论文标题:AN EFFICIENT AND MIXED HETEROGENEOUS MODEL FOR IMAGE RESTORATION
论文原文 (Paper) :https://arxiv.org/abs/2504.10967
代码 (code) :https://github.com/ClimBin/RestorMixer
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景总结](#2.1 文本背景总结)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解](#4.2 核心创新模块详解)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [4.4 图解总结](#4.4 图解总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验部分简单分析](#6. 实验部分简单分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 RestorMixer 的通用图像复原模型,旨在打破单一架构(如纯 CNN、Transformer 或 Mamba)在处理多样化复原任务时的局限性。其核心思想是 "因地制宜,分而治之" :利用 CNN 的高效性处理高分辨率浅层特征,利用 Mamba 的线性复杂度建模全局长程依赖,并结合 Transformer 的动态注意力机制精细化局部特征。通过这种三阶异构混合设计,RestorMixer 在去雨、去雪、超分及混合退化修复等多个任务上,以极低的参数量和推理延迟实现了 SOTA 性能。
2. 背景与动机
2.1 文本背景总结
图像复原(IR)是计算机视觉的基础任务。近年来,通用型 IR 模型(General-purpose IR)成为主流,主要分为三大流派:
- CNN 基模型(如 IRNeXt):推理快,善于提取局部细节,但在长程依赖建模上乏力。
- Transformer 基模型(如 Restormer):利用 Self-Attention 建模全局或窗口关系,性能强但在高分辨率下计算开销巨大。
- Mamba 基模型(如 MambaIR):引入状态空间模型(SSM)实现线性复杂度的全局建模,但其单向扫描机制容易导致信息遗忘,且在局部精细结构恢复上不如 Attention 机制灵活。
本文动机 :既然三者各有千秋,为何不将它们结合起来?作者认为,现有的"单打独斗"模式无法应对复杂的复原挑战,因此提出了一种 混合异构(Mixed Heterogeneous) 的架构设计思路。
2.2 动机图解分析
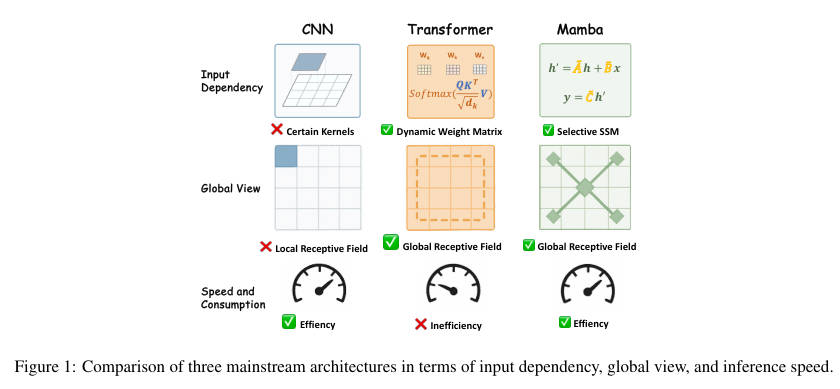
看图说话与痛点分析:
- 左侧 (CNN) :我们可以看到 CNN(蓝色)虽然在 推理速度 (Speed) 上表现优异(Effiency),但由于卷积核的物理限制,它缺乏 全局感受野 (Global View) 和 输入依赖性 (Input Dependency),即它是静态的,无法根据输入内容动态调整权重。
- 中间 (Transformer) :Transformer(黄色)拥有强大的动态权重(Dynamic Weight Matrix)和全局/窗口感受野,但其计算复杂度随 token 数量二次增长,导致 效率低下 (Inefficiency),尤其是在处理大图时。
- 右侧 (Mamba) :Mamba(绿色)虽然兼顾了全局感受野和线性效率,但其原始设计在处理二维图像时存在扫描方向带来的 空间信息割裂 问题。
- 总结:这张雷达图清晰地展示了现有方法的"技能点"偏差。RestorMixer 的目标就是填补这些短板,设计一个在"全局视野"、"动态性"和"效率"三维雷达图上都拉满的模型。
3. 主要创新点
- 三阶异构混合架构 (RestorMixer):首创性地在编码器-解码器的不同阶段分别部署 CNN、Mamba 和 Transformer 模块,根据特征分辨率的特性进行最优匹配。
- 增强记忆视觉 Mamba (EMVM):针对 Mamba 的遗忘问题,设计了基于下采样和四向扫描的改进模块,显著减少了计算冗余并增强了长序列的记忆能力。
- 多尺度窗口自注意力 (MWSA):引入动态窗口机制(从小窗到大窗),弥补了 Mamba 在局部精细特征捕捉上的不足,实现了局部与半全局信息的动态聚合。
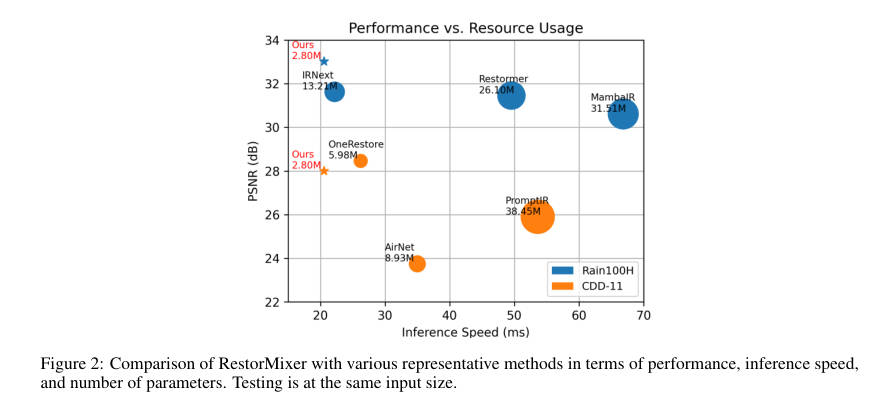
- 极致的性能-效率平衡:在 Rain100H、CSD 等数据集上刷新 SOTA,同时参数量(2.80M)和 FLOPs 远低于 Restormer 等竞品(见 Figure 2)。
4. 方法细节
4.1 整体网络架构
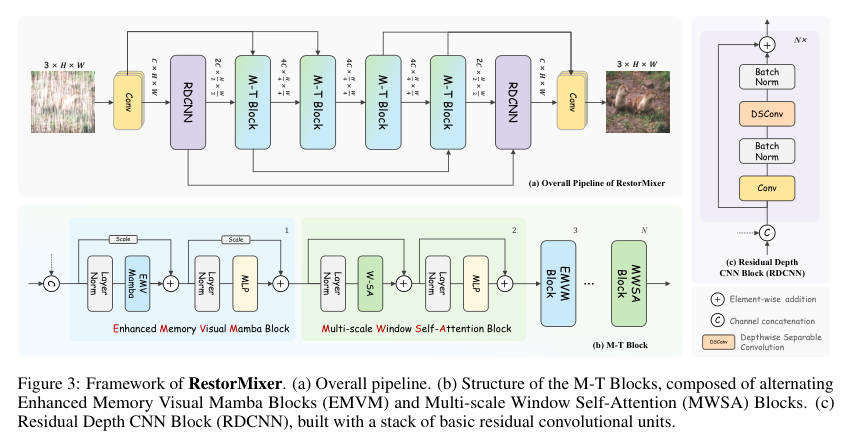
数据流详解 :
RestorMixer 采用经典的三级 U-Net 风格编码器-解码器 结构:
- 输入与浅层特征提取:输入图像首先经过一个 卷积扩展通道。
- 第一阶段(高分辨率)- CNN 主场:
- 由于特征图分辨率最高(H×W),为了节省计算量,这里使用了 RDCNN Block(残差深度卷积模块)。它利用 CNN 的归纳偏置快速提取浅层局部特征,避免了在高分辨率下使用 Attention 的巨大开销。
- 下采样:通过步长为 2 的卷积进行下采样,进入下一阶段。
- 第二、三阶段(低分辨率)- Mamba & Transformer 协同:
- 特征图变小后,计算压力减小,此时引入 M-T Block。
- M-T Block 交替堆叠了 EMVM (负责全局建模)和 MWSA(负责局部精细化),充分利用深层语义信息。
- 解码与输出:通过上采样逐级恢复分辨率,并利用跳跃连接融合编码器特征,最终输出残差图像。
4.2 核心创新模块详解
核心模块 A:增强记忆视觉 Mamba (EMVM)
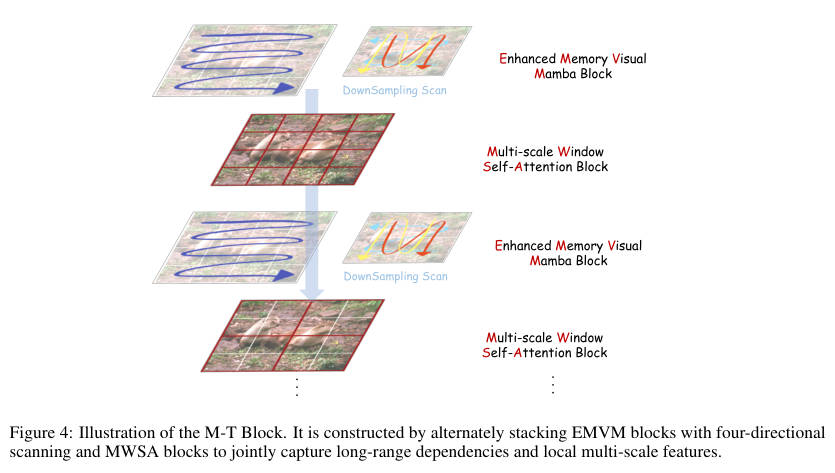
-
内部结构拆解:
-
输入处理:输入特征 首先经过 LayerNorm。
-
四向扫描与下采样 (Downsampling Scan) :这是最大的创新。不同于传统的全分辨率四向扫描(计算量大且易冗余),EMVM 先将特征图 下采样 (Downsample),然后再进行水平/垂直的正反向扫描(Horizontal/Vertical Forward/Backward)。
-
Selective SSM:在降维后的序列上执行选择性状态空间模型(Mamba 核心),捕捉全局依赖。
-
上采样与融合:处理后的特征被上采样回原尺寸,并与原始特征进行加权残差连接。
-
设计目的:下采样策略不仅降低了 FLOPs,还通过缩短序列长度,间接缓解了 SSM 在处理超长序列时的"记忆遗忘"问题,实现了"少花钱多办事"。
核心模块 B:多尺度窗口自注意力
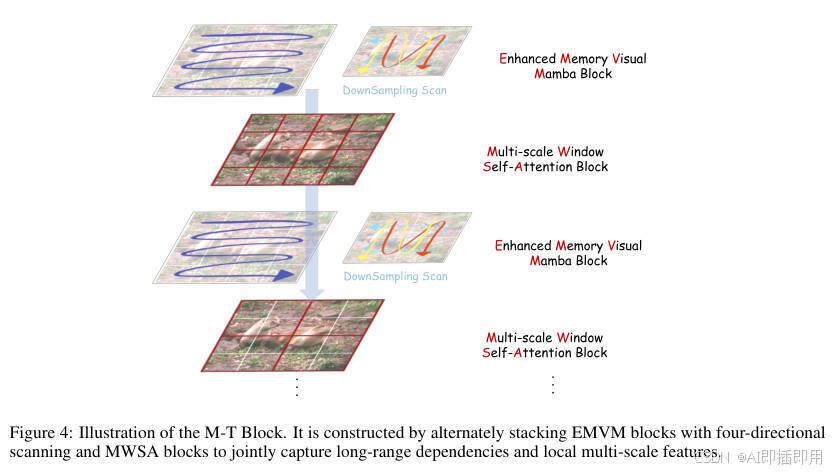
-
内部结构拆解:
-
动态窗口 :该模块不使用固定的窗口大小,而是采用 多尺度策略。例如,第一层使用 的小窗口关注极细微的纹理,下一层则扩大到 甚至更大。
-
Window Self-Attention:在划分好的窗口内计算标准的自注意力,利用其动态权重矩阵(Input-dependent)精修特征。
-
设计目的:Mamba 虽然有全局视野,但对局部高频细节(如雨痕边缘)的捕捉不如 Attention 敏感。MWSA 作为 Mamba 的补充,专门负责在局部区域内进行"精雕细琢"。
4.3 理念与机制总结
RestorMixer 的设计哲学是 互补(Complementarity)。
- 高低频互补:RDCNN 负责高频细节,EMVM 负责低频结构。
- 局域全域互补 :MWSA 负责窗口内的动态关联,EMVM 负责全图的上下文连通。
其数学表达可以概括为:
其中混合块采用了交替更新机制:,确保特征流在全局和局部视角间不断切换与校准。
4.4 图解总结
回到 动机图解 (Figure 1),RestorMixer 通过:
- RDCNN 保持了 CNN 的推理速度优势(Speed)。
- EMVM 赋予了模型 Mamba 级的全局视野(Global View)。
- MWSA 引入了 Transformer 的输入依赖性(Input Dependency)。
从而完美解决了单一架构只能占据雷达图一角的问题,实现了全方位的覆盖。
5. 即插即用模块的作用
本论文提出的 EMVM (Enhanced Memory Visual Mamba) 模块具有极高的通用性。
-
适用场景:
-
计算资源受限的全局建模:如果你正在做移动端的图像处理,且需要全局感受野,EMVM 的下采样扫描机制可以大幅降低显存占用。
-
长序列视觉任务:如视频复原或高分辨率医学图像分割,EMVM 能有效缓解长序列遗忘。
-
具体应用:
-
替换 U-Net 的 Bottleneck:可以直接将 EMVM 插入到现有 U-Net 的最底层,增强全局上下文捕捉能力。
-
YOLO 系列改进:可以将 YOLO 的 Backbone 或 Neck 中的部分 CSP 模块替换为 EMVM,以增强对大物体或背景的理解能力(需注意推理速度权衡)。
6. 实验部分简单分析
论文在去雨、超分、去雪和混合退化四个任务上进行了全面验证。
- 单任务表现 (去雨/超分/去雪):
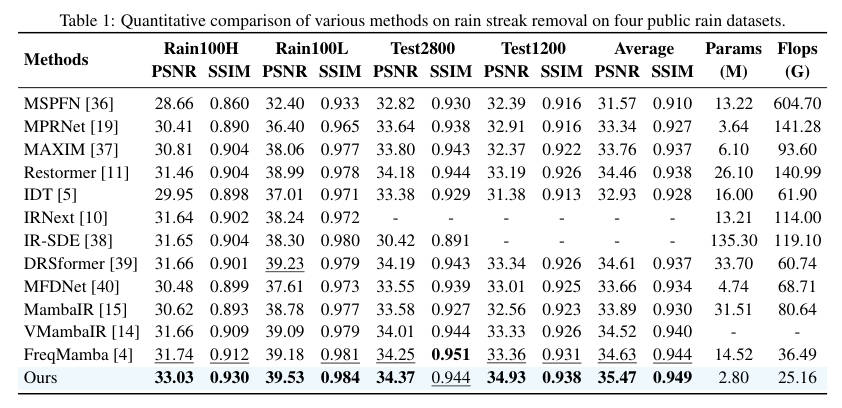
- 去雨 (Rain100H) :RestorMixer 达到了 33.03 dB 的 PSNR,比 MambaIR 高出不少,且参数量仅为 2.8M。
- 超分 (Div2K):在轻量级设定下,其性能与 SwinIR、MambaIR 相当,但计算开销更低。
- 混合退化 (Mixed Degradation):
- 在 CDD-11 数据集上,RestorMixer 展现了强大的通用性,超越了专为混合任务设计的 OneRestore 模型。
- 效率分析 (Efficiency):
- 推理速度:在处理 图片时,RestorMixer 耗时约 20ms,远快于 Restormer (135ms+),甚至优于纯 CNN 的 IRNeXt。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。