****论文题目:****Artificial Feature Bias Rectified by Self-Supervised Learning for Rolling Bearings Fault Diagnosis Under Limited Labeled Vibration Signals(有限标记振动信号下滚动轴承故障诊断的自监督学习修正人工特征偏差)
****期刊:****IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT
****摘要:****考虑到滚动轴承总标记故障信号难以采集,解决有限标记振动信号对故障智能诊断的挑战迫在眉睫。在这种情况下,人工特征和机器学习(ML)技术的结合是处理这个问题的一种潜在方法,因为ML技术具有简单的结构,因此与基于深度学习(DL)的方法相比,在训练过程中不需要大量标记信号。然而,由于人工特征是基于专家的主观经验,因此通常存在偏差,这可能导致基于ML的方法的性能下降。为了解决这一问题,提出了一种自监督的人工特征偏置校正框架(SFAFBR)。具体来说,振动信号的人工特征来自小波包(WPs),小波包通过引导深度网络学习与深度网络相结合。学习到的特征与原始人工特征密切相关,但由于深度模型的稀疏表达,偏差得到了纠正。然后,在此基础上,构建基于ML的分类器来执行最终诊断。该框架在两个轴承数据集上分别获得了97.79%和94.84%的诊断准确率。结果表明,利用深度网络辅助校正人工特征偏差是解决有限标记振动信号下滚动轴承故障诊断问题的一种有前途的方法。
用自监督学习纠正人工特征偏差:一种面向有限标注数据的滚动轴承故障诊断新框架
一、背景与问题:为什么有限标注数据是工业诊断的核心难题?
滚动轴承是现代工业机械系统中不可缺少的关键部件,其工况直接影响整机的安全与效率。因此,对轴承进行及时、准确的智能故障诊断至关重要。
然而,在工业现实中,有两个客观困难长期制约着智能诊断方法的发展:
第一,故障样本极难收集。 工业设备不允许在故障状态下长期运行,加之个体故障的随机性,使得可供训练的标注故障样本数量极其有限。这让当前主流的深度学习方法面临严重的"数据饥渴"问题------深度网络强大的特征提取能力背后,是对海量标注数据的依赖。
第二,现有解决方案各有局限。 学界已提出多种应对策略:
- 数据增强(如GAN生成样本):依赖对抗网络,生成质量难以保证;
- 半监督学习(如伪标签传播):依赖高质量的初始标注;
- 元学习(如N-way K-shot):需要大量有标注的支持集;
- 迁移学习:依赖源域与目标域之间的分布对齐。
这些方法的共同短板是:在完全缺乏标注支持集的极端场景下,性能会显著下降。
二、为什么不直接用机器学习加人工特征?------人工特征偏差问题的根源
面对上述困境,一个自然的想法是:既然深度学习太"重",为什么不退回到更轻量的方案------用专家设计的人工特征 结合传统**机器学习(ML)**来完成诊断?
这条路确实有吸引力:ML模型结构简单,不需要海量标注数据。然而,这篇论文敏锐地指出了这条路的核心瓶颈------人工特征存在固有偏差(Artificial Feature Bias)。
所谓人工特征,是领域专家根据丰富的工程经验,从振动信号中手工定义或提取的特征,如时频域统计量、能量分布等。
人工特征偏差主要来源于两个方面:
- 低相关性(Low Correlation):专家凭主观经验选取的特征,未必与具体的诊断任务高度相关,导致特征的判别能力不足。
- 知识冲突(Knowledge Conflict):不同人工特征之间可能存在语义矛盾或信息冗余,使得特征集合整体上存在内部矛盾。
正是这两类偏差,导致基于人工特征的ML方法在诊断性能上普遍弱于深度学习方法。
本文的核心洞见是: 如果能在保留ML方法"轻量"优势的同时,借助深度网络来自动纠正人工特征中的偏差,那么就能兼得两者之长------既降低对标注数据的需求,又提升诊断精度。
三、SFAFBR:核心方法详解
本文提出的方法名为 SFAFBR(Self-supervised Framework of Artificial Feature Bias Rectification,人工特征偏差自监督纠正框架)。
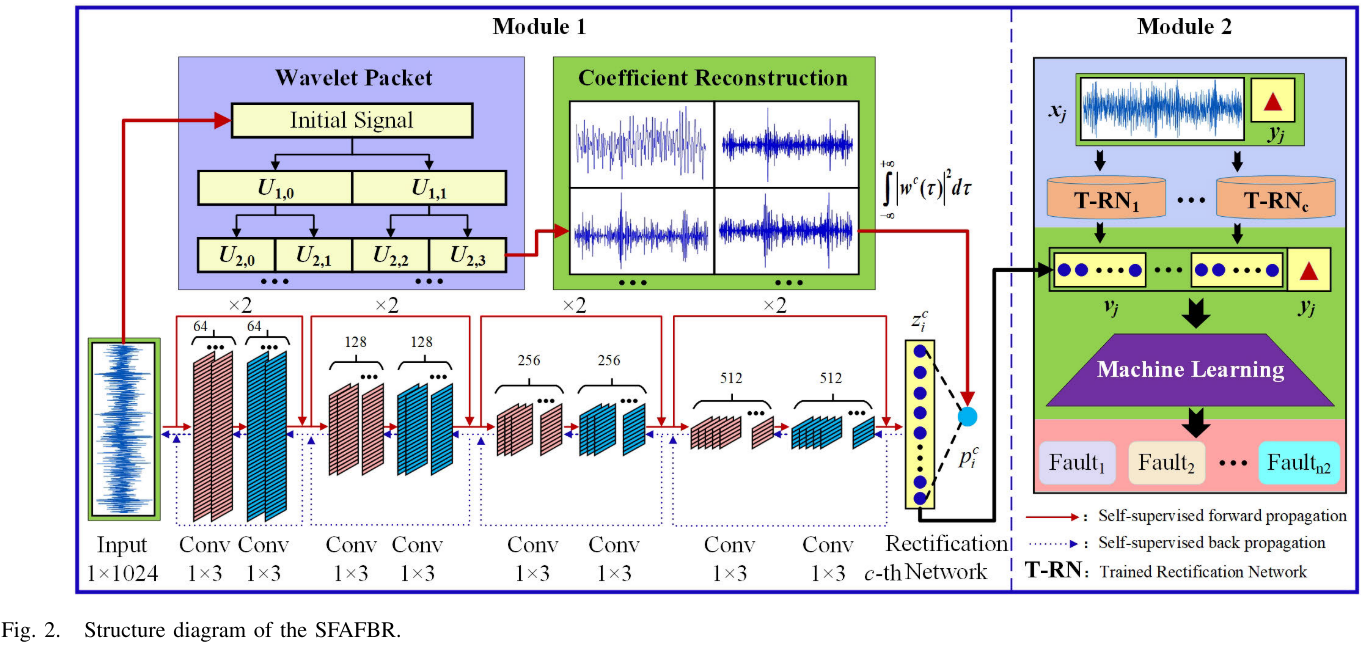
Fig. 2 --- SFAFBR整体结构图
整个框架由两个模块组成:
- Module 1:人工特征偏差纠正模块(自监督训练,仅需无标注数据)
- Module 2:ML诊断模块(仅需极少量标注数据)
3.1 Module 1:WP人工特征的构建
在进行偏差纠正之前,首先需要一组"初始人工特征"作为纠正的对象和目标。论文选用**小波包(Wavelet Packet, WP)**分解来构建这组特征。
选择WP的理由非常充分:小波基的正交性保证了信号的最优分解,WP能够同时对低频和高频子带进行进一步分解,所生成的各子带之间信息冗余最小,知识冲突天然较小------这正是其他特征构建方法(如VMD、时域/频域统计特征)所欠缺的。
具体做法是:将原始振动信号进行4层WP分解(ρ=4),在最终的 2⁴=16 个子带上各自重构信号,计算每个子带重构信号的能量值作为一维人工特征:
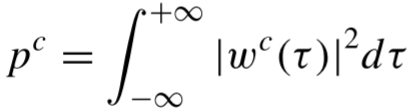
从而得到16维的WP人工特征向量。WP分解中使用Daubechies小波族的"db3"基函数,熵准则选用"Shannon"熵。
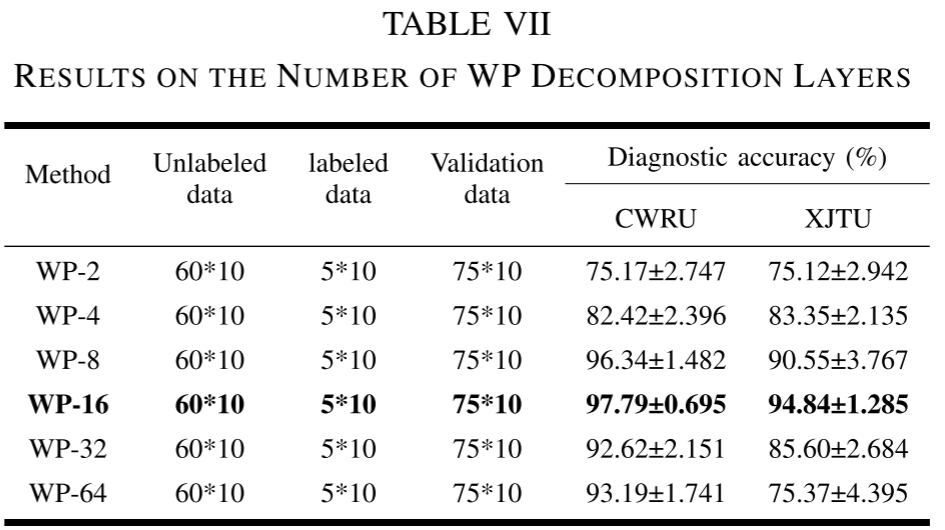
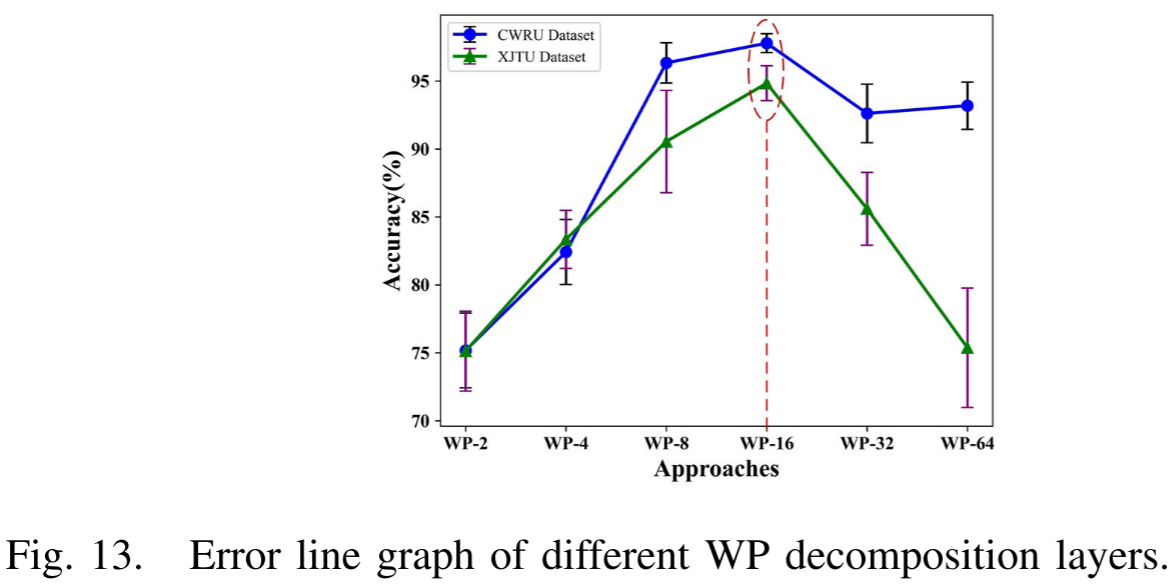
为什么ρ=4是最优? 论文进行了系统的消融实验:ρ过小时生成的特征数量不足,与诊断任务的相关性弱;ρ过大时特征间知识冲突和信息冗余急剧增加,反而加剧偏差。实验结果呈现近似正态分布的趋势,在ρ=4时取得最优。
3.2 Module 1:深度纠偏网络(Deep Rectification Network)
这是整个框架最核心的创新所在。
核心思想 :人工特征本身来源于原始信号。因此,可以将"原始信号 → 人工特征"这一映射关系视为一种自监督信息,用来训练深度网络。深度网络在拟合这一映射的过程中,会通过其稀疏表达能力,在潜空间(potential space)中形成一个"去偏版"的特征表示------这就是论文定义的上位特征(Epitaxial Features)。
上位特征的优越性在于:它既保留了人工特征中蕴含的专家知识,又融合了深度网络通用特征的数据驱动优势,泛化能力更强。
网络结构 :论文采用ResNet作为纠偏网络的骨干,利用残差结构解决训练深度增加和少量数据带来的训练误差问题。采用一对一纠偏策略------针对16个WP人工特征,分别训练16个独立的ResNet纠偏网络,每个网络输出20维上位特征(取FC1层输出),16个网络拼接后得到1×320维的上位特征向量。
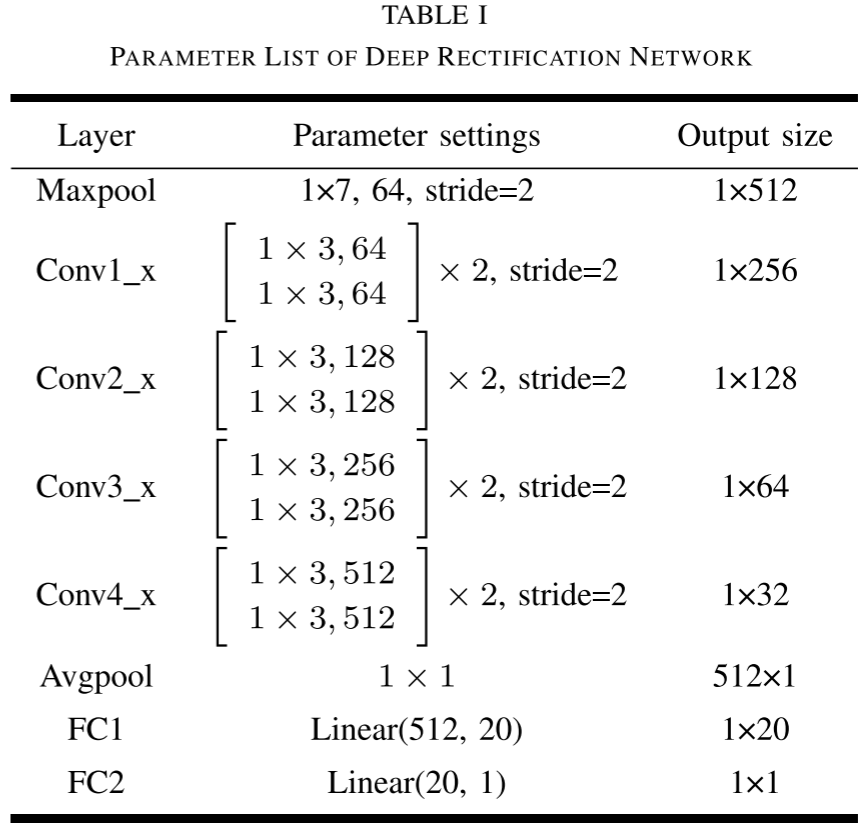
Table I --- 深度纠偏网络参数列表
训练目标(损失函数):
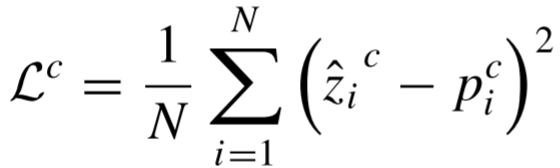
其中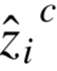 是网络FC2层的输出,
是网络FC2层的输出,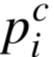 是第c个WP人工特征值。整个训练过程只使用无标注数据,完全符合自监督学习的范式。
是第c个WP人工特征值。整个训练过程只使用无标注数据,完全符合自监督学习的范式。
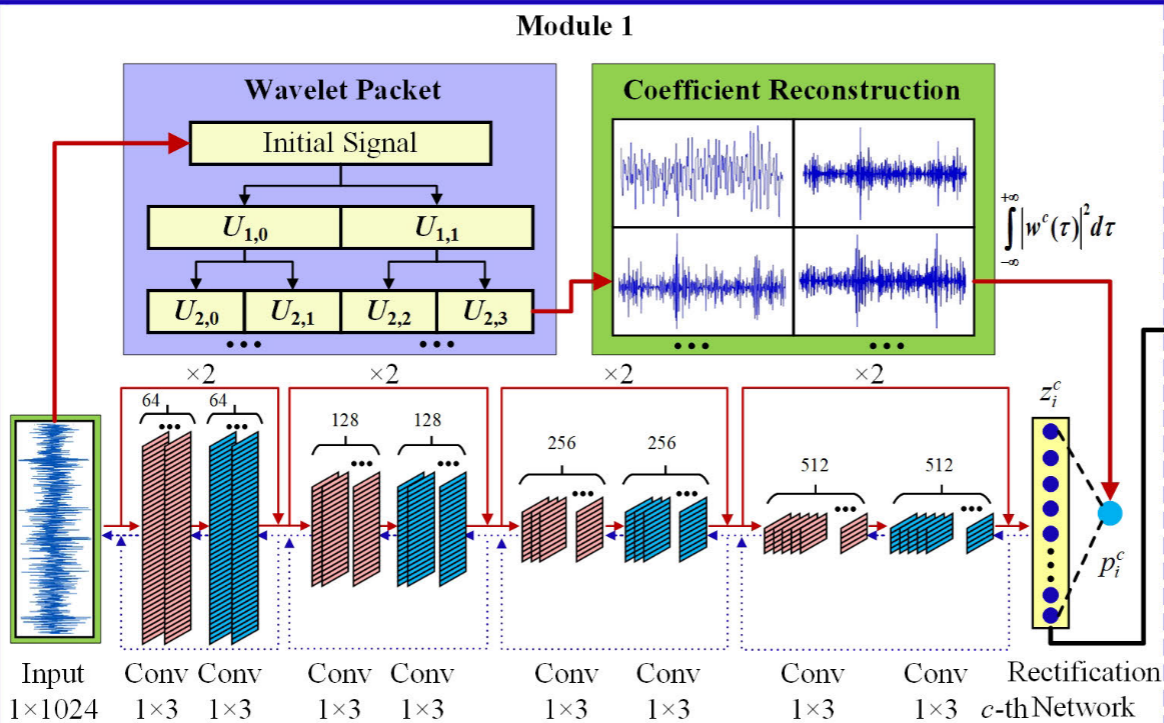
Fig. 2 --- Module 1训练流程(自监督反向传播部分)
3.3 Module 2:ML线性判别分类器
完成特征纠偏后,Module 2使用线性判别分析(LDA,由奇异值分解SVD求解) 作为分类器,输入为上位特征向量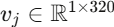 ,仅需极少量标注样本(实验中为5个/类)即可完成训练。
,仅需极少量标注样本(实验中为5个/类)即可完成训练。
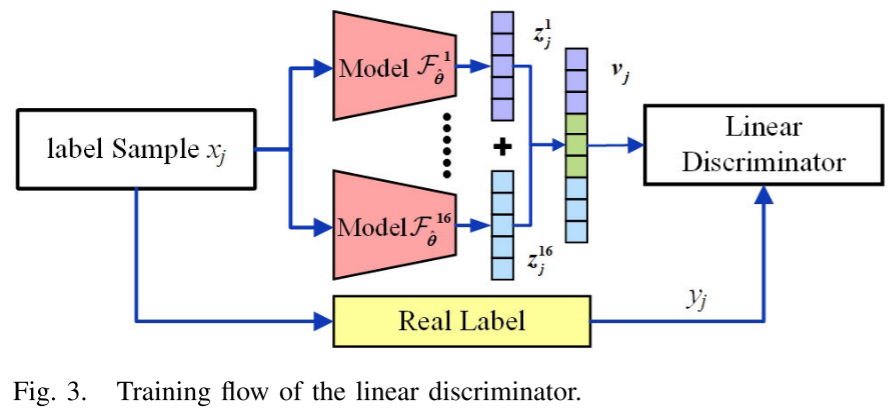
Fig. 3 --- 线性判别器训练流程图
使用LDA这一简单分类器并非妥协,而是有意为之------这恰恰可以证明:只要上位特征质量足够高,即便是最简单的线性分类器也能达到优异的诊断性能。
3.4 整体诊断工作流
整个诊断流程分为五步:
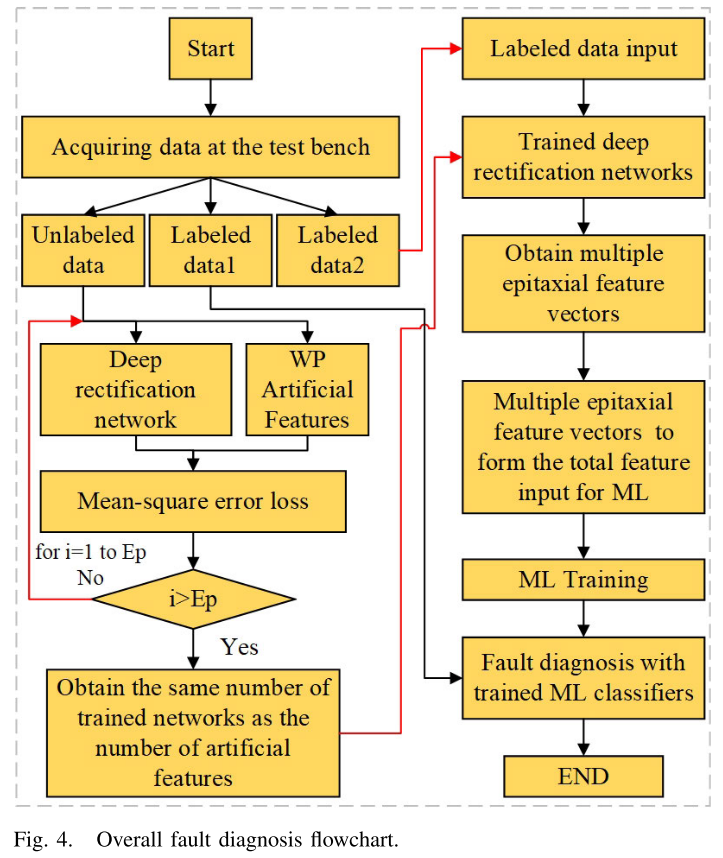
Fig. 4 --- 整体故障诊断流程图
- 振动传感器采集1D时序信号;
- 将数据划分为无标注集、少量标注集和验证集;
- 用无标注数据训练深度纠偏网络;
- 用训练好的纠偏网络提取上位特征,配合少量标注数据训练ML线性判别器;
- 用验证集进行故障诊断验证。
四、实验设计
4.1 数据集
论文在两个公开轴承数据集上进行验证:
CWRU数据集(凯斯西储大学):全球公认的轴承故障诊断基准数据集,故障类型通过电火花加工人工制造。采样频率12 kHz,转速1797 r/min,共10类轴承状态(不同故障部位 × 不同故障尺寸)。每类生成400个样本,划分为:200个用于无标注训练,100个用于ML训练(取5个),100个用于验证(取75个)。
XJTU数据集 (西安交通大学):基于加速寿命试验的实际故障数据,模拟轴承从正常到失效的全生命周期,更贴近工业现实。采样频率25.6 kHz,转速2100 r/min。值得注意的是,论文专门提取了早期故障阶段数据,这无疑增加了诊断难度。共10类故障状态,样本划分方式与CWRU一致。
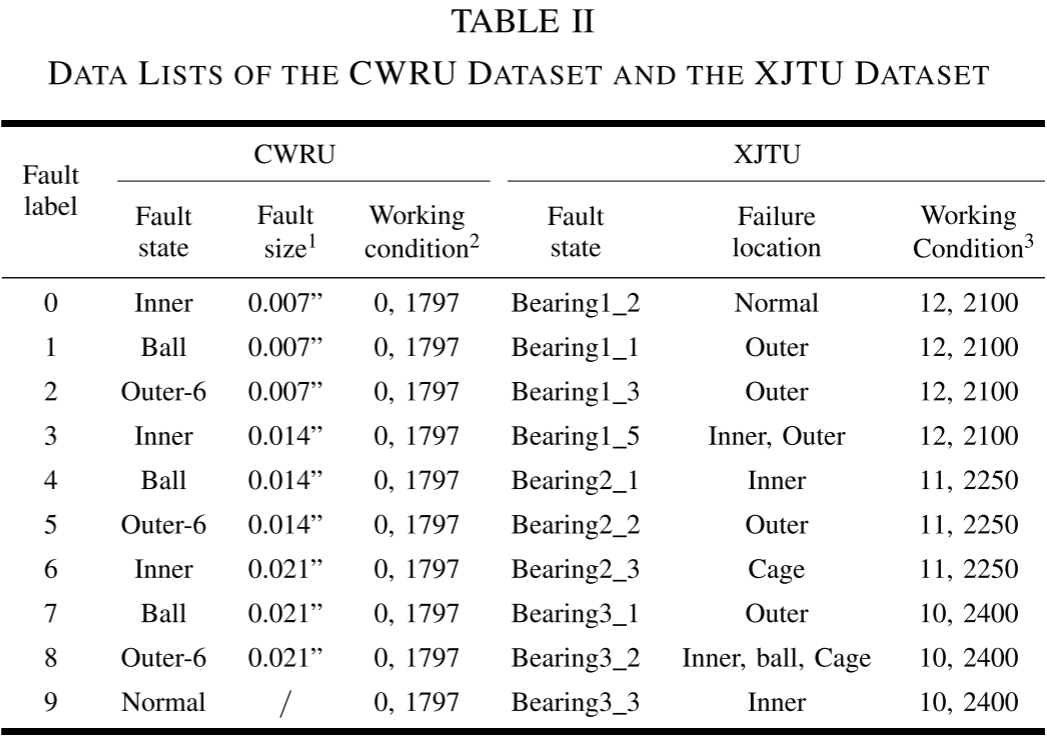
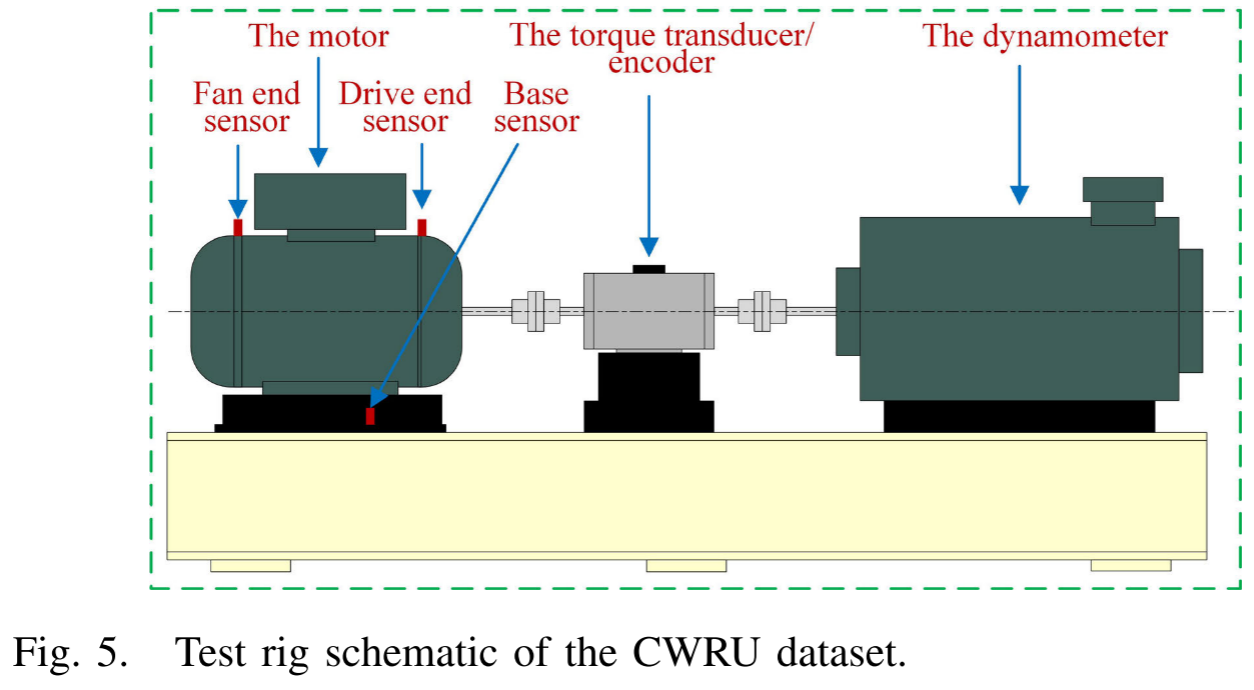

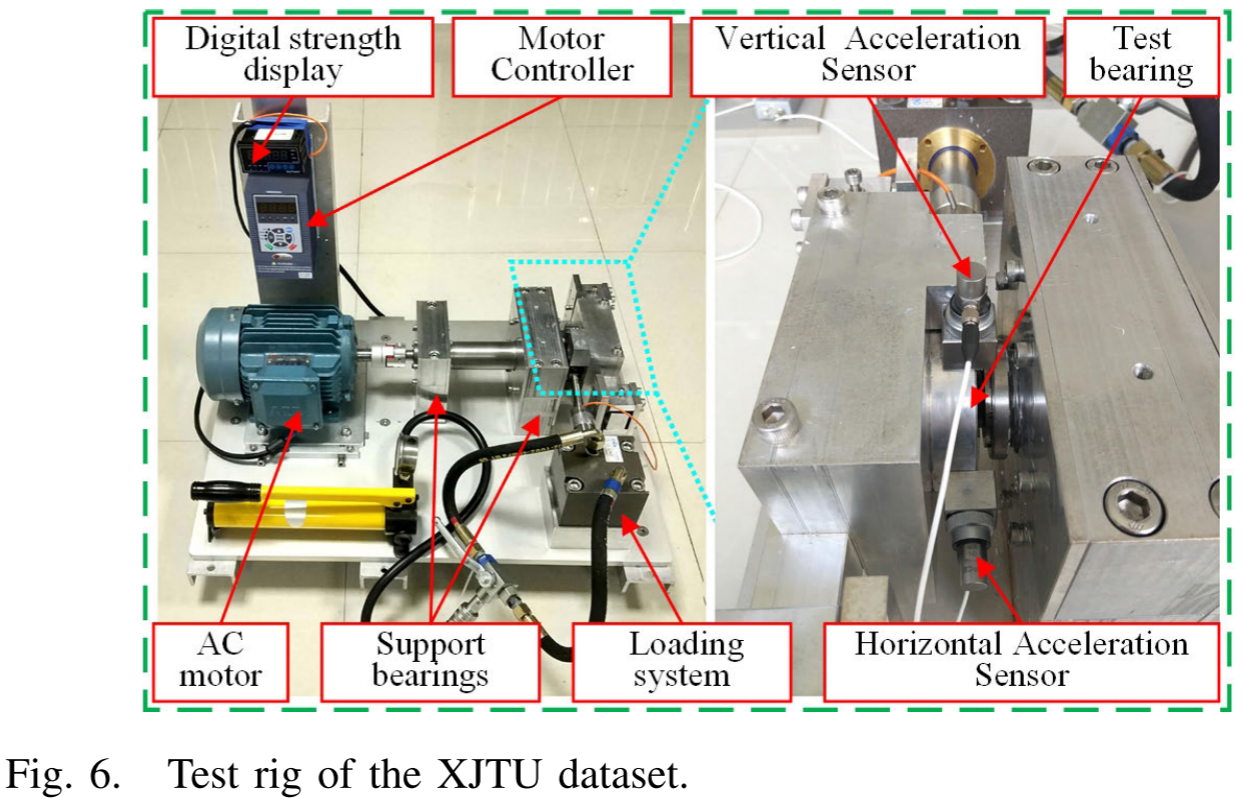
Table II --- CWRU与XJTU数据集详细信息
Fig. 5 --- CWRU测试台示意图;
Fig. 6 --- XJTU测试台照片;
Fig. 7 --- XJTU轴承失效类型图
4.2 对比方法
论文共对比了6种方法,覆盖自监督与监督两大类:
| 方法 | 类别 | 核心思想 |
|---|---|---|
| SSF | 自监督(对比学习) | SimSiam算法提取通用特征 |
| AFFE | 自监督(对比学习) | 数据增强 + Bootstrap Your Own Latent网络 |
| SSPT | 自监督(预训练任务) | 5种信号变换构建预训练任务 |
| S3M | 自监督(预训练任务) | 2种预训练任务提取全局与局部特征 |
| 1D-2D JCNN | 监督深度学习 | 1D与2D卷积神经网络联合 |
| EMD-1DCNN | 监督深度学习 | EMD分解 + 1D CNN |
实验统一超参数:Adam优化器,学习率 lr=1×10⁻³,batch size=30,迭代轮数100,每组实验重复10次取均值和标准差。
五、实验结果与分析
5.1 诊断精度对比
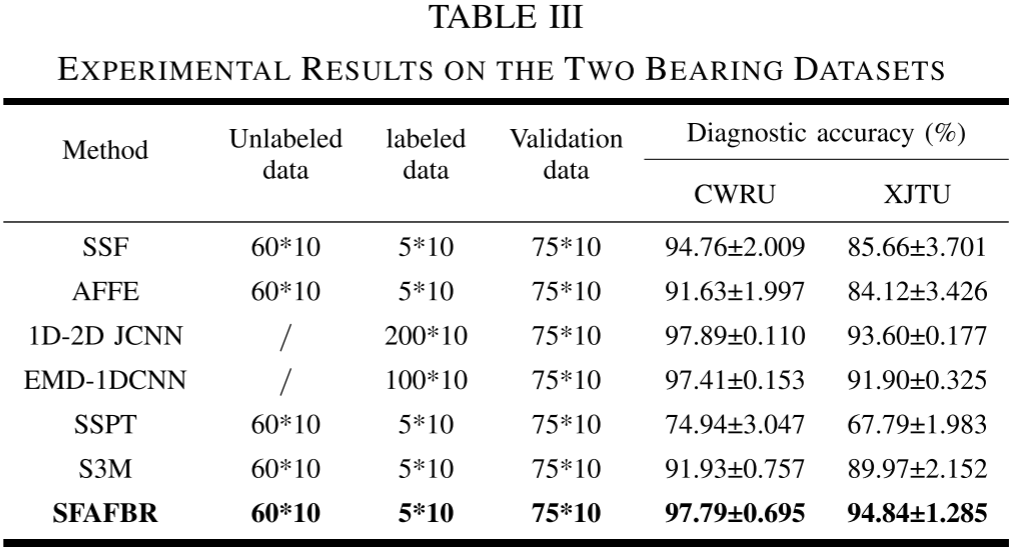
Table III --- 两个数据集上各方法的实验结果汇总
核心结论:
- SFAFBR在CWRU数据集上达到97.79±0.695%,在XJTU数据集上达到94.84±1.285%,在所有方法中综合表现最优。
- 与监督方法相比:SFAFBR仅使用了1D-2D JCNN所需标注数据量的2.5% (5个 vs 200个/类),达到相近精度;在XJTU数据集上甚至超越了所有监督方法------SFAFBR的94.84%对比EMD-1DCNN的91.90%。这说明融入专家知识的上位特征在区分真实工程信号方面具有天然优势。
- 与同类SSL方法相比:其他4种SSL方法在仅60个无标注样本的极端条件下难以提取优质通用特征,而SFAFBR只需纠正人工特征偏差,对无标注数据量要求更低,优势明显。
5.2 泛化性能:标准差分析
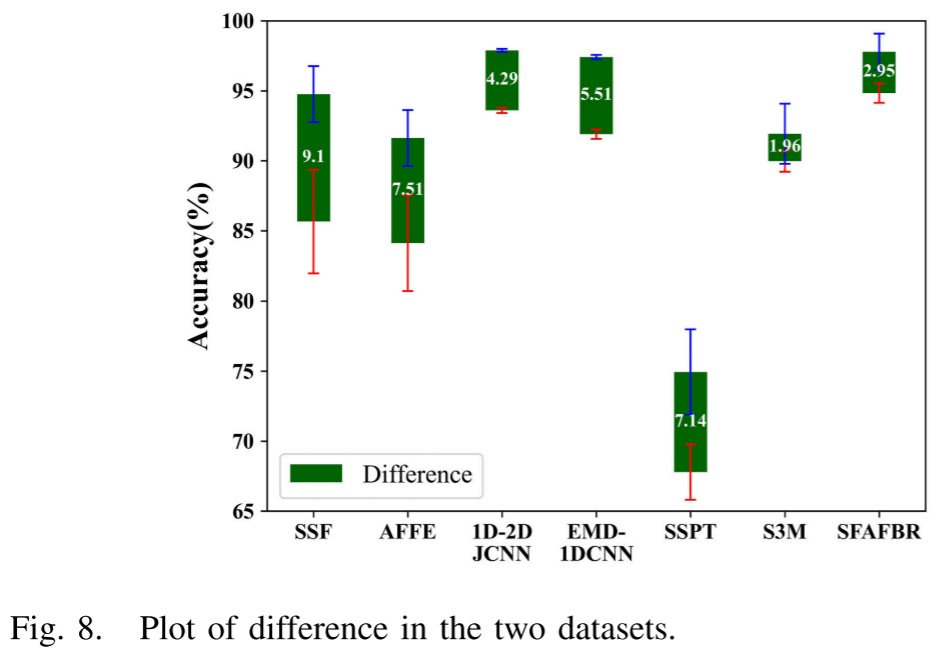
Fig. 8 --- 两个数据集上各方法实验结果差异图(含标准差误差棒)
标准差反映了方法在随机实验中的稳定性。特征偏差越大,随机实验中的标准差往往越大。由于SFAFBR通过自监督机制显著纠正了特征偏差,其标准差在5种SSL方法中最小,充分说明该方法具有更强的泛化能力和鲁棒性。
5.3 各健康状态分析:混淆矩阵
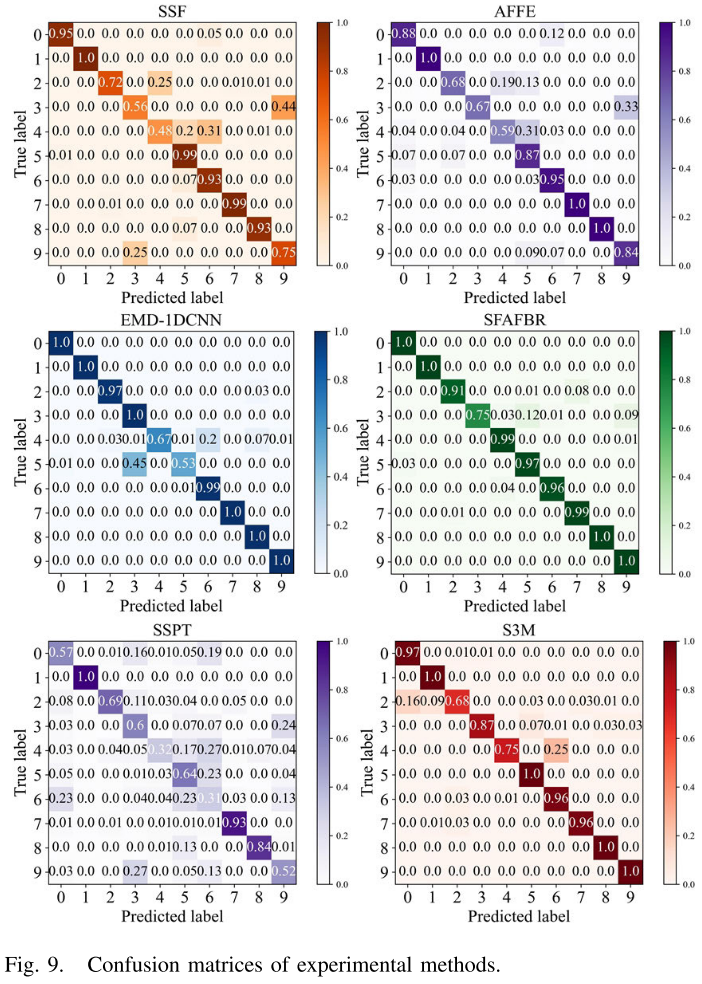
Fig. 9 --- 各方法在XJTU数据集上的混淆矩阵
以XJTU数据集为例进行细粒度分析:
- EMD-1DCNN在No.4和No.5两类故障上混淆严重,而SFAFBR对这两类分别达到99%和97%的诊断率。这说明即使监督方法使用大量标注样本,其通用特征仍可能不完整,对混淆故障类区分困难;而SFAFBR的上位特征融入了大量专家经验知识,对混淆故障的区分能力更强。
- 四种SSL方法在No.2、No.3、No.4三类故障上均出现混淆,SFAFBR对这三类分别提升至91%、75%、99%。
5.4 特征空间可视化:t-SNE分析
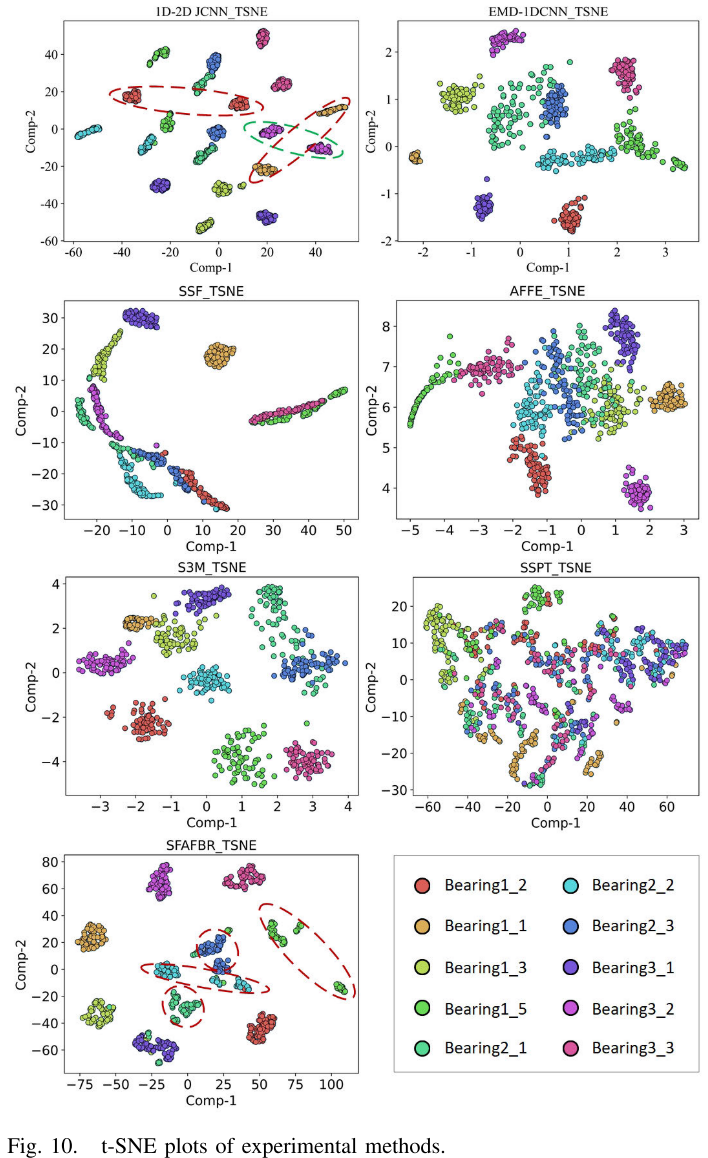
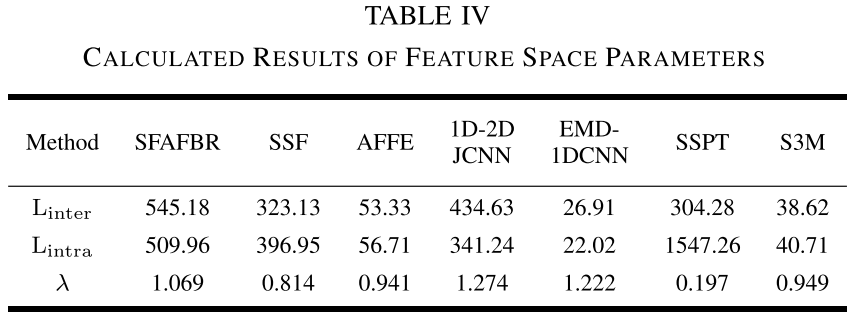
Fig. 10 --- 各方法特征空间的t-SNE可视化图
Table IV --- 特征空间参数(类间距/类内距/λ值)计算结果
论文引入参数 λ = L_inter / L_intra(类间距与类内距之比)来定量衡量特征空间质量,λ越大代表特征空间中不同类别区分越清晰。
计算结果显示,SFAFBR的λ=1.069,在所有SSL方法中最高(SSF: 0.814,AFFE: 0.941,SSPT: 0.197,S3M: 0.949),进一步证明上位特征质量优越。虽然两种监督方法的λ值更高(依靠大量标注样本的训练优势),但结合混淆矩阵分析可知,这种"更好看"的特征空间并不总是转化为更好的下游诊断性能------SFAFBR的上位特征中丰富的专家知识使其在相对较小的λ值下依然取得了超越监督方法的诊断性能。
5.5 人工特征构建方式对比
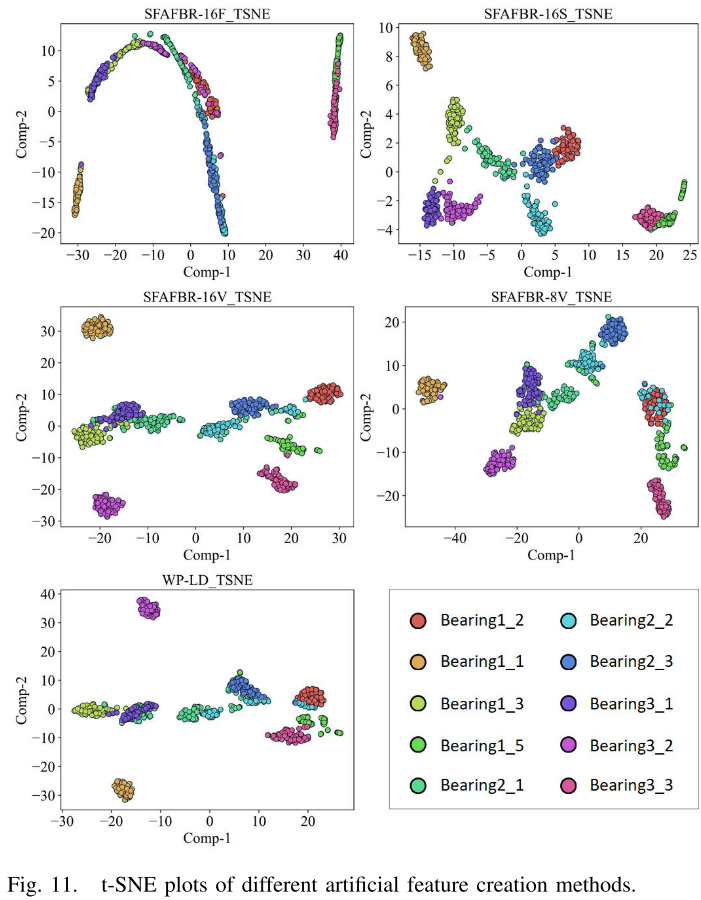
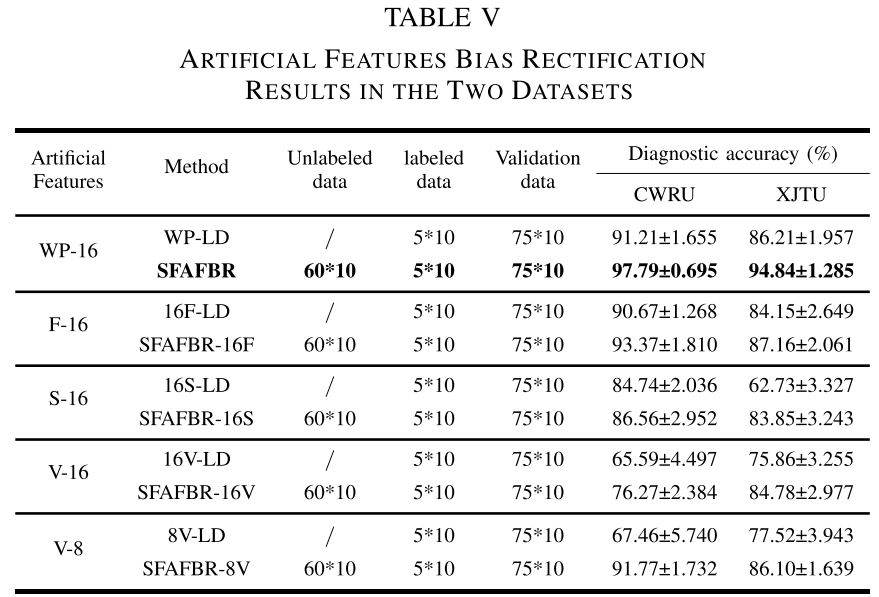
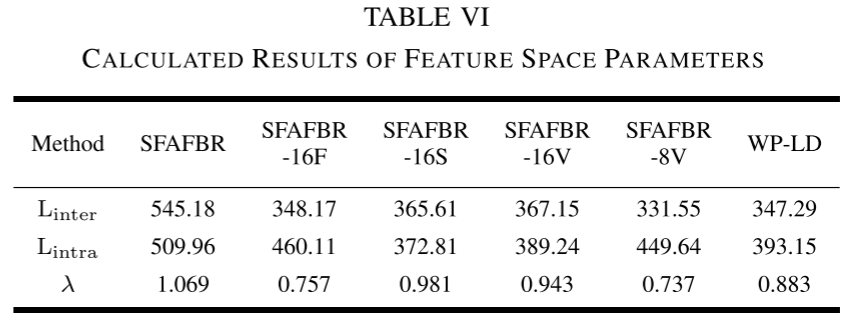
Fig. 11 --- 不同人工特征构建方式的t-SNE可视化
Table V --- 不同人工特征方式在两个数据集上的诊断精度对比
Table VI --- 不同人工特征方式的特征空间参数对比
论文对比了5种人工特征构建方式:
| 方法 | 特征类型 | CWRU精度 | XJTU精度 |
|---|---|---|---|
| WP-16(本文) | 16维WP能量特征 | 97.79% | 94.84% |
| SFAFBR-16F | 16维频域统计特征 | 93.37% | 87.16% |
| SFAFBR-16S | 16维时域统计特征 | 86.56% | 83.85% |
| SFAFBR-16V | 16维VMD能量特征 | 76.27% | 84.78% |
| SFAFBR-8V | 8维VMD能量特征 | 91.77% | 86.10% |
WP特征全面领先的原因:VMD方法存在残差分量引入额外偏差;时频域统计特征只关注信号的单一侧面,且任意组合导致更大的知识冲突;而WP正交分解天然保证了特征间的最小冗余,偏差最小。
5.6 偏差纠正能力验证
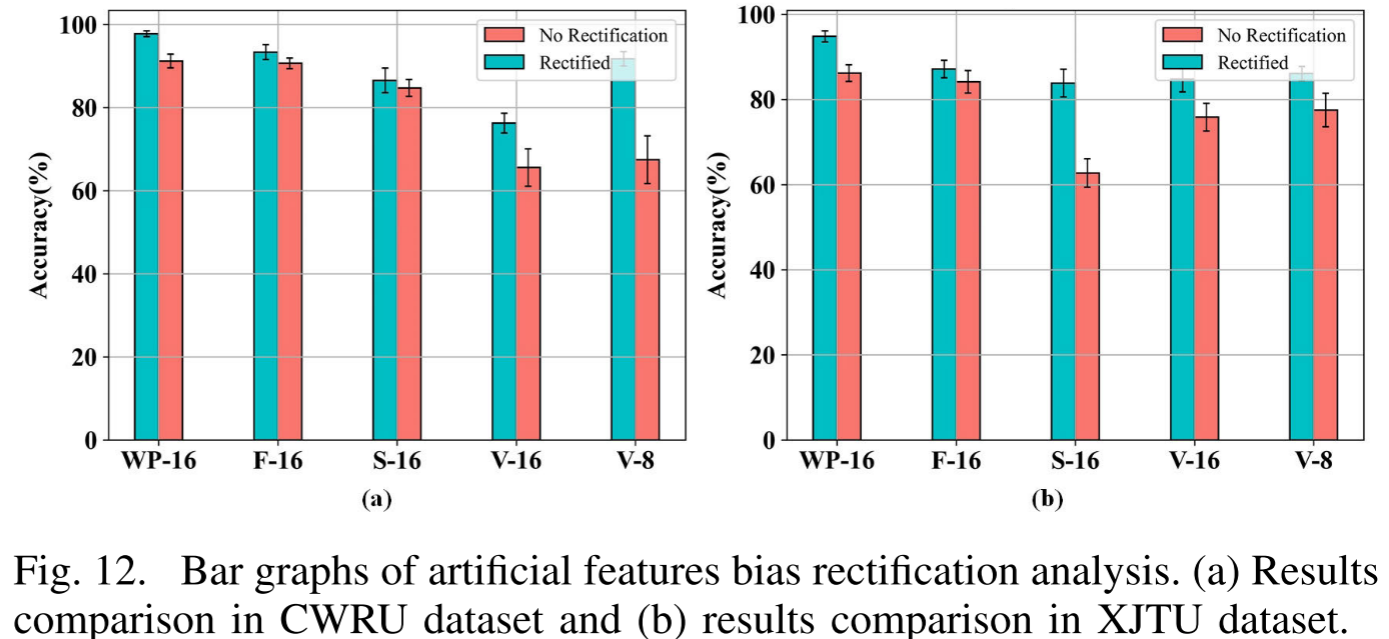
Fig. 12 --- 不同人工特征纠正前后的诊断精度对比条形图
对所有5种人工特征类型均进行了纠正实验,结果表明:所有类型的人工特征经过深度网络纠正后,诊断性能均有提升,充分验证了深度网络作为偏差纠正工具的有效性。
以WP特征为例,纠正后的特征空间λ值从0.883(直接使用WP特征+LDA)提升至1.069(SFAFBR),特征空间优化效果显著。
5.7 关键参数分析
参数ρ(WP分解层数):实验结果呈正态分布趋势,ρ=4对应16维特征时取得最优性能(CWRU: 97.79%,XJTU: 94.84%)。
参数zi(上位特征维度) :结果呈"先升后降"趋势,维度过低则上位特征不足以表征原始信号,维度过高则导致过拟合。综合实验,zi=20为最优值。
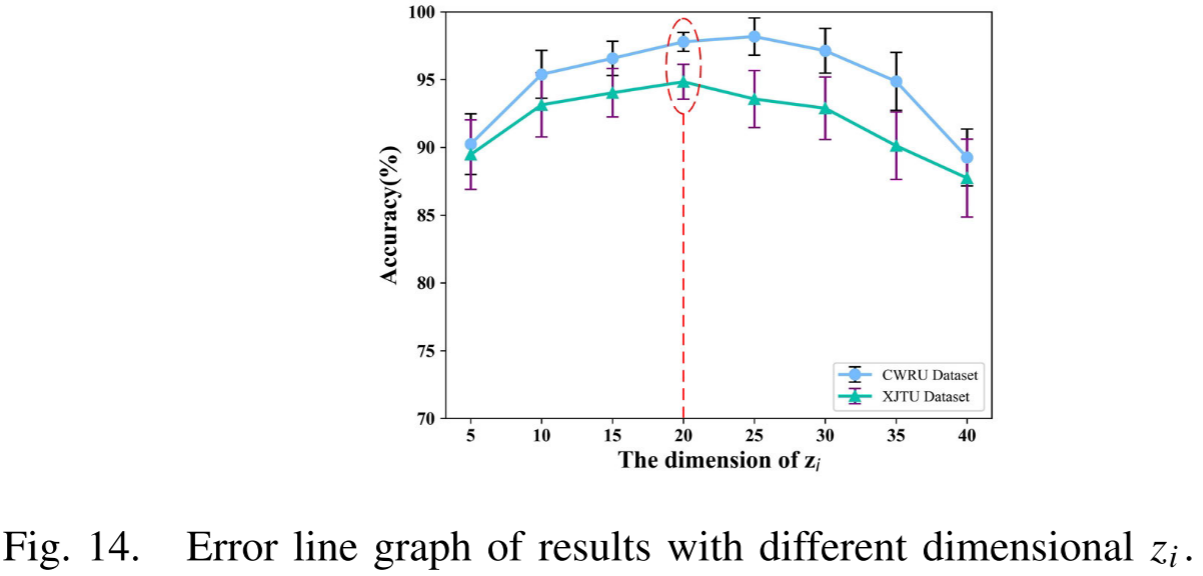
Fig. 14 --- 不同上位特征维度zi下的误差折线图
六、局限性与未来展望
论文作者坦诚地指出了SFAFBR的不足:一对一纠偏策略导致深度网络数量是其他方法的数倍(16个纠偏网络),模型总参数量显著增加,训练时间延长。
不过作者也指出,当这些代价能够有效解决实际工程挑战时,它们是合理的。
未来研究方向将重点关注数据不均衡问题,这是更贴近工业现实的挑战场景。
七、总结
SFAFBR的核心价值可以用一句话概括:
用深度网络纠正人工特征偏差,用上位特征驱动机器学习,在极少标注数据下实现可靠的轴承故障诊断。
这篇论文的贡献不仅在于提出了一种新的方法,更在于揭示了一个长期被忽视的问题------人工特征偏差是制约ML方法诊断性能的关键瓶颈,并给出了一个优雅的解决方案:让深度网络做"特征医生",让机器学习做"诊断专家",各司其职,相得益彰。
对于工业场景中标注样本极其稀缺的实际应用,SFAFBR提供了一种实用且高效的新思路。