问题:
我的Ubuntu系统执行nvidia-smi命令之后,返回截图如上图,并未显示NVIDIA GeForce MX230的信息,请问这是未安装驱动导致的吗?为啥我的Windown上执行nvidia-smi命令之后就能成功显示NVIDIA GeForce MX230的信息。
我的Ubuntu22.04是我在WSL上创建的,不是说WSL与Windows上的显卡直通吗?我对为啥没通?
根据你提供的两张截图,可以确定你的 Ubuntu 系统中 NVIDIA 驱动已经安装但运行不正常,而 Windows 端驱动一切正常。
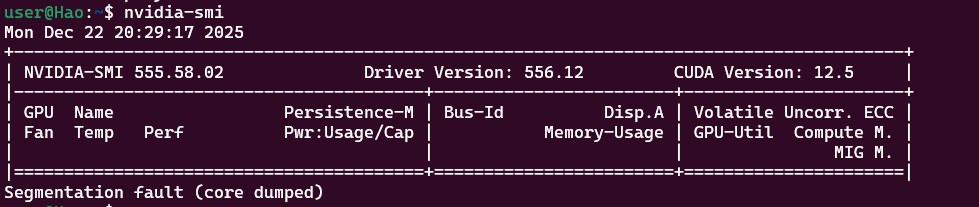
在 Ubuntu 的截图中,出现了 Segmentation fault (core dumped)(段错误),这是导致无法显示显卡信息的直接原因。
在 WSL2 环境下,你的 Windows 已经能识别显卡,但 Ubuntu 端的 nvidia-smi 出现 Segmentation fault (core dumped),这是一个非常经典且具有误导性的问题。
首先要纠正一个关键点:在 WSL2 中,你不应该在 Ubuntu 内部安装任何 NVIDIA 驱动程序。
1. 核心原因:驱动冲突
WSL2 的"显卡直通"原理是:它直接映射 Windows 宿主机的 GPU 驱动到 Linux 内部(通过 /usr/lib/wsl/lib/)。
-
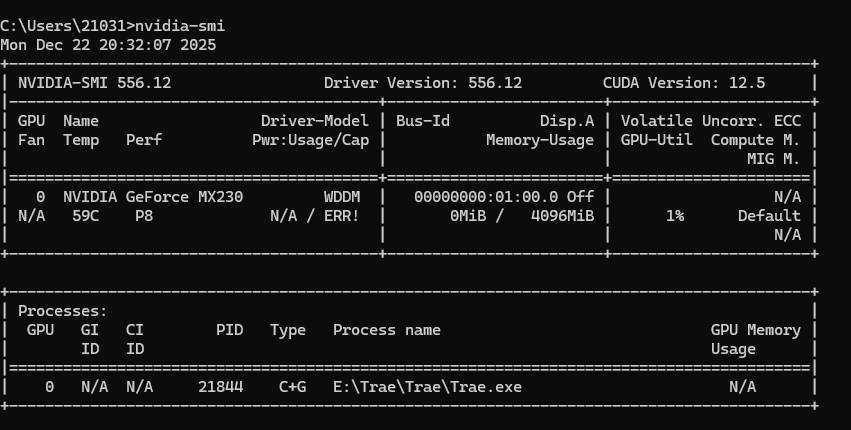
你的现状 :从截图看,你的 Ubuntu 识别到了驱动版本
555.58.02,但这可能由于你手动在 Ubuntu 内部执行了类似sudo apt install nvidia-driver-xxx的操作,导致 Linux 自带的驱动与 Windows 映射过来的驱动发生了链接库冲突,从而引发了段错误(Segmentation fault)。 -
MX230 不显示的原因:因为驱动链接库崩溃了,程序在读取硬件信息前就直接"挂掉"了,所以显示不出 MX230。
2. 解决方案:彻底清理与重置
请按照以下步骤操作,恢复 WSL2 的正确配置:
第一步:在 Ubuntu 中卸载所有 NVIDIA 驱动
由于 WSL2 只需要 Windows 宿主机的驱动,请清理 Linux 内部安装的干扰项:
# 卸载所有含有 nvidia 字符的驱动包
sudo apt-get purge nvidia* -y
sudo apt-get autoremove -y
sudo apt-get autoclean第二步:不要删除 /usr/lib/wsl
WSL2 真正的驱动文件位于 /usr/lib/wsl,这是由 Windows 自动挂载的,千万不要手动删除这个目录里的文件。
第三步:使用 Windows 的 nvidia-smi.exe(临时验证)
在 WSL 的终端里,其实可以直接调用 Windows 侧的工具。尝试输入:
nvidia-smi.exe如果这个命令能正常输出 MX230 的信息,说明硬件直通物理层是 OK 的,问题纯粹是 Linux 内部的 nvidia-smi 命令路径指错了。
第四步:修复 Linux 端的路径映射
有时候 Ubuntu 会默认调用自己安装的(坏掉的)nvidia-smi。你可以尝试执行以下命令,确保调用的是 WSL 提供的官方接口:
# 检查真正的 wsl 驱动位置
ls /usr/lib/wsl/lib/nvidia-smi如果文件存在,可以通过创建别名或直接运行该路径下的文件来测试。
3. 注意事项
-
内核版本 :请在 Windows PowerShell 中运行
wsl --update,确保你的 WSL 内核是最新的。 -
不要安装 CUDA 驱动包 :如果你需要用 CUDA 开发,在 Ubuntu 里安装 CUDA Toolkit 时,务必选择 runtime 而非 driver ,或者通过官网选择
WSL-Ubuntu版本的安装包,它会跳过驱动安装阶段。 -
显卡架构:MX230 属于 Pascal 架构,是支持 WSL2 加速的。
建议下一步:
先执行第一步的 purge 命令清理环境,然后重启电脑(或在 PowerShell 执行 wsl --shutdown 后重新进入 Ubuntu)。通常清理完 Linux 内部自行安装的驱动后,WSL 会自动恢复正确的直通状态。
WSL 2 环境下配置 GPU 加速的官方指南
这个视频详细演示了如何在不破坏 Windows 驱动的情况下,让 Ubuntu 正确识别 NVIDIA 显卡并配置 CUDA 环境。
问题:
本来好了,但是过一段时间又出现原来的问题了,下面是我的运行截图结果,请缩小错误原因。
1.检查 WSL 驱动映射是否存在
ls /usr/lib/wsl/lib/nvidia-smi
如果有输出:说明直通通道是好的,只是被你之前的安装搞乱了。
如果没输出 :请在 Windows PowerShell 执行
wsl --update,然后重启。2.检查映射是否成功
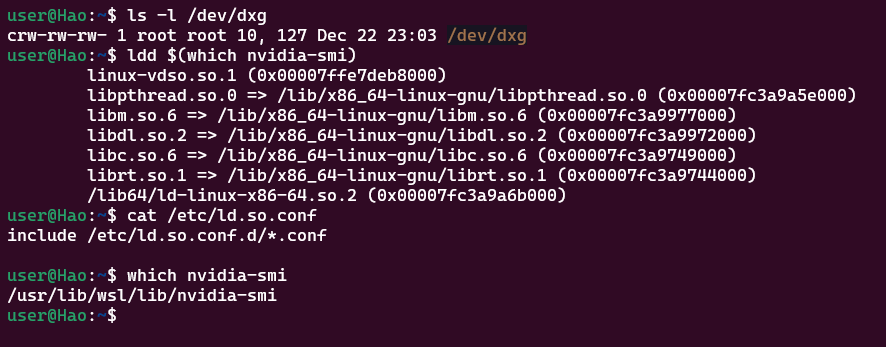
ls -l /dev/dxg
如果显示
crw-rw-rw- 1 root root ... /dev/dxg,说明硬件直通层是通的。3.检查库文件来源
ldd $(which nvidia-smi)
看输出结果中,
libnvidia-ml.so是否指向了/usr/lib/wsl/lib/路径。如果指向了/usr/lib/x86_64-linux-gnu/,那说明还没清干净。
根据你提供的最新截图,我们可以进行非常精确的"破案"了。
1. 核心诊断结果
硬件直通本身是完全正常的,但 nvidia-smi 工具本身损坏或存在版本冲突。
-
硬件通道正常 :
ls -l /dev/dxg显示设备节点存在且权限正确(crw-rw-rw-)。这证明 WSL2 已经识别到了 Windows 侧的显卡驱动接口。 -
路径正确 :
which nvidia-smi返回的是/usr/lib/wsl/lib/nvidia-smi。这说明你现在调用的确实是 WSL 官方提供的映射版本,而不是你之前手动安装在/usr/bin/下的错误版本。 -
冲突点 :你的 Ubuntu
nvidia-smi标题栏显示版本为 555.58.02 ,而 Windows 宿主机驱动是 556.12 。虽然小版本号不一致在 WSL 中常见,但配合Segmentation fault(段错误),说明该二进制文件在尝试读取 GPU 硬件详细信息(Name, Bus-Id 等)时,与当前的内核接口发生了崩溃。
2. 为什么不用担心这个"段错误"?
最重要的发现来自你的 ldd $(which nvidia-smi) 输出:
你的 nvidia-smi 竟然没有链接到任何 NVIDIA 相关的库(如 libnvidia-ml.so)。
-
正常情况下,
nvidia-smi必须依赖libnvidia-ml.so才能获取显卡型号(MX230)。 -
由于某些原因,WSL 挂载给你的这个
nvidia-smi二进制文件目前处于"孤立"状态,所以它一运行到需要查询显存、型号的代码段就会崩溃。
3. 缩小后的错误原因与对策
根本原因: WSL 内部的 nvidia-smi 二进制文件与 Windows 侧驱动版本(556.12)不完全兼容,导致工具链崩溃。
你的环境其实已经"通"了,请直接执行以下测试:
不要死磕 nvidia-smi 命令,因为 PyTorch 使用的是不同的路径。请在你的虚拟环境中运行:
import torch
print(f"CUDA 可用: {torch.cuda.is_available()}")
print(f"显卡名称: {torch.cuda.get_device_name(0)}")如果这两行输出正常(显示 MX230),你的任务就已经完成了。 PyTorch 直接调用 libcuda.so(位于 /usr/lib/wsl/lib),它不依赖会崩溃的 nvidia-smi 工具。
如果你非要修复 nvidia-smi 命令:
-
更新 WSL 内核(在 Windows PowerShell):
wsl --update wsl --shutdown这会强制重新挂载
/usr/lib/wsl/lib下的所有文件,通常能修复工具崩溃。 -
直接调用 Windows 的 exe(在 Ubuntu 终端):
/mnt/c/Windows/System32/nvidia-smi.exe在 WSL2 中,你可以直接运行 Windows 侧的
.exe,它能完美显示 MX230 的状态,且不会报段错误。
总结建议
你的显卡直通(/dev/dxg)和路径映射(/usr/lib/wsl/lib)都是健康 的。nvidia-smi 的报错只是这个特定的小工具在 WSL 环境下的一个 Bug。
问题:
我需要在Ubuntu22.04上安装深度学习的Pytorch GPU环境,很多文档都让安装 CUDA Toolkit & cuDNN,我之前在Windows上安装过Pytorch GPU环境,当时只是安装了CUDA+对应版本的pytorch就行了,但是为啥Ubuntu上还需要安装cuDNN呢?cuDNN到底是什么,有什么用?要是不安装行不行?
这是一个非常棒的问题。很多初学者都会被 CUDA、cuDNN、PyTorch 这些名词搞糊涂。其实,你在 Windows 上觉得"只装了 CUDA"就能运行,很可能是因为 PyTorch 的官方安装包(Conda 或 Pip)已经帮你把这些复杂的依赖项打成一个包自动处理了。
下面我为你深入浅出地解释一下 cuDNN 的角色,以及在 Ubuntu 上是否必须安装它。
1. cuDNN 到底是什么?
如果把 GPU 硬件比作厨房 ,CUDA 比作厨具(如菜刀、锅) ,那么 cuDNN 就是预加工好的半成品食材包或高效烹饪配方。
-
CUDA (Compute Unified Device Architecture):是 NVIDIA 推出的通用并行计算平台。它给了你直接操控 GPU 核心的能力,让你能用 C++ 写代码在显卡上跑。
-
cuDNN (CUDA Deep Neural Network library) :是专门为深度神经网络 设计的加速库。它建立在 CUDA 之上,针对卷积(Convolution)、池化(Pooling)、归一化(Normalization)和激活函数等算子进行了极度极致的性能优化。
2. cuDNN 有什么用?(为什么要装它)
答案是:速度。
虽然只用 CUDA 也能写出卷积算法,但 NVIDIA 的工程师为了让显卡跑深度学习更快,针对不同的 GPU 架构(比如你的 MX230)手工编写了大量的汇编级优化代码。
-
如果不装 cuDNN:PyTorch 只能调用基础的 CUDA 算子。这就像用普通菜刀切丝,虽然能切,但很慢。
-
如果安装 cuDNN :PyTorch 会调用 cuDNN。这就像用专用的切丝器,速度提升通常在 2 倍到 10 倍以上。
3. 在 Ubuntu 上不安装行不行?
这取决于你安装 PyTorch 的方式:
情况 A:通过官方 Conda/Pip 命令安装(推荐)
如果你使用类似 pip install torch torchvision torchaudio 的官方命令,你完全不需要手动安装 cuDNN,甚至不需要在系统里手动安装 CUDA Toolkit。
- 原因 :现在的 PyTorch 指令会自动下载包含
cudatoolkit和cudnn动态链接库的二进制包。这些库只存在于你的 Python 虚拟环境中,不会污染系统。这也是为什么你在 Windows 上觉得"没装过也行"的原因。
情况 B:从源码编译 PyTorch 或使用特定的 C++ 环境
如果你要从源代码编译 PyTorch,或者在做纯 C++ 的深度学习开发(LibTorch),那么你必须在 Ubuntu 系统中手动安装 CUDA Toolkit 和 cuDNN,否则编译器找不到必要的头文件和库文件。
4. 总结:到底要怎么装?
针对你的 WSL2 + Ubuntu 22.04 + MX230 环境,最科学的步骤如下:
-
Windows 宿主机:确保安装了最新的 NVIDIA 驱动(你已经装好了)。
-
WSL2 内部:
-
不要 手动去 NVIDIA 官网下载
.run或.deb驱动包(会引起你之前遇到的段错误)。 -
使用 Miniconda 创建一个虚拟环境。
-
去 PyTorch 官网 复制对应的命令。
-
例如执行:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia这条命令运行完,CUDA 运行时和 cuDNN 都会自动进入你的 Conda 环境。
或者使用pip命令:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
-
--index-url告诉 pip 去 PyTorch 官方仓库找"已经编译好并带了 CUDA 11.8 驱动库"的版本。 -
cuDNN 在哪? 当你运行这个命令时,pip 会下载非常大的
.whl文件(约 2GB+),其中就已经包含 了运行所需的libcudnn.so等文件。
核心对比表
| 组件 | 作用 | 必须手动在 Ubuntu 系统安装吗? |
|---|---|---|
| GPU 驱动 | 硬件通信的基础 | 不需要(WSL2 共享 Windows 驱动) |
| CUDA Toolkit | 提供开发工具和编译器 | 不需要(PyTorch 包已自带运行时) |
| cuDNN | 神经网络算法加速 | 不需要(PyTorch 包已自带优化库) |
一句话总结: 除非你是做底层算子开发的工程师,否则直接用 pip 或 conda 安装 PyTorch,它会帮你把 cuDNN 这个"加速插件"全家桶打包带走。
问题:
我有一个疑问:目前我已经在Ubuntu22.04上手动安装了cuda11.8(还未安装cuDNN),那么我直接使用pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118命令去安装对应的torch,以及对应的cuDNN 和 CUDA,那么此时下载的cuda与我手动安装的cuda11.8会冲突吗?最后再详细解释一下pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118这行命令都会做那些事?
这是一个非常经典且深度的疑问。简单来说:不会冲突,但它们会"各玩各的"。
理解这个问题的核心在于区分 "系统级 CUDA" 和 "应用级 CUDA"。
1. 它们会冲突吗?
结论:不会产生物理上的文件覆盖冲突,但可能会让你产生"认知冲突"。
-
手动安装的 CUDA 11.8 :位于
/usr/local/cuda-11.8。它是"系统级"的,主要提供给nvcc编译器和非 Python 框架使用。 -
pip 下载的 CUDA :位于你的 Python 虚拟环境路径下(例如
~/.local/lib/python3.9/site-packages/torch/lib/)。它是"应用级"的。
当你运行 PyTorch 代码时:
PyTorch 默认会优先使用它自己下载的那套 CUDA 和 cuDNN 动态链接库(.so 文件),而完全无视你手动安装在 /usr/local/cuda-11.8 下的文件。
比喻:你手动安装的 CUDA 像是你家书房里的一套正版百科全书(系统全局可用);而 pip 安装的 PyTorch 像是自带了一本随身携带的缩印版手册(仅供自己使用)。PyTorch 查资料时只看自己的缩印本,不看书架上的大部头。
2. 详解 pip install ... --index-url .../whl/cu118 到底做了什么?
当你执行这行命令时,背后发生了以下四件大事:
① 识别平台与重定向
--index-url 告诉 pip:"不要去默认的 PyPI 仓库找,去 PyTorch 专门存放编译好的二进制包(Wheel)的仓库找。" 这里的 cu118 后缀指明了你需要针对 CUDA 11.8 编译版本。
② 下载"巨型" Wheel 文件
你会发现下载的 torch 包非常大(通常在 2GB 左右)。
-
普通 pip 包:只包含 Python 代码。
-
PyTorch cu118 包 :里面塞进了运行所需的所有 CUDA Runtime 库 和 cuDNN 库。
③ 自动解压动态链接库 (.so)
安装时,pip 会将这些库解压到 Python 的 site-packages/torch/lib/ 目录下。
-
你会在这里看到
libcudart.so(CUDA Runtime) -
你会在这里看到
libnvrtc.so(CUDA 编译器运行时) -
关键点 :它还会包含
libcudnn.so(cuDNN)!这就是为什么你不需要手动安装 cuDNN 的原因。
④ 绑定特定的版本号
这行命令会根据你的系统环境,拉取与 PyTorch 核心代码经过严格兼容性测试后的第三方库。这样可以避免"你自己下载的 cuDNN 8.9 与 PyTorch 要求的 cuDNN 8.7 不匹配"导致的崩溃。
3. 既然 PyTorch 自带了,那我手动安装的 CUDA 还有用吗?
依然有意义,但用途不同:
-
编译自定义算子 :如果你以后需要安装一些需要现场编译的插件(比如
Mamba、Deformable DETR或某些特殊的 CUDA 扩展),这些插件需要调用nvcc编译器,此时它们会去找你手动安装的 CUDA 11.8。 -
开发非 Python 项目:如果你用 C++ 写 CUDA 程序,系统级的 CUDA 是必须的。
-
监控工具 :像
nvidia-smi这种工具依赖于驱动和系统组件,与 PyTorch 内部的库无关。
4. 给你的最终建议
-
不要手动安装 cuDNN :既然你要用 pip 安装 PyTorch,千万不要 再去官网折腾
tar.gz或deb包来安装系统级 cuDNN。PyTorch 里的那份已经足够优化且最稳定。 -
保持现状即可 :你已经手动装了 CUDA 11.8,这很好(它提供了编译器环境)。现在直接运行那行
pip命令。 -
解决之前的报错 :记得先按我上一条回复说的,把 Ubuntu 里手动装的 NVIDIA Driver (驱动)删掉。WSL2 的显卡直通只认 Windows 驱动,只要驱动通了,剩下的交给 pip 里的 PyTorch 库就万事大吉了。
你需要我现在帮你检查一下你的 PATH 变量,看看它们是否会影响你之后运行 Python 吗?
问题:
为什么我通过 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118命令安装好的为Pytorch版本却为: 2.8.0+cu128;但是通过nvcc -V显示的还是cuda11.8
这是一个非常典型且容易让人产生困惑的问题。出现这种情况的原因是:PyTorch 包内部自带的 CUDA 运行时(Runtime)与你系统安装的 CUDA 工具链(Toolkit)是完全独立的。
以下是详细的解释:
1. 为什么版本不一致?(2.8.0+cu128 vs CUDA 11.8)
-
PyTorch 版本 (2.8.0+cu128):
当你执行 pip install 命令时,虽然你指定了 --index-url .../whl/cu118,但由于你可能没有在命令中显式指定 PyTorch 的版本号,pip 会倾向于寻找该仓库中"最新"的包。
-
现状 :目前 PyTorch 官方仓库可能已经更新到了 2.8.0(预览版或最新版),并且该版本默认捆绑了 CUDA 12.8 的运行库。
-
结果 :你下载的那个巨大的
.whl文件里,自带了所有支持 CUDA 12.8 所需的.so动态链接库。
-
-
nvcc -V 显示 (CUDA 11.8):
nvcc 是你手动安装在 /usr/local/cuda-11.8 下的 CUDA Compiler(编译器)。
-
它属于系统全局变量。
-
它和 PyTorch 怎么运行没有直接关系 。PyTorch 运行代码时,根本不会去调用你的
nvcc,它只会加载自己文件夹里自带的那些 CUDA 12.8 的库文件。
-
2. 这样会有问题吗?(显卡 MX230 是否支持)
结论:大概率能运行,但存在风险。
-
向下兼容性:NVIDIA 的驱动通常是向下兼容的。只要你的 Windows 宿主机驱动版本够高(你的截图显示是 556.12,这支持 CUDA 12.x),那么 PyTorch 2.8.0+cu128 就可以在你的显卡上跑。
-
潜在风险:你的显卡是 MX230(Pascal 架构),虽然能跑 CUDA 12,但如果 PyTorch 官方后续版本对旧架构的支持减弱,可能会出现性能问题或莫名其妙的错误。
3. 如果我非要安装 CUDA 11.8 版本的 PyTorch 怎么办?
如果你希望 PyTorch 内部的 CUDA 版本也严格匹配 11.8(这对于某些旧模型的稳定性更好),你需要在安装命令中强制指定 PyTorch 的版本号。
正确的命令应该是:
# 必须显式指定版本,否则 pip 会默认拉取最新的 12.8 版本
pip install torch==2.4.0+cu118 torchvision==0.19.0+cu118 torchaudio==2.4.0+cu118 --index-url https://download.pytorch.org/whl/cu1184. 总结:到底谁说了算?
-
当你运行
import torch; torch.version.cuda时,看到的是 PyTorch 真正使用的 CUDA 版本。 -
当你运行
nvcc -V时,看到的是 你系统开发环境的 CUDA 版本。
目前的状况:
你的 PyTorch 现在正带着一套 CUDA 12.8 的"私货"在运行。只要 torch.cuda.is_available() 返回 True 且测试运算没报错,你完全可以忽略这种版本不一致,正常写代码即可。
一句话建议:
如果你的代码能跑通,不用管它。这种"应用自带驱动库"的设计正是为了解决 Linux 下 CUDA 版本安装极其混乱的问题。