最近我在社区发起了一个关于"内容偏好"的投票,结果既在意料之外,又在情理之中。我问大家:是更倾向于"三分钟快速听完论文概要",还是愿意花"一小时深度解析一篇论文"?
结果77%的同学选择了后者------深度解析。但更让我惊喜且感动的,是评论区里大量涌现的另一种声音。许多小伙伴留言说:"其实具体的论文内容只是其次,我真正渴望的是掌握那套'读论文的方法论'。我希望你能说说你是怎么阅读论文的,让我下一次面对陌生论文时不再迷茫。"
这正是人们常说的"授人以鱼不如授人以渔"。既然大家有这样的觉悟和求知欲,今天我就暂缓具体的算法讲解,专门来聊聊**"如何像审稿人一样高效阅读一篇学术论文"**。掌握这项技能,是你从被动接收知识转向主动探索科研边界的关键一步。
一、 解构论文:理解学术界的"八股文"范式
在深入方法论之前,我们必须先理解对手------论文本身的结构。现在的理工科论文,尤其是计算机(CS)领域的顶会论文,几乎都遵循着一套严格的IMRaD结构(Introduction, Methods, Results, and Discussion),也就是我们俗称的"学术八股文"。
这并非死板,而是为了科学交流的效率。一篇标准的论文通常包含以下模块:
- Title(标题): 浓缩的核心贡献。
- Abstract(摘要): 整个故事的"预告片"。
- Introduction(介绍): 类似电影的"导演阐述",交代背景、动机和贡献。
- Related Work(相关工作): 梳理学术坐标系,明确自己在前人基础上的位置。
- Method(方法): 核心算法与模型构建,这是论文的心脏。
- Experiments(实验): 用数据证明"心脏"跳动得很有力,这部分包含大量图表。
- Conclusion(结论): 总结陈词与未来展望。
这种结构化写作意味着我们完全不需要从头读到尾。如果你像读小说一样逐字阅读,不仅效率低下,更容易陷入细节的泥潭。
二、 为什么你需要"过滤"而非"全读"?
根据arXiv的数据显示,仅在人工智能领域,每天新上传的论文就数以百计。 "信息过载"是科研人员面临的最大痛点。 在海量文献中,真正值得你精读的文章可能只是沧海一粟。
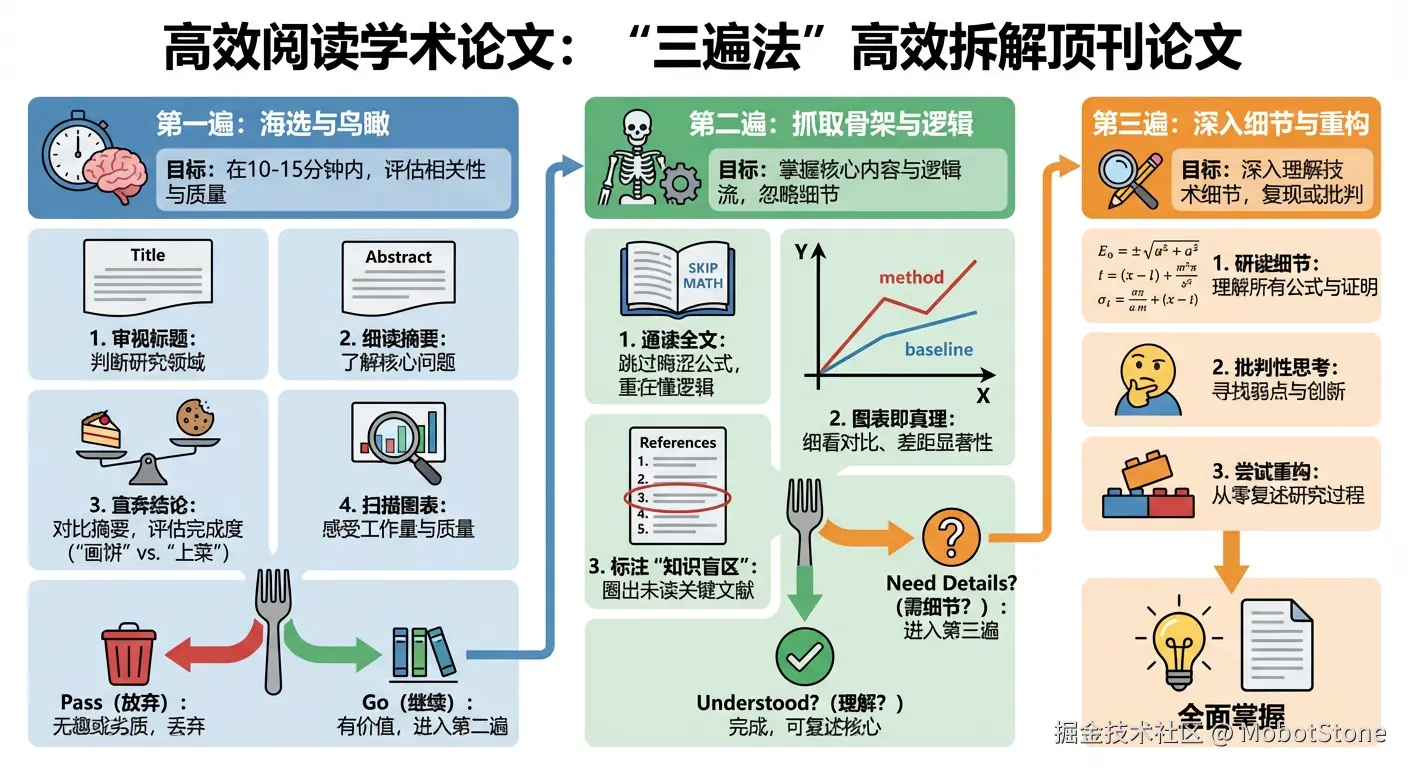
因此,我们需要一种"漏斗式"的阅读策略:通过层层筛选,快速剔除无关信息,将宝贵的精力集中在高价值目标上。这也就是我今天要分享的核心技术------ "三步阅读法"(The Three-Pass Approach)。
三、 实战演练:三步法详解
第一步:海选与鸟瞰(The Scanner)
-
目标: 在10-15分钟内,判断这篇文章是否值得读下去,评估其相关性与质量。
-
执行步骤:
- 审视标题(Title): 判断它是否属于你的研究领域。
- 细读摘要(Abstract): 了解作者声称解决了什么问题。
- 直奔结论(Conclusion): 这是一个关键技巧。摘要通常是"画饼",而结论是"上菜"。结论部分往往会把摘要里提出的问题,用更确凿的实验数据和结果进行呼应。对比首尾,你就能大致判断文章的完成度。
- 扫描图表(Glance over Figures): 快速翻阅实验部分的图表。虽然不需要看懂细节,但通过图表的绘制质量、数据量级,你可以直观感受作者的治学态度和工作量。
-
**决策时刻:**读完这几部分,你就要做决定了------Pass(放弃)还是Go(继续)?如果不感兴趣或发现质量低劣,直接丢弃,不要浪费时间。如果觉得有点意思,但现在没空,可以先加入文献库。如果觉得很有价值,那就进入第二步。
第二步:抓取骨架与逻辑(The Reader)
-
目标: 掌握文章的核心内容和逻辑流,但暂时忽略繁琐的数学证明和技术细节。
-
执行步骤:
- **通读全文(不求甚解):**从头到尾阅读,但遇到复杂的公式推导、晦涩的证明细节时,请大胆跳过。这一步的重点是"懂逻辑",而不是"扣细节"。
- 图表即真理: 这是第二步的重中之重。文字可能会有修饰,但图表是诚实的。你要仔细看图表的X轴、Y轴分别代表什么?图中的每个数据点意味着什么?作者的方法(通常是红线或蓝线)相比Baseline(基线)提升了多少?差距是否显著?
- 标注"知识盲区":在阅读Introduction和Related Work时,作者会引用大量前人的工作(如"基于Smith等人的方法...")。如果你发现某些被反复引用的关键文献你没读过,一定要把它们圈出来。
-
决策时刻: 这一步读完,你可能还是有些懵,这很正常。此时你有三个选择:
- 放弃: 发现内容虽好,但对自己当前的研究帮助不大。
- 回溯:发现读不懂是因为基础薄弱。这时你应该暂停阅读本文,去补读刚才圈出来的那些引用的参考文献(Background Papers)。这叫"磨刀不误砍柴工",读完前置知识再回来,门槛会低很多。
- 精读: 觉得文章太棒了,必须彻底搞懂,那就进入第三步。
第三步:虚拟重现与批判(The Reviewer)
-
目标: 达到"重构级"理解。不仅知道作者做了什么,还要知道他为什么这么做,以及如果是你,你会怎么做。
-
执行步骤:
-
虚拟复现(Virtual Re-implementation):这是最高阶的读法。在读每一段、每一个公式时,强迫大脑进行"脑补模拟"。
- 看到问题定义,掩卷思考:"如果是我,我会用什么方法解决?"
- 看到作者的方法,对比思考:"我的方案和他的有什么不同?为什么他选了这个?"
- 看到实验设置,批判思考:"他的实验有没有漏洞?如果我来做,能不能设计得更严谨?甚至能不能得到更好的结果?"
-
挖掘隐藏细节: 关注作者提到的那些"失败的尝试"或"未来的工作",这些往往是后续研究的突破口。
-
-
最终成果: 经过这炼狱般的第三步,你应该能够做到:
- 在脑海中完整复述文章的细节。
- 清楚其优缺点(Gap)。
- 甚至可以直接基于此复现代码或开启新的研究。
这套"三步法"的核心在于时间精力的非线性分配:
- 第一步是"海选" ,用最少的时间(~10分钟)筛选掉90%的噪音;
- 第二步是"精选" ,梳理逻辑,构建知识网络;
- 第三步是"研读" ,只有极少数对你最重要的论文才配得上这个待遇。
优秀的读者不是被动接受信息,而是与作者进行深度对话。当你能够自然地在"三步阅读法"间灵活切换时,你就掌握了开启学术宝库的钥匙。正如诺贝尔物理学奖得主Richard Feynman所说:"如果你不能向大一学生解释清楚一个概念,说明你自己也没有真正理解它。"而这种理解深度,正是通过结构化的深度阅读获得的。