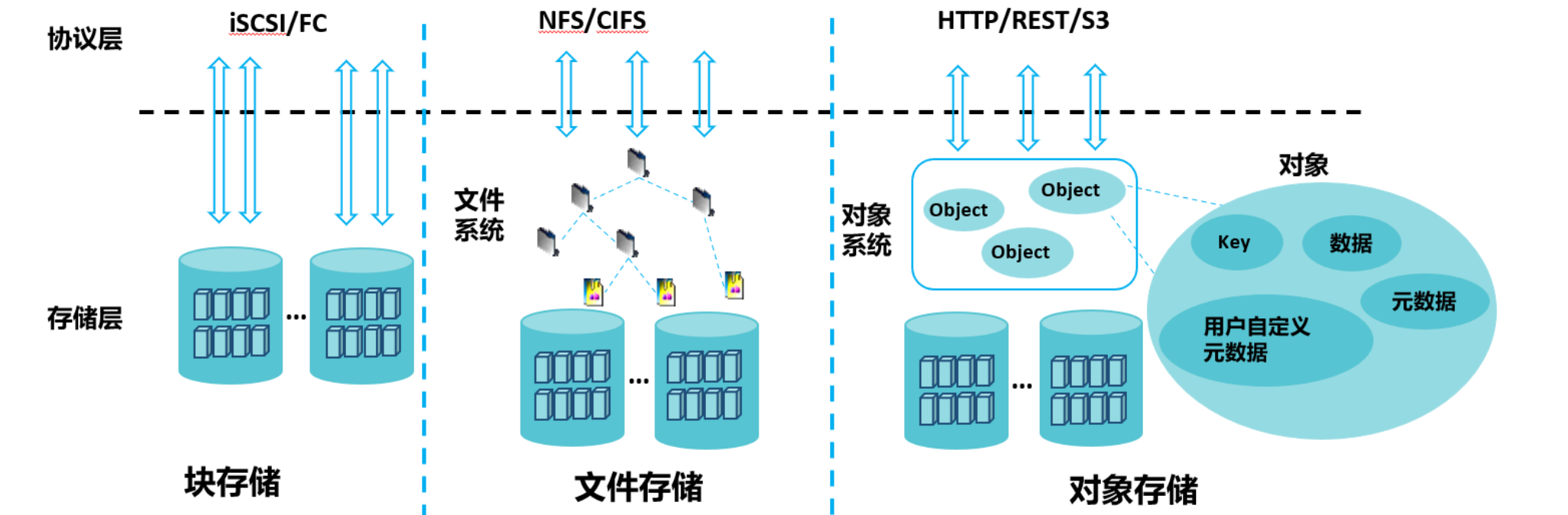
2、块存储
1)定义
块存储(Block Storage)是一种将数据分割成固定大小的块进行存储的方法。每个块都有一个唯一的地址,应用程序通过块地址来读取和写入数据,而不关心文件系统的具体实现。这种存储方式类似于我们日常使用的图书馆,每本书可以被分割成多个章节,每个章节都有一个唯一的编号。
典型设备: 磁盘阵列,硬盘
2)原理
块存储的基本原理是将数据分割成多个固定大小的块,并为每个块分配一个唯一的地址。操作系统通过块设备驱动程序直接访问这些块,从而实现对数据的读写操作。
块存储系统通常不关心数据的具体内容和结构,只提供简单的读写接口。应用程序或文件系统负责管理数据的逻辑结构,如文件的组织和目录结构。
块存储的一个重要特点是支持随机访问,即可以快速定位并读取任意块的数据。这使得块存储非常适合需要高性能和低延迟的数据访问场景。 3)应用场景
-
数据库存储:数据库系统通常需要高性能的随机访问,块存储能够满足这一需求,提供快速的数据读写能力。
-
虚拟机存储:虚拟机镜像文件需要高效的存储和管理,块存储提供了灵活和高效的解决方案,支持虚拟机的快速启动和迁移。
-
高性能计算:高性能计算(HPC)需要快速读写大规模数据集,块存储可以提供高吞吐量和低延迟的数据访问,支持科学计算、数据分析等应用。
-
容灾和备份:块存储支持数据的快速复制和备份,提高系统的容灾能力,确保数据的安全性和可靠性。
3、对象存储
1)定义
对象存储(Object Storage)是一种将数据作为对象进行存储的方法。每个对象包含数据、元数据和一个唯一的标识符,用户通过标识符访问对象,而不需要关心对象的物理存储位置。这种存储方式类似于我们日常使用的邮政系统,每个邮件包裹都有一个唯一的追踪号,可以通过追踪号查找包裹的状态和位置
典型设备: 内置大容量硬盘的分布式服务器(swift, s3)
2)原理
对象存储的基本原理是将数据作为独立的对象进行存储,每个对象包含数据本身、元数据和唯一标识符。对象存储系统通过分布式存储节点来存储和管理这些对象,并提供统一的接口供用户访问。
对象存储系统通常采用水平扩展的架构,可以通过增加存储节点来扩展存储容量和性能。对象存储系统还支持数据的冗余和分布,以提高数据的可靠性和可用性
对象存储系统通过元数据来管理对象的属性和访问权限,支持快速检索和复杂查询。对象存储系统还支持大规模并发访问,适合处理海量数据和高访问负载的应用场景。
3)应用场景
-
云存储服务:云存储服务提供大规模、高可用的存储空间,支持数据的冗余和分布,如亚马逊S3、阿里云OSS等。
-
媒体存储和分发:对象存储适合存储和分发图片、视频、音频等多媒体内容,支持大规模并发访问和快速检索。
-
备份和归档:对象存储系统可以用于备份和归档数据,提供高效的数据保护和恢复,支持海量数据的存储和管理。
-
大数据和分析:对象存储适合存储和管理大规模的数据集,支持大数据分析和处理,如日志分析、数据挖掘等。
4、文件存储
1)定义
文件存储(File Storage)是一种将数据以文件的形式存储在存储介质上的方法。每个文件都有一个文件名,并存储在一个目录结构中,用户可以通过文件路径来访问和管理文件。这种存储方式类似于我们日常使用的文件柜,每个文件柜有多个文件夹,文件夹中有多个文件。
典型设备: FTP、NFS服务器
2)原理
文件存储的基本原理是将数据分割成文件,并通过文件系统进行管理。文件系统提供了一个抽象层,使用户可以通过简单的路径和文件名来访问数据,而不需要关心数据在物理存储介质上的具体位置。
文件系统通常采用树状目录结构来组织文件,根目录下可以有多个子目录,每个子目录下可以包含多个文件或其他子目录。文件系统通过索引和目录结构来快速定位文件,提高数据访问的效率。
文件存储系统支持多种操作,包括文件的创建、删除、读取、写入、复制、移动等。文件系统负责管理文件的存储空间分配和回收,保证数据的一致性和完整性。
3)应用场景
个人计算机:用户可以在个人计算机上存储文档、图片、音乐、视频等文件,通过文件系统进行管理和访问。
企业文件服务器:企业内部可以使用文件服务器进行文件共享和协作,支持多用户访问和权限管理,提高工作效率。
网络文件共享:通过网络文件系统协议(如NFS、SMB等),用户可以在不同设备之间共享文件,实现跨平台的数据访问。
备份和归档:文件存储系统可以用于备份和归档数据,提供数据的冗余和保护,确保数据的安全性和可靠性。
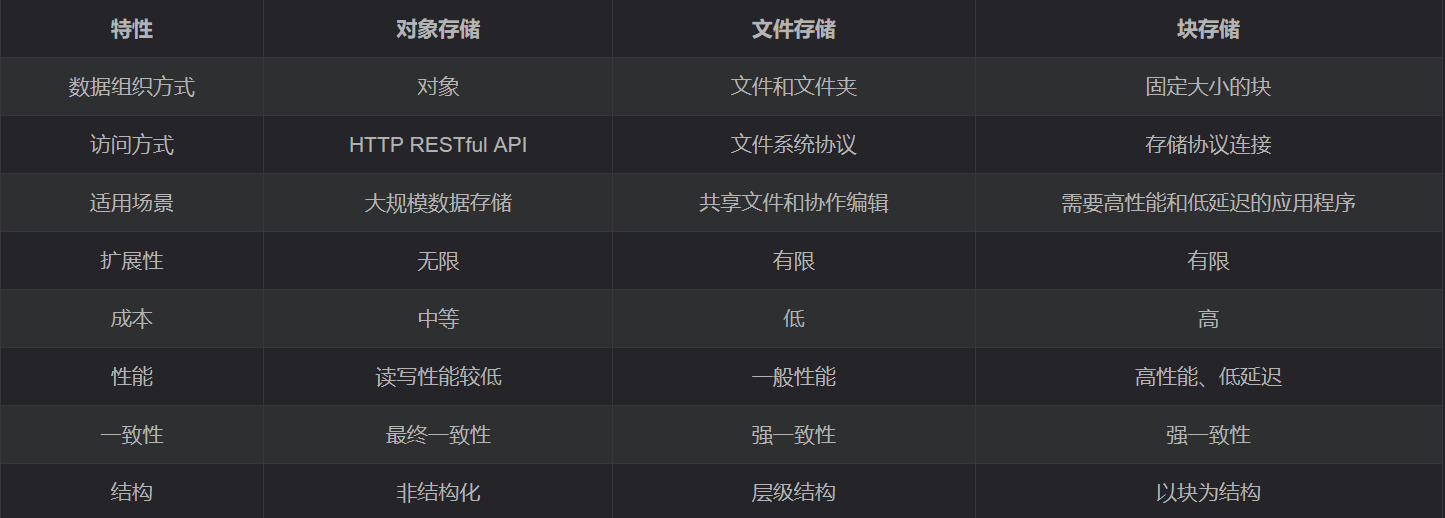
5、对别区别
二、ceph概述
1、概述
Ceph是一个统一的分布式存储系统,最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),随后贡献给开源社区。其设计初衷是提供较好的性能、可靠性和可扩展性。在经过多年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
Ceph是一个能提供文件存储 、块存储 和对象存储的分布式存储系统。它提供了一个可无限伸缩的Ceph存储集群。
高性能:
-
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
-
考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
-
能够支持上千个存储节点的规模。支持TB到PB级的数据
高可用
-
副本数可以灵活控制
-
支持故障域分隔,数据强一致性
-
多种故障场景自动进行修复自愈
-
没有单点故障,自动管理
高扩展性
-
去中心化
-
扩展灵活
-
随着节点增加,性能线性增长
特性丰富
-
支持三种存储接口:对象存储,块设备存储,文件存储
-
支持自定义接口,支持多种语言驱动
2、架构
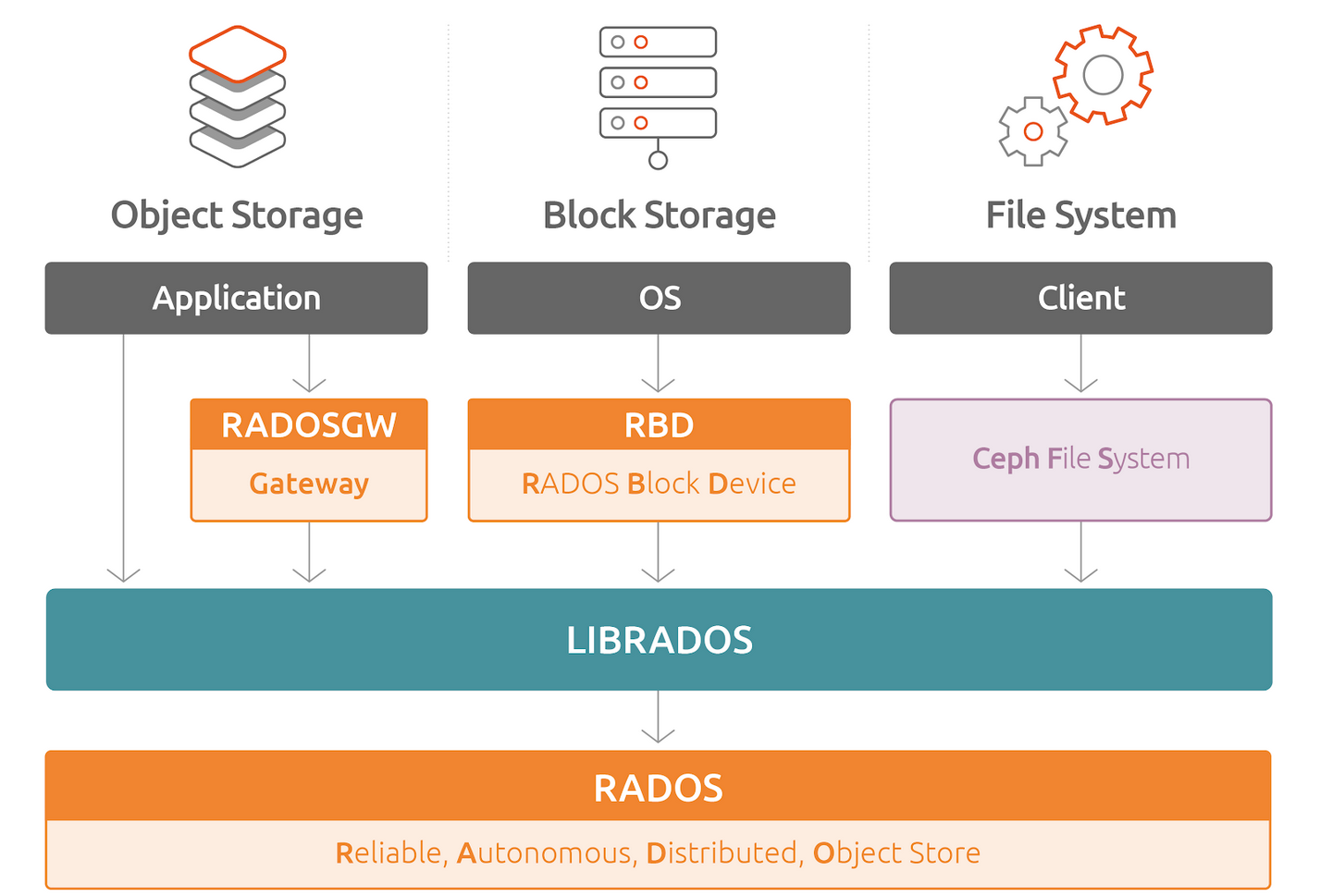
Ceph的底层是RADOS,RADOS本身也是分布式存储系统,Ceph所有的存储功能都是基于RADOS实现的。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,RedHat已经将RBD驱动集成在KVM/QEMU中,以提供虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
CephFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所有无需调用用户空间的librados库。它通过内核中的net模块来与RADOS进行交互。
3、核心组件
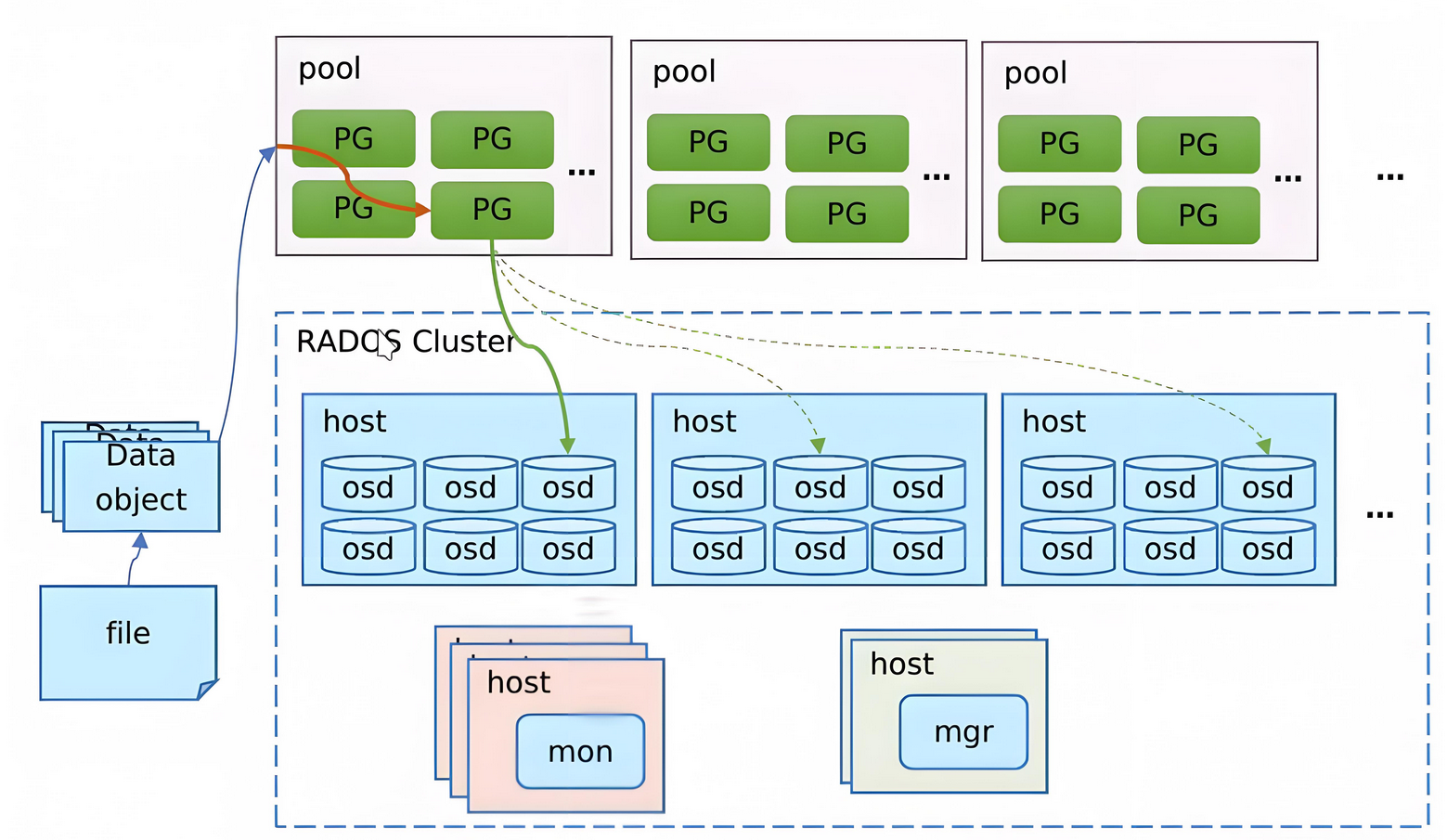
RADOS:RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作
Monitor:一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据(mon及mgr组成的monitor)
OSD:OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD
pool:资源池,管理了PG
PG:PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据
Object:Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据
三、ceph集群搭建
1、集群概述
Ceph集群包括Ceph OSD 、Ceph Monitor两种守护进程:
Ceph OSD(Object Storage Device):功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitor提供一些监控信息
Ceph Monitor:是一个监视器,监视Ceph集群状态和维护集群中的各种关系
2、环境说明就初始化
1)环境概述
本次实验总共需要4台机器,具体如下:
| 主机 | IP | 安装软件 | 磁盘 |
|---|---|---|---|
| node1 | 192.168.217.171 | ceph-deploy ceph ceph-radosgw | sda,sdb(5G) |
| node2 | 192.168.217.172 | ceph ceph-radosgw | sda,sdb(5G) |
| node3 | 192.168.217.173 | ceph ceph-radosgw | sda,sdb(5G) |
| client | 192.168.217.174 | ceph-common | sda |
2)环境初始化
0. 上传rpm包资源
1. 主机名
2. hosts文件
3. 防火墙
4. 时间同步
5. 配置yum源#!/bin/bash
# 1. 设置主机名
hostnamectl set-hostname $1
# 2. 修改hosts文件
echo 192.168.169.153 node1 >> /etc/hosts
echo 192.168.169.154 node2 >> /etc/hosts
echo 192.168.169.155 node3 >> /etc/hosts
echo 192.168.169.156 client >> /etc/hosts
# 3. 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
# 4. 配置yum源
cd /etc/yum.repos.d
rm -rf *
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
cat <<EOF > /etc/yum.repos.d/ceph.repo
[local_ceph]
name=local_ceph
baseurl=file:///root/ceph_soft
gpgcheck=0
enabled=1
EOF
yum clean all
yum makecache
yum install epel-release -y
# 5. 安装必要软件
yum install vim -y
yum install net-tools -y
yum install wget -y
yum install yum-utils -y
yum install ntp -y
# 6. 时间同步
systemctl enable ntpd --now
# 7. 重启
reboot3、集群部署
1. 配置免密登录node1免密node2,node3
2. 在node1上安装部署工具ceph-deploy
3. 在node1上创建集群
4. ceph集群节点安装ceph(node1,node2,node3)
5. 客户端安装ceph-common
6. 创建mon(监控)
7. 创建mgr(管理)
8. 创建osd(存储盘)1)配置免密登录node1免密node2,node3
以node1为部署配置节点,在node1上配置ssh等效性(要求ssh node1、node2、node3、client都要免密码)
说明:此步骤不是必要的,做此步骤的目的:
-
如果使用ceph-deploy来安装集群,密钥会方便安装
-
如果不使用ceph-deploy安装,也可以方便后面操作:比如同步配置文件
在node1上进行以下操作:
ssh-keygen -P '' -f /root/.ssh/id_rsa
ssh-copy-id -i root@node2
ssh-copy-id -i root@node3
ssh-copy-id -i root@client2)在node1上安装部署工具ceph-deploy
yum install createrepo -y
cd /root/ceph_soft
createrepo .
yum -y install ceph-deploy3)在node1上创建集群
# 创建一个集群配置目录,后续的大部分操作都会在此目录
mkdir /etc/ceph && cd /etc/ceph
# 创建集群
ceph-deploy new node1
ls
####################################################
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
# 说明:
# ceph.conf 集群配置文件
# ceph-deploy-ceph.log 使用ceph-deploy部署的日志记录
# ceph.mon.keyring mon的验证key文件此过程中可能遇到如下问题:
问题:安装完成ceph部署工具之后,执行ceph-deploy命令报错,执行python脚本导入pkg_resources模块不存在。
解决方法:
yum -y install python-setuptools


4)ceph集群节点安装ceph(node1,node2,node3)
前面准备环境时已经准备好了yum源,在这里**所有集群节点(不包括client)**都安装以下软件
yum -y install ceph ceph-radosgw
ceph -v
#############################
ceph version 13.2.6 (02899bfda814146b021136e9d8e80eba494e1126) mimic (stable)补充说明:
如果公网OK,并且网速好的话,可以用
ceph-deploy install node1 node2 node3命令来安装,但网速不好的话会比较坑所以这里我们选择直接用准备好的本地ceph源,然后
yum -y install ceph ceph-radosgw安装即可。
5)客户端安装ceph-common
yum -y install ceph-common6)创建mon(监控)
# 在node1上增加public网络用于监控,在[global]配置段里添加下面一句(直接放到最后一行)
vi /etc/ceph/ceph.conf
public network = 192.168.169.0/24 # 监控网络
# 监控节点初始化,并同步配置到所有节点(node1、node2、node3、不包括client)
ceph-deploy mon create-initial
ceph health
###################################################
HEALTH_OK # 状态health(健康)
# 将配置文件信息同步到所有节点
ceph-deploy admin node2 node3
ceph -s
###################################################
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK # 健康状态为OK
services:
mon: 1 daemons, quorum node1 # 1个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: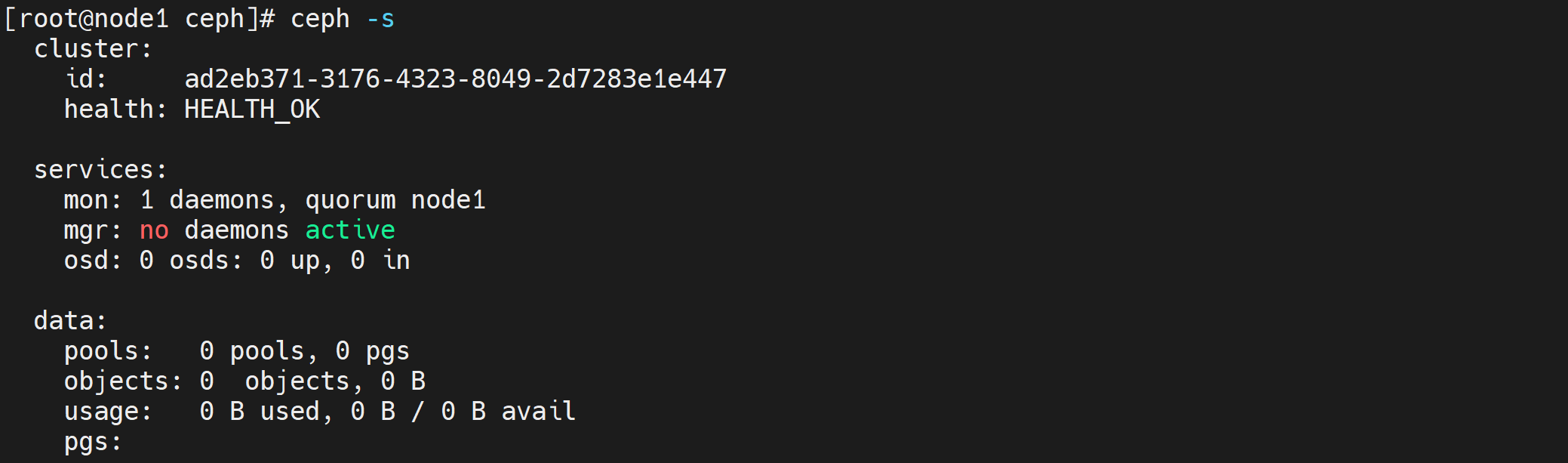
为了防止mon单点故障,你可以加多个mon节点(建议奇数个,因为有quorum仲裁投票)
ceph-deploy mon add node2
ceph-deploy mon add node3
ceph -s
##################################################
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK # 健康状态为OK
services:
mon: 3 daemons, quorum node1,node2,node3 # 3个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:问题描述:clock skew detected on mon.node2, mon.node3
在node1部署节点修改配置参数
vi /etc/ceph/ceph.conf 在global字段下添加: mon clock drift allowed = 2 mon clock drift warn backoff = 30向需要同步的mon节点推送配置文件
ceph-deploy --overwrite-conf config push node2 node3重启mon服务(centos7环境下)
systemctl restart ceph-mon.target验证
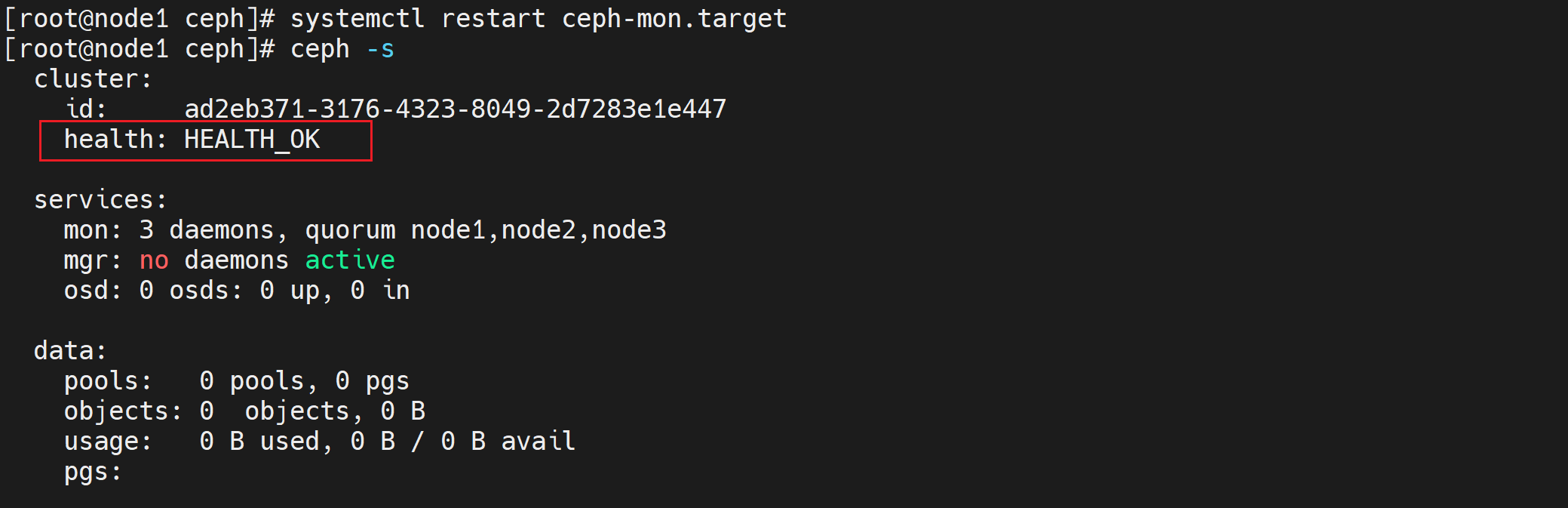
7)创建mgr(管理)
ceph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。
# 创建一个mgr
ceph-deploy mgr create node1
ceph -s
#################################################
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active) # node1为mgr
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: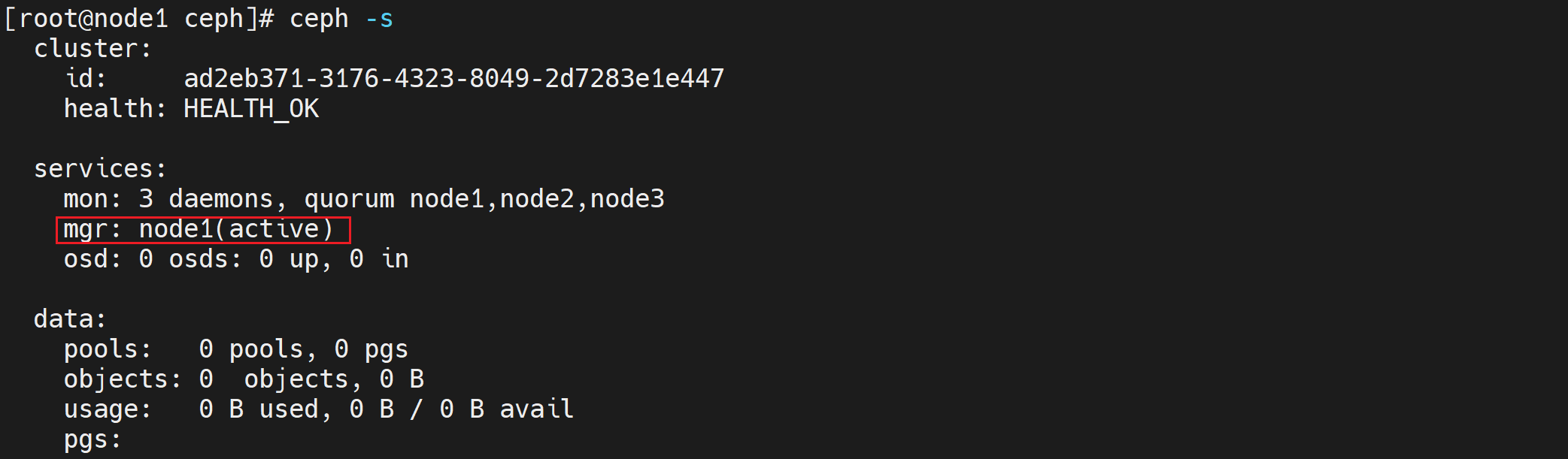
添加多个mgr可以实现HA
ceph-deploy mgr create node2
ceph-deploy mgr create node3
ceph -s
##################################################
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK # 健康状态为OK
services:
mon: 3 daemons, quorum node1,node2,node3 # 3个监控
mgr: node1(active), standbys: node2, node3 # 看到node1为主,node2,node3为备
osd: 0 osds: 0 up, 0 in # 看到为0个磁盘
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: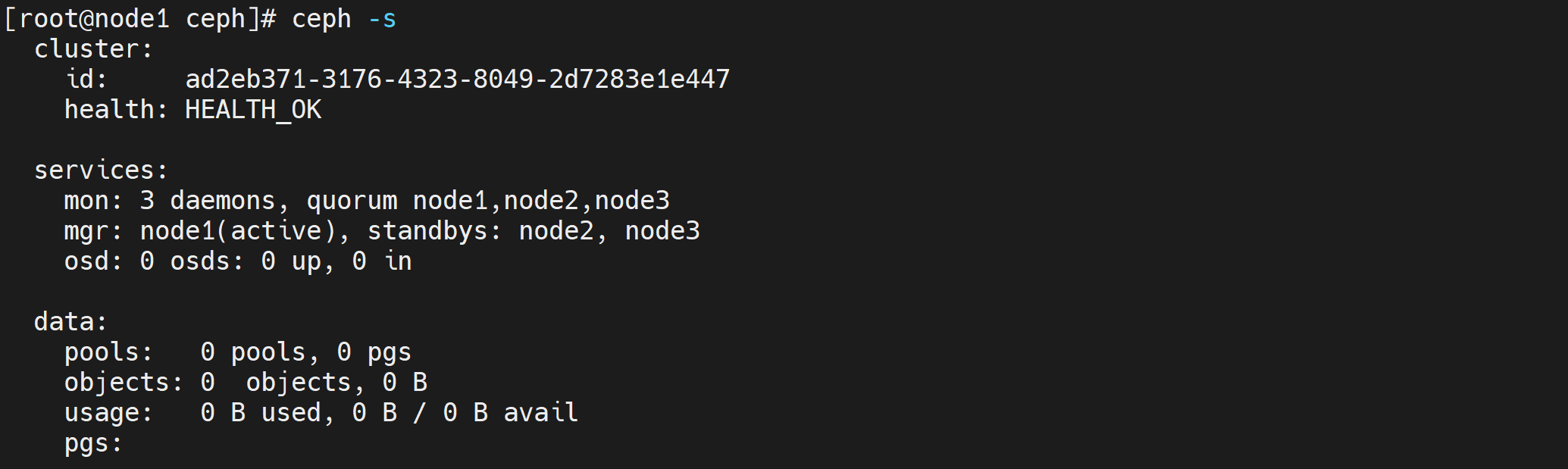
8)创建osd(存储盘)
列表所有节点的磁盘,都有sda和sdb两个盘,sdb为我们要加入分布式存储的盘
# 列表查看节点上的磁盘
ceph-deploy disk list node1
ceph-deploy disk list node2
ceph-deploy disk list node3
# zap表示干掉磁盘上的数据,相当于格式化
ceph-deploy disk zap node1 /dev/sdb
ceph-deploy disk zap node2 /dev/sdb
ceph-deploy disk zap node3 /dev/sdb
# 将磁盘创建为osd
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
ceph -s
##############################
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active), standbys: node2, node3
osd: 3 osds: 3 up, 3 in # 看到这里有3个osd
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 41 MiB used, 2.9 GiB / 3.0 GiB avail # 大小为3个磁盘的总和
pgs: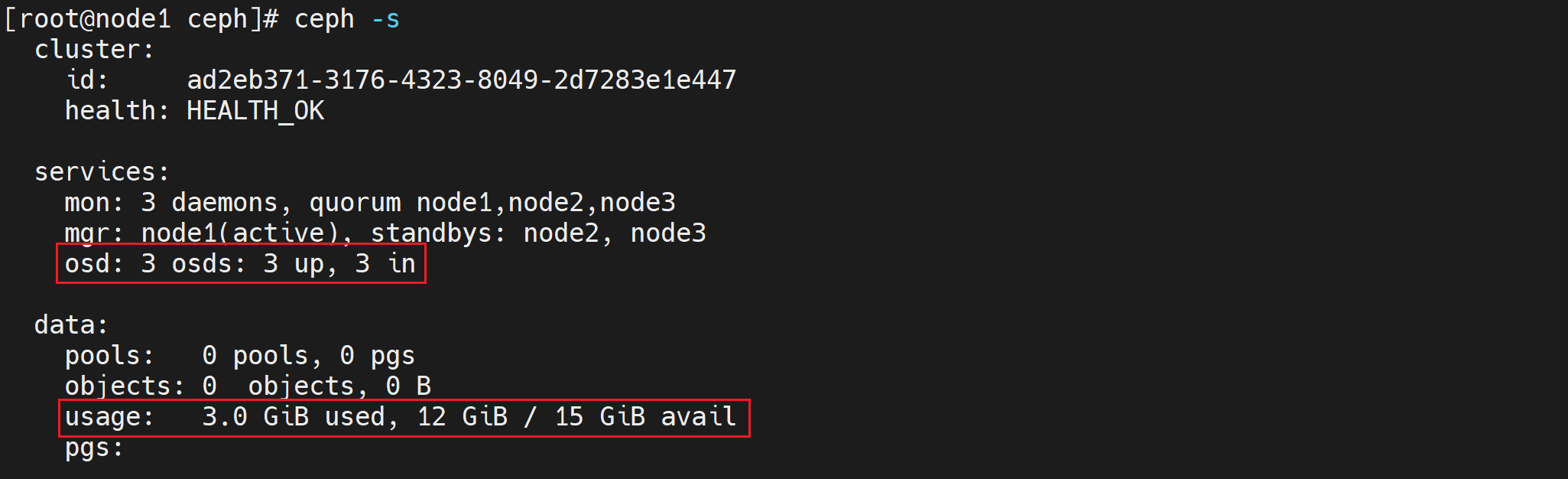
四、RADOS原生数据管理
1、概述
上面提到了RADOS也可以进行数据的存取操作,一般不直接使用它,但我们可以先用RADOS的方式来深入了解下ceph的数据存取原理
2、原理
要实现数据存取需要创建一个pool,创建pool要先分配PG。
如果客户端对一个pool写了一个文件,那么这个文件是如何分布到多个节点的磁盘上呢?
答案是通过CRUSH算法。
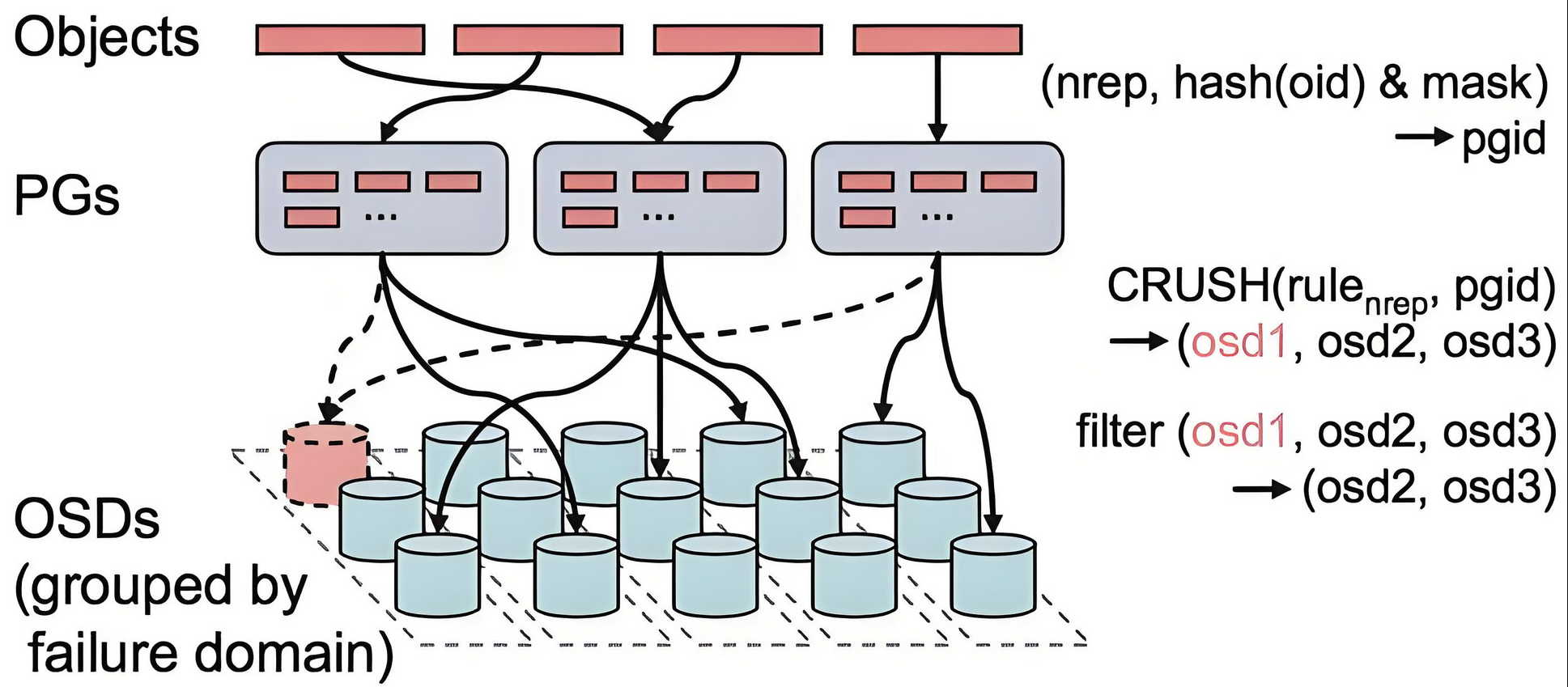
CRUSH算法
CRUSH(Controlled Scalable Decentralized Placement of Replicated Data)算法为可控的、可扩展的、分布式的副本数据放置算法的简称。
PG到OSD的映射的过程算法叫做CRUSH 算法。(一个Object需要保存三个副本,也就是需要保存在三个osd上)。
CRUSH算法是一个伪随机的过程,它可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。
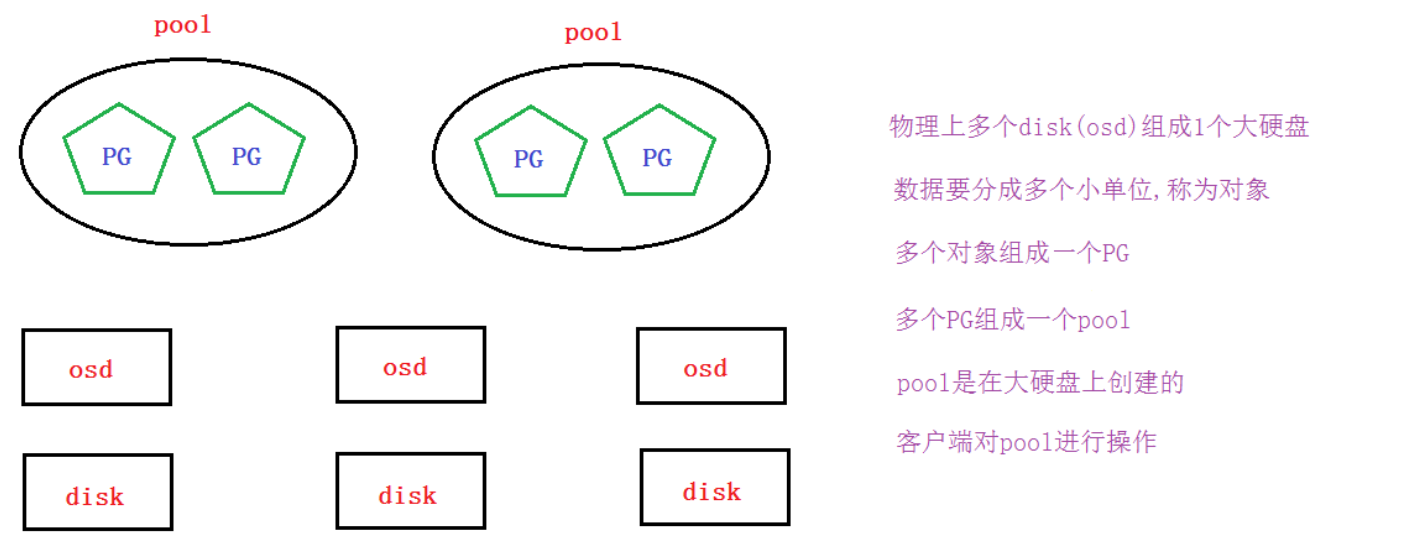
客户端直接对pool操作(但文件存储,块存储,对象存储我们不这么做)
pool里要分配PG
PG里可以存放多个对象
对象就是由客户端写入的数据分离的单位
CRUSH算法将客户端写入的数据映射分布到OSD,从而最终存放到物理磁盘上(这个具体过程是抽象的,我们运维工程师可以不用再深挖,因为分布式存储对于运维工程师来说就是一个大硬盘)
3、创建pool
创建test_pool,指定pg数为128
ceph osd pool create test_pool 128查看pg数量,可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
ceph osd pool get test_pool pg_num说明:pg数与osd数量有关系
pg数为2的倍数,一般5个以下osd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低)
可以使用
ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
4、存储数据
把本机的/etc/fstab文件上传到test_pool,并取名为newfstab
rados put newfstab /etc/fstab --pool=test_pool查看数据
# 数据列表
rados -p test_pool ls
# 从pool中获取对象内容(下载)
# 语法:rados -p pool名 get 获取的对象名字 获取的内容保存的文件名
rados -p test_pool get newfstab fstab01删除数据
rados rm newfstab --pool=test_pool5、删除pool
# 在部署节点node1上增加参数允许ceph删除pool
vi /etc/ceph/ceph.conf
##############################
# 文件内容最后一行添加下面的配置
mon_allow_pool_delete = true
# 修改了配置,要同步到其它集群节点
ceph-deploy --overwrite-conf admin node2 node3
# 重启监控服务
systemctl restart ceph-mon.target
# 删除时pool名输两次,后再接`--yes-i-really-really-mean-it`参数就可以删除了
ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it五、文件存储
1、概述
要运行Ceph文件系统,你必须先创建至少带一个mds的Ceph存储集群。Ceph MDS:Ceph文件存储类型存放与管理元数据metadata的服务
Ceph块设备和Ceph对象存储不使用MDS
2、创建文件存储
1. 在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)
2. 一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们
3. 创建Ceph文件系统,并确认客户端访问的节点
4. 客户端准备验证key文件
5. 客户端挂载(挂载ceph集群中跑了mon监控的节点,mon监控为6789端口)
6. 验证# 在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)(注意该命令的执行位置需要在/etc/ceph目录下)
ceph-deploy mds create node1 node2 node3
#一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们
ceph osd pool create cephfs_pool 128
####################################
pool 'cephfs_pool' created
ceph osd pool create cephfs_metadata 64
###################################
pool 'cephfs_metadata' created
ceph osd pool ls |grep cephfs
###################################
cephfs_pool
cephfs_metadata
# 创建Ceph文件系统,并确认客户端访问的节点,cephfs为文件系统的名称
ceph fs new cephfs cephfs_metadata cephfs_pool
ceph fs ls
################################################
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_pool ]
ceph mds stat
################################################
# 这里看到node3为up状态
cephfs-1/1/1 up {0=ceph_node3=up:active}, 2 up:standby
# 客户端准备验证key文件
cat /etc/ceph/ceph.client.admin.keyring
###############################
[client.admin]
key = AQAOEuFnjDwUHhAAap8d0fqHfYkdEwskjRaMQQ== # 后面的字符串就是验证需要的
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
# 在客户端上任意目录创建一个文件记录密钥字符串(client上进行操作)
vi /root/admin.key # 创建一个密钥文件,复制粘贴上面得到的字符串
#################################
AQAOEuFnjDwUHhAAap8d0fqHfYkdEwskjRaMQQ==
# 客户端挂载(挂载ceph集群中跑了mon监控的节点,mon监控为6789端口)(在client中进行操作)
mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=/root/admin.key
# 验证
df -h |tail -1
####################################
node1:6789:/ 3.8G 0 3.8G 0% /mnt # 大小不用在意,场景不一样,pg数,副本数都会影响
3、测试验证
进入到mnt目录中添加数据进行测试:
cd /mnt
echo 123 > abc.txt
cat abc.txt
4、删除文件存储
1. 在客户端上删除数据,并umount所有挂载
2. 停掉所有节点的mds(只有停掉mds才能删除文件存储)
3. 回到集群任意一个节点上(node1、node2、node3其中之一)删除
4. 再次mds服务再次启动# 在客户端上删除数据,并umount所有挂载
rm -rf /mnt/*
umount /mnt/
# 停掉所有节点的mds(只有停掉mds才能删除文件存储)
# node1
systemctl stop ceph-mds.target
# node2
systemctl stop ceph-mds.target
# node3
systemctl stop ceph-mds.target
# 回到集群任意一个节点上(node1、node2、node3其中之一)删除
# 删除文件系统
ceph fs rm cephfs --yes-i-really-mean-it
# 删除池
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
# 再次mds服务再次启动
# node1
systemctl start ceph-mds.target
# node2
systemctl start ceph-mds.target
# node3
systemctl start ceph-mds.target如果要客户端删除,需要在node1上
ceph-deploy admin client同步配置才可以
六、对象存储
1、概述
RadosGW是对象存储(OSS,Object Storage Service)的一种访问实现方式,RADOS网关也称为Ceph对象网关、RadosGW、RGW,是一种服务,使客户端能够利用标准对象存储API来访问Ceph集群,它支持AWS S3和Swift API,在 ceph 0.8版本之后使用Civetweb(https:/lgithub.com/civetweb/civetweb)的 web服务器来响应api请求,客户端使用http/https协议通过RESTful API与RGW通信,而RGW则通过librados与ceph集群通信,RGW客户端通过s3或者swift api使用RGW用户进行身份验证,然后RGW网关代表用户利用cephx与ceph存储进行身份验证。 说明:S3由Amazon于2006年推出,全称为Simple Storage Service,S3定义了对象存储,是对象存储事实上的标准,从某种意义上说,S3就是对象存储,对象存储就是S3,它是对象存储市场的霸主,后续的对象存储都是对S3的模仿。
2、ceph网关操作
1. 在node1上创建rgw
2. 在客户端测试连接对象网关# 在node1上创建rgw
ceph-deploy rgw create node1
lsof -i:7480 # 或者也可以用ss -lntp |grep 7480
# 在客户端测试连接对象网关
# 创建一个测试用户,需要提前在部署节点使用ceph-deploy admin client同步配置文件给client
# node1上操作
ceph-deploy admin client
# client上操作
radosgw-admin user create --uid="testuser" --display-name="First User"
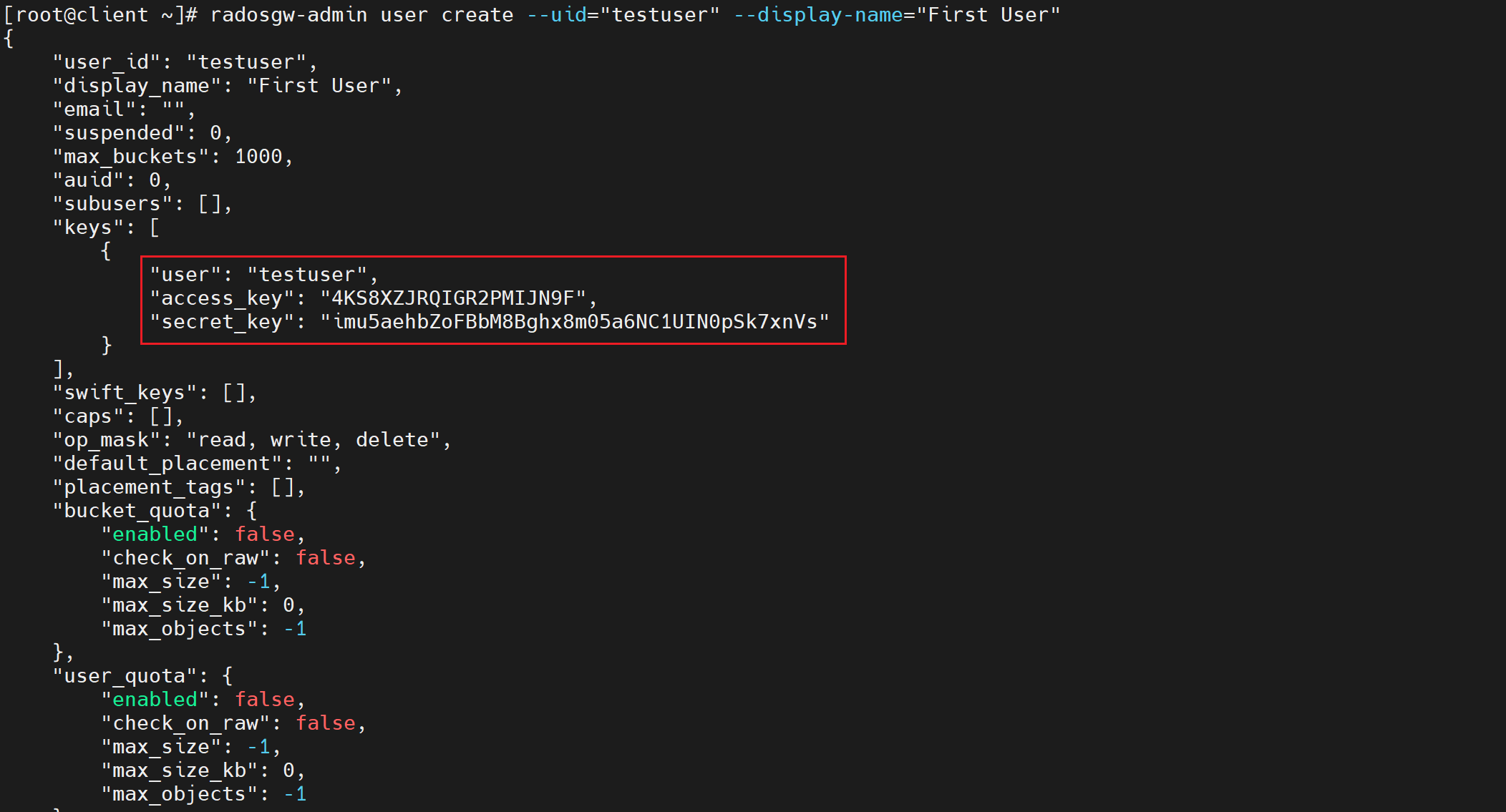
上面一大段主要有用的为access_key与secret_key,用于连接对象存储网关
3、客户端网关操作
AmazonS3是一种面向Internet的对象存储服务.我们这里可以使用s3工具连接ceph的对象存储进行操作
1. 客户端安装s3cmd工具,并编写ceph连接配置文件
2. 命令测试# 客户端安装s3cmd工具,并编写ceph连接配置文件
yum -y install s3cmd
# 创建并编写下面的文件,key文件对应前面创建测试用户的key
vi /root/.s3cfg
#######################################
[default]
access_key = 8DWBPXUND84H8ERE4KZ3
secret_key = uoW0oBx1NcxX19aigLD7uJQ7jZLVfIVVu8L0dF6i
host_base = 192.168.169.153:7480
host_bucket = 192.168.169.153:7480/%(bucket)
cloudfront_host = 192.168.169.153:7480
use_https = False
# 命令测试
# 列出bucket
s3cmd ls
# 建一个桶
s3cmd mb s3://test_bucket
# 上传文件到桶
s3cmd put /etc/fstab s3://test_bucket
#################################
upload: '/etc/fstab' -> 's3://test_bucket/fstab' [1 of 1]
501 of 501 100% in 1s 303.34 B/s done
# 下载到当前目录
s3cmd get s3://test_bucket/fstab
# 更多命令请见参考命令帮助
s3cmd --help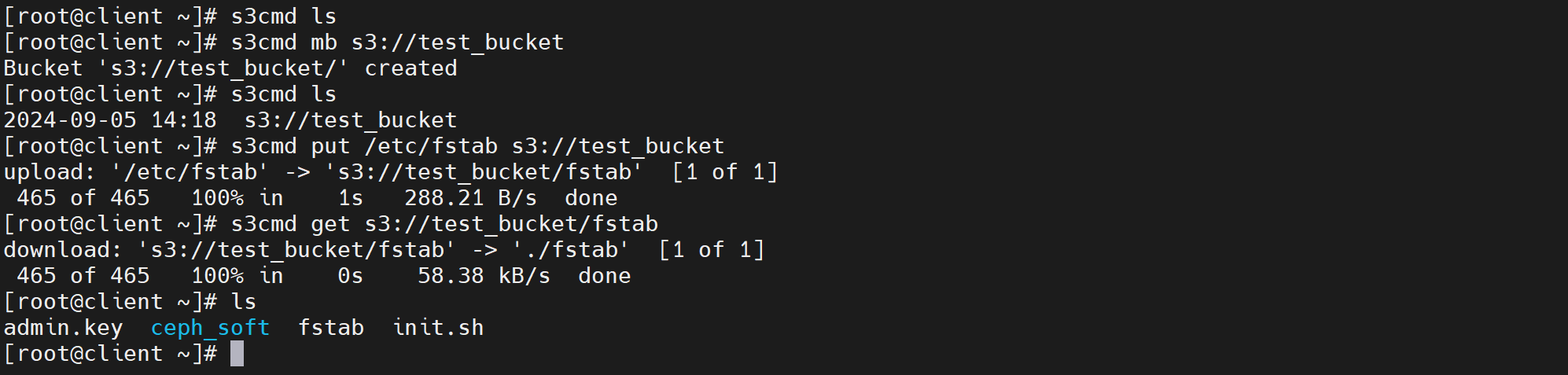
七、综合练习
课堂小结
-
存储相关概念及分布式存储介绍
-
ceph集群搭建实验
-
ceph文件存储实验
-
ceph块存储实验
-
ceph对象存储实验
课后作业
-
完成课堂的案例及练习
-
将今天的内容整理为思维导图的形式
-
完成以下需求
1、分布式存储接触过吗,搭过ceph吗?ceph有哪些数据冗余方式;删副本数据如何冗余?
2、您是用什么方式部署的Ceph?
3、ceph的三副本模式怎么管理?
4、ceph的副本模式是怎么实现数据冗余的?
扩展内容
无