@浙大疏锦行
作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略
过拟合的判断
# Day40 早停策略和模型权重保存 - 信贷数据集
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载信贷数据集
df = pd.read_csv('data.csv')
# 处理缺失值和非数字列
df = df.drop('Id', axis=1)
for col in df.select_dtypes(include=['object']).columns:
if col != 'Credit Default':
le = LabelEncoder()
df[col] = le.fit_transform(df[col].astype(str))
df = df.fillna(df.mean())
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
# 划分数据集并归一化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)
input_size = X_train.shape[1]
num_classes = len(torch.unique(y_train))
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, 10)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, num_classes)
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20000
train_losses = [] # 存储训练集损失
test_losses = [] # 存储测试集损失
epochs_list = []
start_time = time.time()
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train)
train_loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
# 每200个epoch记录损失值
if (epoch + 1) % 200 == 0:
# 计算测试集损失
model.eval()
with torch.no_grad():
test_outputs = model(X_test)
test_loss = criterion(test_outputs, y_test)
model.train()
train_losses.append(train_loss.item())
test_losses.append(test_loss.item())
epochs_list.append(epoch + 1)
# 更新进度条显示训练集和测试集损失
pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})
if (epoch + 1) % 1000 == 0:
pbar.update(1000)
if pbar.n < num_epochs:
pbar.update(num_epochs - pbar.n)
print(f'训练时间: {time.time() - start_time:.2f} 秒')
# 可视化损失曲线(训练集和测试集)
plt.figure(figsize=(10, 6))
plt.plot(epochs_list, train_losses, label='Train Loss')
plt.plot(epochs_list, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()
# 评估模型
model.eval()
with torch.no_grad():
outputs = model(X_test)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test).sum().item() / y_test.size(0)
print(f'测试集准确率: {accuracy * 100:.2f}%')
效果图:
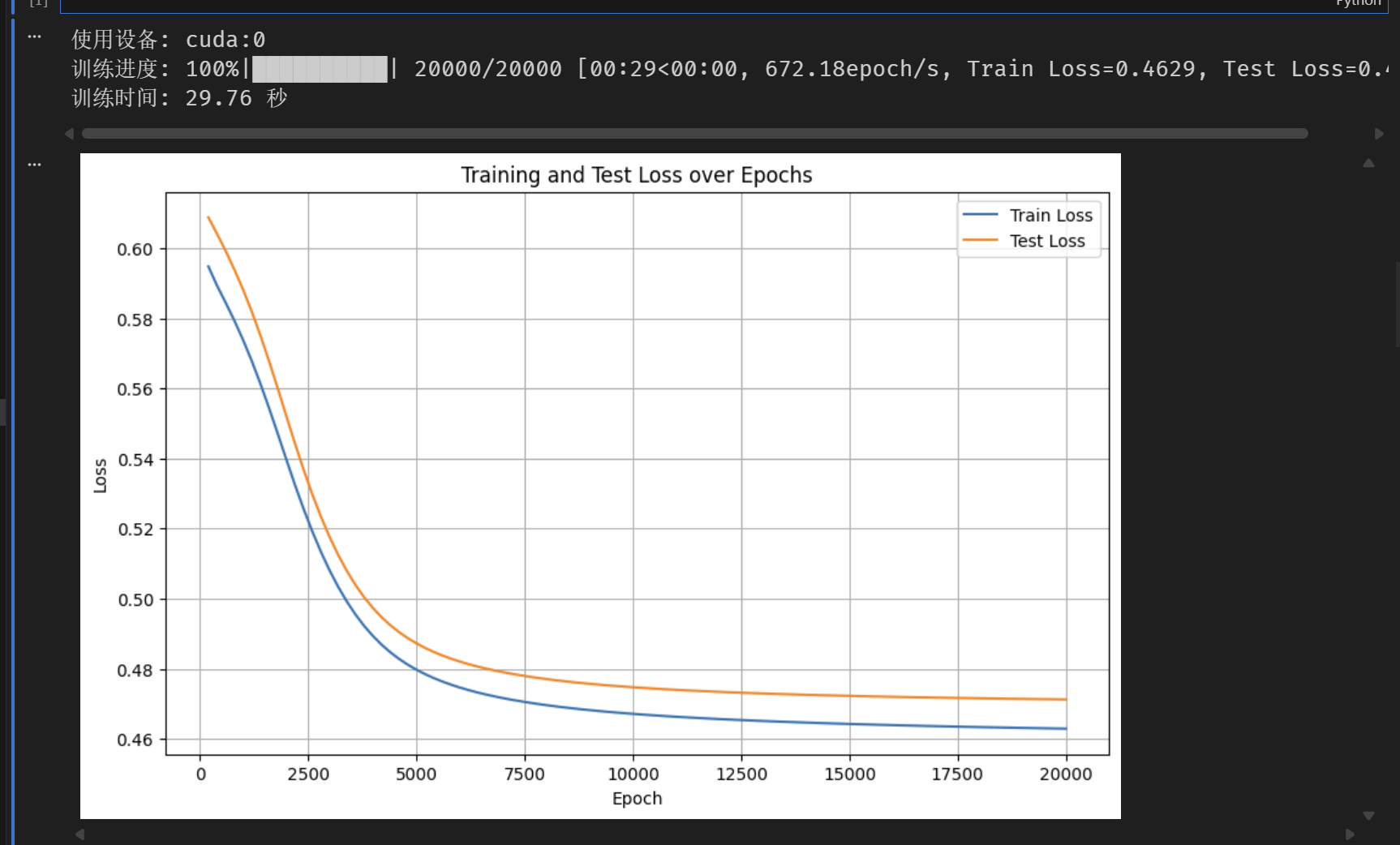
我们梳理下过拟合的情况
- 正常情况:训练集和测试集损失同步下降,最终趋于稳定。
- 过拟合:训练集损失持续下降,但测试集损失在某一时刻开始上升(或不再下降)。
如果可以监控验证集的指标不再变好,此时提前终止训练,避免模型对训练集过度拟合。----监控的对象是验证集的指标。这种策略叫早停法。
# Day40 早停策略和模型权重保存 - 信贷数据集(带早停法)
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载信贷数据集
df = pd.read_csv('data.csv')
# 处理缺失值和非数字列
df = df.drop('Id', axis=1)
for col in df.select_dtypes(include=['object']).columns:
if col != 'Credit Default':
le = LabelEncoder()
df[col] = le.fit_transform(df[col].astype(str))
df = df.fillna(df.mean())
X = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
# 划分数据集并归一化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)
input_size = X_train.shape[1]
num_classes = len(torch.unique(y_train))
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, 10)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, num_classes)
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
model = MLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 20000
train_losses = [] # 存储训练集损失
test_losses = [] # 存储测试集损失
epochs_list = []
# ===== 早停相关参数(改进版)=====
best_test_loss = float('inf') # 记录最佳测试集损失
best_epoch = 0 # 记录最佳epoch
patience = 100 # 增加耐心值,允许更多波动
min_delta = 0.001 # 最小改善阈值,损失需要至少改善这么多才算有效改善
counter = 0 # 早停计数器
early_stopped = False # 是否早停标志
# ================================
start_time = time.time()
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train)
train_loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
# 每200个epoch记录损失值
if (epoch + 1) % 200 == 0:
# 计算测试集损失
model.eval()
with torch.no_grad():
test_outputs = model(X_test)
test_loss = criterion(test_outputs, y_test)
model.train()
train_losses.append(train_loss.item())
test_losses.append(test_loss.item())
epochs_list.append(epoch + 1)
# 更新进度条显示训练集和测试集损失
pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})
# ===== 改进的早停逻辑 =====
# 使用min_delta作为最小改善阈值
if test_loss.item() < best_test_loss - min_delta:
best_test_loss = test_loss.item() # 更新最佳损失
best_epoch = epoch + 1 # 更新最佳epoch
counter = 0 # 重置计数器
# 保存最佳模型
torch.save(model.state_dict(), 'best_model.pth')
else:
counter += 1
if counter >= patience:
print(f"\n早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未显著改善。")
print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")
early_stopped = True
break # 终止训练循环
# =========================
if (epoch + 1) % 1000 == 0:
pbar.update(1000)
if pbar.n < num_epochs:
pbar.update(num_epochs - pbar.n)
print(f'训练时间: {time.time() - start_time:.2f} 秒')
# ===== 加载最佳模型用于最终评估 =====
if early_stopped:
print(f"加载第{best_epoch}轮的最佳模型进行最终评估...")
model.load_state_dict(torch.load('best_model.pth'))
# ================================
# 可视化损失曲线(训练集和测试集)
plt.figure(figsize=(10, 6))
plt.plot(epochs_list, train_losses, label='Train Loss')
plt.plot(epochs_list, test_losses, label='Test Loss')
plt.axvline(x=best_epoch, color='r', linestyle='--', label=f'Best Epoch ({best_epoch})')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs (with Early Stopping)')
plt.legend()
plt.grid(True)
plt.show()
# 评估模型
model.eval()
with torch.no_grad():
outputs = model(X_test)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test).sum().item() / y_test.size(0)
print(f'测试集准确率: {accuracy * 100:.2f}%')
效果图:
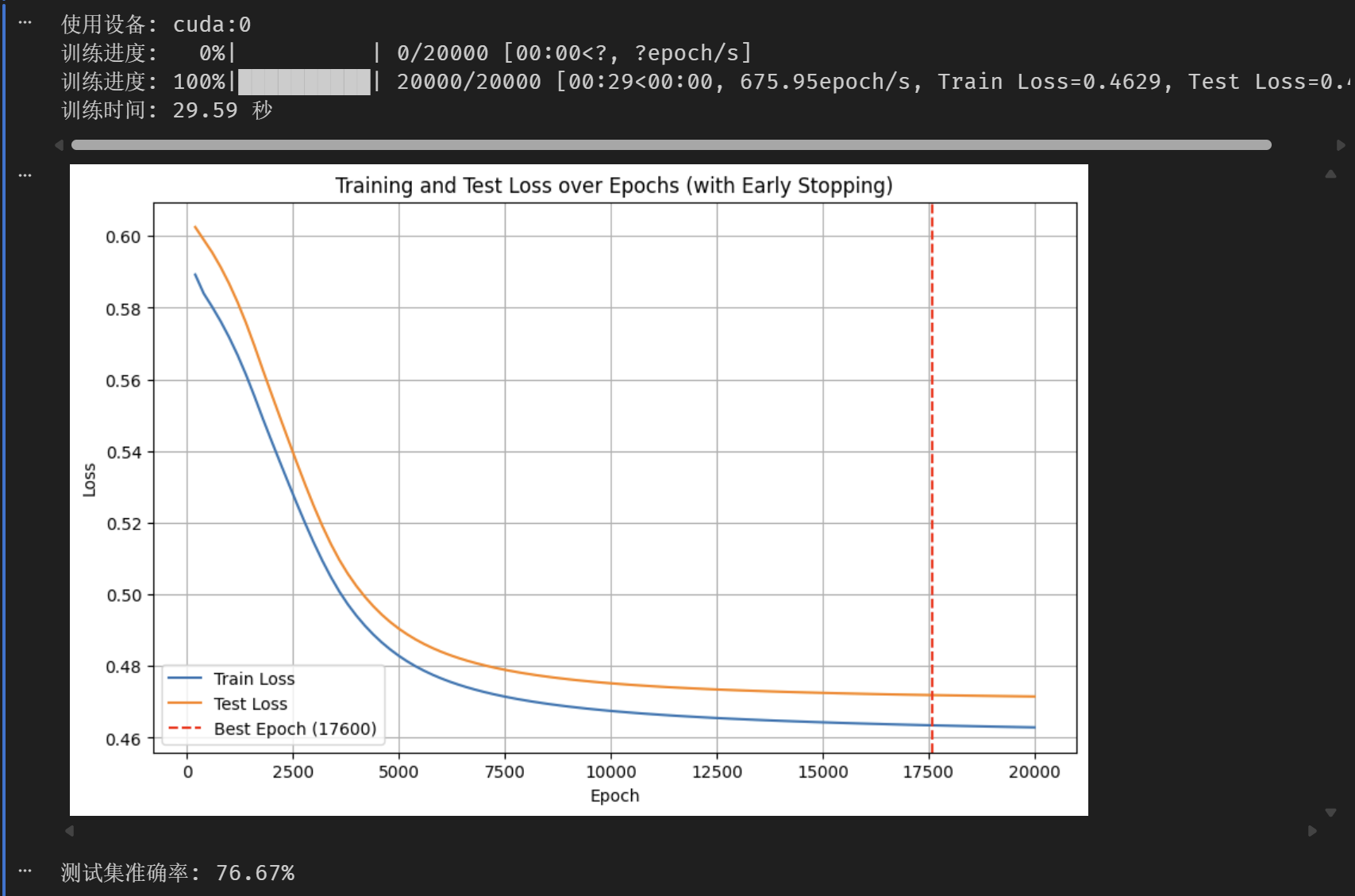
红线则代表最佳状态