2025.12.22
这篇文章发表于《Medical Image Analysis》期刊(2026 年第 109 卷),由清华大学、中山大学附属第一医院等机构学者联合撰写,聚焦病理全切片图像(WSI)的层级分类问题,提出一种诊断文本引导的表示学习方法 PathTree。
Title 题目
01
Diagnostic text-guided representation learning in hierarchical classification for pathological whole slide image
诊断文本引导的分层分类全玻片图像表征学习
文献速递介绍
02
现代计算成像技术推动了病理学从传统显微镜诊断向数字化成像分析的转变。全玻片图像(WSIs)的出现不仅提高了病理医生的工作效率,也促进了计算机视觉技术在病理诊断中的应用。由于WSI的巨大尺寸,现有的高性能模型无法直接应用于高分辨率病理图像,因此早期研究多采用补丁级学习。然而,受限于大规模像素级手动标注的困难,研究逐渐转向玻片级监督和表征学习。如何从补丁嵌入中获取WSI表征成为一个主要关注点,目前已探索多实例学习、图基表征和序列建模等方法。这些方法在早期临床实践任务中取得了成功,但这些任务通常涉及明确分离的类别。对于形态差异微妙、类别边界模糊、显微镜下视觉线索不清晰的复杂亚型分类等挑战性任务,现有WSI表征学习方法仍有局限。受病理医生分层诊断策略和丰富文本描述的启发,本文将挑战性的病理多分类问题转化为具有二叉树结构的分层分类任务,并设计了名为PathTree的WSI分层表征学习方法。PathTree利用专业病理术语描述每个类别,通过树状图交换信息,并结合文本嵌入指导多玻片级嵌入的聚合。PathTree通过玻片-文本相似度进行预测,并引入了两个树状结构感知损失来捕捉分层文本嵌入间的语义匹配关系。在三个大型分层数据集上的实验验证了PathTree的卓越性能,为具有挑战性的病理任务提供了更客观和精确的辅助。
Aastract摘要
02
随着医学显微镜数字化成像技术的发展,人工智能在病理全玻片图像(WSI)分析中的应用为癌症诊断提供了强大工具。由于像素级标注成本高昂,当前研究主要聚焦于玻片级标签的表征学习,并在多种下游任务中取得了成功。然而,鉴于病变类型的多样性及其间复杂的相互关系,这些技术在处理高级病理任务方面仍有探索空间。为此,本文引入了分层病理图像分类的概念,并提出了一种名为PathTree的表征学习方法。PathTree将疾病多分类问题视为二叉树结构,其中每个类别都由专业的病理文本描述表示,并通过树状编码器进行信息传递。交互式文本特征随后用于指导分层多重表征的聚合。PathTree利用玻片-文本相似度获得概率分数,并引入两个额外的树特定损失,以进一步约束文本与玻片之间的关联。通过在三个具有挑战性的分层分类数据集(包括内部冷冻切片肺组织病变识别、公共前列腺癌分级评估和公共乳腺癌亚型分类)上进行的广泛实验,我们提出的PathTree方法始终优于现有最先进方法,并为更复杂的WSI分类问题提供了深度学习辅助解决方案的新视角。
Method 方法
03
本文提出的PathTree方法包含六个阶段。首先,将WSI裁剪为补丁,并设计树状文本以生成数据对。其次,使用预训练编码器提取补丁和文本的高维表征,并通过树状图神经网络作为文本提示编码器来交换文本语义信息。第三,通过补丁级注意力聚合生成多个玻片级嵌入,每个嵌入代表树中一个节点的玻片特征。第四,计算文本提示和玻片级嵌入之间的相关性,以指导多个玻片级嵌入沿树路径向根节点聚合,从而获得全局WSI特征。第五,设计路径对齐损失和树状匹配学习损失函数来约束不同文本语义的关系。最后,通过计算玻片-文本相似度获得预测分数。PathTree通过Otsu方法对WSI进行预处理,分离前景并以20倍放大裁剪256x256的非重叠补丁。PLIP的图像编码器用于提取补丁嵌入。PathTree根据组织病理学特定任务准备文本模态,详细描述树结构中每个节点(包括根、分支和叶节点)的病理形态。文本提示编码器利用PLIP的文本编码器生成树状文本嵌入,并通过设计的双向有向图(BiTree)允许文本提示之间进行信息传递。多注意力模块使用多门控注意力和多头Nystrom注意力生成多个玻片级特征,以捕捉不同的形态模式和空间区域。文本引导的树状聚合器利用文本提示嵌入指导玻片级嵌入沿树路径递归聚合,从叶子节点向上直到根节点。联合玻片-文本约束包括路径对齐损失和树状匹配损失,前者旨在对齐WSI表征与路径上所有祖先类别,后者通过三元组损失增强类别间的判别性,使WSI表征与父节点强相关,与兄弟节点次之,与其他不相关叶节点距离远。最后,通过计算WSI特征与文本提示嵌入的余弦相似度获得预测概率,并通过交叉熵损失进行优化。总损失函数结合了交叉熵损失、树状匹配损失和路径对齐损失。
Discussion讨论
04
本文将传统的挑战性病理任务从平面分析转化为树状分析方法,引入了分层WSI分类的概念,并提出了PathTree来解决这些分层任务。PathTree综合考虑文本和WSI模态,使用专业的病理描述作为粗粒度和细粒度提示,并引入树状图在类别之间交换语义信息。为了让文本指导WSI表征,PathTree基于树路径聚合多个玻片级嵌入,并使用玻片-文本相似度和额外的度量损失来优化下游任务目标。在三个具有挑战性的分层分类任务中,PathTree优于其他最先进的方法,并为解决复杂计算病理问题提供了更具临床相关性的视角。尽管取得了令人鼓舞的结果,PathTree仍有一些局限性。首先,PathTree依赖于文本注释的质量和细节来构建有意义的分层提示嵌入,这可能会限制其在诊断知识不完整任务中的适用性。未来的工作可以考虑结合大型语言模型的医学知识和真实临床报告来生成更丰富、更精确的文本提示。其次,当前的评估任务相对有限,未来需要将其应用于更广泛的下游任务,如大规模泛癌分析和脑、淋巴增生性肿瘤等亚专科的复杂亚型分类。最后,当前的PathTree需要针对每个特定任务从头开始训练,这可能限制其可扩展性和性能提升。未来计划收集更广泛的临床数据并构建大规模分层树状结构,以预训练一个临床级别的PathTree基础模型,支持肿瘤学领域的全面诊断。
Conclusion结论
05
本文将传统挑战性病理任务从平面分析转化为树状分析方法,引入了分层WSI分类的概念,并提出了PathTree来解决这些分层任务。PathTree综合考虑文本和WSI模态,使用专业的病理描述作为粗粒度和细粒度提示,并引入树状图在类别之间交换语义信息。为了让文本指导WSI表征,PathTree基于树路径聚合多个玻片级嵌入,并使用玻片-文本相似度和额外的度量损失来优化下游任务目标。在三个具有挑战性的分层分类任务中,我们展示了PathTree优于其他最先进的方法,并能为解决复杂的计算病理问题提供更具临床相关性的视角。
Results结果
06
在精细粒度分类方面,PathTree(基于门控注意力)在SYSFL、PANDA和BRACS数据集的所有三个指标上均优于其他竞争对手,而PathTree-Ny(基于多头Nystrom机制)在SYSFL和PANDA数据集上的性能甚至高于PathTree。在分层指标上,PathTree方法在H-Precision和H-Recall上达到有竞争力的水平,并在更全面的H-F1指标上比其他方法高出约2%,表明PathTree比其他最先进方法能更精确地区分玻片。在粗粒度分类任务中,PathTree方法在SYSFL(4类)、PANDA(2类)和BRACS(3类)数据集上的整体表现依然优越。在少样本学习方面,PathTree在BRACS和PANDA数据集上表现出最佳的少样本能力,尤其在BRACS中标准差最小。虽然在1和2-shot设置下PathTree并非最佳,但在4、8、16-shot下表现出有效性,这表明固定树状结构在极少样本下难以学习更多上下文信息,但随着样本数量略微增加,分层结构可以显著学习类别内部关系,从而提高模型性能。消融实验显示,本文设计的专业描述作为提示文本,其性能始终优于其他常规和一般病理相关文本提示。当使用完整的病理报告作为文本输入时,PathTree的性能在所有六个评估指标上均有显著提升,并且优于ViLa-MIL和FiVE两种基线方法。SHAP可解释性分析表明,PathTree有效捕捉了病理报告中语义丰富和诊断相关的词汇。计算成本分析显示,PathTree(基于门控注意力)在GPU内存使用方面最低,推理速度具有竞争力。不同图基文本提示编码器对PathTree最终性能影响不大。不同补丁编码器对PathTree性能影响显著,自然图像预训练的编码器表现不佳,而病理图像自监督预训练的编码器性能更优。生物医学文本预训练的文本编码器略优于自然语言预训练的编码器。树状约束损失的消融研究表明,Lmatch和Lpath的引入显著提升了PathTree的性能,且PathTree对这两个超参数具有相对较强的鲁棒性。当两个系数较大且接近时,PathTree性能更佳。
Figure 图
07
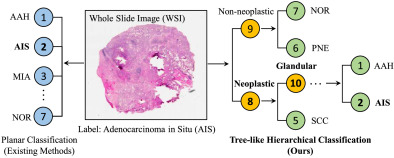
图1. 现有的WSI多分类方法被描述为平面分类问题,它独立且平等地对待每个类别。然而,在真实的病理环境中,各种类别之间的相互关系表现出相当大的复杂性。病理医生通常遵循类别之间分层、树状的关系,从粗粒度宏观到细粒度微观层面进行分析。这种方法提高了诊断的效率和精确性,并有助于病理医生系统地理解和解释复杂的病理信息,从而做出更准确的医疗决策。
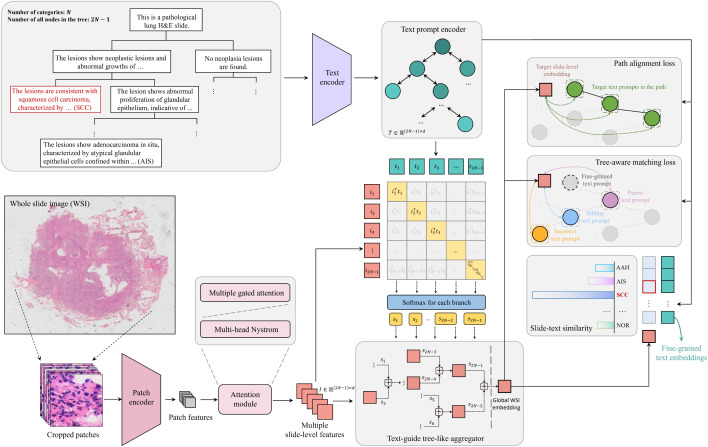
图2. PathTree概览。主要思想是将具有挑战性的病理多分类问题转换为分层树状结构进行分析。PathTree利用WSI从补丁级特征生成多个玻片级嵌入,使其能够与文本语义进行对比。根据树路径聚合后,通过两个结构特定的损失函数测量树状文本语义之间的关系,并通过计算玻片与细粒度文本嵌入之间的余弦相似度获得预测分数。
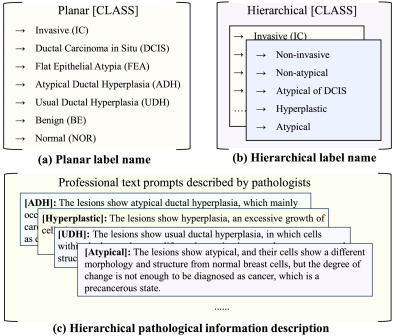
图3. 病理肺组织类别的三种不同文本形式。(a) 平面文本标签,仅使用细粒度类别名称;(b) 分层文本标签,同时使用细粒度和粗粒度类别名称;(c) 分层描述性文本标签,每个细粒度和粗粒度类别均使用病理学术语详细描述。
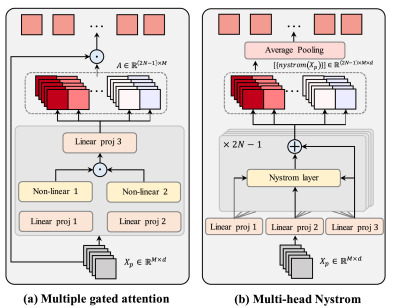
图4. 两种注意力模块的示意图。(a) 多门控注意力为每个补丁分配多个注意力分数,然后将其与补丁嵌入加权以获得多个玻片表征;(b) 多头Nystrom分配2N-1个头,然后使用线性Nystrom方法更新每个头中的嵌入,最后通过平均池化层获得多个玻片表征。
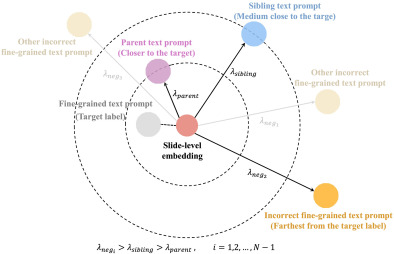
图5. 树状感知匹配学习的图形演示,其中目标节点的玻片级嵌入用作锚点,其文本嵌入作为正样本,其他文本嵌入作为负样本。目标是使锚点与负样本之间的距离大于其与正样本之间的距离。
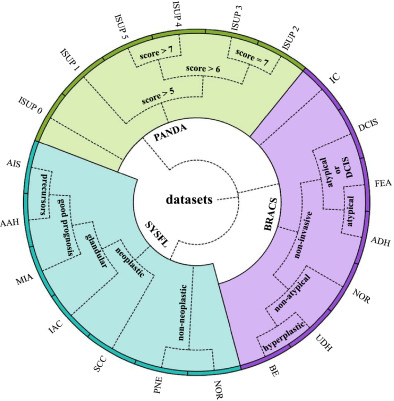
图6. SYSFL、PANDA和BRACS数据集的分层形式。它们都由二叉树表示。
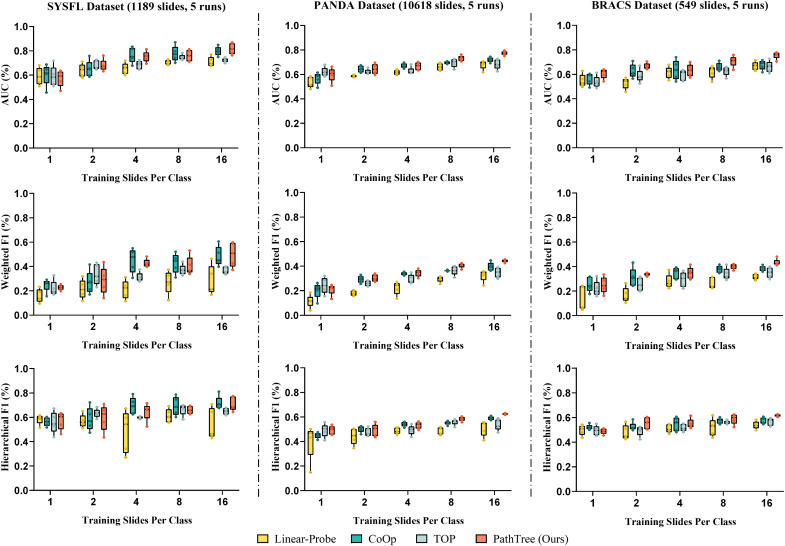
图7. 在少样本设置下,精细粒度7类别SYSFL、6类别PANDA和7类别BRACS数据集上的AUC、加权F1和H-F1结果%。
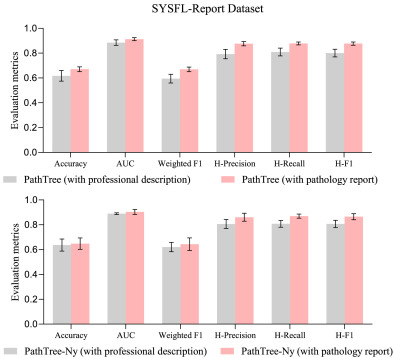
图8. PathTree在不同文本输入下的比较结果。
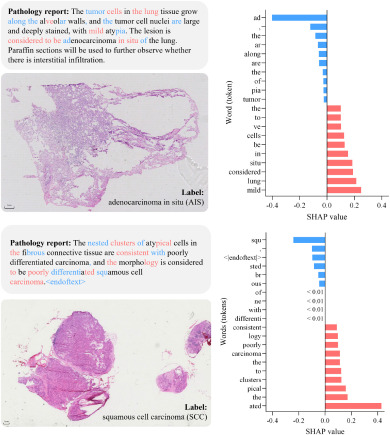
图9. 两个WSI示例及其对应的病理报告以及SHAP值结果。
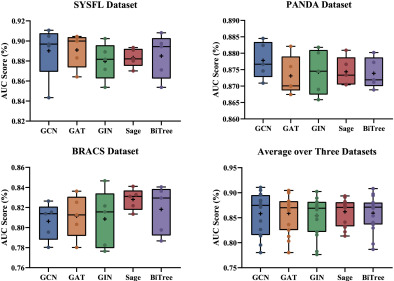
图10. 在三个细粒度数据集上,不同基于图的文本提示编码器的AUC结果%。
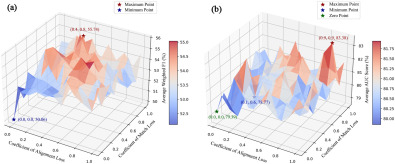
图11. BRACS数据集中,PathTree在最佳平均加权F1和AUC得分以及不同匹配损失系数μm、对齐损失系数μp下的曲面图。参数μm、μp范围从0.0到1.0,步长为0.1。
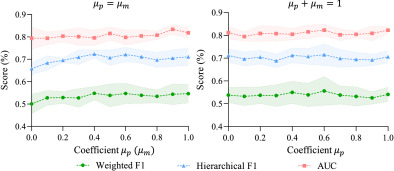
图12. PathTree在BRACS数据集中不同系数下的比较。(a) 保持系数μp和μm相等。(b) 保持系数μp和μm之和等于1。
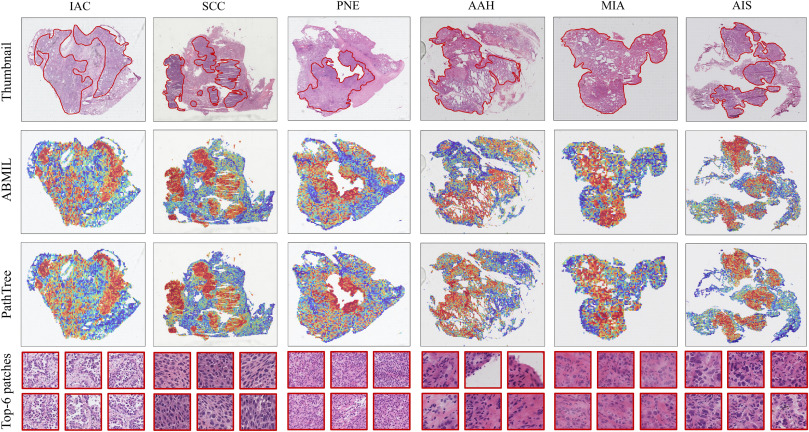
图13. SYSFL数据集中ABMIL和PathTree之间的可视化热图结果。缩略图中的感兴趣区域由病理医生标注。