简介
本文围绕Haar-like特征 、Adaboost算法 与级联分类器三大核心,系统解析Viola-Jones人脸检测器的工作原理------从特征量化、弱分类器提升,到积分图加速与级联筛选的完整逻辑。结合Python实践视角,揭示其"快速检测"的核心密码,帮助读者理解经典人脸检测算法的设计思路与工程实现。
1 核心框架:Haar分类器的四大组件
Haar分类器的本质是**"特征提取+加速计算+分类器提升+快速筛选"**的组合框架,可简化为公式:Haar分类器=Haar-like特征+积分图+AdaBoost+级联结构\text{Haar分类器} = \text{Haar-like特征} + \text{积分图} + \text{AdaBoost} + \text{级联结构}Haar分类器=Haar-like特征+积分图+AdaBoost+级联结构
其核心逻辑可拆解为四步:
- 特征检测:用Haar-like特征量化人脸区域的像素差异;
- 加速计算:通过积分图快速求解Haar特征值,避免重复计算;
- 强分类器构建:用Adaboost将多个弱分类器加权融合,提升分类能力;
- 快速筛选 :用级联结构将强分类器按"简单到复杂"排列,快速排除非人脸区域。
2 技术溯源:从Viola-Jones到OpenCV的Haar分类器
人脸检测的里程碑式突破来自2001年Viola与Jones的两篇论文------《Rapid Object Detection using a Boosted Cascade of Simple Features》与《Robust Real-Time Face Detection》。他们的创新点在于:
- 不直接使用传统小波特征,而是设计了针对人脸的Haar-like特征(如眼睛与脸颊的明暗差异);
- 将Adaboost训练的强分类器级联,实现"快速拒真"(非人脸区域 early reject);
- 用积分图 将Haar特征的计算复杂度从O(n)O(n)O(n)降至O(1)O(1)O(1)。
这一算法被称为Viola-Jones检测器。后来Rainer Lienhart与Jochen Maydt扩展了Haar特征的类型(如45度旋转特征),最终形成OpenCV中广泛使用的Haar分类器。
而Adaboost本身是1995年Freund与Schapire提出的Boosting改进算法,核心思想是**"弱分类器加权投票"**------通过调整样本权重(错分样本权重更高),让后续分类器聚焦难例,最终融合成强分类器("三个臭皮匠顶个诸葛亮")。
3 Haar-like特征:人脸特征的量化表达
特征是分类器的"输入语言"。在人脸检测中,我们用滑动子窗口遍历图像:子窗口每到一个位置,计算该区域的Haar特征,再用级联分类器判断是否为人脸。
3.1 什么是Haar-like特征?
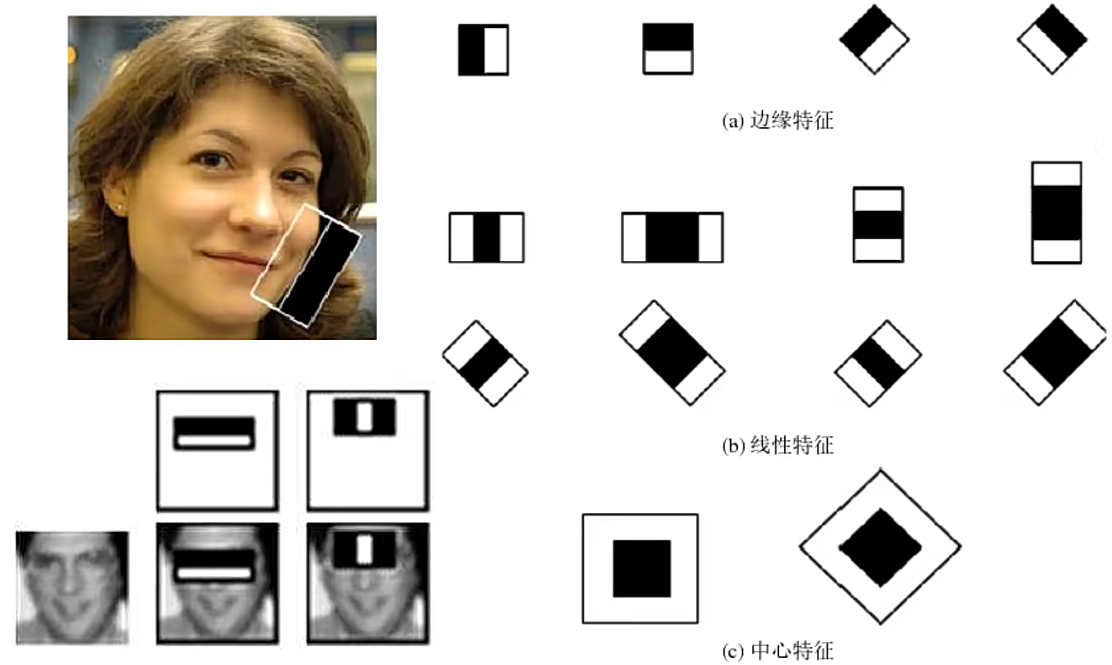
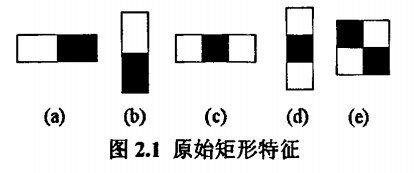
Haar-like特征是带黑白矩形块的模板,通过计算"白色区域像素和 - 黑色区域像素和"得到特征值。例如:
- 两矩形特征:用于捕捉眼睛(黑)与脸颊(白)的明暗差异;
- 三矩形特征:用于捕捉鼻梁(白)与两侧眼睛(黑)的差异;
- 对角线特征:用于捕捉45度方向的纹理(如眼角)。
Viola最初提出的基础特征(如两矩形、三矩形)与Rainer扩展的旋转特征,共同构成了Haar分类器的特征库
3.2 特征的意义
将Haar模板覆盖在人脸区域时,得到的特征值与人脸的结构高度相关(如眼睛区域比脸颊暗,特征值为负);而覆盖非人脸区域时,特征值会显著不同。通过这种量化方式,分类器能区分"人脸"与"非人脸"。
4 Adaboost算法:弱分类器的强联合
Adaboost的核心是**"迭代提升弱分类器"**------每轮训练一个基于单特征的弱分类器(对当前样本权重敏感),最终将所有弱分类器加权融合成强分类器。
4.1 弱分类器的形式
Haar分类器中的弱分类器非常简单:基于单个Haar特征,通过阈值判断样本类别。其数学表达为:hj(x)=pj⋅sign(fj(x)−θj)h_j(x) = p_j \cdot \text{sign}(f_j(x) - \theta_j)hj(x)=pj⋅sign(fj(x)−θj)其中:
- fj(x)f_j(x)fj(x):第jjj个Haar特征的值;
- θj\theta_jθj:该特征的分类阈值;
- pjp_jpj:不等式方向(+1+1+1表示"fj(x)>θjf_j(x) > \theta_jfj(x)>θj为正类",−1-1−1相反);
- sign(⋅)\text{sign}(\cdot)sign(⋅):符号函数(正返回+1+1+1,负返回−1-1−1)。
4.2 Adaboost的迭代流程
Adaboost的训练过程可概括为:
- 初始化样本权重 :所有样本权重相等,D1(i)=1/ND_1(i) = 1/ND1(i)=1/N(NNN为样本数);
- 迭代训练弱分类器 :对第ttt轮,a. 用当前权重DtD_tDt训练弱分类器hth_tht;b. 计算hth_tht的误差率ϵt=∑i=1NDt(i)⋅ht(xi)eqyi\epsilon_t = \sum_{i=1}^N D_t(i) \cdot h_t(x_i) eq y_iϵt=∑i=1NDt(i)⋅ht(xi)eqyi(yiy_iyi为真实标签);c. 计算弱分类器的权重αt=12ln(1−ϵtϵt)\alpha_t = \frac{1}{2} \ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right)αt=21ln(ϵt1−ϵt)(误差越小,权重越大);d. 更新样本权重:Dt+1(i)=Dt(i)⋅exp(−αtyiht(xi))ZtD_{t+1}(i) = \frac{D_t(i) \cdot \exp(-\alpha_t y_i h_t(x_i))}{Z_t}Dt+1(i)=ZtDt(i)⋅exp(−αtyiht(xi)),其中ZtZ_tZt是归一化常数(确保权重和为1);
- 融合强分类器 :H(x)=sign(∑t=1Tαtht(x))H(x) = \text{sign}\left(\sum_{t=1}^T \alpha_t h_t(x)\right)H(x)=sign(∑t=1Tαtht(x))。
4.3 Adaboost的变种
常见的Adaboost变种有三种:
- Discrete Adaboost :弱分类器输出+1/−1+1/-1+1/−1(如上述流程);
- Gentle Adaboost:弱分类器输出实数,权重更新更平滑;
- Real Adaboost:弱分类器输出概率(而非硬标签),更适合概率建模。
Rainer在论文3中对比了三者的效果,发现Real Adaboost在人脸检测中表现更优(误识率更低)。
5 级联分类器:快速筛选的决策链
单独的强分类器虽准确,但计算成本高。级联分类器的设计目标是**"快速排除非人脸区域"**------用一系列"简单→复杂"的强分类器依次筛选, early reject 大部分非人脸,只让疑似区域进入后续复杂计算。
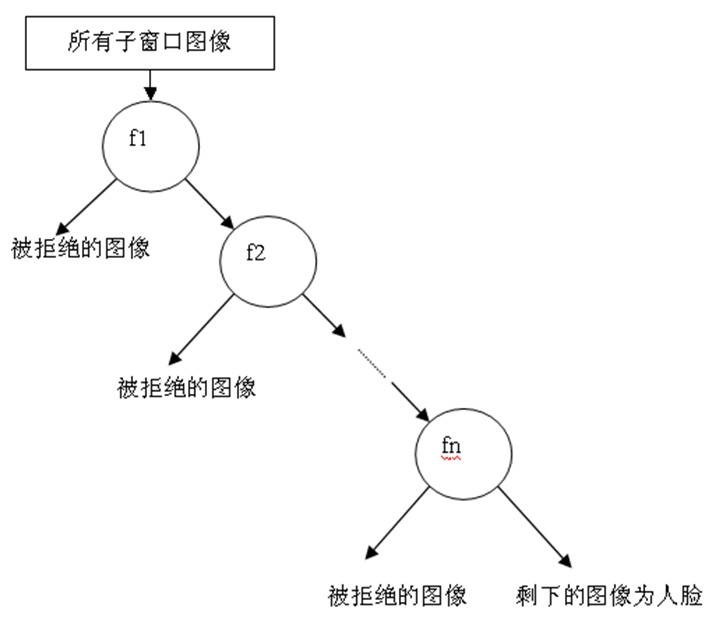
5.1 级联的结构
级联分类器是**"退化的决策树"**:每个节点是一个强分类器,若样本被拒(判定为非人脸),直接淘汰;若通过,进入下一个更强的分类器。
5.2 级联的策略
训练时,每个强分类器需满足:
- 高检测率 (≥99%\geq 99\%≥99%):尽量不遗漏人脸;
- 低误识率 (≤50%\leq 50\%≤50%):允许部分非人脸通过。
假设级联有TTT个强分类器,总检测率为(单检测率)T(\text{单检测率})^T(单检测率)T,总误识率为(单误识率)T(\text{单误识率})^T(单误识率)T。例如:
- 20个强分类器的总检测率:0.9920≈98%0.99^{20} \approx 98\%0.9920≈98%(几乎不丢人脸);
- 总误识率:0.520≈0.0001%0.5^{20} \approx 0.0001\%0.520≈0.0001%(几乎没有假阳性)。
这种"简单先筛、复杂后判"的策略,让检测速度提升了几个数量级。
5.3 多尺度检测
人脸在图像中的大小不一,因此需要多尺度检测:
- 策略1:固定子窗口大小,缩放图像(效率低,需重复计算积分图);
- 策略2:固定图像大小,缩放子窗口(更高效,只需计算一次积分图)。
OpenCV中默认使用策略2,通过扩大子窗口的尺寸(如从20×20到40×40),覆盖不同大小的人脸。
6 积分图:Haar特征的加速引擎
Haar特征的计算依赖区域像素和 ,直接计算每个区域的和需O(w×h)O(w \times h)O(w×h)时间(w,hw,hw,h为区域宽高)。而积分图(Integral Image)能将区域和的计算降至O(1)O(1)O(1),是Haar分类器快速检测的关键。
6.1 积分图的定义
积分图是与原始图像同尺寸的二维数组,其中(x,y)(x,y)(x,y)位置的值是原始图像左上角到(x,y)(x,y)(x,y)的像素和 :SAT(x,y)=∑i=0x∑j=0yI(i,j)SAT(x,y) = \sum_{i=0}^x \sum_{j=0}^y I(i,j)SAT(x,y)=i=0∑xj=0∑yI(i,j)其中SATSATSAT(Summed Area Table)是积分图的缩写,I(i,j)I(i,j)I(i,j)是原始图像在(i,j)(i,j)(i,j)处的像素值。
6.2 区域和的快速计算
对于任意矩形区域(左上角(x1,y1)(x_1,y_1)(x1,y1),右下角(x2,y2)(x_2,y_2)(x2,y2)),其像素和可通过积分图的四个角点值计算:RecSum=SAT(x2,y2)−SAT(x1−1,y2)−SAT(x2,y1−1)+SAT(x1−1,y1−1)RecSum = SAT(x_2,y_2) - SAT(x_1-1,y_2) - SAT(x_2,y_1-1) + SAT(x_1-1,y_1-1)RecSum=SAT(x2,y2)−SAT(x1−1,y2)−SAT(x2,y1−1)+SAT(x1−1,y1−1)
例如,两矩形Haar特征(白色区域AAA,黑色区域BBB)的特征值为:f=RecSum(A)−RecSum(B)f = RecSum(A) - RecSum(B)f=RecSum(A)−RecSum(B)
6.3 45度旋转特征的积分图
对于Rainer扩展的45度旋转特征(如对角线矩形),需要旋转积分图(Rotated Integral Image),其定义与普通积分图类似,只是求和方向变为45度。
7 总结:Haar分类器的优势与局限
Haar分类器的核心优势是**"快"**,主要来自三点:
- 特征简单:Haar特征只需计算区域和,复杂度低;
- 积分图加速 :将特征计算从O(n)O(n)O(n)降至O(1)O(1)O(1);
- 级联筛选:early reject 90%以上的非人脸区域,减少无效计算。
但其局限性也明显:
- 特征表达能力弱:无法捕捉复杂纹理(如遮挡、表情变化);
- 对光照敏感:Haar特征依赖明暗差异,强光/阴影下检测率下降;
- 精度不如深度学习:与CNN(如MTCNN、RetinaFace)相比,误识率更高。
尽管如此,Haar分类器仍是**"轻量级实时检测"**的首选(如嵌入式设备、低算力场景),也是理解人脸检测原理的经典案例。
8 Python实践:用OpenCV实现Haar人脸检测
OpenCV内置了训练好的Haar分类器(如haarcascade_frontalface_default.xml),只需几行代码即可实现人脸检测:
python
import cv2
# 加载Haar分类器(需提前下载xml文件)
face_cascade = cv2.CascadeClassifier('image/haarcascade_frontalface_default.xml')
# 读取图像并转灰度(Haar特征基于灰度图)
img = cv2.imread('image/Lenna.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸(参数:灰度图、缩放因子、最小邻域数)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
# 画框标注人脸
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果
cv2.imshow('Faces Detected', img)
cv2.waitKey(0)
cv2.destroyAllWindows()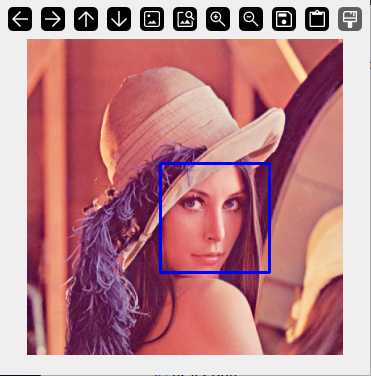
获取更多资料
欢迎下载学习资料,包含:机器学习,深度学习,大模型,CV方向,NLP方向,kaggle大赛,实战项目、自动驾驶等。
"点击" 免费获取 。