什么是 Plan-and-Execute
Plan-and-Execute = Planning(规划)+ Execution(执行)
这是一种将复杂任务先进行全局规划,然后按计划逐步执行的架构模式,强调先思后行、有序推进。
人类类比
想象你在规划一次旅行。与其走一步看一步,更明智的做法是先制定一个清晰的行程表,然后按计划执行。这个流程图展示了这种思维方式:
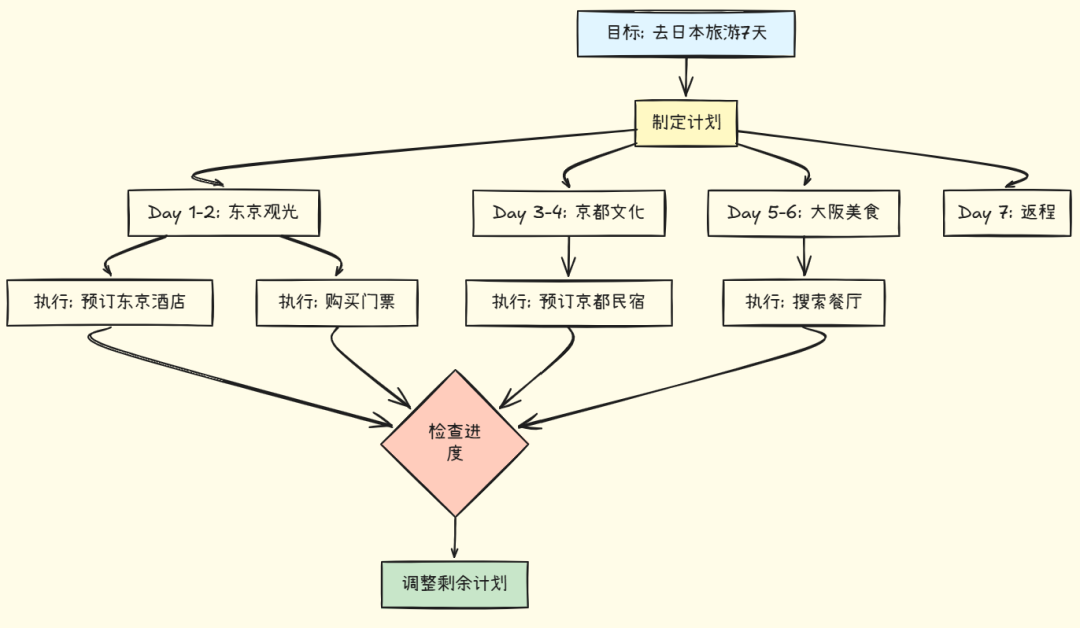
从图中可以看到,我们首先在顶层确立目标,然后分解成具体的日程安排。每个日程进一步细化为可执行的具体任务(预订、购票等)。执行过程中,我们会定期检查进度,发现问题及时调整后续计划。
这就是 Plan-and-Execute 的本质:先制定完整计划 → 逐步执行 → 检查进度 → 必要时调整计划。这种方法让复杂任务变得有序可控,避免迷失方向。
定义
Plan-and-Execute 是一种目标导向的架构模式,特点是:
-
• ✅ 先进行全局规划,后执行具体任务
-
• ✅ 计划具有层次结构(高层目标 → 子任务)
-
• ✅ 执行过程相对独立和并行
-
• ✅ 支持计划的监控和动态调整
-
• ✅ 适合长时间、多步骤的复杂任务
为什么需要 Plan-and-Execute
在开始深入之前,让我们先理解为什么需要这种范式。要回答这个问题,我们需要看看传统方法在处理复杂任务时遇到的挑战。
ReAct 的局限性
使用传统的 ReAct 模式处理复杂任务时,会遇到以下问题:
❌ 问题1:容易迷失方向
用户: "帮我分析竞争对手,制作市场报告"
ReAct: 思考 → 搜索公司A → 思考 → 搜索公司B → 思考 → 咦,我要做什么来着?
❌ 问题2:效率低下
每一步都需要重新思考"下一步做什么",缺乏全局视野
❌ 问题3:难以并行
所有任务必须串行执行,无法利用并发能力
❌ 问题4:成本高昂
每个思考步骤都需要调用 LLM,token 消耗大这些问题在简单任务中或许不明显,但当任务变得复杂、步骤增多时,就会显著影响效率和质量。
Plan-and-Execute 的优势
✅ 全局规划:一次性制定完整路线图
✅ 高效执行:明确知道要做什么,减少重复思考
✅ 支持并行:多个独立子任务可以同时执行
✅ 降低成本:规划阶段用强模型,执行阶段可用弱模型
✅ 易于监控:清晰的计划使进度可视化
✅ 灵活调整:可以根据执行结果重新规划Plan-and-Execute 的核心原理
理解了为什么需要 Plan-and-Execute,接下来我们深入探讨它的核心工作原理。整个框架可以分解为三个关键组件,它们相互配合形成一个完整的闭环系统。
三大核心组件
下面这张架构图展示了 Plan-and-Execute 的核心流程:
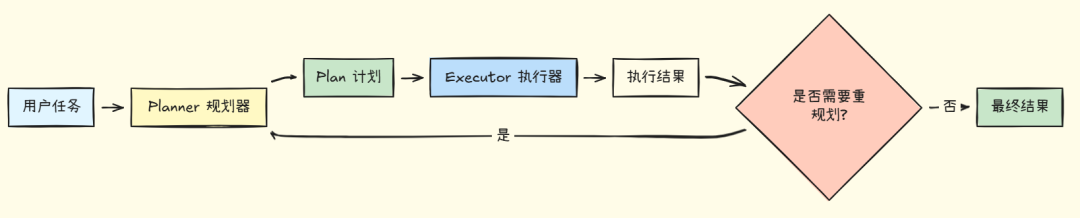
从图中可以看出,整个流程分为三个阶段:规划(Planning) 、执行(Execution)和评估(Evaluation)。规划器负责将复杂任务分解为具体步骤,执行器按计划完成每个步骤,评估环节则决定是否需要调整计划。这种设计使系统既有全局视野,又保持灵活性。
1. Planner(规划器)
职责:将复杂任务分解为有序的子任务列表
规划器的工作流程可以用下图表示:

规划输出示例:
任务: 分析市场并制作竞争报告
↓
步骤1: 收集竞争对手列表 [web_search]
↓
步骤2: 分析产品特点 [web_scrape] (依赖步骤1)
↓
步骤3: 收集市场份额 [data_query] (依赖步骤1)
↓
步骤4: 生成报告 [document_generate] (依赖步骤2,3)特点:
-
• 使用强大的 LLM(如 GPT-4)进行规划
-
• 只在开始时和需要调整时调用
-
• 生成结构化的任务列表
2. Executor(执行器)
职责:按照计划执行每个子任务
执行器的核心流程:
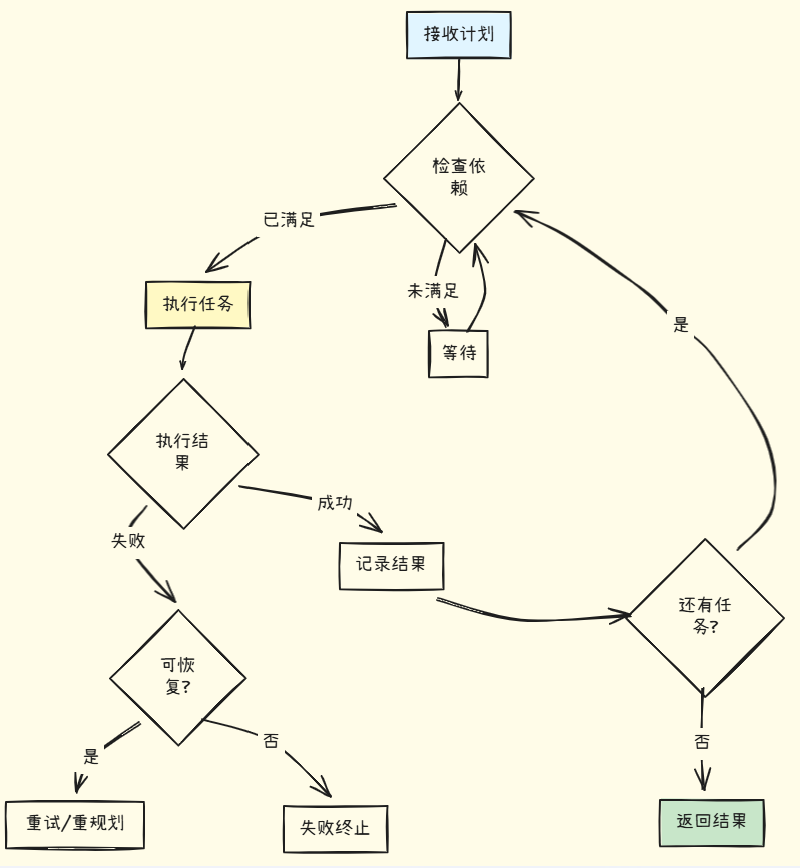
特点:
-
• 可以使用较弱的 LLM 或专门工具
-
• 专注于执行单个明确的任务
-
• 支持并行执行独立任务
3. Replanner(重规划器)
职责:在执行过程中遇到问题时调整计划
重规划的触发场景:
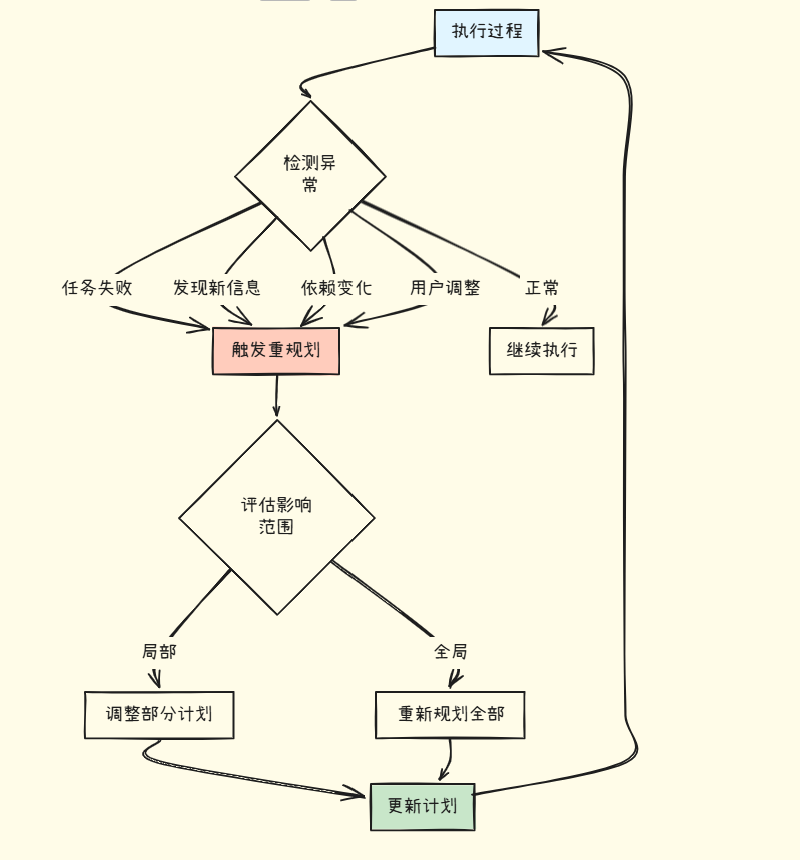
常见触发条件:
-
• ❌ 任务执行失败
-
• 💡 发现新的重要信息
-
• 🔄 依赖条件发生变化
-
• 👤 用户需求调整
Plan-and-Execute 的工作机制
前面我们介绍了核心组件,现在让我们通过一个完整的时序图来看看这些组件如何协同工作。这将帮助我们理解从接收任务到返回结果的全过程。
完整流程图
这张时序图展示了各个组件之间的交互过程:
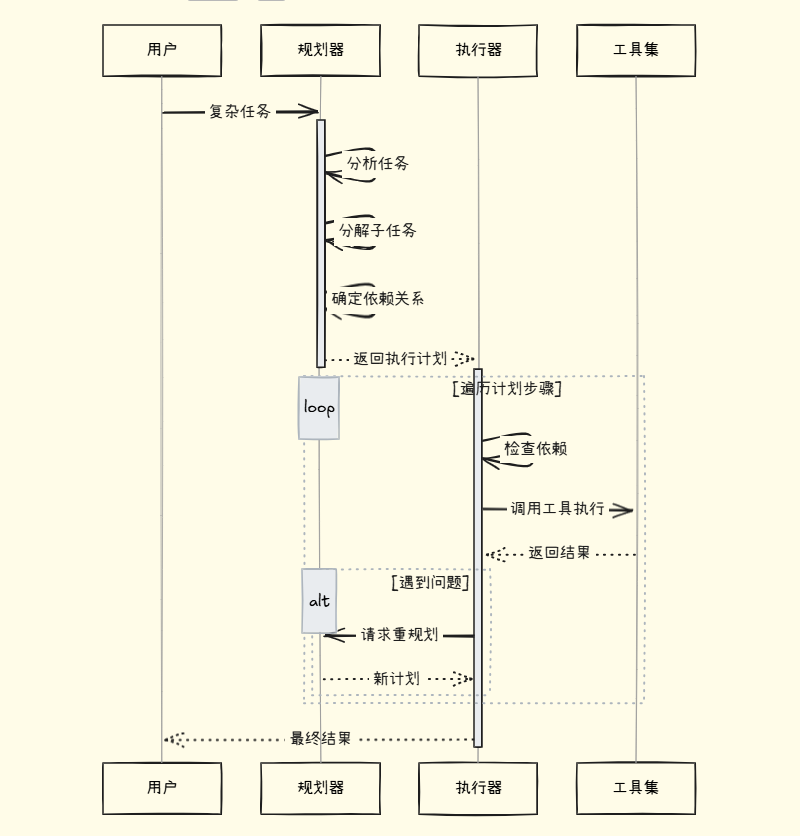
从图中可以看到,规划器首先进行"三步走":分析任务、分解子任务、确定依赖关系。然后执行器接管,循环处理每个步骤。关键的是,执行过程中如果遇到问题,系统可以回到规划阶段重新制定计划,体现了动态调整的能力。
详细步骤
让我们通过一个具体示例来理解每个步骤的实际操作:
步骤1:任务输入
user_task = "帮我研究 AI Agent 市场,写一份包含技术趋势和竞争格局的报告"步骤2:规划阶段
规划器会将任务分解为多个步骤,并确定依赖关系:
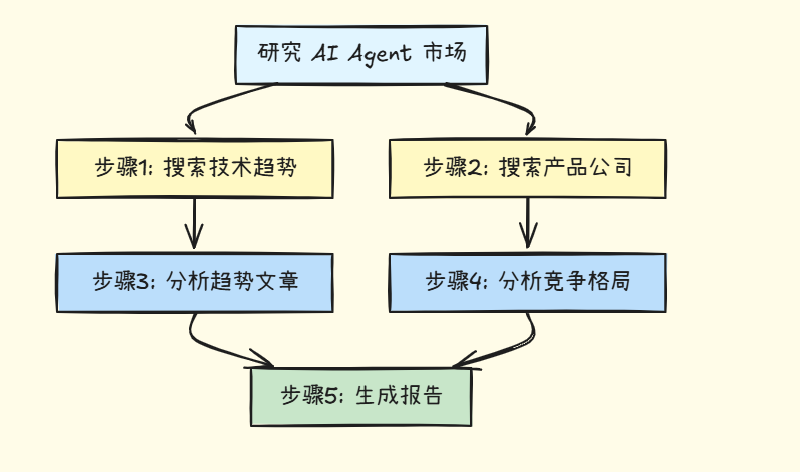
输出的执行计划:
-
• 步骤1和2可以并行执行(无依赖)
-
• 步骤3依赖步骤1的结果
-
• 步骤4依赖步骤2的结果
-
• 步骤5需要等待步骤3和4完成
步骤3:执行阶段
执行器按照依赖关系智能调度任务:
并行执行策略:

执行核心逻辑:
-
- 找出所有依赖已满足的任务 → 并行执行
-
- 记录结果并检查是否需要重规划
-
- 重复直到所有任务完成
步骤4:执行过程示例
执行日志:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[Round 1] 并行执行独立任务
├─ Task 1: 搜索 AI Agent 技术趋势
│ └─ 状态: ✓ 完成
│ └─ 结果: 找到 15 篇相关文章
│
└─ Task 2: 搜索 AI Agent 产品和公司
└─ 状态: ✓ 完成
└─ 结果: 找到 8 家主要公司
[Round 2] 执行依赖任务
├─ Task 3: 分析技术趋势文章(依赖 Task 1)
│ └─ 状态: ✓ 完成
│ └─ 结果: 提取 5 个核心趋势
│
└─ Task 4: 分析竞争格局(依赖 Task 2)
└─ 状态: ✓ 完成
└─ 结果: 生成竞争矩阵
[Round 3] 最终汇总
└─ Task 5: 生成报告(依赖 Task 3, 4)
└─ 状态: ✓ 完成
└─ 结果: 报告已生成(3500 字)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
总计: 5 个任务,3 轮执行,耗时 45 秒规划器(Planner)设计
规划器的核心能力
规划器的五个核心步骤:

核心能力:
-
- 任务理解 - 分析用户意图和目标
-
- 任务分解 - 将复杂任务拆分为子任务
-
- 工具映射 - 为每个子任务分配合适的工具
-
- 依赖分析 - 确定任务之间的执行顺序
-
- 优化排序 - 最大化并行性和效率
任务分解策略
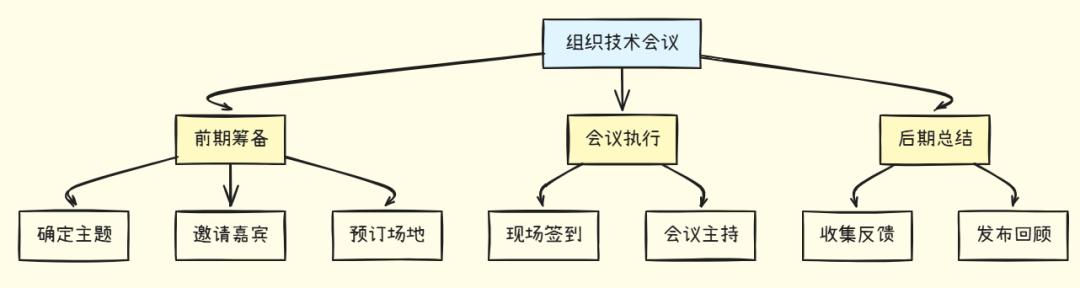
三种常见的分解策略:
1. 层次分解
将复杂任务递归分解为多个层次:
2. 时序分解
按时间顺序分解任务(发布软件版本示例):

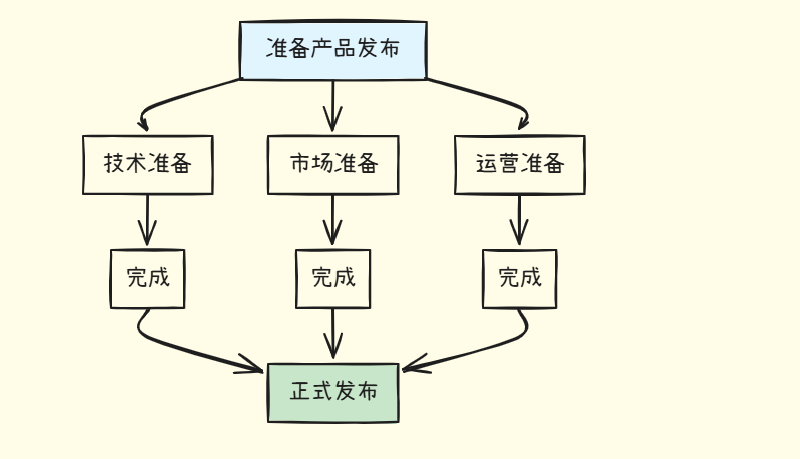
3. 并行分解
识别可以同时进行的任务流:
规划器提示词设计
核心规划原则:
-
- SMART 原则 - 具体、可衡量、可实现
-
- 最小化依赖 - 支持并行执行
-
- 合理粒度 - 不太细也不太粗
-
- 明确工具 - 为每个任务指定工具
-
- 清晰依赖 - 标注任务间依赖关系
执行器(Executor)设计
执行器的核心职责
执行器负责按计划执行任务,支持三种执行模式:
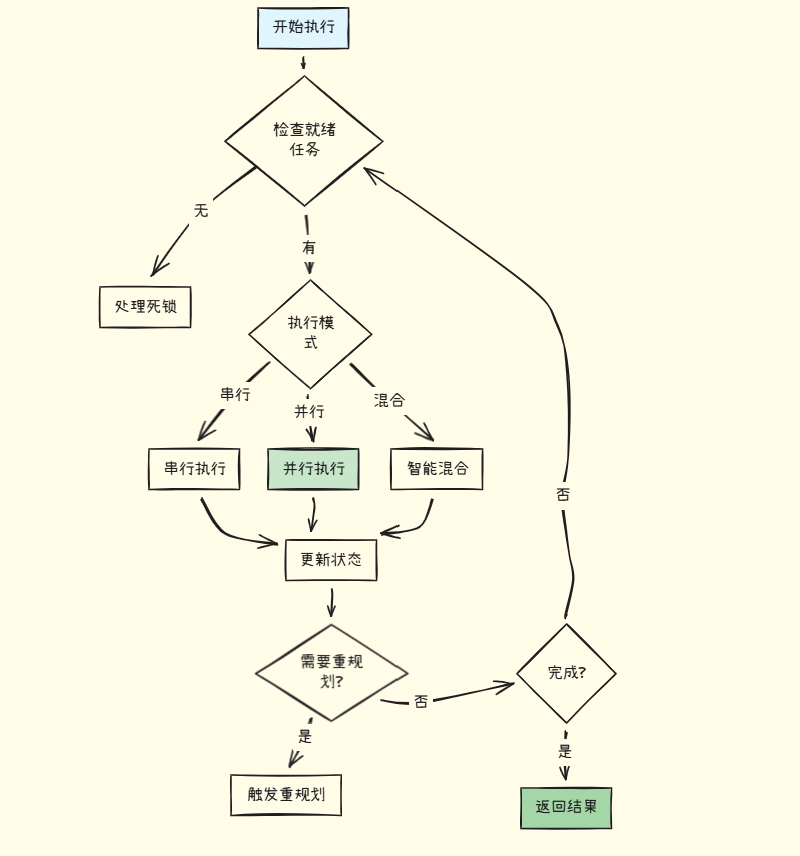
核心职责:
-
• 🔍 监控任务依赖关系
-
• ⚡ 智能调度(串行/并行)
-
• 📊 维护执行状态
-
• 🔄 触发重规划机制
任务执行策略
三种执行策略的对比:
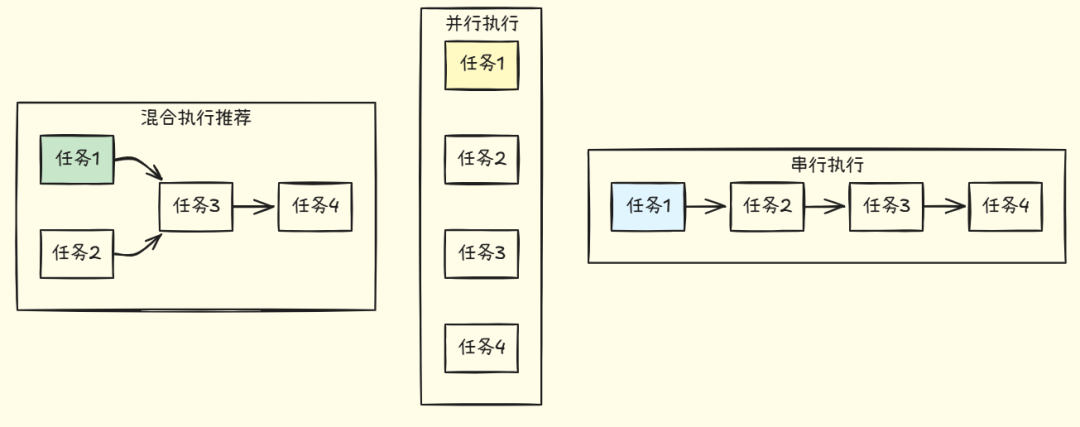
1. 串行执行
-
• 适用:任务有严格顺序要求
-
• 优点:实现简单,资源占用少
-
• 缺点:效率较低
2. 并行执行
-
• 适用:所有任务相互独立
-
• 优点:效率最高
-
• 缺点:资源消耗大
3. 混合执行(推荐)
-
• 适用:有依赖的复杂任务
-
• 策略:分析依赖图,组内并行,组间串行
-
• 优点:平衡效率和资源
执行上下文管理
执行状态管理的数据流:
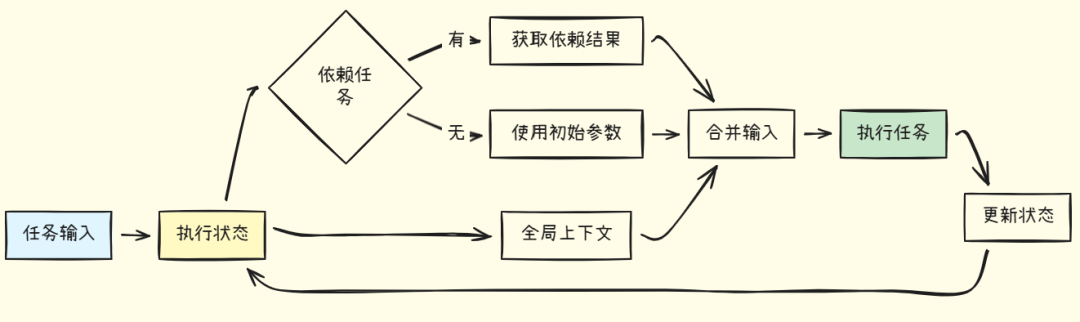
状态管理职责:
-
• 📦 存储任务结果
-
• 🔗 管理任务依赖
-
• 🌐 维护全局上下文
-
• 🔄 状态实时更新
重规划机制
何时需要重规划
重规划的五大触发条件:
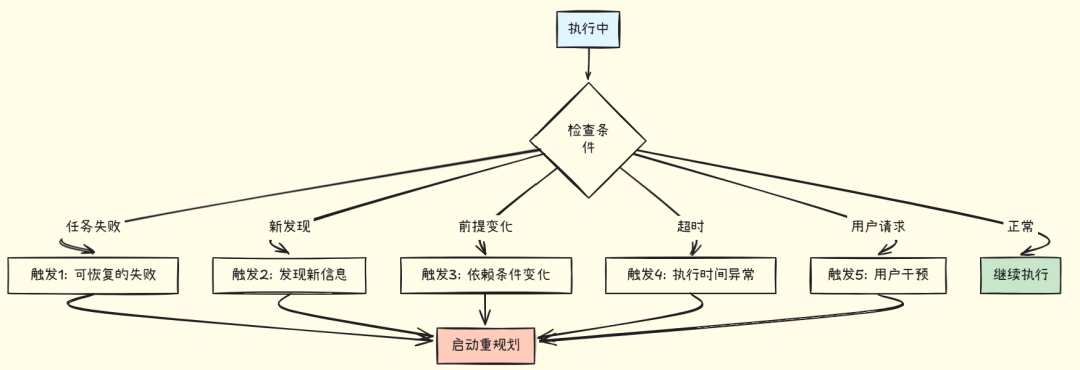
触发场景示例:
-
- ❌ 任务失败 - API 调用失败,可切换备用方案
-
- 💡 新信息 - 搜索发现更好的数据源
-
- 🔄 条件变化 - 依赖服务不可用
-
- ⏱️ 超时 - 任务耗时超过预期2倍
-
- 👤 用户干预 - 用户修改需求
重规划策略
三种重规划策略的应用场景:
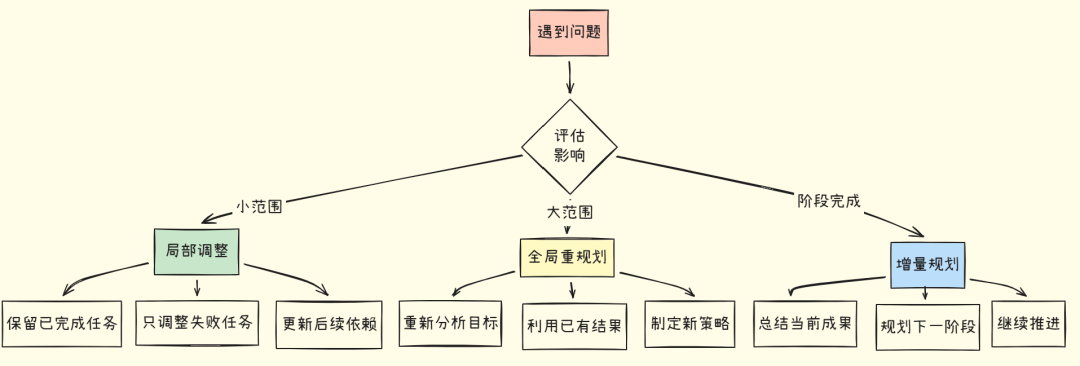
1. 局部调整
适用 :单个任务失败,影响范围小
策略:保留已完成任务,只调整失败部分及后续依赖
2. 全局重规划
适用 :发现重要新信息,需要改变整体策略
策略:基于新信息完全重新规划,但利用已有结果
3. 增量规划
适用 :长期任务,分阶段执行
策略:当前阶段完成后,规划下一阶段目标
重规划实现
重规划器的工作流程:
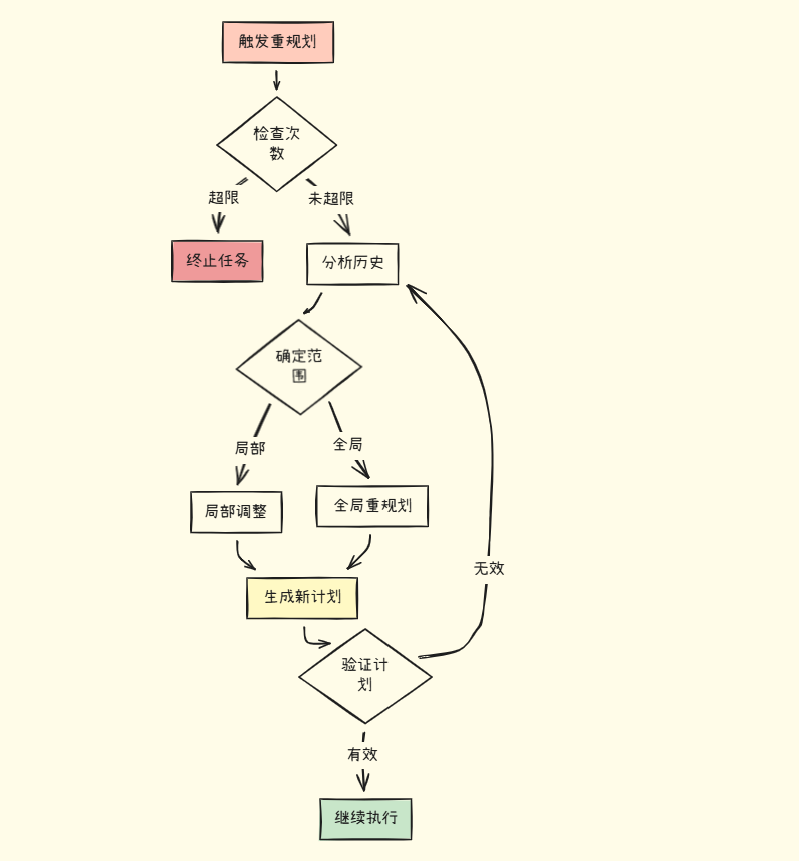
重规划的关键要素:
-
• 🔢 次数限制 - 避免无限循环
-
• 📊 历史分析 - 总结已完成和失败任务
-
• 🎯 范围判断 - 局部还是全局
-
• ✅ 计划验证 - 确保新计划可行
与其他范式的对比
了解了 Plan-and-Execute 的工作原理后,一个自然的问题是:什么时候该用它?什么时候用其他范式更好?让我们通过对比来找到答案。
Plan-and-Execute vs ReAct
这两种范式代表了两种不同的思维方式:一个强调"先谋后动",一个强调"边走边看"。下表总结了它们的核心差异:
| 维度 | Plan-and-Execute | ReAct |
|---|---|---|
| 思考方式 | 先全局规划,后执行 | 边思考边行动 |
| 适用场景 | 复杂、多步骤、可预见的任务 | 探索性、动态变化的任务 |
| 执行效率 | 高(可并行,减少重复思考) | 低(串行,每步都需思考) |
| 灵活性 | 中(需要触发重规划) | 高(每步都可调整) |
| 成本 | 低(规划用强模型,执行可用弱模型) | 高(每步都需调用 LLM) |
| 可控性 | 高(清晰的计划和进度) | 中(可能偏离目标) |
| 错误处理 | 需要重规划机制 | 自然融入思考过程 |
关键区别:Plan-and-Execute 适合"目标明确、路径清晰"的任务,而 ReAct 适合"需要探索、情况多变"的任务。
Plan-and-Execute vs CoT
| 维度 | Plan-and-Execute | CoT |
|---|---|---|
| 核心 | 任务分解 + 执行 | 推理链展示 |
| 交互 | 与外部工具交互 | 纯推理,无外部交互 |
| 适用 | 需要行动的复杂任务 | 需要推理的问题 |
| 输出 | 执行结果 | 推理过程 + 答案 |
混合使用示例
class HybridAgent:
"""混合策略智能体"""
defsolve(self, task):
# 1. 判断任务类型
task_type = self.classify_task(task)
if task_type == "complex_actionable":
# 使用 Plan-and-Execute
plan = self.planner.plan(task)
result = self.executor.execute(plan)
elif task_type == "exploratory":
# 使用 ReAct
result = self.react_agent.solve(task)
elif task_type == "reasoning":
# 使用 CoT
result = self.cot_agent.solve(task)
else:
# 混合使用
# 先用 Plan-and-Execute 制定大框架
high_level_plan = self.planner.plan(task)
# 对每个子任务,根据需要选择 ReAct 或 CoT
for subtask in high_level_plan.steps:
if subtask.requires_exploration:
result = self.react_agent.solve(subtask)
else:
result = self.simple_executor.execute(subtask)
return result实际应用场景
理论固然重要,但 Plan-and-Execute 的真正价值体现在实际应用中。让我们通过几个典型场景,看看这种范式如何解决真实世界的复杂问题。
场景1:数据分析报告生成
这是 Plan-and-Execute 的经典应用场景。数据分析任务通常包含多个清晰的步骤,且步骤之间有明确的依赖关系,非常适合先规划后执行。
# 用户任务
task = "分析我们公司过去一年的销售数据,生成详细的分析报告"
# Plan-and-Execute 方案
plan = {
"goal": "生成年度销售分析报告",
"steps": [
{
"id": 1,
"task": "从数据库提取销售数据",
"tool": "database_query",
"sql": "SELECT * FROM sales WHERE year = 2024"
},
{
"id": 2,
"task": "数据清洗和预处理",
"tool": "data_processing",
"dependencies": [1]
},
{
"id": 3,
"task": "计算关键指标(总销售额、增长率等)",
"tool": "data_analysis",
"dependencies": [2]
},
{
"id": 4,
"task": "生成销售趋势图表",
"tool": "visualization",
"dependencies": [2]
},
{
"id": 5,
"task": "识别畅销产品和区域",
"tool": "data_analysis",
"dependencies": [2]
},
{
"id": 6,
"task": "编写分析报告",
"tool": "document_generate",
"dependencies": [3, 4, 5]
}
]
}
# 执行优势:
# - Task 3, 4, 5 可以并行执行(都依赖 Task 2)
# - 清晰的数据流向
# - 每个步骤职责明确场景2:软件发布流程
# 用户任务
task = "准备并发布软件 v2.0 版本"
# Plan-and-Execute 方案
plan = {
"goal": "发布 v2.0 版本",
"steps": [
# 阶段1:准备工作(可并行)
{
"id": 1,
"task": "运行完整测试套件",
"tool": "test_runner",
"dependencies": []
},
{
"id": 2,
"task": "更新版本号和变更日志",
"tool": "version_manager",
"dependencies": []
},
{
"id": 3,
"task": "生成 API 文档",
"tool": "doc_generator",
"dependencies": []
},
# 阶段2:构建(依赖测试通过)
{
"id": 4,
"task": "构建生产版本",
"tool": "build_system",
"dependencies": [1, 2]
},
# 阶段3:发布(可并行)
{
"id": 5,
"task": "发布到应用商店",
"tool": "app_store_deploy",
"dependencies": [4]
},
{
"id": 6,
"task": "更新官网下载链接",
"tool": "website_update",
"dependencies": [4]
},
{
"id": 7,
"task": "发送发布公告邮件",
"tool": "email_sender",
"dependencies": [4, 3]
}
]
}场景3:客户支持自动化
# 用户问题
user_question = "我的订单 #12345 还没收到,而且无法退款"
# Plan-and-Execute 方案
plan = {
"goal": "解决客户订单问题",
"steps": [
{
"id": 1,
"task": "查询订单状态",
"tool": "order_system",
"parameters": {"order_id": "12345"}
},
{
"id": 2,
"task": "查询物流信息",
"tool": "logistics_api",
"dependencies": [1]
},
{
"id": 3,
"task": "检查退款资格",
"tool": "refund_policy_checker",
"dependencies": [1]
},
{
"id": 4,
"task": "生成解决方案",
"tool": "solution_generator",
"dependencies": [2, 3],
"logic": """
if 物流显示已签收:
告知客户并提供签收凭证
elif 物流异常:
提供补发或退款选项
elif 符合退款条件:
启动退款流程
else:
转人工处理
"""
},
{
"id": 5,
"task": "发送回复给客户",
"tool": "email_sender",
"dependencies": [4]
}
]
}