PyTorch实战(27)------自动混合精度训练
0. 前言
在将预训练的机器学习模型投入生产环境之前,模型训练是不可或缺的关键环节。随着深度学习的发展,大模型往往具有数百万乃至数十亿参数。使用反向传播来调整这些参数需要大量的内存和计算资源,模型训练可能需要数天甚至数月时间才能完成。
在本节中,我们将学习如何借助 torch.cuda.amp.autocast 和 torch.cuda.amp.GradScaler 等 API 实现混合精度训练,在加快深度学习模型训练速度的同时降低内存占用,使用 PyTorch 的自动混合精度 (Automatic Mixed Precision, AMP) 工具,加速训练并减少内存消耗。
1. 自动混合精度训练
大多数深度学习模型使用 float32 张量表示输入数据、权重参数等。这种 32 位高精度数据类型虽然对损失计算等关键操作的数值稳定性至关重要,但许多运算其实可以使用 float16 低精度张量完成,在保证模型性能的前提下显著提升训练效率。现代 GPU 针对 float16 运算进行了专门优化,不仅能更快执行计算,还可降低内存占用。在训练中混合使用 float16 和 float32 张量的技术,称为混合精度训练。在本节中,我们首先将非分布式训练代码迁移至 GPU 环境,然后应用混合精度训练,对比观察内存占用和训练速度的提升效果。
2. 在 GPU 上进行常规模型训练
使用 GPU 进行无分布式训练 MNIST 数据集的代码与<使用常规方式训练MNIST模型>一节代码相同,仅存在以下两处关键修改:
- 将
device = torch.device("cpu")替换为device = torch.device("cuda") - 在模型实例化
model = ConvNet()之后,加入model.to(device)将模型加载到GPU上
通过在命令行运行以下命令来执行 Python 脚本:
shell
$ python convnet_undistributed_cuda.py --epochs 1输出结果如下所示:
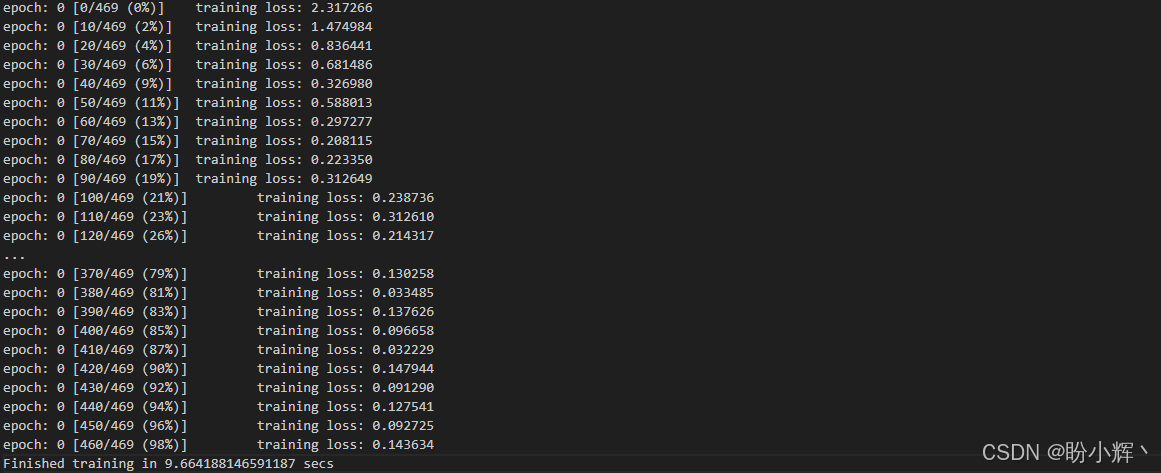
使用 GPU 进行训练的每个 epoch 仅需 9 秒,而使用 CPU 则需要 20 秒。使用不同型号的 GPU,训练时间可能会有所不同。
除了训练日志外,我们还可以在训练过程中监控 GPU 的使用情况。在命令行中使用 nvidia-smi 命令,可以看到如下输出:
在训练运行时,可以使用以下命令来实时查看 nvidia-smi 输出:
shell
$ watch -n0.1 nvidia-smi上示命令以每 0.1 秒的间隔实时展示 GPU 使用指标。在 GPU 上训练 MNIST 模型时,上述命令捕获的快照如下所示:

显示了 GPU 内存使用量和 GPU 利用率百分比。接下来,我们将在 GPU 上使用混合精度训练相同的模型,并观察这些关键指标的变化:训练速度、GPU显存占用及处理器利用率。
3. 在 GPU 上进行混合精度训练
PyTorch 提供了 torch.amp.autocast API,该接口能自动为不同的 GPU 运算选择精度级别( float32 或 float16),在保持模型训练稳定性和准确性的同时提升性能。得益于该 API,我们只需对常规训练代码稍作修改即可启用混合精度训练。代码基本与上一小节代码基本相同,仅存在以下差异。
(1) 原先模型前向传播与损失计算步骤如下:
python
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y)使用混合精度训练时,需修改为:
python
with torch.amp.autocast('cuda'):
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y) # nll is the negative likelihood loss本质上,我们让 autocast 自动决定输入数据 (X)、模型参数 (model) 和输出 (y) 应该转换为 float32 还是 float16 精度。通过以下命令执行混合精度训练脚本:
shell
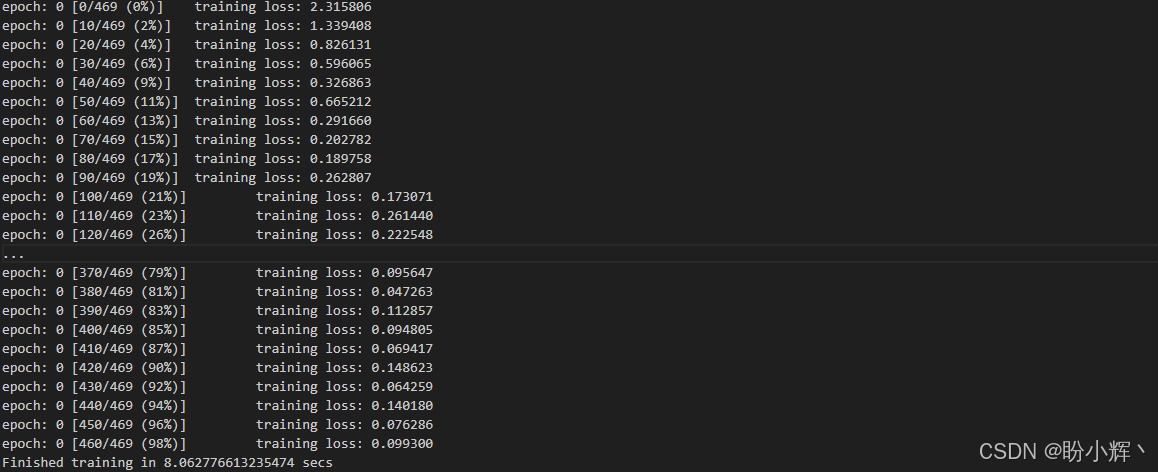
python convnet_undistributed_cuda_amp.py --epochs 1输出结果如下所示:
同时,在另一个命令窗口运行以下命令:
shell
$ watch -n0.1 nvidia-smi输出结果如下所示:

需要重点关注三个关键数值:训练时长、GPU 显存占用和 GPU 利用率百分比。训练时间从 9.66 秒略微缩短至 8.06 秒,GPU 显存占用从 1149 MB 降至 949 MB;GPU 利用率则从 14% 提升至 20%,这表明 autocast 确实能针对 float16 运算更高效地利用 GPU 资源。
虽然在这个练习中性能提升并不显著,但对于更大规模、更适合 GPU 加速的深度学习模型,这种优势往往会成倍放大。从训练日志中可以看出,混合精度的引入并未影响训练进程和稳定性。不过若出现异常情况,PyTorch 的 torch.amp.GradScaler 可通过缓解梯度下溢来解决问题------当梯度值极小(例如 1e-27 量级)时,float16 精度会将其直接归零导致梯度下溢。GradScaler 能有效预防混合精度训练中出现这种情况。借助该API,我们只需替换梯度更新步骤的相关代码。原先的代码段为:
python
loss.backward()
optimizer.step()
optimizer.zero_grad()使用 GradScaler 后则变为:
python
scaler.scale( loss) .backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()在启动训练循环前,还需要初始化 scaler:
python
scaler = torch.amp.GradScaler('cuda')我们可以模型训练代码中尝试这些更改,观察模型训练时长、GPU 显存占用和 GPU 利用率的变化。通过联合使用 torch.amp.autocast 和 torch.amp.GradScaler 这两个 API,我们可以轻松将任何 PyTorch 模型训练代码升级为自动混合精度 (Automatic Mixed Precision, AMP) 训练模式。
虽然 AMP 既适用于 CPU 也适用于 GPU,但由于 GPU 硬件针对 float16 运算的特殊优化,后者通常能获得更显著的性能提升。需要说明的是,虽然我们在本节介绍的是 GPU 环境下的 AMP,但相关 API 在 CPU 上的运作原理相同------唯一的区别在于 CPU 模式下 float32 会转换为 bfloat16 而非 float16 (bfloat16 与 float16 虽同为 16 位精度表示,但存在细微差异)。
小结
在本节中,我们探讨了机器学习中一个重要的实践方面------如何优化模型训练过程。我们探讨了如何通过混合精度优化模型训练性能,用于提升现有深度学习模型训练代码的性能,同时编写更高效的训练代码。
相关链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练