在深度学习的训练过程中,我们经常需要直观地观察模型的训练曲线、参数变化、网络结构以及中间特征图,而不是盲目地看 loss 数字。之前知道TensorBoard这个工具,也用过,但研究之后才发现这玩意这么好用!
它是 TensorFlow 官方推出的可视化工具,但如今 PyTorch、JAX、MindSpore 等框架也已全面兼容。

无论你是调试模型还是展示实验结果,TensorBoard 都能让你事半功倍。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
一、安装与启动
TensorBoard 的安装非常简单:
bash
pip install tensorboard启动命令:
bash
tensorboard --logdir=./runs --port=6006然后在浏览器中访问:
plain
http://localhost:6006提示:--logdir 指向你保存日志的文件夹路径,比如 PyTorch 默认保存到 runs/ 下。
二、在 PyTorch 中使用 TensorBoard
初始化 SummaryWriter
python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="./runs/exp1")这行代码就会创建一个用于写入日志的对象,exp1 是实验名称。
记录训练指标
python
for epoch in range(10):
train_loss = 0.1 * epoch
val_acc = 0.8 + 0.02 * epoch
writer.add_scalar("Loss/train", train_loss, epoch)
writer.add_scalar("Accuracy/val", val_acc, epoch)打开 TensorBoard 后,就能看到漂亮的折线图啦:
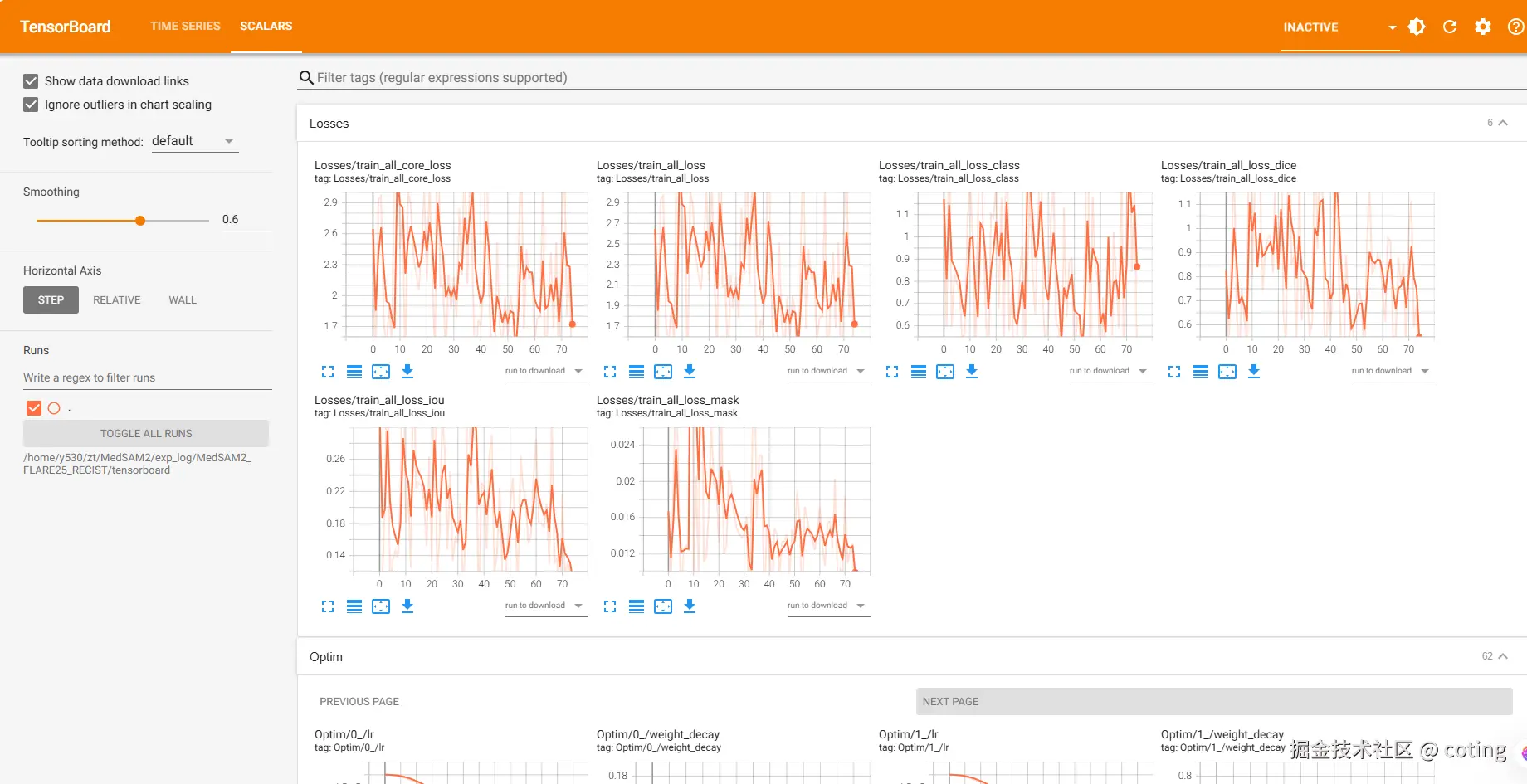
Scalars 选项卡用于展示损失函数、准确率等指标随 epoch 的变化趋势。
可视化模型结构
python
# === 定义一个简单的 MLP 模型 ===
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# === 模型结构可视化 ===
dummy_input = torch.randn(1, 1, 28, 28)
writer.add_graph(model, dummy_input)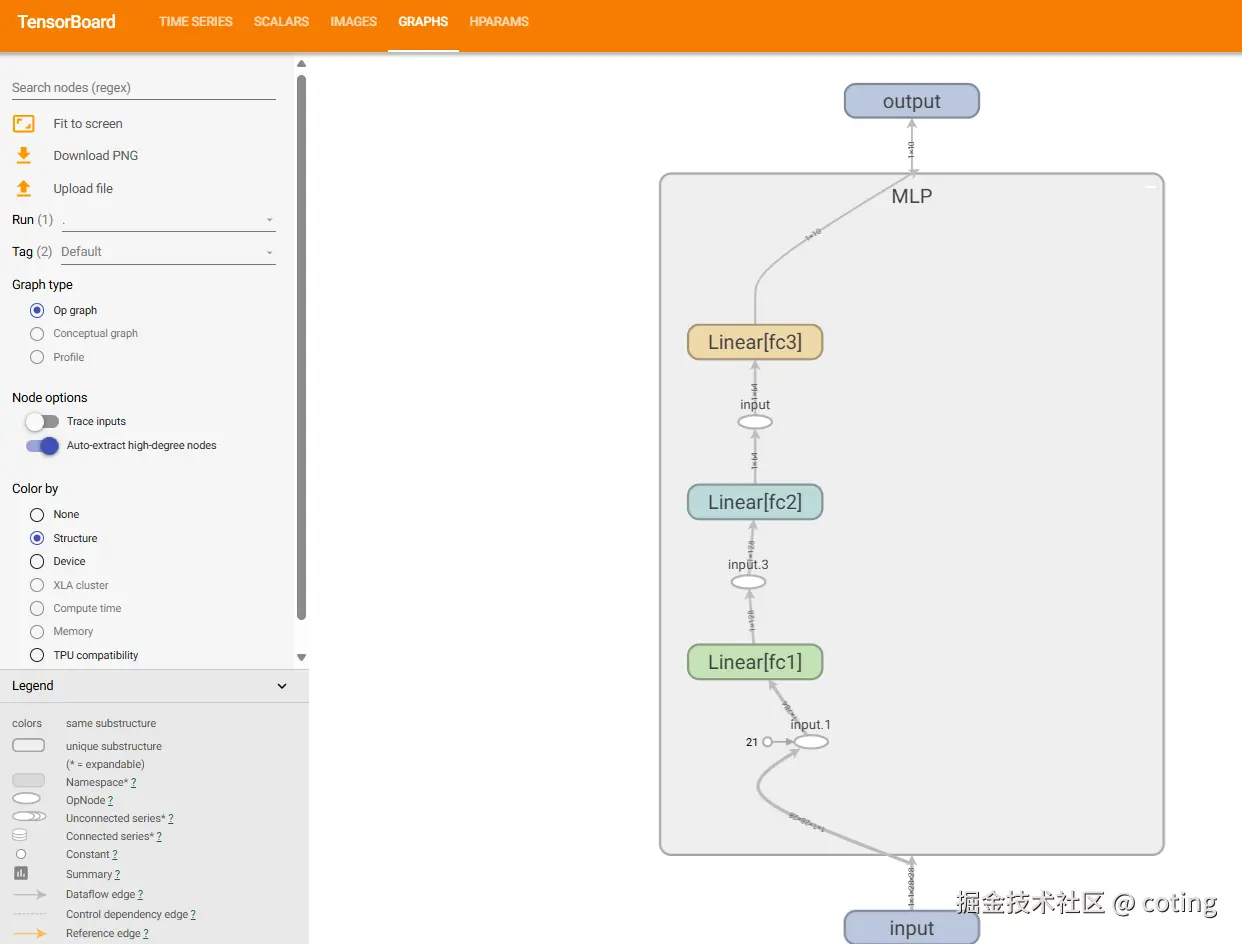
在 TensorBoard 的 Graphs 页面中,你可以看到网络的计算图结构,帮助你排查模型拼接或梯度传递错误,这个确实足够优秀了,画出来的模型结构也很清晰。
可视化特征图(Feature Maps)
假设我们在卷积层之后想看看模型提取了什么特征:
python
images = torch.randn(16, 3, 32, 32)
writer.add_images("Input Images", images, 0)对于特征图,可以通过 make_grid 拼接后写入:
python
from torchvision.utils import make_grid
feature_maps = torch.randn(16, 1, 28, 28)
grid = make_grid(feature_maps, nrow=4, normalize=True)
writer.add_image("Feature Maps", grid, 0)这在调试 CNN 时非常有用。
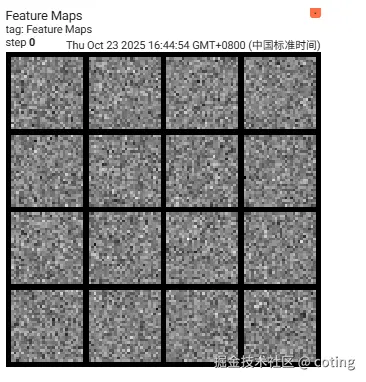
三、高级功能与技巧
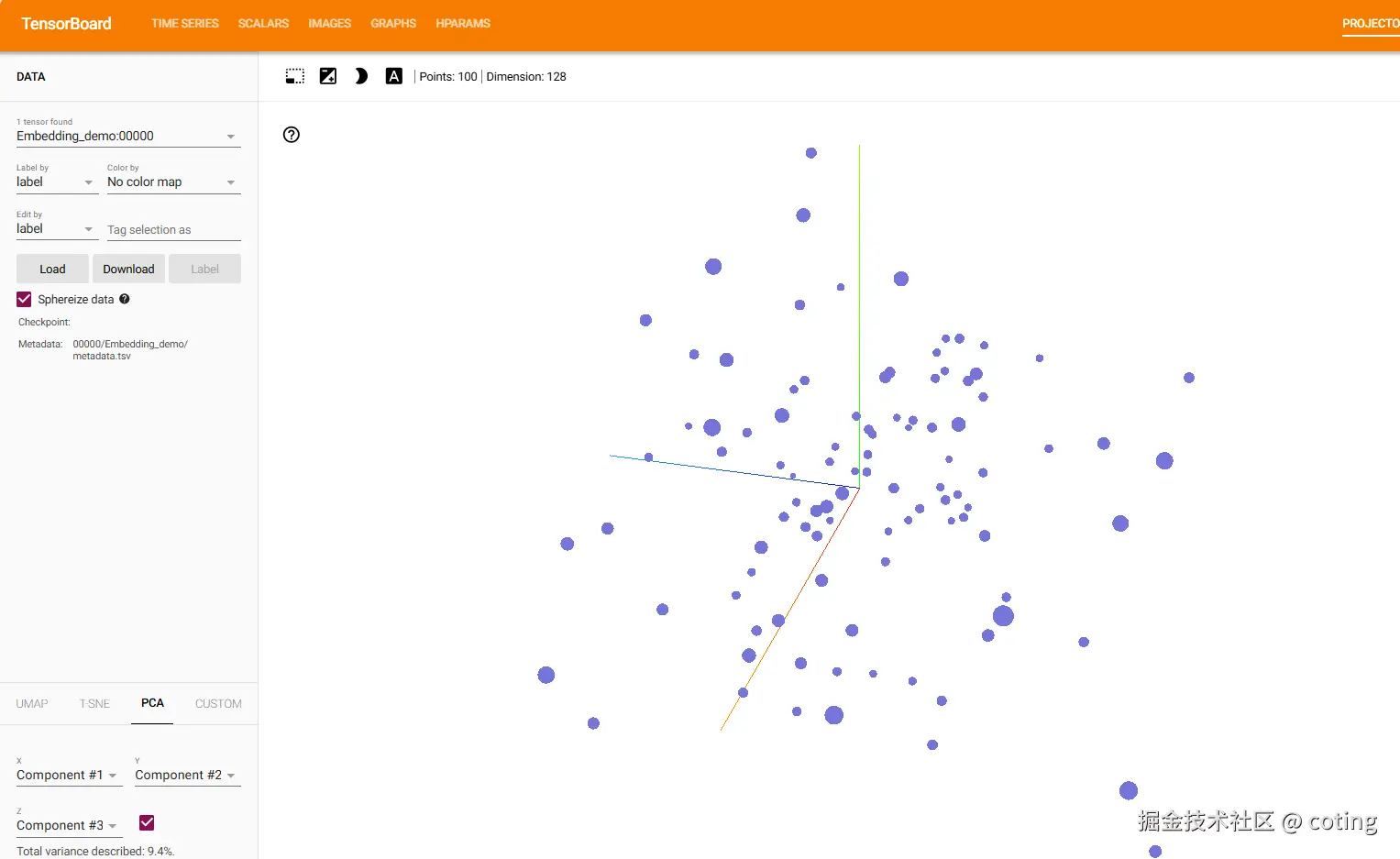
Embedding 可视化(高维特征降维)
在模型训练结束后,我们可以用 TensorBoard 来查看高维向量的分布(常用于可视化词向量、图像特征):
python
import numpy as np
features = np.random.rand(100, 128)
labels = [f"class_{i%10}" for i in range(100)]
writer.add_embedding(features, metadata=labels, tag="Embedding_demo")打开 Projector 页面,就能看到点云分布及类别区分情况,这里让我挺震惊的,他是三维动画形式的,如果数据量再大一些我想应该会非常优美。
超参数追踪(HParams)
python
# === 超参数记录 ===
writer.add_hparams(
{'lr': 0.001, 'batch_size': 64, 'epochs': epochs},
{'accuracy': test_acc, 'loss': test_loss}
)这样你可以在 TensorBoard 的 HParams 选项卡中对比不同实验参数的表现,非常适合调参阶段。

记录混淆矩阵
python
cm = confusion_matrix(all_targets, np.array(all_preds).flatten())
fig, ax = plt.subplots(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", ax=ax)
ax.set_xlabel("Predicted")
ax.set_ylabel("True")
writer.add_figure("Confusion Matrix", fig)这种方式比单纯打印矩阵更直观,我们平时看的很多论文就有这种图像。

对比多次实验
多个实验只需写入不同目录即可,例如:
bash
runs/
├── exp_lr_1e-3/
├── exp_lr_1e-4/
└── exp_lr_5e-4/TensorBoard 会自动加载所有实验的指标,方便对比曲线趋势。
但是TensorBoard也会存在一些问题,比如当日志太多时就会导致加载速度慢,所以就需要我们定期清理 runs
文件夹,或使用 --samples_per_plugin限制加载数量。
TensorBoard 是深度学习工程师的必备工具。它不仅能让训练过程「看得见」,还能帮助我们调试网络结构、分析收敛趋势与异常点、追踪参数与特征变化、展示实验结果与模型可解释性。
会跑模型很重要,但是会使用可视化工具同等重要,毕竟可以大幅提升我们处理数据的速度,帮助我们迸发新的idea!
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!