词编码技术演进:从"机器识字符"到"AI懂语义"的四代革命
大家好,今天我们聊聊自然语言处理(NLP)的"地基"------词编码技术。从让机器"区分单词"到"理解语义",这背后是四代技术的迭代,正好对应四张经典示意图。
1. 独热编码------机器"能认词,但看不懂"
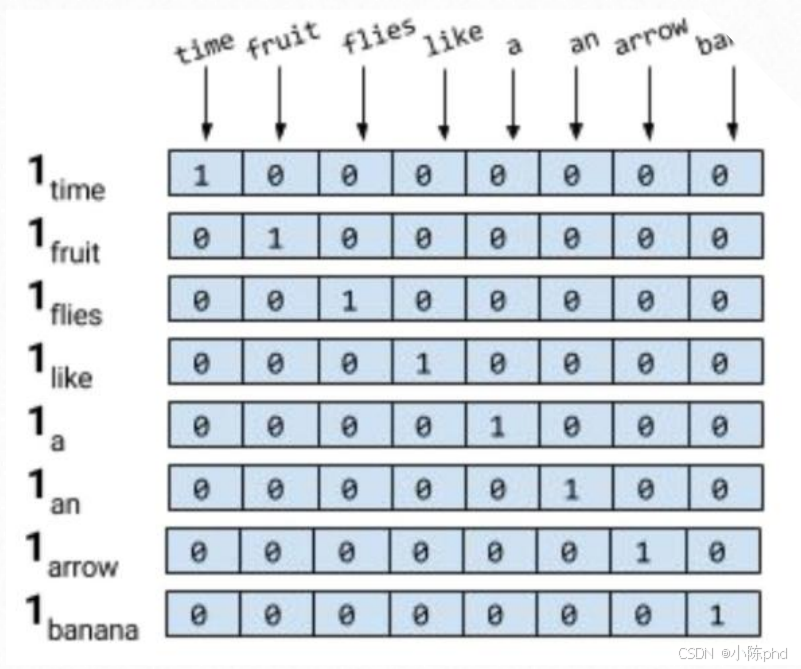
先看这张图(独热编码示意图):
它的逻辑很直接:给每个单词分配一个向量,只有单词对应的位置是1,其余全为0 。比如"time"对应[1,0,0,...],"fruit"对应[0,1,0,...]。
这代技术的核心是"区分单词",但缺陷也很致命:
- 语义割裂:任意两个词的向量都是"正交"的(相似度为0),机器根本不知道"苹果"和"香蕉"都是水果;
- 内存爆炸:若词汇表有10万个单词,每个向量就要10万维,完全是资源浪费。
一句话总结:独热编码让机器"能认词",但完全"看不懂语义"。
2. Word2Vec------机器"能感知语义,但太死板"
为了破解独热编码的困境,Word2Vec来了(Word2Vec示意图)。

它的核心是**"降维+语义关联"**:通过一个训练好的Q矩阵,把高维独热向量压缩成低维稠密向量(比如图中5维转3维)。
这代技术的突破是:
- 压缩维度:从10万维降到几百维,内存压力直接消失;
- 语义关联:相似词的向量会更接近(比如"苹果"和"香蕉"的向量相似度高),机器终于能感知"它们是一类东西"。
但Word2Vec有个硬伤:它是静态词嵌入------同一个单词(比如"bank")在"河岸"和"银行"语境下,向量完全一样,机器分不清多义词。
3. ELMo模型------机器"能懂上下文,区分多义"
为了解决"多义词"问题,ELMo模型登场(ELMo示意图)。

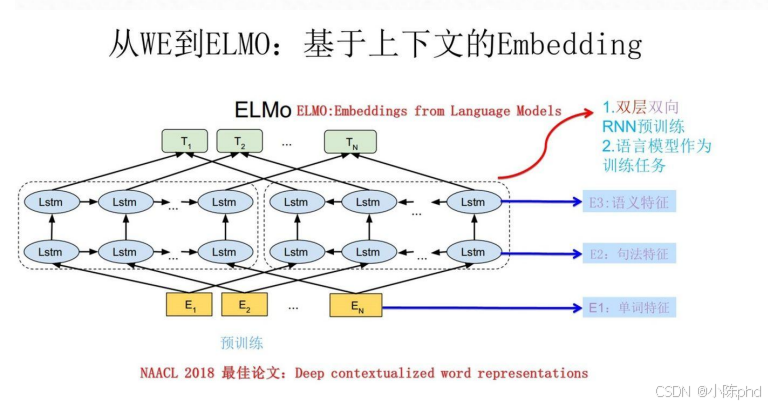
左边例子很典型:"bank"既可以是"河岸",也可以是"银行"------Word2Vec分不清,但ELMo能。
它的核心是**"动态词嵌入":用"双层双向RNN"训练,同一个单词会根据上下文**生成不同的向量:
- 当"bank"出现在"river"附近时,向量对应"河岸";
- 当"bank"出现在"money"附近时,向量对应"银行"。
这代技术让机器终于"能结合语境理解单词",但缺点是:RNN是串行计算,处理长文本时效率很低。
4. Multi-head Self Attention------机器"能多角度懂语义,还高效"
最后是Transformer的核心:多头自注意力(Multi-head Self Attention示意图)。

它一次性解决了两个问题:
- 多角度语义捕捉:"多头"意味着机器可以同时从多个维度关注句子(比如图中不同颜色的线代表不同"头")------有的头关注语法(如"it"和"is"的关联),有的头关注语义(如"making"和"difficult"的关联);
- 并行计算:和RNN的串行不同,注意力是并行处理的,长文本效率直接提升10倍以上。
这代技术不仅让机器"懂上下文",还能"精准、高效地理解语义"------正是它,支撑了现在的GPT、BERT等大模型。