PyTorch实战(17)------神经风格迁移
-
- [0. 前言](#0. 前言)
- [1. 神经风格迁移原理](#1. 神经风格迁移原理)
-
- [1.1 内容损失](#1.1 内容损失)
- [1.2 风格损失](#1.2 风格损失)
- [1.3 神经风格迁移](#1.3 神经风格迁移)
- [2. 使用 PyTorch 实现神经风格迁移](#2. 使用 PyTorch 实现神经风格迁移)
-
- [2.1 加载内容和风格图像](#2.1 加载内容和风格图像)
- [2.2 加载预训练 VGG19 模型](#2.2 加载预训练 VGG19 模型)
- [2.3 构建神经风格迁移模型](#2.3 构建神经风格迁移模型)
- [2.4 训练风格迁移模型](#2.4 训练风格迁移模型)
- [3. 风格迁移系统超参数调优](#3. 风格迁移系统超参数调优)
- 小结
- 系列链接
0. 前言
我们已经学习了如何使用 PyTorch 构建生成模型,通过在文本和音乐数据上进行无监督训练,构建了能够生成文本和音乐的机器学习模型。本节我们将继续探索生成建模,将类似的方法应用于图像数据。
我们将混合两张不同图像A和B的不同特征,生成包含图像 a 内容与图像 b 风格的结果图像 c。这项任务通常被称为神经风格迁移 (Neural Style Transfer),本质上我们是把图像 b 的风格迁移到图像 a 上以获得图像 c。
在下图中,将 B、C、D 左下角子图(风格图像)中的风格迁移到图像 A (内容图像)中的内容之上,得到融合结果图像。

在本节中,我们首先简要探讨如何解决这一问题,并理解风格迁移背后的实现原理。随后,我们将使用 PyTorch 框架实现神经风格迁移。通过这个实现过程,还将深入分析不同参数对风格迁移效果的影响。通过本节的学习,将了解神经风格迁移的核心概念,并能够使用 PyTorch 构建风格迁移模型。
1. 神经风格迁移原理
1.1 内容损失
卷积神经网络 (Convolutional Neural Network, CNN)在图像分类、目标检测等计算机视觉任务中表现卓越,其核心优势在于卷积层能够有效学习空间特征表示。以猫狗分类器为例,CNN 模型通过提取高层特征,既能捕捉图像内容本质,又能识别犬类特征与猫科特征的差异。我们将利用图像分类 CNN 的这种特性来理解图像内容。
VGG是强大的图像分类模型。我们将使用 VGG 的卷积部分(不含全连接层)从图像中提取内容相关特征。
每个卷积层会产生 N N N 个大小为 X × Y X\times Y X×Y 的特征图。例如,假设有一张单通道(灰度)的输入图像,大小为 (3,3),并且使用一个卷积层,该层的输出通道数为 3,卷积核大小为 (2,2),步幅为 (1,1),没有填充。这个卷积层将生成 3 张每张大小为 2 x 2 的特征图,在这种情况下, X = 2 X=2 X=2, Y = 2 Y=2 Y=2。
我们可以将卷积层生成的 N N N 张特征图表示为一个大小为 N × M N \times M N×M 的二维矩阵,其中 M = X × Y M=X\times Y M=X×Y。通过将每个卷积层的输出定义为二维矩阵,我们可以为每个卷积层定义对应的损失函数。
这个损失函数称为内容损失 (content loss),它是卷积层目标输出和预测输出之间的平方损失,如下图所示,其中 N = 3 N=3 N=3, X = 2 X=2 X=2, Y = 2 Y=2 Y=2:
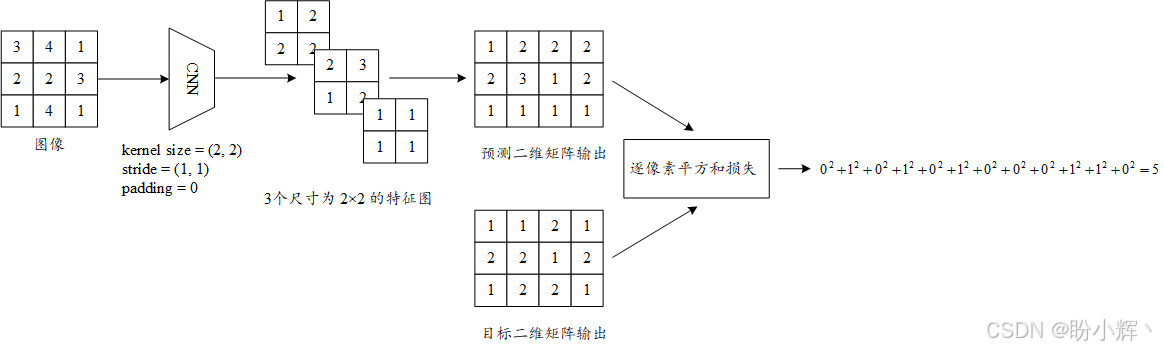
如图所示,输入图像经过卷积层处理后生成了三个 2 × 2 的特征图。这些特征图被重组为 3×4 的矩阵,该矩阵将与目标输出进行比对------目标输出由内容图像 a 通过相同流程生成。通过计算像素级平方和损失(我们称之为内容损失),即可完成内容特征的量化对比。
1.2 风格损失
为提取图像风格特征,我们将使用 Gram 矩阵 (gram matrix),该矩阵通过降维后的二维矩阵行向量内积运算构建:
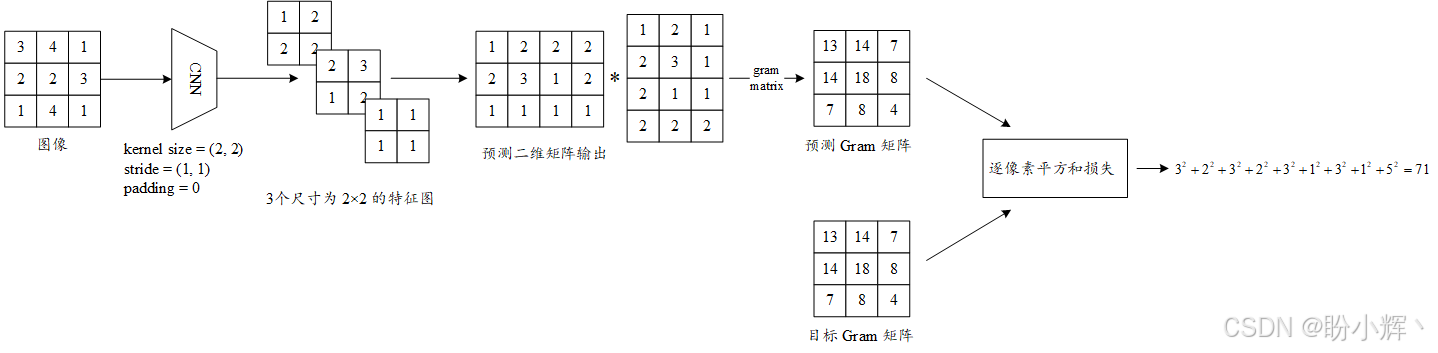
Gram 矩阵承载着不同卷积特征图之间的相关性(如上图所示的三个特征图)。如果预测 Gram 矩阵与目标 Gram 矩阵接近,那么意味着这两个矩阵中的三个卷积特征图之间的相关性(而非绝对值)是相似的。相关性表示的是像素之间的关系,而不是像素的绝对值。因此,Gram 矩阵捕捉了图像的风格或纹理的这种关系。
相较于内容损失计算,Gram 矩阵运算是此处唯一新增的步骤。值得注意的是,像素级平方和损失的输出值通常远大于内容损失,因此需要通过除以 N × X × Y N×X×Y N×X×Y (特征图数量×长度×宽度)进行归一化处理。这种标准化方法还能确保不同卷积层(各层的 N N N、 X X X、 Y Y Y 参数不同)的风格损失指标具有可比性。
1.3 神经风格迁移
理解了内容损失和风格损失的概念后,接下来继续介绍神经风格迁移:
对于给定的 VGG (或其他 CNN )网络,我们需要定义网络中哪些卷积层应附加内容损失。同样地,我们也要确定哪些卷积层用于计算风格损失。
一旦确定了这些卷积层,首先将内容图像输入网络,并在需要计算内容损失的卷积层处记录其预期的卷积输出(二维矩阵)。
接下来,我们将风格图像传入网络,并在卷积层中计算 Gram 矩阵。
例如,在下图中,内容损失将在第二和第三卷积层计算,而风格损失则在第二、第三和第五卷积层计算:
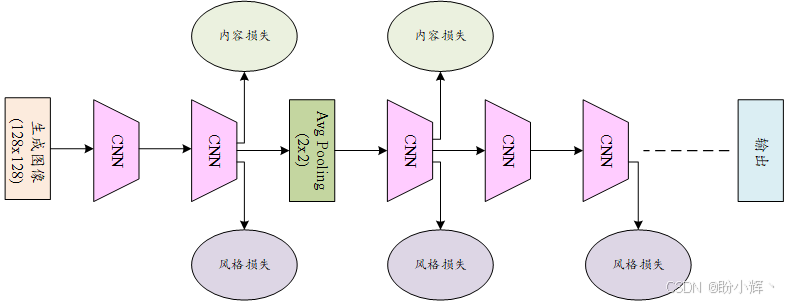
确定了卷积层的内容目标和风格目标后,我们便可以生成一张同时包含内容图像主体与风格图像风格的合成图像。
初始化时,可以选择使用随机噪声矩阵作为生成图像的起点,也可以直接以内容图像作为初始输入。
将该图像输入网络,并在预先选定的卷积层上计算风格损失和内容损失。通过累加各层风格损失得到总风格损失,汇总各层内容损失得到总内容损失。最后采用加权求和方式将二者组合为总损失函数。
若赋予风格损失更高权重,生成图像将更显著地呈现风格特征,反之则保留更多内容特征。我们通过梯度下降算法将损失反向传播至输入层,从而迭代更新生成图像。经过若干轮训练后,生成图像会逐步演化至能同时最小化内容与风格损失的状态,最终实现风格迁移效果。
池化层采用平均池化而非传统的最大池化,这是为了确保梯度平滑流动,平均池化能避免生成图像出现像素突变。值得注意的是,网络在最后一个计算损失的卷积层(第五层)即终止,因为原始网络的第六卷积层未参与任何损失计算,在风格迁移场景下使用更深层网络并无意义。
下一节我们将使用 PyTorch 框架实现神经风格迁移。借助预训练的VGG模型,生成艺术风格图像,并通过调节不同模型参数来观察其对生成图像内容保真度与风格化程度的影响。
2. 使用 PyTorch 实现神经风格迁移
在讨论了神经风格迁移系统的内部原理之后,接下来,使用 PyTorch 构建神经风格迁移系统。首先加载风格图像和内容图像,然后载入预训练的 VGG 模型。在定义计算风格损失和内容损失的对应网络层后,我们将对模型进行修剪,仅保留相关层结构。最后,训练神经风格迁移模型,通过不断迭代来优化生成的图像。
2.1 加载内容和风格图像
(1) 首先,我们需要导入必要的库,导入 torchvision 库用于加载预训练的 VGG 模型以及其他与计算机视觉相关的工具:
python
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
dvc = torch.device("cuda" if torch.cuda.is_available() else "cpu")(2) 接下来,加载一张风格图像和一张内容图像:
python
def image_to_tensor(image_filepath, image_dimension=128):
img = Image.open(image_filepath).convert('RGB')
# display image to check
plt.figure()
plt.title(image_filepath)
plt.imshow(img)
if max(img.size) <= image_dimension:
img_size = max(img.size)
else:
img_size = image_dimension
torch_transformation = torchvision.transforms.Compose([
torchvision.transforms.Resize(img_size),
torchvision.transforms.ToTensor()
])
img = torch_transformation(img).unsqueeze(0)
return img.to(dvc, torch.float)
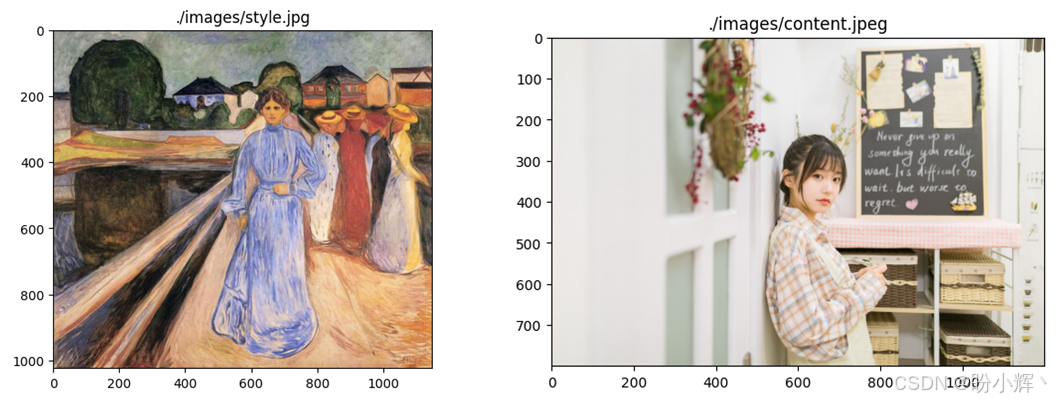
style_image = image_to_tensor("./images/style.jpg")
content_image = image_to_tensor("./images/content.jpeg")unsqueeze 命令在张量的第 0 维上增加一个维度,例如,将一个大小为 (32, 32) 的张量转换为 (1, 32, 32) 的张量。输出结果如下所示:
2.2 加载预训练 VGG19 模型
在本节中,我们将使用预训练 VGG 模型,并保留其卷积层。并对模型进行修改,使其能够用于神经风格迁移。
(1) 首先,加载预训练的 VGG19 模型,并使用其卷积层生成内容和风格目标,进而计算内容损失和风格损失:
python
vgg19_model = torchvision.models.vgg19(weights=torchvision.models.VGG19_Weights.DEFAULT).to(dvc)
print(vgg19_model)输出结果如下所示:
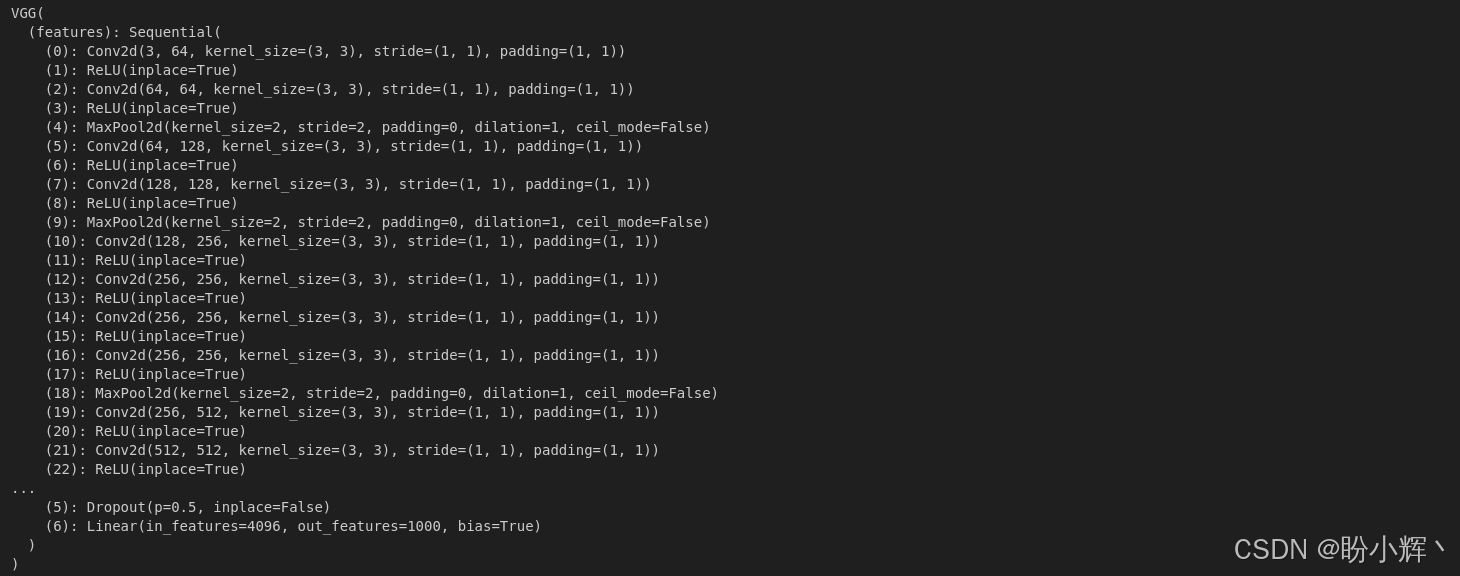
(2) 我们不需要线性层,只需要模型的卷积部分,可以通过仅保留模型对象的 features 属性来实现:
python
vgg19_model = vgg19_model.features(3) 在本节中,我们不会调整 VGG 模型的参数。要调整的唯一参数是生成图像的像素,位于模型的输入端。因此,确保加载的 VGG 模型的参数保持固定。我们必须冻结 VGG 模型的参数:
python
for param in vgg19_model.parameters():
param.requires_grad_(False)(4) 我们已经加载了 VGG 模型的相关部分,需要将最大池化层 (maxpool) 替换为平均池化层 (average pooling):
python
conv_indices = []
for i in range(len(vgg19_model)):
if vgg19_model[i]._get_name() == 'MaxPool2d':
vgg19_model[i] = nn.AvgPool2d(kernel_size=vgg19_model[i].kernel_size,
stride=vgg19_model[i].stride,
padding=vgg19_model[i].padding)
if vgg19_model[i]._get_name() == 'Conv2d':
conv_indices.append(i)
conv_indices = dict(enumerate(conv_indices, 1))
print(vgg19_model)输出如下所示,可以看到,线性层已经被移除,并且最大池化层已被平均池化层替换。
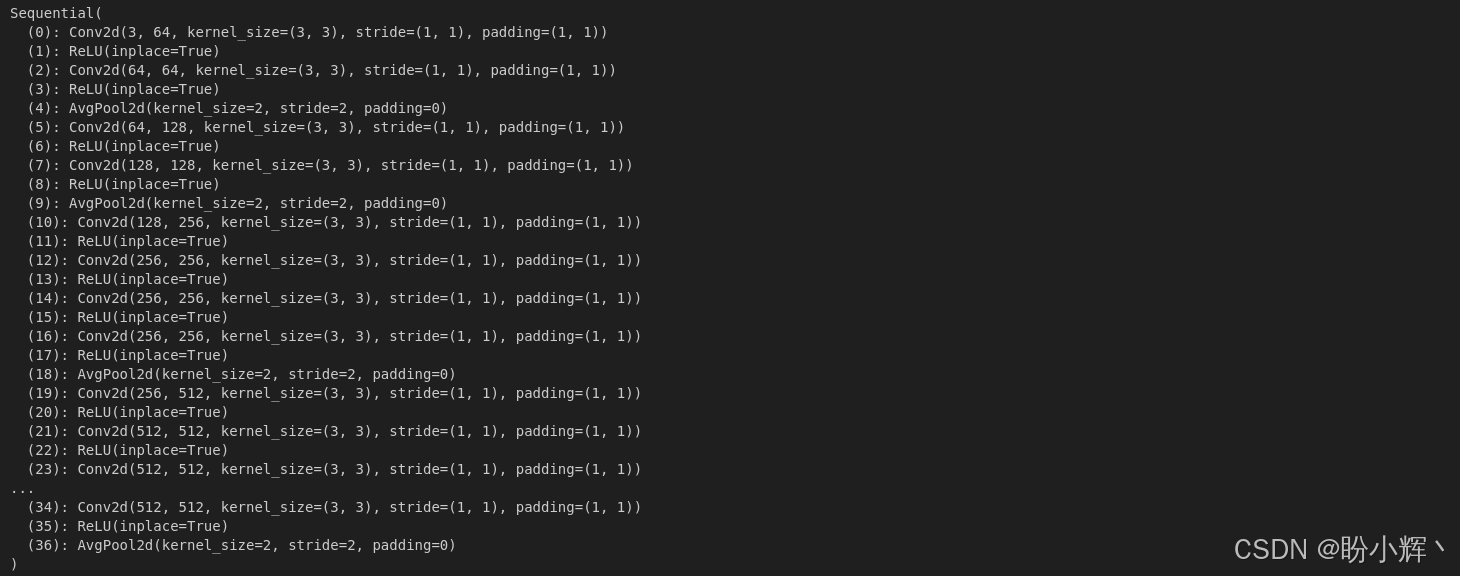
我们已经加载了一个预训练 VGG 模型,并对其进行了修改,以便将其用作神经风格迁移模型。接下来,我们将把这个修改过的 VGG 模型转化为神经风格迁移模型。
2.3 构建神经风格迁移模型
我们可以指定需要在哪些卷积层上计算内容损失和风格损失,风格损失在前五个卷积层( conv1_1 到 conv5_1 )上进行计算,而内容损失仅针对第四个卷积层 (conv4_2) 进行计算。我们也可以尝试不同的组合并观察它们对生成图像的影响。
(1) 首先,列出需要计算风格损失和内容损失的层:
python
layers = {1: 's', 2: 's', 3: 's', 4: 'sc', 5: 's'}在本节中,我们定义了前五个卷积层与风格损失相关联;而第四个卷积层与内容损失相关联,s 和 c 分别代表风格和内容损失。
(2) 移除 VGG 模型中不必要的部分:
python
vgg_layers = nn.ModuleList(vgg19_model)
last_layer_idx = conv_indices[max(layers.keys())]
vgg_layers_trimmed = vgg_layers[:last_layer_idx+1]
neural_style_transfer_model = nn.Sequential(*vgg_layers_trimmed)
print(neural_style_transfer_model)输出结果如下所示,可以看到,我们将具有 16 个卷积层的 VGG 模型转化为一个仅包含五个卷积层的神经风格迁移模型:

2.4 训练风格迁移模型
待生成的图像可以通过多种方式初始化,比如使用随机噪声图像,或者直接以内容图像作为初始图像。我们先用随机噪声作为起点,后续我们会对比使用内容图像初始化对结果的影响。
(1) 用随机数字初始化一个 torch 张量:
python
ip_image = torch.randn(content_image.data.size(), device=dvc)
plt.figure()
plt.imshow(ip_image.squeeze(0).cpu().detach().numpy().transpose(1,2,0).clip(0,1))输出结果如下所示:
(2) 最后,开始模型的训练循环。首先,定义训练 epoch 以及风格损失和内容损失的相对权重,并实例化 Adam 优化器进行基于梯度下降的优化,学习率设为 0.1:
python
num_epochs=300
wt_style=1e6
wt_content=1
style_losses = []
content_losses = []
opt = optim.Adam([ip_image.requires_grad_()], lr=0.1)(3) 在训练循环开始时,将风格损失和内容损失初始化为零,并且为了数值稳定性,将输入图像的像素值限制在 0 到 1 之间:
python
for curr_epoch in range(1, num_epochs+1):
ip_image.data.clamp_(0, 1)
opt.zero_grad()
epoch_style_loss = 0
epoch_content_loss = 0(4) 为每个预定义的风格和内容卷积层计算风格损失和内容损失。将各层单独计算的风格损失和内容损失累加,即可得到当前训练 epoch 的总风格损失和内容损失:
python
for k in layers.keys():
if 'c' in layers[k]:
target = neural_style_transfer_model[:conv_indices[k]+1](content_image).detach()
ip = neural_style_transfer_model[:conv_indices[k]+1](ip_image)
epoch_content_loss += torch.nn.functional.mse_loss(ip, target)
if 's' in layers[k]:
target = gram_matrix(neural_style_transfer_model[:conv_indices[k]+1](style_image)).detach()
ip = gram_matrix(neural_style_transfer_model[:conv_indices[k]+1](ip_image))
epoch_style_loss += torch.nn.functional.mse_loss(ip, target)对于风格损失和内容损失,首先,使用风格图像和内容图像计算风格和内容目标(即真实值)。使用 .detach() 将这些目标值设为不可训练参数,表明它们仅作为固定的目标参考值。接下来,以生成的图像作为输入,在每一个风格层和内容层上计算预测的风格输出和内容输出。最后,再基于这些输出值计算风格损失和内容损失。
对于风格损失,我们还需要使用预定义的 gram_matrix 函数来计算 Gram 矩阵:
python
def gram_matrix(ip):
num_batch, num_channels, height, width = ip.size()
feats = ip.view(num_batch * num_channels, width * height)
gram_mat = torch.mm(feats, feats.t())
return gram_mat.div(num_batch * num_channels * width * height)我们可以使用 torch.mm 函数计算内积。该运算将生成 Gram 矩阵,并通过将矩阵除以特征图数量与每个特征图宽度、高度的乘积来实现归一化处理
(5) 在完成风格总损失和内容总损失的计算后,我们需要使用预先定义的权重系数,将这两类损失加权求和以计算出最终的总损失值:
python
epoch_style_loss *= wt_style
epoch_content_loss *= wt_content
total_loss = epoch_style_loss + epoch_content_loss
total_loss.backward()(6) 最后,每隔 k 个 epoch,可以通过查看损失和生成的图像来观察训练的进展。下图展示了运行 180 个训练 epoch (每 20 个 epoch 记录一次)过程中风格迁移图像的演变过程:
python
if curr_epoch % 50 == 0:
print(f"epoch number {curr_epoch}")
print(f"style loss = {epoch_style_loss}, content loss = {epoch_content_loss}")
plt.figure()
plt.title(f"epoch number {curr_epoch}")
plt.imshow(ip_image.data.clamp_(0, 1).squeeze(0).cpu().detach().numpy().transpose(1,2,0))
plt.show()
style_losses += [epoch_style_loss.cpu().detach().numpy()]
content_losses += [epoch_content_loss.cpu().detach().numpy()]
opt.step()
(7) 可以看到,模型最初会将风格图像的样式特征施加在随机噪声上。随着训练推进,内容损失开始发挥作用,从而为风格化图像注入内容特征。下图显示了随着训练的进行,风格损失和内容损失逐渐减少的过程:
python
plt.plot(range(50, 300+1, 50), style_losses, label='style_loss');
plt.plot(range(50, 300+1, 50), content_losses, label='content_loss');
plt.legend()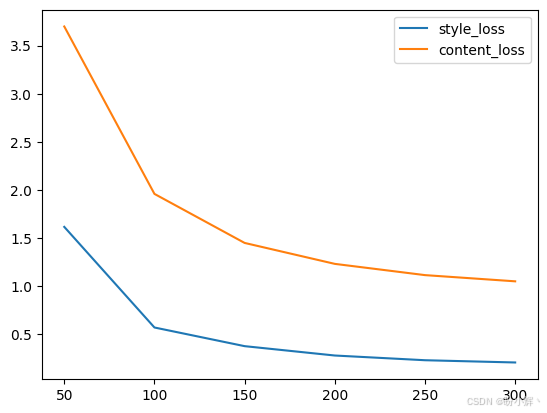
值得注意的是,风格损失在训练初期急剧下降,始阶段主要体现在风格特征而非内容特征的迁移。在训练后期,两种损失同步平稳下降,最终生成的风格迁移图像实现了艺术风格与照片写实性之间的完美平衡:既保留了风格画作的艺术特质,又维持了摄影作品的真实感。
3. 风格迁移系统超参数调优
成功训练风格迁移模型后,接下来,我们继续研究不同超参数对模型的影响。
在上一小节中,内容权重设为 1,风格权重设为 1e6。接下来,将风格权重再提高 10 倍至 1e7,观察其对风格迁移过程的影响。使用新权重训练 600 个 epoch,与之前的情况相比,需要更多的训练 epoch 才能达到理想效果。更重要的是,提高风格权重的确对生成图像产生了显著影响。通过对比上一小节与本节的生成图像,可以明显发现后者与风格图像的相似度更高,艺术风格的呈现更为突出。
同理,当我们将风格权重从 1e6 降至 1e5 时,生成图像会呈现更明显的内容导向特征,与采用较高风格权重的情况相比,降低风格权重后仅需极少训练 epoch 即可获得视觉效果合理的输出。此时生成图像中的风格特征显著减弱,内容图像的特征占据主导地位。由于该配置下模型很快会达到收敛状态,我们仅训练了 6 个 1epoch 便终止了训练过程。
保持原始风格权重 1e6 和内容权重 1 不变,但改用内容图像(而非随机噪声)作为生成图像的初始化输入。以内容图像作为起点为风格迁移提供了不同的演化路径。与使用随机噪声中"先迁移风格后注入内容"的渐进过程不同,本节中内容与风格特征呈现出更同步的融合态势。随着训练的进行,风格损失与内容损失同步下降并在末期趋于稳定。
小结
神经风格迁移是一种利用深度学习技术合成两个图像风格的方法,通过卷积神经网络提取图像的特征表示,并通过优化损失函数的方式合成新的图像,从而创造出独特而富有艺术感的合成图像。在本节中,我们使用 PyTorch 构建了一个神经风格迁移模型,通过使用一张内容图像和一张风格图像,生成了一个融合内容图像和风格图像的新图像。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成