文章目录
-
- 一、贝叶斯代码解析
-
- [1. 核心库导入](#1. 核心库导入)
- [2. 混淆矩阵可视化函数](#2. 混淆矩阵可视化函数)
- [3. 数据加载与预处理](#3. 数据加载与预处理)
- [4. 数据集分割](#4. 数据集分割)
- [5. 模型训练与预测](#5. 模型训练与预测)
- [6. 可视化与性能评估](#6. 可视化与性能评估)
- 二、随机森林代码解析
-
- [1. 库导入与混淆矩阵函数](#1. 库导入与混淆矩阵函数)
- [2. 数据准备](#2. 数据准备)
- [3. 随机森林模型配置与训练](#3. 随机森林模型配置与训练)
- [4. 特征重要性分析](#4. 特征重要性分析)
- [5. 模型评估与可视化](#5. 模型评估与可视化)
一、贝叶斯代码解析
1. 核心库导入
python
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import confusion_matrix
from sklearn import metrics各库作用:
pandas:数据处理与分析,用于读取CSV文件matplotlib.pyplot:数据可视化,绘制混淆矩阵sklearn.model_selection.train_test_split:数据集分割sklearn.naive_bayes.MultinomialNB:多项式朴素贝叶斯分类器sklearn.metrics.confusion_matrix:计算混淆矩阵sklearn.metrics:提供多种评估指标
2. 混淆矩阵可视化函数
python
def cm_plot(y, yp):
cm = confusion_matrix(y, yp) # 计算混淆矩阵
plt.matshow(cm, cmap=plt.cm.Blues) # 使用热力图显示矩阵
plt.colorbar() # 添加颜色条
for x in range(len(cm)):
for y_ in range(len(cm)):
plt.annotate(cm[x, y_], xy=(y_, x), horizontalalignment='center',
verticalalignment='center') # 在图上标注数值
plt.ylabel('True label') # y轴标签
plt.xlabel('Predicted label') # x轴标签
return plt3. 数据加载与预处理
python
data = pd.read_csv(r"spambase.csv")
X_whole = data.iloc[:, :-1] # 所有行,除最后一列外的所有列
y_whole = data.iloc[:, -1] # 所有行,最后一列方法详解:
pd.read_csv():读取CSV文件header=None:指定文件无列名
iloc:基于位置的索引[:, :-1]:所有行,从第一列到倒数第二列[:, -1]:所有行,最后一列
4. 数据集分割
python
x_train, x_test, y_train, y_test = train_test_split(
X_whole,
y_whole,
test_size=0.3,
random_state=1000
)train_test_split参数详解:
test_size=0.3:测试集占30%,训练集占70%random_state=1000:随机种子,确保每次分割结果一致- 返回值:
(训练特征, 测试特征, 训练标签, 测试标签)
5. 模型训练与预测
python
classifier = MultinomialNB(alpha=1)
classifier.fit(x_train, y_train)
train_pred = classifier.predict(x_train)
test_pred = classifier.predict(x_test)MultinomialNB参数详解:
alpha=1:拉普拉斯平滑参数- 避免零概率问题
- 默认值为1.0
- 值越大,平滑程度越高
关键方法:
fit(X, y):训练模型predict(X):预测类别predict_proba(X):预测概率
6. 可视化与性能评估
python
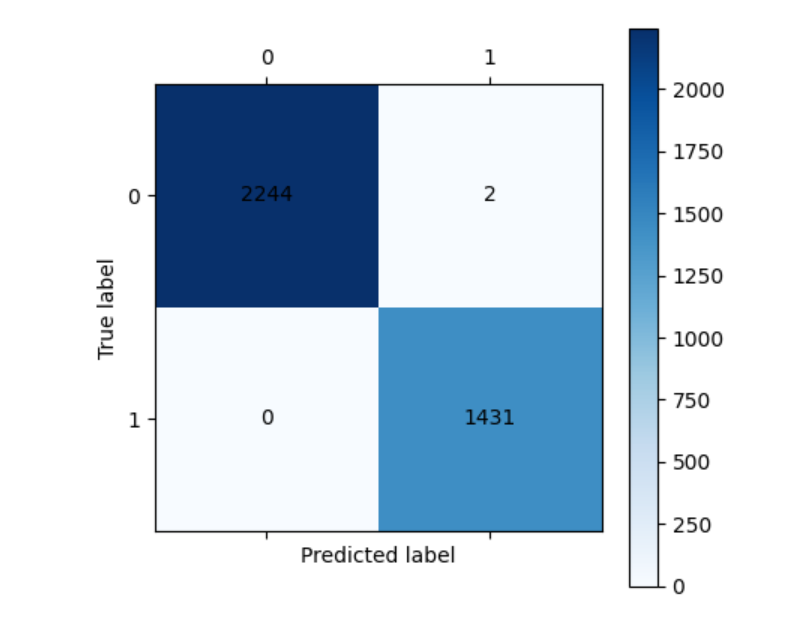
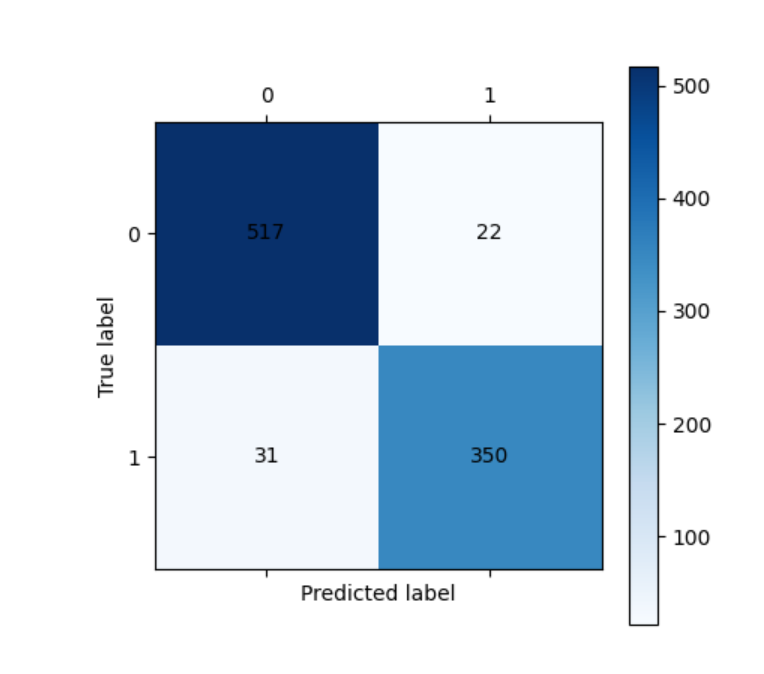
cm_plot(y_train, train_pred).show()
cm_plot(y_test, test_pred).show()
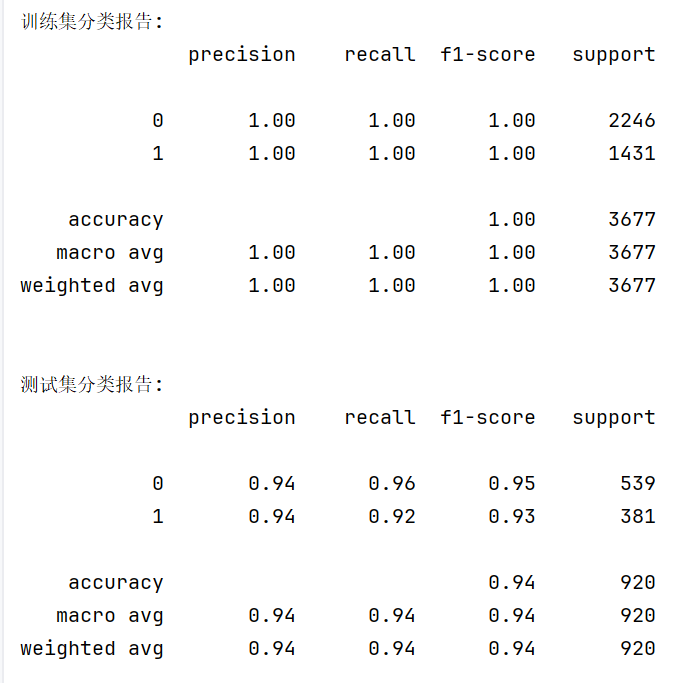
print("\n训练集分类报告:")
print(metrics.classification_report(y_train, train_pred))
print("\n测试集分类报告:")
print(metrics.classification_report(y_test, test_pred))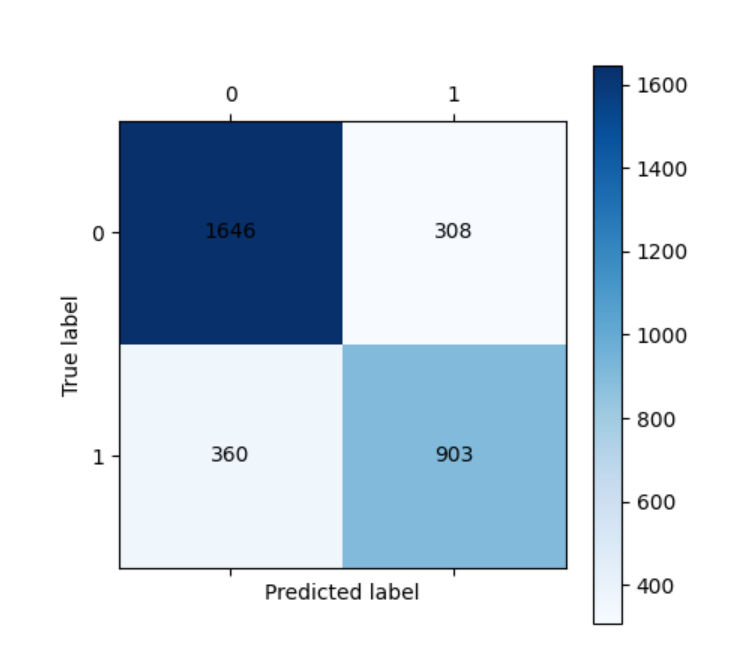
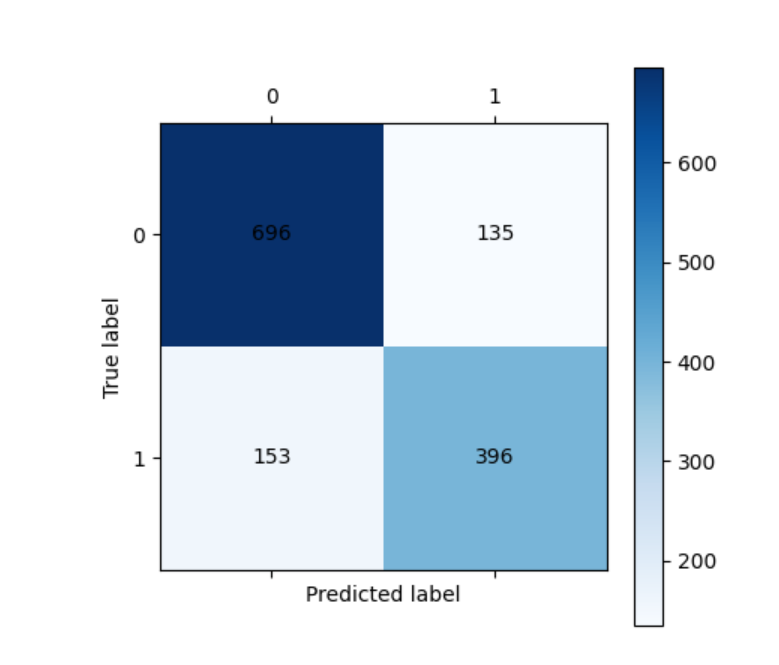
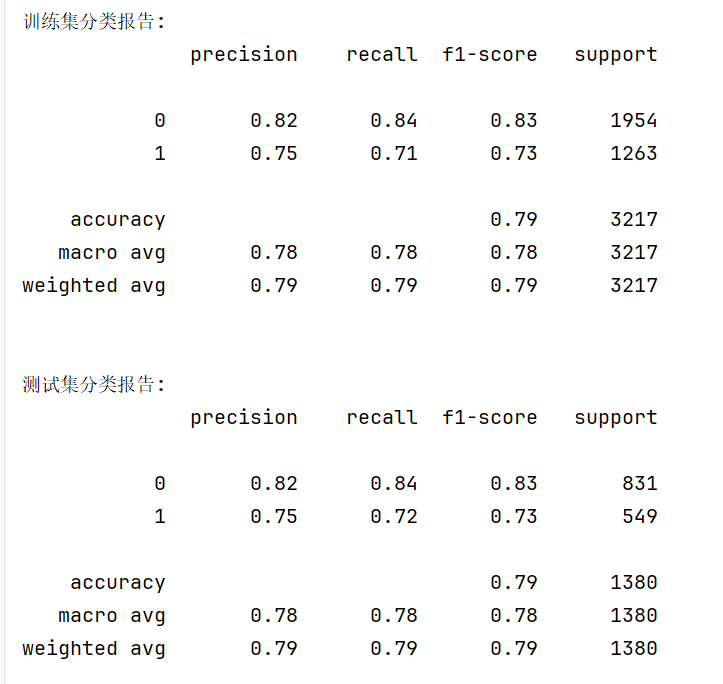
classification_report输出包含:
- 精确率(Precision): P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP
- 召回率(Recall): R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
- F1分数: F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
- 支持数(Support):各类别的样本数量
二、随机森林代码解析
1. 库导入与混淆矩阵函数
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier与朴素贝叶斯类似,增加了RandomForestClassifier
2. 数据准备
python
df = pd.read_csv(r"spambase.csv")
X = df.iloc[:, :-1] # 特征
y = df.iloc[:, -1] # 标签
xtrain, xtest, ytrain, ytest = train_test_split(
X, y,
test_size=0.2, # 测试集比例20%
random_state=100 # 随机种子
)3. 随机森林模型配置与训练
python
rf = RandomForestClassifier(
n_estimators=100, # 决策树数量
max_features=0.8, # 每棵树使用的特征比例
random_state=0 # 随机种子
)
rf.fit(xtrain, ytrain) # 训练模型RandomForestClassifier关键参数详解:
树的数量参数:
n_estimators=100:森林中决策树的数量- 值越大,性能通常越好,但计算成本越高
- 一般建议在100-500之间
特征选择参数:
max_features=0.8:每棵树考虑的最大特征数- 可以设置为整数、浮点数或字符串
- 浮点数表示特征的比例(80%)
- 常用值:
'sqrt'(平方根)、'log2'、None(全部特征)
树深度控制:
max_depth=None:树的最大深度None表示不限制,直到所有叶子纯净- 设置值可以防止过拟合
min_samples_split=2:内部节点再划分所需最小样本数min_samples_leaf=1:叶子节点最少样本数
其他重要参数(类似决策树):
criterion='gini':分裂标准'gini':基尼不纯度 G i n i = 1 − ∑ i = 1 n p i 2 Gini = 1 - \sum_{i=1}^{n} p_i^2 Gini=1−∑i=1npi2'entropy':信息增益 E n t r o p y = − ∑ i = 1 n p i log 2 p i Entropy = -\sum_{i=1}^{n} p_i \log_2 p_i Entropy=−∑i=1npilog2pi
4. 特征重要性分析
python
# 获取特征重要性
feature_importances = rf.feature_importances_
features = X.columns
# 创建重要性DataFrame
importance_df = pd.DataFrame({
'feature': features,
'importance': feature_importances
})
# 按重要性排序
importance_df = importance_df.sort_values('importance', ascending=False)
# 可视化前20个重要特征
plt.figure(figsize=(10, 6))
plt.barh(range(20), importance_df['importance'][:20])
plt.yticks(range(20), importance_df['feature'][:20])
plt.xlabel('Feature Importance')
plt.title('Top 20 Important Features')
plt.gca().invert_yaxis() # 重要度从高到低排列
plt.show()5. 模型评估与可视化
python
train_predicted = rf.predict(xtrain)
test_predicted = rf.predict(xtest)
# 可视化混淆矩阵
cm_plot(ytrain, train_predicted).show()
cm_plot(ytest, test_predicted).show()
# 输出详细评估报告
print("\n训练集分类报告:")
print(metrics.classification_report(ytrain, train_predicted))
print("\n测试集分类报告:")
print(metrics.classification_report(ytest, test_predicted))