生活中的决策助手
想象一下,你要决定周末做什么活动。你可能会问自己一连串问题:
- 天气好吗?如果不好,就选择室内活动;如果好,就继续问...
- 有朋友一起吗?如果没有,就选择个人活动;如果有,就继续问...
- 预算是多少?如果预算低,就选择免费活动;如果预算充足,就...
这个不断提问、根据答案走向不同分支的过程,就像决策树的工作原理。在人工智能领域,决策树是最直观、最易于理解的分类算法之一,它通过一系列"如果...那么..."的规则,将复杂问题分解为简单的决策步骤。
今天,让我们一起探索决策树这个神奇的工具,看看它是如何帮助计算机"学会思考"的。
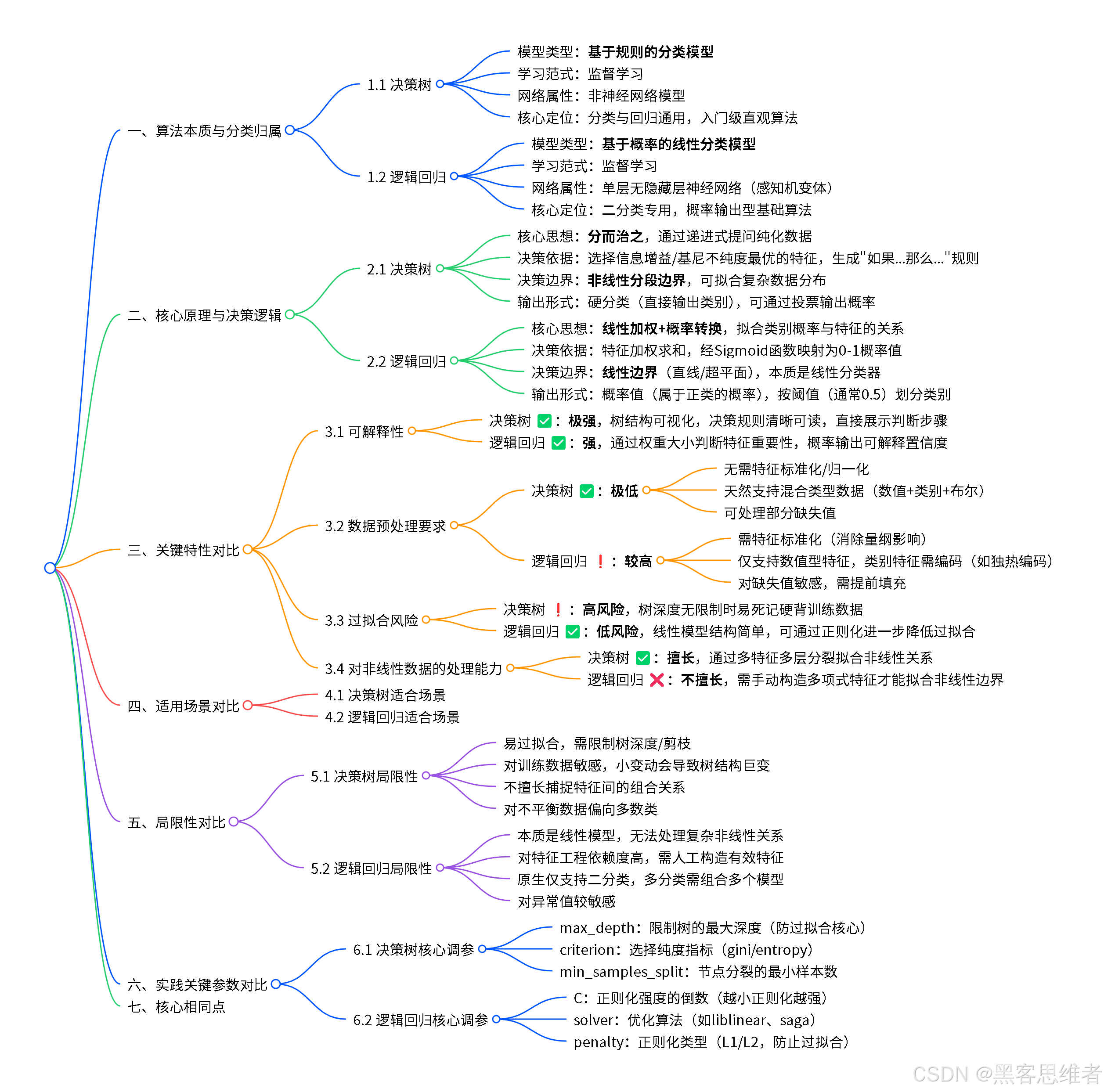
1. 分类归属:决策树在AI大家庭中的位置
1.1 按功能用途划分
决策树属于分类与回归算法 家族,是监督学习的重要成员。它不是神经网络,而是机器学习中另一大类方法的代表。
1.2 按算法特性划分
决策树属于基于规则的模型 ,与神经网络、支持向量机等基于数学函数的模型形成对比。它的核心特点是可解释性强------你可以清楚地看到它做决策的每一步逻辑,就像看一本操作手册。
1.3 在机器学习中的位置
机器学习
├── 监督学习(有标签数据)
│ ├── 基于规则的模型
│ │ └── 决策树 ← 我们今天的主角
│ ├── 基于函数的模型
│ │ ├── 神经网络
│ │ └── 支持向量机
│ └── 基于概率的模型
│ └── 朴素贝叶斯
└── 无监督学习(无标签数据)决策树虽然不属于神经网络家族,但它是机器学习入门的最佳起点,因为它的思考方式最接近人类。
2. 底层原理:像侦探破案一样寻找最佳问题
2.1 核心思想:不断提"好问题"
决策树的构建过程就像一位侦探调查案件:
- 收集线索(数据):嫌疑人的身高、体型、发型、衣着...
- 找到最有区分度的线索:什么特征最能缩小嫌疑人范围?
- 根据线索分组:高个子一组,矮个子一组
- 在每组中继续找线索:在高个子组中,再找其他区分特征
- 直到确定"凶手":最终每个小组只包含同一类人
2.2 如何选择"好问题":纯度的艺术
决策树的关键在于:每次选择最能"纯化"数据的问题。
是 否 是 否 开始:混合的水果
苹果,橙子,香蕉 问题1:颜色是红色吗? 红色组:苹果 问题2:形状是圆形吗? 圆形组:橙子 长条形组:香蕉
通俗解释 :
假设你要区分苹果、橙子和香蕉。如果你问"它甜吗?",可能大部分水果都甜,这个问题的区分效果不好。但如果你问"它是红色的吗?",就能立刻把苹果分出来------这就是"好问题"。
2.3 衡量"好坏"的数学工具
虽然我们尽量不用公式,但了解背后的原理有助于深入理解。决策树用以下指标衡量问题的"好坏":
(1)信息增益(最常用)
通俗理解:一个问题能让不确定性减少多少
- 提问前:完全不知道是什么水果(不确定性高)
- 提问后:如果是红色,基本确定是苹果(不确定性低)
- 信息增益 = 提问前的不确定性 - 提问后的平均不确定性
数学表达(了解即可):
信息增益 = 父节点的熵 - 子节点的加权平均熵其中熵(Entropy)衡量混乱程度:
熵 = -Σ(p_i × log₂(p_i))
p_i是第i类所占比例(2)基尼不纯度
通俗理解:从数据中随机抽两个样本,它们属于不同类的概率
- 概率越低,说明这个组越"纯"
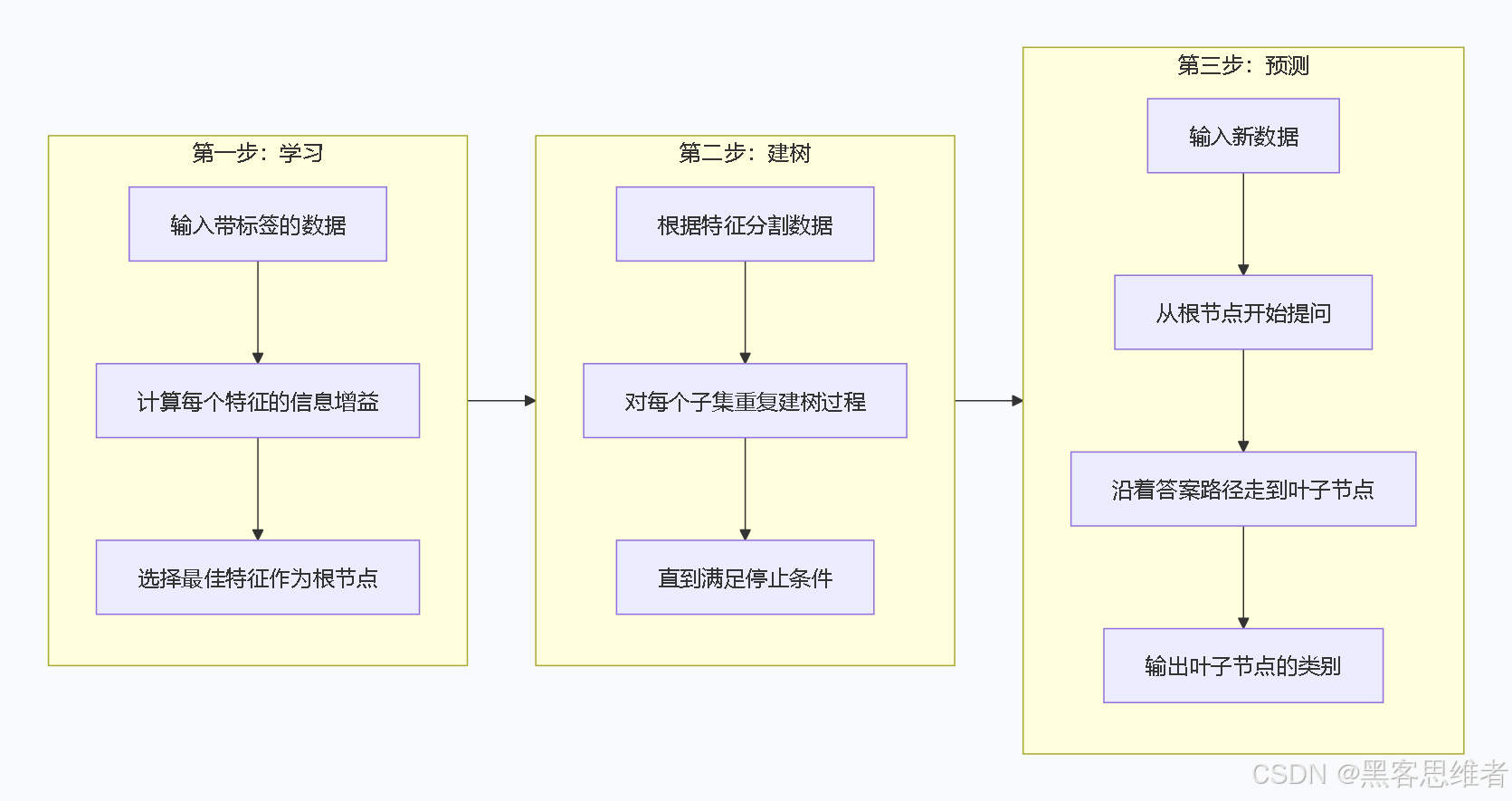
2.4 决策树的三段式工作流程
2.5 防止"过度提问":停止条件
就像审讯时不能无休止地问问题,决策树也需要停止条件:
- 所有样本属于同一类:已经纯净了,无需再分
- 没有更多特征可用:所有问题都问过了
- 树的深度达到限制:防止树太复杂
- 节点样本数太少:再分下去没有统计意义
3. 局限性:没有完美的工具
3.1 容易"死记硬背"------过拟合问题
问题描述 :
决策树可能把训练数据中的每一个细节都记住,包括噪声和偶然特征。
生活类比 :
学生A:理解知识点,掌握核心原理(好的决策树)
学生B:死记硬背所有例题,但不会举一反三(过拟合的决策树)
当遇到新考题(新数据)时:
- 学生A能正确解答
- 学生B因为没见过完全一样的题而做错
为什么会有这个问题 :
决策树可以无限生长,直到每个叶子节点只有一个样本------这样在训练数据上准确率100%,但对新数据效果很差。
3.2 对"小变动"敏感------不稳定性
问题描述 :
训练数据稍微改变,可能生成完全不同的树。
生活类比 :
根据今天见到的10个人(训练数据)总结"穿西装的是老板":
- 周一见到的10个人:8个穿西装的是老板 → 得出规则
- 周二见到的10个人:只有2个穿西装的是老板 → 得出相反规则
为什么会有这个问题 :
决策树在每一步都选择"当前最佳"特征,数据的小变化可能导致完全不同的选择。
3.3 不擅长发现"组合特征"
问题描述 :
决策树关注单个特征的效果,不擅长发现特征之间的复杂关系。
例子 :
判断是否批准贷款:
- 好规则:如果(收入高 且 信用好)或(抵押物充足 且 工作稳定)
- 决策树可能分开考虑:收入高吗?信用好吗?...
为什么会有这个问题 :
决策树是"贪心算法"------每一步只考虑当前最优,不考虑特征的组合效果。
3.4 对"倾斜数据"处理不佳
问题描述 :
当某一类样本远多于其他类时,决策树容易偏向多数类。
例子 :
100个病人中:
- 95个健康,5个患病
- 决策树可能直接判断"所有人都健康",这样准确率95%!
- 但完全漏掉了病人------这不是我们想要的
4. 使用范围:适合什么,不适合什么
4.1 决策树擅长处理的场景 ✅
(1)需要可解释性的场合
- 医疗诊断:医生需要知道"为什么判断为糖尿病"
- 信贷审批:法律要求说明"为什么拒绝贷款"
- 客户分群:市场部门需要理解客户分类规则
(2)数据混合了不同类型
- 既有数字(年龄、收入)
- 又有类别(性别、职业)
- 还有是否(是否有房、是否结婚)
决策树可以天然处理混合类型,无需像神经网络那样需要统一标准化。
(3)有缺失值的数据
决策树可以处理部分特征缺失的情况,不像有些算法要求完整数据。
(4)非线性关系
决策树可以捕捉复杂的"如果...并且...或者..."关系,无需假设数据是线性的。
4.2 决策树不擅长的场景 ❌
(1)需要极高精度的预测
- 人脸识别:需要99.9%以上的准确率
- 自动驾驶:安全要求极高
在这些场景,深度学习通常表现更好。
(2)特征间有复杂数学关系
- 图像识别:像素间的空间关系复杂
- 语音识别:时间序列的长期依赖
决策树难以捕捉这种深层次模式。
(3)数据维度极高
当特征成千上万时(如基因数据):
- 决策树选择困难:从10000个特征中找最佳?
- 容易过拟合:总能找到区分训练数据的特征
(4)需要概率估计
决策树输出的是"硬分类"(是或否),而不是"属于各类的概率"。
5. 应用场景:决策树在生活中的身影
5.1 医疗诊断:辅助医生判断疾病
场景 :
患者来到医院,描述症状:发烧、咳嗽、乏力...
决策树的作用:
发烧吗?
├── 是 → 咳嗽吗?
│ ├── 是 → 检测流感病毒 → 阳性 → 诊断:流感
│ └── 否 → 有其他症状吗?...
└── 否 → 继续其他检查...价值:
- 帮助年轻医生系统化思考
- 减少漏诊、误诊
- 解释性强:可以告诉患者"因为你有A、B、C症状,所以怀疑是X病"
5.2 金融风控:银行信贷审批
场景 :
小明向银行申请10万元消费贷款。
决策树的作用:
月收入 > 1万元?
├── 是 → 信用记录良好?
│ ├── 是 → 现有负债 < 5万元?
│ │ ├── 是 → **批准,利率5%**
│ │ └── 否 → 需要进一步审核
│ └── 否 → **拒绝**
└── 否 → 有抵押物吗?
├── 是 → **批准,利率8%**(高风险,高利率)
└── 否 → **拒绝**价值:
- 标准化审批流程,减少人为偏差
- 快速处理大量申请
- 满足监管要求:可以明确说明拒绝原因
5.3 电商推荐:预测用户购买意向
场景 :
小华浏览电商网站,系统判断他是否可能购买某款相机。
决策树的作用:
用户过去3个月买过电子产品?
├── 是 → 浏览过相机详情页?
│ ├── 是 → 在页面停留 > 2分钟?
│ │ ├── 是 → **高购买意向(95%)** → 推送优惠券
│ │ └── 否 → 中等购买意向(60%)
│ └── 否 → 低购买意向(30%)
└── 否 → 根据其他特征判断...价值:
- 提高营销转化率
- 个性化用户体验
- 避免对低意向用户过度打扰
5.4 人力资源管理:员工离职预测
场景 :
公司想提前识别可能离职的员工,以便采取措施挽留。
决策树的作用:
最近一次涨薪 > 6个月?
├── 是 → 加班频率 > 每周10小时?
│ ├── 是 → 有猎头联系记录?
│ │ ├── 是 → **高离职风险(90%)**
│ │ └── 否 → 中等风险(50%)
│ └── 否 → 低风险(20%)
└── 否 → 低风险(10%)价值:
- 降低员工流失成本
- 针对性地改善管理
- 提升员工满意度
5.5 制造业:产品质量检测
场景 :
工厂生产零件,需要快速判断是否合格。
决策树的作用:
尺寸误差 < 0.1mm?
├── 是 → 表面光洁度达标?
│ ├── 是 → 材料硬度合格?
│ │ ├── 是 → **合格品**
│ │ └── 否 → **不合格(材质问题)**
│ └── 否 → **不合格(工艺问题)**
└── 否 → **不合格(尺寸问题)**价值:
- 实时质量监控
- 快速定位问题环节
- 减少人工检测成本
6. Python实践:用决策树预测 Iris 花种
让我们通过一个经典案例,亲手体验决策树的魅力。我们将使用著名的鸢尾花(Iris)数据集,根据花瓣和萼片的尺寸,预测花的种类。
6.1 环境准备
python
# 首先安装必要的库(如果在本地运行)
# pip install scikit-learn matplotlib pandas numpy
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
print("环境准备完成!")6.2 加载和理解数据
python
# 加载鸢尾花数据集
iris = load_iris()
# 看看数据是什么样子
print("=== 数据基本信息 ===")
print(f"特征名称: {iris.feature_names}")
print(f"类别名称: {iris.target_names}")
print(f"数据形状: {iris.data.shape}") # 150个样本,4个特征
print(f"前5个样本的特征值:\n{iris.data[:5]}")
print(f"前5个样本的类别: {iris.target[:5]}")
# 创建DataFrame方便查看
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
df['species_name'] = df['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
print("\n=== 数据统计摘要 ===")
print(df.describe())
print("\n=== 各类别样本数量 ===")
print(df['species_name'].value_counts())6.3 可视化数据分布
python
# 让我们看看数据长什么样
plt.figure(figsize=(15, 10))
# 绘制每个特征的分布
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 3, i+1)
for species_idx, species_name in enumerate(iris.target_names):
# 提取当前类别的当前特征值
species_data = df[df['species'] == species_idx][feature]
plt.hist(species_data, alpha=0.7, label=species_name)
plt.xlabel(feature)
plt.ylabel('数量')
plt.legend()
plt.title(f'{feature}的分布')
plt.tight_layout()
plt.show()
# 绘制特征间的关系散点图
plt.figure(figsize=(12, 10))
# 选择两个最有区分度的特征
plt.scatter(df['petal length (cm)'], df['petal width (cm)'],
c=df['species'], cmap='viridis', alpha=0.7, s=50)
plt.xlabel('花瓣长度 (cm)')
plt.ylabel('花瓣宽度 (cm)')
plt.title('鸢尾花分类:花瓣长度 vs 花瓣宽度')
plt.colorbar(ticks=[0, 1, 2], label='花的种类')
plt.show()6.4 构建和训练决策树
python
# 准备数据
X = iris.data # 特征
y = iris.target # 标签
# 分割数据:80%训练,20%测试
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # stratify确保各类别比例一致
)
print("=== 数据分割结果 ===")
print(f"训练集大小: {X_train.shape[0]} 个样本")
print(f"测试集大小: {X_test.shape[0]} 个样本")
# 创建决策树模型
# 设置最大深度为3,防止过拟合,也便于可视化
tree_model = DecisionTreeClassifier(
max_depth=3, # 树的最大深度
random_state=42, # 确保结果可重现
criterion='gini' # 使用基尼不纯度作为分裂标准
)
# 训练模型
tree_model.fit(X_train, y_train)
print("\n=== 模型训练完成 ===")
print(f"训练准确率: {tree_model.score(X_train, y_train):.2%}")6.5 可视化决策树
python
# 可视化决策树
plt.figure(figsize=(15, 10))
plot_tree(tree_model,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, # 填充颜色
rounded=True, # 圆角
fontsize=10)
plt.title("决策树结构可视化", fontsize=16)
plt.show()
# 打印文本形式的树规则
print("=== 决策树规则(文本形式)===")
# 定义函数来提取规则
def tree_to_rules(tree, feature_names, class_names, node_index=0, depth=0, rule=""):
"""递归提取决策树规则"""
indent = " " * depth
# 如果是叶子节点
if tree.children_left[node_index] == -1:
# 获取该节点的类别分布
values = tree.value[node_index][0]
# 找到最多的类别
predicted_class = np.argmax(values)
probability = values[predicted_class] / np.sum(values)
print(f"{indent}如果{rule},那么预测为 {class_names[predicted_class]} "
f"(置信度: {probability:.1%})")
return
# 获取分裂信息
feature = feature_names[tree.feature[node_index]]
threshold = tree.threshold[node_index]
# 左子树(特征 <= 阈值)
left_rule = f"{rule} 且 {feature} <= {threshold:.2f}" if rule else f"{feature} <= {threshold:.2f}"
tree_to_rules(tree, feature_names, class_names,
tree.children_left[node_index], depth+1, left_rule)
# 右子树(特征 > 阈值)
right_rule = f"{rule} 且 {feature} > {threshold:.2f}" if rule else f"{feature} > {threshold:.2f}"
tree_to_rules(tree, feature_names, class_names,
tree.children_right[node_index], depth+1, right_rule)
# 获取树的内部结构
tree_structure = tree_model.tree_
tree_to_rules(tree_structure, iris.feature_names, iris.target_names)6.6 评估模型性能
python
# 在测试集上预测
y_pred = tree_model.predict(X_test)
print("=== 模型评估结果 ===")
print(f"测试集准确率: {accuracy_score(y_test, y_pred):.2%}")
print("\n=== 详细分类报告 ===")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 创建混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names,
yticklabels=iris.target_names)
plt.title('混淆矩阵 - 决策树分类结果')
plt.ylabel('真实类别')
plt.xlabel('预测类别')
plt.show()
# 查看特征重要性
feature_importance = pd.DataFrame({
'特征': iris.feature_names,
'重要性': tree_model.feature_importances_
}).sort_values('重要性', ascending=False)
print("\n=== 特征重要性排序 ===")
print(feature_importance)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['特征'], feature_importance['重要性'])
plt.xlabel('重要性')
plt.title('决策树中各特征的重要性')
plt.gca().invert_yaxis() # 最重要的在顶部
plt.show()6.7 尝试预测新样本
python
# 让我们用自己编的数据试试
print("=== 尝试预测新样本 ===")
# 创建几个虚拟的鸢尾花样本
new_samples = np.array([
# 样本1:小花瓣,窄花瓣 - 可能是setosa
[5.0, 3.5, 1.5, 0.3],
# 样本2:中等花瓣 - 可能是versicolor
[6.0, 2.8, 4.5, 1.5],
# 样本3:大花瓣 - 可能是virginica
[7.5, 3.0, 6.0, 2.5],
])
# 进行预测
predictions = tree_model.predict(new_samples)
prediction_probs = tree_model.predict_proba(new_samples)
print("\n预测结果:")
for i, sample in enumerate(new_samples):
predicted_class = iris.target_names[predictions[i]]
probabilities = prediction_probs[i]
print(f"\n样本{i+1}:")
print(f" 特征值: 花萼长={sample[0]:.1f}cm, 花萼宽={sample[1]:.1f}cm, "
f"花瓣长={sample[2]:.1f}cm, 花瓣宽={sample[3]:.1f}cm")
print(f" 预测种类: {predicted_class}")
print(f" 各类别概率: ")
for j, class_name in enumerate(iris.target_names):
print(f" {class_name}: {probabilities[j]:.1%}")
# 手动验证(根据我们看到的决策树规则)
print(f" 手动验证逻辑:")
if sample[2] <= 2.45: # 花瓣长度 <= 2.45
print(" 花瓣长度 <= 2.45cm → setosa")
elif sample[3] <= 1.75: # 花瓣宽度 <= 1.75
print(" 花瓣长度 > 2.45cm 且 花瓣宽度 <= 1.75cm → versicolor")
else:
print(" 花瓣长度 > 2.45cm 且 花瓣宽度 > 1.75cm → virginica")6.8 进阶探索:调整参数观察效果
python
# 让我们看看不同参数如何影响决策树
print("=== 探索不同参数的效果 ===")
# 测试不同最大深度
depths = [2, 3, 4, 5, 10, None] # None表示不限制深度
train_scores = []
test_scores = []
for depth in depths:
# 创建模型
model = DecisionTreeClassifier(max_depth=depth, random_state=42)
model.fit(X_train, y_train)
# 记录分数
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
train_scores.append(train_score)
test_scores.append(test_score)
print(f"最大深度={str(depth).ljust(4)}: "
f"训练准确率={train_score:.2%}, "
f"测试准确率={test_score:.2%}")
# 可视化结果
plt.figure(figsize=(10, 6))
x_labels = [str(d) if d is not None else '无限制' for d in depths]
x_positions = range(len(depths))
plt.plot(x_positions, train_scores, 'o-', label='训练准确率', linewidth=2)
plt.plot(x_positions, test_scores, 's-', label='测试准确率', linewidth=2)
plt.xlabel('决策树最大深度')
plt.ylabel('准确率')
plt.title('决策树深度对性能的影响')
plt.xticks(x_positions, x_labels)
plt.legend()
plt.grid(True, alpha=0.3)
# 标记最佳测试准确率
best_depth_idx = np.argmax(test_scores)
plt.axvline(x=best_depth_idx, color='red', linestyle='--', alpha=0.5)
plt.text(best_depth_idx+0.1, test_scores[best_depth_idx]-0.05,
f'最佳深度: {x_labels[best_depth_idx]}', color='red')
plt.show()
print("\n=== 观察总结 ===")
print("1. 深度太小(如2):模型太简单,无法学习足够模式(欠拟合)")
print("2. 深度适中(如3-5):平衡训练和测试性能")
print("3. 深度太大(如10或无限制):完美拟合训练数据,但测试性能下降(过拟合)")6.9 完整代码总结
python
# 完整的决策树鸢尾花分类代码(精简版)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 1. 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 2. 分割数据
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 创建并训练模型
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 4. 预测并评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2%}")
# 5. 预测新样本
new_flower = [[5.1, 3.5, 1.4, 0.2]] # 一个花的特征
prediction = model.predict(new_flower)
predicted_species = iris.target_names[prediction[0]]
print(f"新样本预测为: {predicted_species}")总结:决策树的核心价值与学习重点
决策树就像一位善于提问的侦探,通过一系列精心设计的问题,将复杂问题层层分解。它的核心价值在于:
一句话概括
决策树通过模仿人类"如果-那么"的思考方式,将复杂的分类问题转化为一系列简单决策,兼具直观性和实用性。
学习重点回顾
- 核心思想:找到最能区分数据的问题,不断将数据"纯化"
- 最大优点:可解释性强,规则透明,易于理解
- 主要局限:容易过拟合,对数据变化敏感
- 适用场景:需要解释性的分类问题,混合类型数据
- 实践关键:合理设置参数(如最大深度),防止过拟合
决策树是机器学习入门的绝佳起点:
- 先理解概念:把决策树看作"智能问卷"
- 再动手实践:用scikit-learn快速实现
- 关注可解释性:学会查看和解释树的结构
- 理解权衡:在模型简单性和准确性间找到平衡
记住,没有"最好"的算法,只有"最适合"的算法。决策树可能不是最强大的工具,但它是最透明的工具之一------在需要解释和信任的领域,这种透明性本身就是一种强大的力量。