TL;DR
- 场景:解释 RabbitMQ 为何用 Channel 复用 Connection,并串起发布/消费与 AMQP 帧结构
- 结论:Channel 负责多路复用与隔离;高流量用多 Connection 分摊;抓包可验证命令映射与帧字段
- 产出:一套"连接/信道/API→AMQP命令→抓包验证"的工程化理解路径 + 常见错误速查表

版本矩阵
| 类别 | 说明 |
|---|---|
| 已验证说明 | 未提供环境版本 |
| 建议标注版本 | RabbitMQ Server 版本、Erlang/OTP 版本、Java amqp-client 版本、(如有)Spring AMQP 版本 |
| 通用概念 | Connection/Channel、多路复用、AMQP 命令映射、抓包字段解释 |
| 适用版本范围 | RabbitMQ 3.x + Java client 5.x 的常见组合 |
| 需核对版本配置项 | 每连接最大 Channel 数、流控/阻塞行为、客户端线程模型建议 |
| 注意事项 | 避免读者对"默认值/上限"产生误用 |
| 配置依据 | 需以当前集群配置与客户端版本为准 |
RabbitMQ 工作流程
Connection与Channel
生产者和消费者在与RabbitMQ Broker进行通信时,首先需要建立一个TCP连接(Connection)。这个TCP连接作为底层传输通道,为后续的AMQP协议通信提供基础。建立TCP连接的过程通常包括三次握手,确保连接的可靠性。
在TCP连接建立之后,客户端会在该连接上创建AMQP信道(Channel)。每个信道都会被分配一个唯一的数字ID标识。信道是建立在物理TCP连接之上的虚拟连接,具有以下特点:
- 多路复用:单个TCP连接上可以创建多个信道,每个信道都可以独立进行消息的发布和消费
- 资源隔离:不同信道之间的操作相互隔离,一个信道的异常不会影响其他信道
- 轻量级:创建和销毁信道的开销远小于建立TCP连接
RabbitMQ处理的所有AMQP指令(如队列声明、消息发布、消息消费等)都是通过信道完成的。典型的工作流程如下:
- 生产者通过信道声明队列
- 生产者通过信道发布消息到指定队列
- 消费者通过信道订阅队列
- 消费者通过信道接收消息
使用信道的优势包括:
- 避免了为每个操作建立TCP连接的开销
- 允许多个线程共享同一个TCP连接
- 提高了网络资源利用率
- 降低了系统整体开销
在实际应用中,通常会维护一个连接池和信道池,根据业务需求动态创建和回收这些资源。例如,在Java客户端中,一个常见的模式是为每个线程分配独立的信道,而多个线程共享同一个TCP连接。
需要注意的是,虽然信道比TCP连接更轻量,但也不应该无限制地创建。RabbitMQ对每个连接的信道数量有限制(默认是2047个),超出限制会导致信道创建失败。
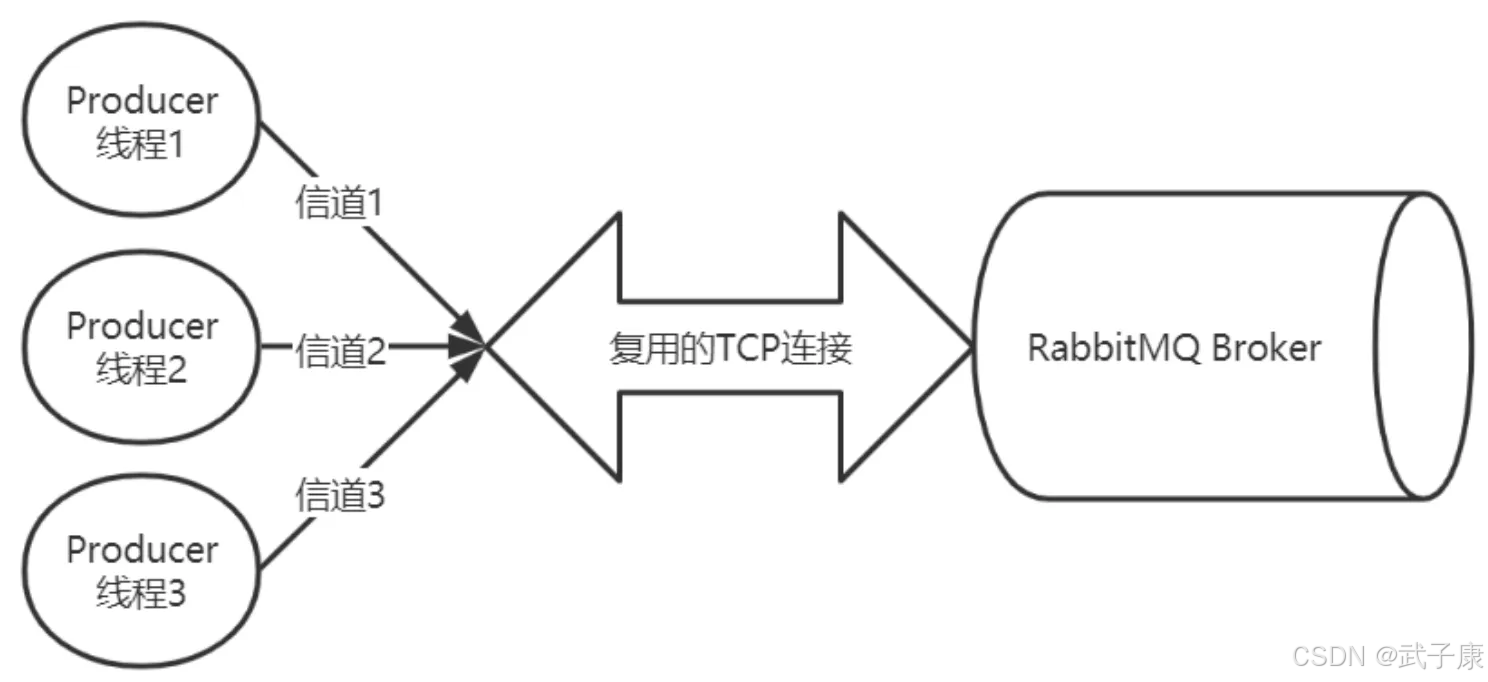
为什么不直接使用TCP?
为什么不直接使用TCP连接而使用信道呢?这主要基于以下几个方面的考虑:
- 连接复用与性能优化:
- RabbitMQ 采用了类似 Java NIO 的机制,通过复用TCP连接来减少性能开销
- 每个TCP连接的建立和销毁都需要三次握手和四次挥手,会产生较大的性能损耗
- 通过信道机制,可以在单个TCP连接上创建多个虚拟信道(默认最多2047个),大大提高了连接利用率
- 资源管理优势:
- 当每个信道的流量较小时(如QPS<1000),复用单一Connection可以:
- 节省服务器端口资源
- 减少连接维护开销
- 降低操作系统TCP栈的压力
- 典型的应用场景包括:后台管理系统、低频数据采集等
- 高流量场景处理:
- 当单个信道流量很大时(如QPS>5000),会出现性能瓶颈:
- TCP连接会成为吞吐量的限制因素
- 单个连接的流量控制会影响所有信道
- 解决方案是建立多个Connection:
- 将高流量信道分散到不同Connection
- 可根据业务特点进行灵活配置(如按业务类型划分)
- AMQP协议设计:
- 信道是AMQP协议的核心概念
- 大多数操作都在信道层完成,包括:
- 队列声明(queue.declare)
- 消息发布(basic.publish)
- 消息消费(basic.consume)
- 信道提供了独立的:
- 流控机制
- 错误处理隔离
- QoS控制
实际应用建议:
- 常规场景:1个Connection + 多个Channel
- 高并发场景:多个Connection(建议不超过CPU核心数*2) + 每个Connection多个Channel
- 监控指标:关注Connection的带宽利用率(建议不超过70%)
1. channel.exchangeDeclare
用于声明一个交换机,是消息路由机制的核心组件。主要参数包括:
- exchangeName: 交换机名称
- exchangeType: 交换机类型(direct/fanout/topic/headers)
- durable: 是否持久化(true/false)
- autoDelete: 无绑定时是否自动删除
- internal: 是否内部使用(客户端不可直接发布到此交换机)
- arguments: 额外参数(Map类型)
示例场景:创建一个持久化的直连交换机
java
channel.exchangeDeclare("order.exchange", "direct", true);2. channel.queueDeclare
声明消息队列,主要参数:
- queueName: 队列名称(空字符串时服务器自动生成)
- durable: 是否持久化
- exclusive: 是否排他队列(仅当前连接可见)
- autoDelete: 无消费者时是否自动删除
- arguments: 队列参数(消息TTL、最大长度等)
典型应用:创建工作队列
java
channel.queueDeclare("task.queue", true, false, false, null);3. channel.basicPublish
发布消息到交换机,关键参数:
- exchange: 目标交换机名称
- routingKey: 路由键
- mandatory: 是否强制路由(无匹配队列时返回Basic.Return)
- immediate: RabbitMQ特有参数(已弃用)
- props: 消息属性(MessageProperties)
- body: 消息内容(byte\[\])
消息发布示例:
java
channel.basicPublish("order.exchange",
"order.create",
MessageProperties.PERSISTENT_TEXT_PLAIN,
"订单数据".getBytes());4. channel.basicConsume
注册消费者,主要配置:
- queue: 监听的队列名
- autoAck: 是否自动确认
- consumerTag: 消费者标识
- noLocal: 是否排除来自同一连接的消息
- exclusive: 是否独占消费
- callback: 消息处理回调函数
消费者实现示例:
java
channel.basicConsume("task.queue", false, "worker-1", new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) {
// 处理消息逻辑
channel.basicAck(envelope.getDeliveryTag(), false);
}
});AMQP 协议对应关系
这些API直接映射到AMQP协议命令:
- exchangeDeclare → Exchange.Declare
- queueDeclare → Queue.Declare
- basicPublish → Basic.Publish
- basicConsume → Basic.Consume
协议细节可通过抓包工具(如Wireshark)深入观察AMQP帧结构。每个完整的AMQP命令帧由以下四个关键部分组成:
-
Frame Type (帧类型):
- 1字节标识符,表示帧的类型
- 常见类型包括:方法帧(0x01)、内容头帧(0x02)、内容体帧(0x03)、心跳帧(0x08)
- 例如:0x01表示这是一个方法帧,用于携带AMQP命令
-
Channel Number (通道号):
- 2字节无符号整数
- 用于多路复用,标识当前帧所属的逻辑通道
- 范围:0-65535,其中0为特殊通道,用于连接级控制
-
Payload (有效载荷):
- 变长字段,包含具体的命令参数
- 方法帧的payload包含:类ID(2字节)、方法ID(2字节)、参数列表
- 例如:Basic.Publish命令会包含exchange名称、routing key等参数
-
Frame End标记:
- 固定为0xCE(206)的1字节结束符
- 用于标识帧的结束,便于解析器识别帧边界
在实际抓包分析中,可以观察到典型的帧结构示例:
shell
Frame 123: 60 bytes on wire (60 bytes captured)
AMQP
[Frame Type: Method (0x01)]
[Channel: 1]
[Method: Basic.Publish]
Class: Basic (60)
Method: Publish (40)
[content: 0]
[exchange: my_exchange]
[routing key: test.route]
[Frame End: 0xCE]通过Wireshark的AMQP解析器,可以直观地查看这些字段的详细信息和原始字节数据,帮助开发者深入理解AMQP协议的通信机制。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Channel 创建失败(提示达到上限/无法分配) | 单 Connection 上 Channel 数达到 server 端 channel_max(常见配置为 2047,但可变) | 管理台/日志看 connection 参数;客户端创建 channel 报错栈 | 减少 Channel 数(复用/池化);拆分为多 Connection;调整服务端 channel_max(谨慎评估资源) |
| 频繁建连导致延迟抖动、端口耗尽、TIME_WAIT 激增 | 每次操作都新建 TCP Connection(握手/挥手成本高) | OS 端口与连接状态统计;客户端连接数曲线 | 固定少量 Connection + Channel 池;按业务分组而非按请求建连 |
| AlreadyClosedException / ShutdownSignalException | 连接被 broker 关闭(认证失败、心跳超时、资源限制、网络抖动) | RabbitMQ 日志(connection closed 原因);客户端异常 cause | 校验用户名/vhost/权限;合理 heartbeat;网络稳定性;开启自动重连并确保幂等 |
| PRECONDITION_FAILED(声明交换机/队列失败) | 同名交换机/队列参数不一致(type、durable、arguments 等) | broker 日志 + 客户端异常信息(inequivalent arg) | 统一声明参数;先清理旧资源或更名;把声明收敛到单一初始化模块 |
| 消息发出但丢到"黑洞",队列无消息 | exchange/routingKey 不匹配绑定;未开启 mandatory 或未处理 Return | 开启 publisher confirm/return;看 binding 与路由;抓包看 Basic.Publish 参数 | 校验交换机类型与 binding;开启 mandatory 并处理 Return;引入可观测性(confirm/metrics) |
| 单 Connection 多 Channel 时整体吞吐卡住/延迟飙升 | 单连接带宽/拥塞窗口/流控影响所有 Channel;热点业务挤占 | 监控 connection 级别吞吐、blocked 状态;队列积压与延迟 | 将高流量业务拆到多 Connection;按业务隔离连接;限制单 Channel 并发与 prefetch |
| 消费端重复消费或堆积 | autoAck=true 导致处理失败仍确认;或手动 ack 丢失/未 ack | 消费代码检查;看 redelivered 标记与积压 | 关闭 autoAck;在成功后 basicAck;失败 basicNack/requeue 或进 DLQ;设置合理 prefetch |
| 抓包看到帧但字段对不上/解析异常 | Wireshark 未正确识别 AMQP;TLS 场景无法看到明文;端口/协议混淆 | 确认是否 AMQP 0-9-1;是否 TLS;抓包过滤与解码设置 | 明文环境验证协议学习;TLS 用日志/客户端 tracing 替代;确保抓的是 broker 端口与正确会话 |
| "多线程共享一个 Channel" 后出现随机协议错误 | Channel 在多数客户端实现中非线程安全;并发 publish/consume 交叉 | 异常栈与偶发性;并发压测时复现 | 共享 Connection,但每线程/每 worker 独立 Channel;使用 Channel 池控制数量 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接