DBT(Data Build Tool)
核心定位:ELT 中的 "T"
官网:https://docs.getdbt.com/docs/introduction
我们使用dbt core 开源免费
dbt Cloud vs dbt Core
| 特性 | dbt Core (开源) | dbt Cloud (企业版) |
|---|---|---|
| 调度 | 需要外部工具 (Airflow, etc.) | 内置调度器 |
| CI/CD | 需要自行设置 | 内置 PR 环境、自动化测试 |
| 界面 | 命令行 | Web IDE、监控面板 |
| 协作 | 有限 | 团队协作、权限管理 |
| 成本 | 免费 | 按用量付费 |
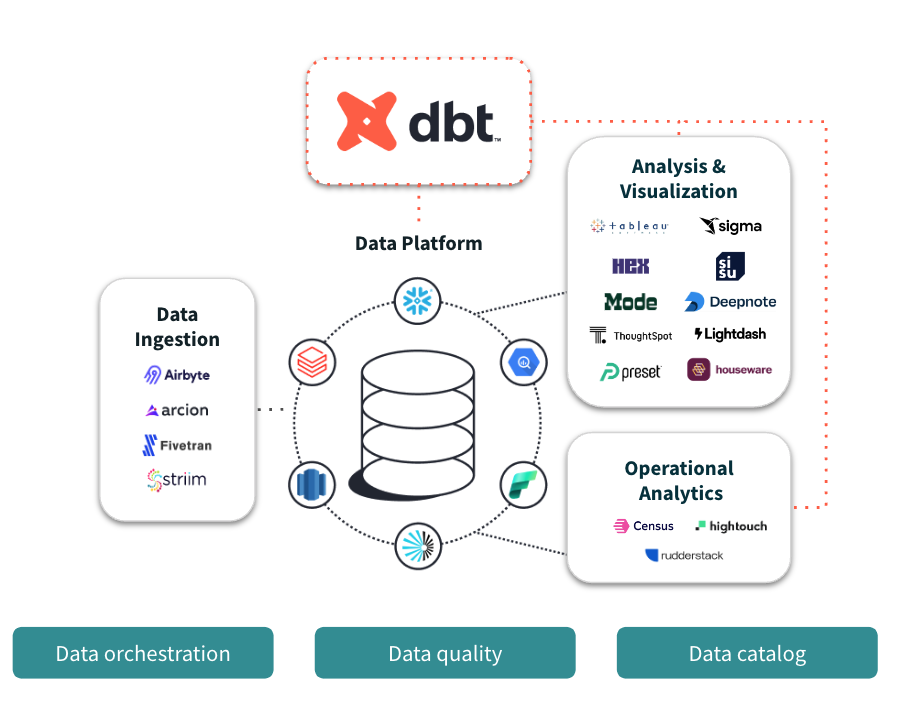
目标:
1.好的清洗流程开发体验
2.支持全量、增量清洗
3.支持多维度清洗-城市维度、项目维度
4.清洗支持多任务并行
5.清洗可以做到近实时清洗
6.支持维护节点依赖关系
7.现有工作流集成
dbt 核心定位与特性
dbt 是专注于数据转换阶段的开源工具,采用声明式建模方式。用户只需定义数据模型逻辑,dbt 自动生成并执行 SQL。关键特性包括:
| 关键特性 | 说明 |
|---|---|
| "做什么"而非"怎么做" | 声明式建模:定义 users.yml 中的模型逻辑,dbt 自动推导依赖和执行顺序。 |
| 只有 SQL + Jinja 模板 | 不引入新语言,降低学习成本;Jinja 提供变量、循环、条件等模板能力,提升 SQL 的动态性和复用性。 |
| 专为现代数据仓库设计 | 直接运行在 Snowflake、BigQuery、Redshift、Databricks 等数仓之上,利用其强大计算能力做转换(ELT 模式)。 |
| 内置 DAG 与依赖管理 | 使用 ref() 函数引用模型,dbt 自动解析依赖关系图(DAG),确保按正确顺序执行。 |
| 高度模块化与可复用 | 通过 macros(宏)封装通用逻辑(如日期处理、指标计算),实现跨项目代码复用。 |
| 自动生成文档网站 | 解析模型、字段注释、血缘关系,一键生成交互式文档站点,便于团队协作和数据治理。 |
| 内置数据质量测试 | 支持唯一性、非空、外键、自定义 SQL 断言等测试,可在 CI/CD 或调度流程中自动运行。 |
| 原生支持 Git 与 CI/CD | 所有代码即配置(YAML、SQL、.yml),天然适合版本控制,易于集成 GitHub Actions、GitLab CI 等自动化流程。 |
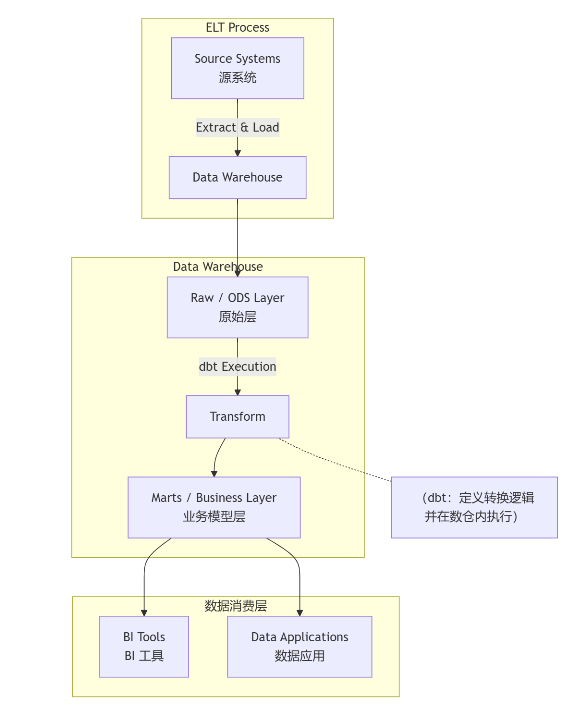
dbt 的工作流程(典型 ELT 流程中的位置)
与"阿里云清洗数据平台"类产品的对比
| 维度 | dbt | 阿里云 DataWorks 等平台 |
|---|---|---|
| 架构模式 | ELT(转换在数仓内完成) | ETL(外部计算引擎如 MaxCompute) |
| 技术栈 | SQL + Jinja + YAML(代码优先) | 图形化拖拽 + SQL/PyODPS(平台化) |
| 部署方式 | 开源/私有化/SaaS(dbt Cloud) | 云厂商封闭平台,绑定阿里云生态 |
| 灵活性 | 高(完全掌控 SQL 和逻辑) | 中(受限于平台组件和调度机制) |
| 版本控制 | 原生 Git 集成,CI/CD 成熟 | 支持较弱,需配合外部系统 |
| 学习曲线 | 需熟悉 SQL、DAG、Jinja | 图形化易上手,适合初级开发者 |
| 适用团队 | 工程化、DevOps 化数据团队 | 企业级多角色协作(开发/运维/管理员) |
| 成本模型 | 开源免费或按 seat 收费 | 按资源使用量 + 功能模块计费 |
●dbt 更像"数据工程师的代码框架",强调代码化、版本化、自动化,适合追求敏捷、可复用、高质量数据产品的团队。
●DataWorks 更像"企业级数据中台操作系统",强调可视化、流程管控、权限治理,适合需要统一管理、跨部门协作的大型组织。
●dbt也是重点在Snowflake / BigQuery / Redshift 等现代数仓数据清洗
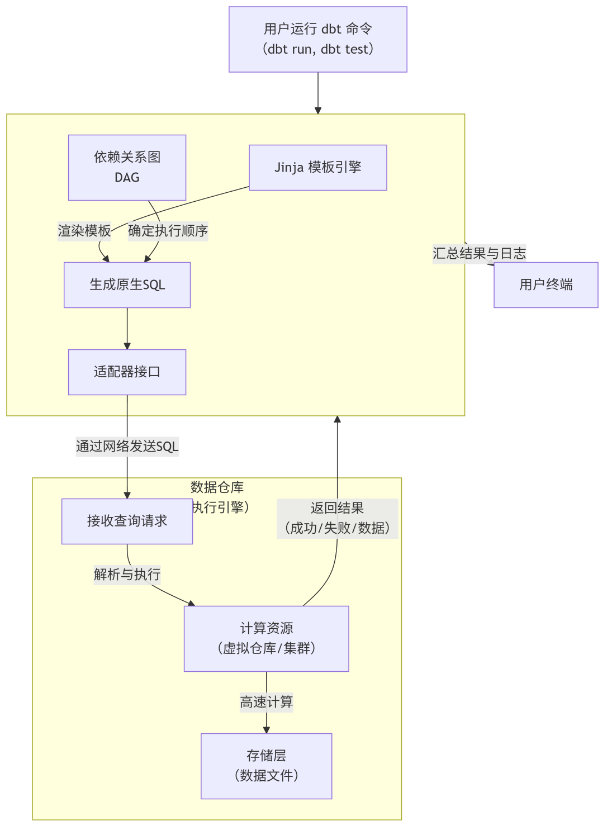
dbt工作原理
开发体验优势
- 熟悉的 SQL + Jinja 组合,支持动态逻辑(循环、条件等)
sql
{% for country in ['CN', 'US', 'UK'] %}
SELECT * FROM raw_orders WHERE country = '{{ country }}'
{% if not loop.last %} UNION ALL {% endif %}
{% endfor %}- 声明式依赖管理(
ref()和source()函数)
sql
-- model: fct_orders.sql
SELECT
o.order_id,
u.user_name
FROM {{ ref('stg_orders') }} o
JOIN {{ ref('stg_users') }} u ON o.user_id = u.user_id这种"模块化"思维让数据建模更像软件开发。
-
本地快速验证(
dbt run/test/compile)可通过 dbt run, dbt test, dbt compile 在本地快速验证逻辑。
○dbt compile 可查看 Jinja 渲染后的最终 SQL,便于调试。
○结合数据库客户端(如 DBeaver、VS Code 插件),可直接运行片段进行测试。
-
自动生成包含血缘关系的文档网站
-
有dbt开发插件

全量与增量清洗实现
全量清洗流程
-
删除备份表
-
重命名目标表为备份表
-
通过查询创建新表
步骤一:删除上次运行的备份表
drop table if existspom_server.pom_project__dbt_backupcascade
步骤二:把目标表表名更改为备份表表名
rename tablepom_server.pom_projecttopom_server.pom_project__dbt_backup
步骤三:通过查询的数据创建表
create table
pom_server.`pom_project as
( 查询语句)
增量清洗流程
-
创建临时表存储查询结果
-
检查表结构一致性
-
根据临时表数据删除目标表记录
-
将临时表数据插入目标表
sql
步骤一:执行SQL文件中的创建临时表
create temporary table
`pom_server`.`pom_project__dbt_tmp` as
( 查询SQL)
步骤二:检查表结构
show columns from pom_server.pom_project__dbt_tmp
show columns from pom_server.pom_project
步骤三:根据临时表唯一值删除目标表数据
delete
from `pom_server`.`pom_project`
where (id) in (
select id
from `pom_server`.`pom_project__dbt_tmp`
)
步骤四:临时表数据插入到目标表中
insert into `pom_server`.`pom_project` (`id`, `city`, `city_type`, `region_name`, `proj_name`, `proj_state`, `proj_adress`, `avg_price`, `s_room_use`, `proj_build_area_summary`, `s_developer`, `latitude`, `longitude`, `sector`, `total_price`, `platform_type_count`, `is_enterprise_verified`, `created_at`, `updated_at`, `launch_time`, `delivery_time`, `project_features`, `property_category`, `sales_status`, `pre_sale_license`, `top_developer_name`, `main_area`, `data_crawled_date`, `master_id`, `is_deleted`, `dt_timestamp`, `dt_timestamp_unique`)
(
select `id`, `city`, `city_type`, `region_name`, `proj_name`, `proj_state`, `proj_adress`, `avg_price`, `s_room_use`, `proj_build_area_summary`, `s_developer`, `latitude`, `longitude`, `sector`, `total_price`, `platform_type_count`, `is_enterprise_verified`, `created_at`, `updated_at`, `launch_time`, `delivery_time`, `project_features`, `property_category`, `sales_status`, `pre_sale_license`, `top_developer_name`, `main_area`, `data_crawled_date`, `master_id`, `is_deleted`, `dt_timestamp`, `dt_timestamp_unique`
from `pom_server`.`pom_project__dbt_tmp`
)备注:针对步骤三,删除语句通过id大数据量删除执行缓慢,可以使用前置钩子进行城市条件删除
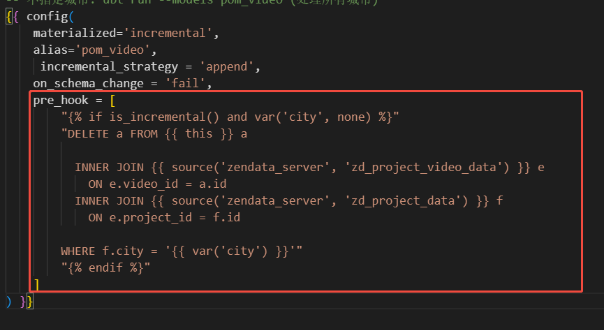
如果是Starrock可以直接插入不需要删除,根据不同数据库操作不同。
多维度清洗支持
通过变量控制清洗维度:
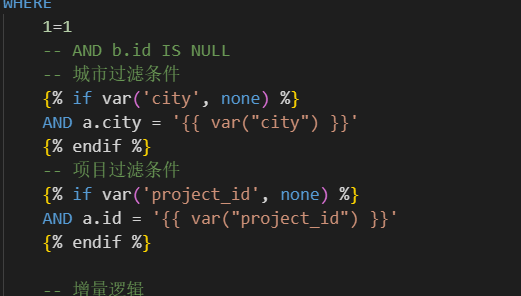
bash
# 全量城市模式
dbt run --models pom_project --vars "{'city':'北京'}"
# 增量项目模式
dbt run --models pom_project --vars "{'project_id':'123','is_incremental':true}"关键适配能力
- 并行清洗:通过 DAG 自动并行执行独立任务
- 近实时清洗:结合增量模式与高频调度
- 依赖管理:自动维护节点依赖关系
- 工作流集成:支持 CLI 和 API 调用,可与现有调度系统对接
并行冲突解决机制
A. 数据库连接隔离
●✅ 独立连接:每个dbt进程使用独立的数据库连接
●✅ 会话隔离:临时表只在当前连接中可见
●✅ 自动清理:连接关闭时临时表自动删除
B. 事务隔离
●✅ 独立事务:每个模型在独立事务中执行
●✅ 原子操作:要么全部成功,要么全部回滚
●✅ 数据一致性:确保数据完整性
C. 临时表作用域
●✅ 会话级别:临时表只在当前会话中可见
●✅ 名称唯一:__dbt_tmp 后缀确保唯一性
●✅ 自动管理:dbt自动创建和清
大多数数仓不支持会话域临时表,通过调整临时表名称随机后缀实现并行。
实施建议
- 对已有数仓且追求工程化的团队,dbt 可显著提升开发效率
- 需评估现有技术栈与 dbt 的兼容性(特别是数据库支持)
- 增量清洗性能需针对大数据量场景优化(如分区删除策略)