
目录
[一、进程创建:fork 函数的 "分身术"](#一、进程创建:fork 函数的 “分身术”)
[1.1 fork 函数初识:一次调用,两次返回的神奇操作](#1.1 fork 函数初识:一次调用,两次返回的神奇操作)
[1.2 fork 函数返回值:父子进程的 "身份标识"](#1.2 fork 函数返回值:父子进程的 “身份标识”)
[1.3 写时拷贝:高效的 "内存共享策略"](#1.3 写时拷贝:高效的 “内存共享策略”)
[1.4 fork 常规用法:父子进程的 "协作模式"](#1.4 fork 常规用法:父子进程的 “协作模式”)
[用法二:子进程调用 exec 函数,执行全新程序](#用法二:子进程调用 exec 函数,执行全新程序)
[1.5 fork 调用失败的原因:这些 "坑" 要避开](#1.5 fork 调用失败的原因:这些 “坑” 要避开)
原因二:实际用户的进程数超过了资源限制(RLIMIT_NPROC)
[二、进程终止:优雅离场的 "正确姿势"](#二、进程终止:优雅离场的 “正确姿势”)
[2.1 进程退出场景:三种常见 "结局"](#2.1 进程退出场景:三种常见 “结局”)
[2.2 进程常见退出方法:正常终止与异常终止](#2.2 进程常见退出方法:正常终止与异常终止)
[2.2.1 正常终止:主动离场的三种方式](#2.2.1 正常终止:主动离场的三种方式)
[方式一:从 main 函数返回(return)](#方式一:从 main 函数返回(return))
[方式二:调用 exit 函数](#方式二:调用 exit 函数)
[方式三:调用_exit 函数](#方式三:调用_exit 函数)
[2.2.2 异常终止:被动离场的常见情况](#2.2.2 异常终止:被动离场的常见情况)
[情况一:用户主动发送信号(如 Ctrl+C)](#情况一:用户主动发送信号(如 Ctrl+C))
[情况二:通过 kill 命令发送信号](#情况二:通过 kill 命令发送信号)
[2.2.3 退出码详解:进程的 "状态报告"](#2.2.3 退出码详解:进程的 “状态报告”)
在 Linux 操作系统的世界里,进程是资源分配与调度的基本单位,就像一个个忙碌的 工人,支撑着整个系统的高效运转。而进程的创建与终止,正是这些 "工人" 从诞生到完成使命离场的完整生命周期。其中,fork 函数是创建新进程的核心工具,exit、_exit 等函数则主导了进程的优雅退出。本文将带大家深入底层,详细拆解 Linux 进程创建与终止的每一个关键环节,让你彻底搞懂这背后的技术原理与实践技巧。下面就让我们正式开始吧!
一、进程创建:fork 函数的 "分身术"
1.1 fork 函数初识:一次调用,两次返回的神奇操作
在 Linux 中,要创建一个新进程,fork 函数是当之无愧的核心。它就像一台 "分身机器",能让一个已存在的进程(父进程)复制出一个全新的进程(子进程),两个进程拥有相同的代码段、数据段(初始状态),却能各自独立运行,开启不同的执行旅程。
首先,我们来看 fork 函数的基本用法。它的头文件和函数原型如下(bash 环境中调用需借助 C 语言编译执行,后续代码案例均提供完整可运行方案):
cpp
#include <unistd.h>
pid_t fork(void);光看原型可能觉得平平无奇,但 fork 函数有一个极具迷惑性的特点:一次调用,两次返回。这是什么意思呢?简单来说,父进程调用 fork 后,内核会完成一系列操作,最终父进程和子进程都会从 fork 函数返回,但返回值却截然不同:
- 子进程中,fork 返回 0;
- 父进程中,fork 返回子进程的 PID(进程 ID);
- 若调用失败,fork 返回 - 1。
为了让大家更直观地感受这个过程,我们来看一个完整的实战代码。先编写 C 语言代码文件 fork_demo.c:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid()); // 打印父进程PID
// 调用fork创建子进程
if ((pid = fork()) == -1)
{
perror("fork() failed");
exit(1);
}
// fork之后,父子进程都会执行下面的代码
printf("After: pid is %d, fork return %d\n", getpid(), pid);
sleep(1); // 防止进程过快退出,确保输出完整
return 0;
}然后在 bash 终端中编译并执行:
bash
# 编译代码
gcc fork_demo.c -o fork_demo
# 执行程序
./fork_demo执行结果如下:
Before: pid is 43676
After: pid is 43676, fork return 43677
After: pid is 43677, fork return 0从结果中可以看到,"Before" 只打印了一次,而 "After" 打印了两次。这是因为在 fork 调用之前,只有父进程在独立执行,所以 "Before" 语句仅执行一次;而 fork 调用之后,父进程和子进程同时存在,各自执行后续的代码,因此 "After" 语句被执行了两次。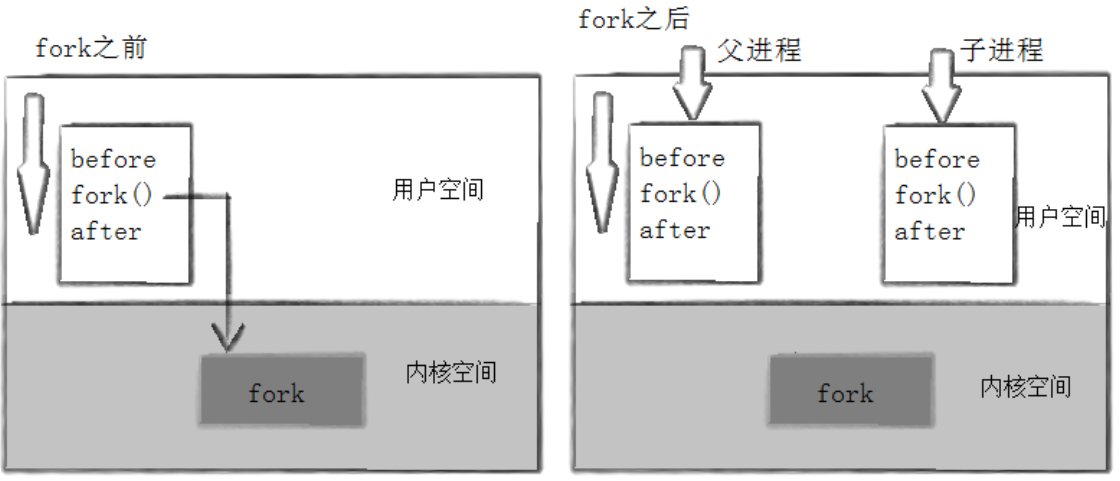
这里有两个关键问题需要解答:
为什么子进程没有打印 "Before"?因为 fork 函数是 "复制" 行为,而不是 "回溯" 行为。fork 只会复制调用 fork 之后的执行上下文,fork 之前父进程已经执行过的代码,子进程不会重新执行。就像分身术是在你当前状态下复制一个你,而不是让复制体回到你过去的某个时刻。
**为什么 fork 会有两次返回?**当父进程调用 fork 后,内核会执行以下四个核心步骤:
- 为子进程分配新的内存块和内核数据结构(如 PCB);
- 将父进程的部分数据结构内容拷贝到子进程(如页表、文件描述符表等);
- 将子进程添加到系统进程列表中,使其成为可调度的进程;
- 完成上述工作后,fork 函数返回,调度器开始调度父子进程。
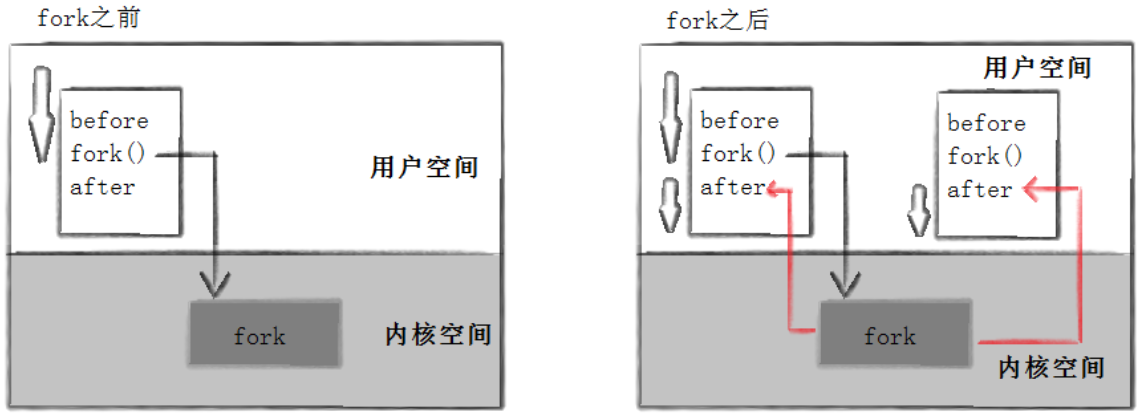
此时,父进程和子进程都处于就绪状态,调度器会根据调度算法选择其中一个先执行。无论是父进程还是子进程,都会从 fork 函数的返回点继续往下走,因此就出现了 "一次调用,两次返回" 的现象。
1.2 fork 函数返回值:父子进程的 "身份标识"
fork 函数的返回值设计非常巧妙,它就像给父子进程分配了不同的 "身份卡片",让它们能够清晰地识别自己的角色,从而执行不同的代码逻辑。
- 子进程返回 0:子进程是父进程的 "分身",它只需要知道自己是子进程即可,不需要知道其他子进程的信息(如果父进程创建了多个子进程)。返回 0 是一种简洁的标识方式,告诉子进程 "你是派生出来的新进程"。
- 父进程返回子进程 PID:父进程可能会创建多个子进程,它需要通过 PID 来唯一标识每个子进程,以便后续进行进程等待、信号发送等操作。PID 是系统分配给每个进程的唯一编号,就像身份证号一样,父进程通过这个编号就能精准管理对应的子进程。
利用这个返回值特性,我们可以让父子进程执行不同的代码段。例如,父进程负责监听端口,子进程负责处理客户端请求。实战代码如下(fork_diff_code.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程执行的代码
printf("我是子进程,PID:%d,父进程PID:%d\n", getpid(), getppid());
sleep(3); // 子进程模拟处理任务
printf("子进程任务处理完成,退出\n");
exit(0);
}
else
{
// 父进程执行的代码
printf("我是父进程,PID:%d,创建的子进程PID:%d\n", getpid(), pid);
sleep(5); // 父进程模拟等待其他请求
printf("父进程继续运行\n");
}
return 0;
}编译执行:
bash
gcc fork_diff_code.c -o fork_diff_code
./fork_diff_code执行结果:
我是父进程,PID:43678,创建的子进程PID:43679
我是子进程,PID:43679,父进程PID:43678
子进程任务处理完成,退出
父进程继续运行从结果可以看出,父子进程根据 fork 的返回值,成功执行了不同的代码逻辑,实现了 "分工协作"。
1.3 写时拷贝:高效的 "内存共享策略"
很多人可能会有疑问:fork 创建子进程时,会把父进程的代码段、数据段都拷贝一份,那如果父进程占用了大量内存,创建子进程岂不是会非常耗时且浪费内存?
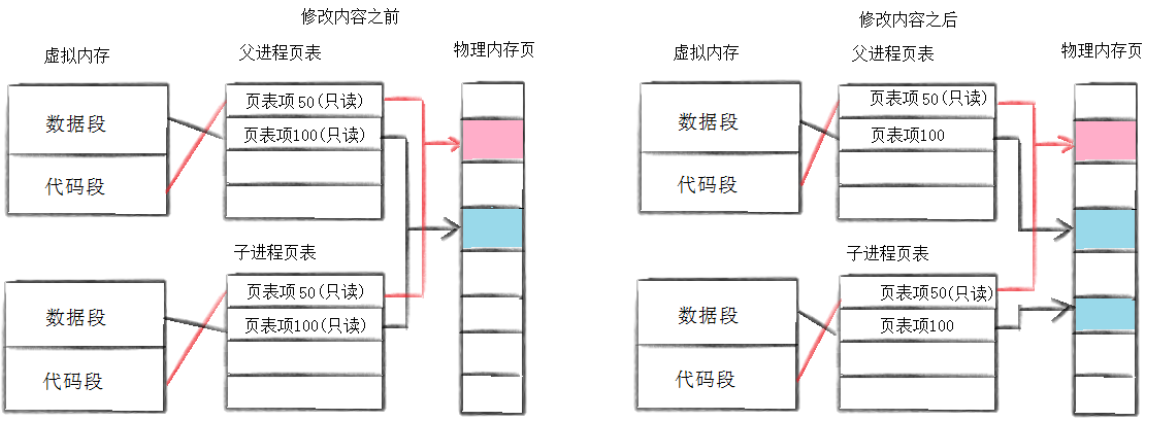
其实,Linux 采用了一种名为**"写时拷贝(Copy-On-Write, COW)"**的优化技术,完美解决了这个问题。写时拷贝的核心思想是:父子进程初始时共享所有内存资源(代码段、数据段、堆、栈等),但这些资源被标记为 "只读"。只有当其中一方试图修改内存数据时,内核才会为修改方分配新的内存空间,拷贝被修改的数据,实现真正的内存分离。
写时拷贝的工作流程:
- fork 创建子进程后,父子进程的虚拟内存页表都指向相同的物理内存页,且这些物理内存页被设置为只读;
- 当父进程或子进程尝试修改某块内存数据时,会触发 CPU 的 "写保护" 异常;
- 内核接收到异常后,会为触发修改的进程分配一块新的物理内存页,将原物理内存页的数据拷贝到新页中;
- 更新该进程的虚拟内存页表,使其指向新的物理内存页,并取消该页的只读限制;
- 之后,该进程对这块内存的修改就只会作用于新的物理内存页,不会影响另一方的内存数据。
写时拷贝技术带来了两个核心优势:
- 提高创建进程的效率:创建子进程时不需要拷贝大量内存数据,只需要复制父进程的 PCB、页表等少量内核数据结构,因此 fork 函数的执行速度非常快;
- 节省系统内存资源:只有当父子进程需要修改数据时才会分配新的内存,避免了不必要的内存浪费。例如,父进程创建子进程后,子进程只是执行读取数据的操作,那么父子进程就可以一直共享内存,无需额外分配。
我们可以通过一个代码案例来验证写时拷贝的效果(cow_demo.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 10; 全局变量,初始时父子进程共享
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程
printf("子进程:初始g_val = %d,地址 = %p\n", g_val, &g_val);
g_val = 20; // 子进程修改全局变量,触发写时拷贝
printf("子进程:修改后g_val = %d,地址 = %p\n", g_val, &g_val);
}
else
{
// 父进程
sleep(1); // 等待子进程修改完成
printf("父进程:g_val = %d,地址 = %p\n", g_val, &g_val);
}
return 0;
}编译执行:
bash
gcc cow_demo.c -o cow_demo
./cow_demo执行结果:
子进程:初始g_val = 10,地址 = 0x560b8b7a204c
子进程:修改后g_val = 20,地址 = 0x560b8b7a204c
父进程:g_val = 10,地址 = 0x560b8b7a204c从结果可以看到,父子进程中 g_val的虚拟地址是相同的,但子进程修改 g_val后,父进程的 g_val 仍然是初始值 10。这正是写时拷贝的作用:虚拟地址相同,但对应的物理内存页已经分离,子进程的修改不会影响父进程。
1.4 fork 常规用法:父子进程的 "协作模式"
fork 函数的应用场景非常广泛,核心可以归纳为两种常见用法:
用法一:父进程复制自己,父子进程执行不同代码段
这种用法主要用于 "并发处理" 场景。父进程负责监听某个任务(如网络连接请求),当有新任务到来时,创建子进程来专门处理该任务,父进程则继续监听下一个任务。这种方式可以实现多个任务的并发处理,提高系统的吞吐量。
典型案例:网络服务器的并发处理。父进程绑定端口并监听客户端连接,每当有一个客户端连接成功,就 fork 一个子进程来处理与该客户端的通信,父进程则回到监听状态,等待下一个客户端连接。
实战代码(server_fork_demo.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#define PORT 8080
#define BACKLOG 5
void handle_client(int client_fd)
{
// 子进程处理客户端请求
char buf[1024] = {0};
ssize_t n = read(client_fd, buf, sizeof(buf));
if (n > 0)
{
printf("子进程(PID:%d)收到客户端数据:%s\n", getpid(), buf);
write(client_fd, "收到你的消息啦!", strlen("收到你的消息啦!"));
}
close(client_fd);
exit(0);
}
int main(void)
{
// 创建套接字
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (listen_fd == -1)
{
perror("socket failed");
exit(1);
}
// 绑定端口
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(PORT);
addr.sin_addr.s_addr = INADDR_ANY;
if (bind(listen_fd, (struct sockaddr*)&addr, sizeof(addr)) == -1)
{
perror("bind failed");
exit(1);
}
// 开始监听
if (listen(listen_fd, BACKLOG) == -1)
{
perror("listen failed");
exit(1);
}
printf("父进程(PID:%d)监听端口 %d...\n", getpid(), PORT);
while (1)
{
// 接受客户端连接
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int client_fd = accept(listen_fd, (struct sockaddr*)&client_addr, &client_len);
if (client_fd == -1)
{
perror("accept failed");
continue;
}
// 创建子进程处理客户端请求
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
close(client_fd);
continue;
}
else if (pid == 0)
{
close(listen_fd); // 子进程不需要监听,关闭监听套接字
handle_client(client_fd);
}
else
{
close(client_fd); // 父进程不需要与客户端通信,关闭客户端套接字
}
}
close(listen_fd);
return 0;
}编译执行:
bash
gcc server_fork_demo.c -o server_fork
./server_fork此时,服务器会监听 8080 端口。可以打开多个终端,使用 telnet或 nc命令连接服务器并发送数据,例如:
bash
nc 127.0.0.1 8080
hello server服务器会输出类似以下内容:
父进程(PID:43680)监听端口 8080...
子进程(PID:43681)收到客户端数据:hello server
子进程(PID:43682)收到客户端数据:hi there可以看到,每个客户端连接都会触发一个子进程来处理,实现了并发处理的效果。
用法二:子进程调用 exec 函数,执行全新程序
fork 创建的子进程与父进程拥有相同的代码段,但很多时候我们希望子进程执行一个完全不同的程序(如执行 ls、ps 等系统命令)。这时就需要结合 exec 函数族,在子进程中替换掉原来的代码段和数据段,执行全新的程序。
这种用法是 shell 命令执行的核心原理:shell 进程(父进程)fork 一个子进程,子进程调用 exec 函数执行用户输入的命令(如 ls),父进程则等待子进程执行完成。
实战代码(exec_fork_demo.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程调用execvp执行ls命令
printf("子进程(PID:%d)执行ls命令...\n", getpid());
char *const argv[] = {"ls", "-l", NULL}; // 命令参数,以NULL结尾
execvp("ls", argv); // 执行ls -l命令
perror("execvp failed"); // 如果execvp返回,说明执行失败
exit(1);
}
else
{
// 父进程等待子进程执行完成
wait(NULL);
printf("父进程(PID:%d):子进程执行完成\n", getpid());
}
return 0;
}编译执行:
bash
gcc exec_fork_demo.c -o exec_fork
./exec_fork执行结果:
子进程(PID:43683)执行ls命令...
总用量 48
-rwxr-xr-x 1 root root 8768 6月 10 15:30 cow_demo
-rwxr-xr-x 1 root root 8800 6月 10 15:35 exec_fork
-rw-r--r-- 1 root root 532 6月 10 15:34 exec_fork_demo.c
-rwxr-xr-x 1 root root 8768 6月 10 14:50 fork_demo
-rw-r--r-- 1 root root 412 6月 10 14:49 fork_demo.c
-rwxr-xr-x 1 root root 8800 6月 10 15:00 fork_diff_code
-rw-r--r-- 1 root root 628 6月 10 14:59 fork_diff_code.c
-rwxr-xr-x 1 root root 9088 6月 10 15:20 server_fork
-rw-r--r-- 1 root root 1456 6月 10 15:19 server_fork_demo.c
父进程(PID:43682):子进程执行完成从结果可以看到,子进程成功执行了ls -l命令,这正是 fork+exec 的经典用法。
1.5 fork 调用失败的原因:这些 "坑" 要避开
虽然 fork 函数很常用,但并不是每次调用都能成功。fork 调用失败的原因主要有以下两种:
原因一:系统中进程数量过多,达到了内核的最大进程数限制
Linux 系统对进程数量有全局限制,当系统中所有进程的总数达到这个限制时,新的 fork 调用就会失败。可以通过以下 bash 命令查看系统的最大进程数限制:
bash
cat /proc/sys/kernel/pid_max默认情况下,很多系统的 pid_max值为 32768,即系统中最多可以有 32768 个进程(PID 从 1 到 32768)。当进程数达到这个上限时,fork 就会返回 - 1。
原因二:实际用户的进程数超过了资源限制(RLIMIT_NPROC)
除了系统全局限制,Linux 还为每个用户设置了最大进程数限制。当某个用户创建的进程数超过这个限制时,该用户后续的 fork 调用就会失败。
可以通过以下 bash 命令查看当前用户的进程数限制:
bash
ulimit -u例如,输出结果为 1024,表示当前用户最多可以创建 1024 个进程。如果该用户已经创建了 1024 个进程,再调用 fork 就会失败。
此外,fork 失败还可能与内存不足有关。虽然写时拷贝减少了内存占用,但创建子进程仍需要分配 PCB、页表等内核数据结构,若系统内存严重不足,也可能导致 fork 失败。
当 fork 调用失败时,我们可以通过 perror函数打印错误信息,以便定位问题。例如:
cpp
if ((pid = fork()) == -1)
{
perror("fork failed"); // 打印错误原因,如"fork failed: Resource temporarily unavailable"
exit(1);
}二、进程终止:优雅离场的 "正确姿势"
进程创建后,总会有结束的时候。进程终止的本质是释放系统资源,包括进程占用的内存、文件描述符、PCB 等内核数据结构,以及代码和数据段等用户空间资源。进程终止的场景和方式有多种,下面我们详细讲解。
2.1 进程退出场景:三种常见 "结局"
进程的退出场景可以分为三大类,每一类对应不同的业务逻辑和处理方式:
场景一:代码运行完毕,结果正确
这是最理想的退出场景。进程完成了预定的任务,没有出现任何错误,退出码为 0(退出码的含义后续会详细讲解)。例如,执行 ls 命令成功列出目录内容后,ls 进程就会正常退出,退出码为 0。
场景二:代码运行完毕,但结果不正确
这种场景下,进程虽然执行完了所有代码,但由于输入错误、逻辑错误等原因,没有得到预期的结果。此时进程会返回一个非 0 的退出码,用于指示错误类型。例如,编写一个计算两数之和的程序,若输入的不是数字,程序执行完毕后会返回非 0 退出码,表示计算失败。
场景三:代码异常终止,未运行完毕
这种场景是进程在执行过程中遇到了意外情况,导致程序无法继续运行,被迫终止。常见的原因包括:
- 收到致命信号(如 Ctrl+C 发送的 SIGINT 信号、kill -9 发送的 SIGKILL 信号);
- 程序运行时出现严重错误(如除零错误、空指针引用、数组越界等),触发内核发送信号终止进程。
例如,在终端中执行一个无限循环的程序,按下 Ctrl+C 后,程序会收到 SIGINT 信号,异常终止。
2.2 进程常见退出方法:正常终止与异常终止
进程的退出方法分为两大类:正常终止和异常终止。正常终止是进程主动结束自己的生命周期,异常终止则是进程被动结束。
2.2.1 正常终止:主动离场的三种方式
正常终止的进程会返回一个退出码(0 表示成功,非 0 表示失败) ,父进程可以通过 wait系列函数获取这个退出码,了解子进程的执行结果。正常终止的方式有三种:
方式一:从 main 函数返回(return)
这是最常见的退出方式。C 语言程序的入口是 main 函数,当 main 函数执行到 return 语句时,程序会正常终止,return 的返回值就是进程的退出码。
实际上,执行 return n 等同于执行 exit (n)。因为调用 main 函数的运行时库会将 main 的返回值作为参数传递给 exit函数,完成进程的终止流程。
实战代码(return_exit_demo.c):
cpp
#include <stdio.h>
// 计算两数之和,若输入非数字则返回错误
int main(int argc, char *argv[])
{
if (argc != 3)
{
printf("用法:%s <数字1> <数字2>\n", argv[0]);
return 1; // 参数错误,返回退出码1
}
int a = atoi(argv[1]);
int b = atoi(argv[2]);
// 简单检查输入是否为有效数字(atoi无法区分0和非数字,这里仅作演示)
if ((a == 0 && argv[1][0] != '0') || (b == 0 && argv[2][0] != '0'))
{
printf("错误:输入必须是数字\n");
return 2; // 输入错误,返回退出码2
}
printf("%d + %d = %d\n", a, b, a + b);
return 0; // 执行成功,返回退出码0
}编译执行:
bash
gcc return_exit_demo.c -o return_exit
# 测试1:参数正确
./return_exit 10 20
echo "退出码:$?" # 打印上一个进程的退出码
# 测试2:参数个数错误
./return_exit 10
echo "退出码:$?"
# 测试3:输入非数字
./return_exit 10 abc
echo "退出码:$?"执行结果:
10 + 20 = 30
退出码:0
用法:./return_exit <数字1> <数字2>
退出码:1
错误:输入必须是数字
退出码:2从结果可以看到,不同的返回值对应不同的退出码,父进程(这里是 shell)可以通过**$?**变量获取该退出码,判断程序的执行情况。
方式二:调用 exit 函数
exit函数是标准库函数(头文件 <stdlib.h>),用于终止进程。它的函数原型如下:
cpp
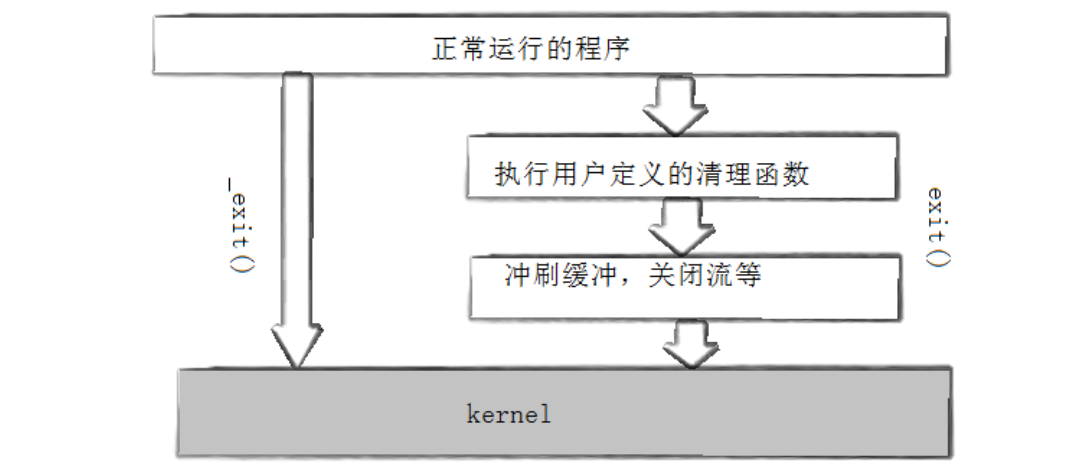
void exit(int status);其中,status是进程的退出码,低 8 位有效。exit 函数的执行流程如下:
- 执行用户通过 atexit或 on_exit函数注册的清理函数(如果有);
- 关闭所有打开的文件流,将缓冲区中的数据刷新到文件中;
- 调用内核的**_exit**函数,完成进程终止,释放系统资源。
实战代码(exit_demo.c):
cpp
#include <stdio.h>
#include <stdlib.h>
// 注册清理函数,exit会自动执行
void clean_up()
{
printf("执行清理函数:释放临时资源\n");
}
int main(void)
{
// 注册清理函数(可以注册多个,执行顺序与注册顺序相反)
atexit(clean_up);
printf("程序开始执行\n");
// 模拟业务逻辑
int flag = 1;
if (flag)
{
printf("业务逻辑执行完成,准备退出\n");
exit(0); // 正常退出,退出码0
}
// 以下代码不会执行
printf("这段代码不会被执行\n");
return 1;
}编译执行:
bash
gcc exit_demo.c -o exit_demo
./exit_demo
echo "退出码:$?"执行结果:
程序开始执行
业务逻辑执行完成,准备退出
执行清理函数:释放临时资源
退出码:0从结果可以看到,exit函数调用后,程序会立即终止,后续的代码不会执行,并且会自动执行注册的清理函数。
方式三:调用_exit 函数
_exit函数是系统调用 (头文件 <unistd.h>),与 exit 函数的区别在于:_exit 函数会直接终止进程,释放系统资源,不会执行清理函数,也不会刷新文件流缓冲区。
它的函数原型如下:
cpp
void _exit(int status);其中,status 是退出码,同样低 8 位有效。如果 status 为 - 1,由于低 8 位有效,实际退出码会是 255(因为 - 1 的补码低 8 位是 0xFF,即 255)。
实战代码(_exit_demo.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void clean_up()
{
printf("执行清理函数:释放临时资源\n");
}
int main(void)
{
atexit(clean_up); // 注册清理函数
printf("使用_exit退出:"); // 没有换行符,缓冲区不会自动刷新
_exit(0); // 直接退出,不执行清理函数,不刷新缓冲区
printf("这段代码不会被执行\n");
return 1;
}编译执行:
bash
gcc _exit_demo.c -o _exit_demo
./_exit_demo
echo "退出码:$?"执行结果:
退出码:0从结果可以看到,printf的内容没有输出(因为缓冲区未刷新),注册的清理函数也没有执行,这正是**_exit**函数与 exit函数的核心区别。
为了更清晰地对比 exit 和_exit 的区别,我们再看一个案例(exit_vs__exit.c):
cpp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
// 案例1:exit会刷新缓冲区
printf("exit函数:");
exit(0);
// 案例2:_exit不会刷新缓冲区(将上面的exit注释掉,启用下面的代码)
// printf("_exit函数:");
// _exit(0);
}编译执行案例 1(exit):
bash
gcc exit_vs__exit.c -o exit_vs__exit
./exit_vs__exit结果:
exit函数:编译执行案例 2(_exit):
bash
./exit_vs__exit结果:
(无任何输出)这是因为 printf的输出会先存入用户空间的缓冲区,exit函数会在终止进程前刷新缓冲区,将数据输出到终端;而**_exit**函数直接终止进程,缓冲区的数据不会被刷新,因此看不到输出。
2.2.2 异常终止:被动离场的常见情况
异常终止是进程在执行过程中被动结束,通常是由于收到了无法处理的信号。常见的异常终止情况有:
情况一:用户主动发送信号(如 Ctrl+C)
在终端中执行程序时,按下 Ctrl+C 会向进程发送 SIGINT 信号(信号编号 2),进程收到该信号后会立即终止。例如:
bash
# 执行一个无限循环的程序
while :; do echo "运行中..."; sleep 1; done按下 Ctrl+C 后,程序会终止,此时通过 $? 查看退出码:
bash
echo $?结果为 130,这是因为信号终止的退出码为128 + 信号编号(128+2=130)。
情况二:通过 kill 命令发送信号
可以使用 kill命令向指定进程发送信号,强制其终止。例如,先执行一个后台进程:
bash
while :; do echo "运行中..."; sleep 1; done &查看该进程的 PID:
bash
ps aux | grep "while"假设 PID 为 43690,使用 kill -9 发送 SIGKILL 信号(信号编号 9,强制终止):
bash
kill -9 43690此时进程会立即终止,查看退出码(需要通过父进程等待获取,这里通过脚本演示):
bash
#!/bin/bash
# kill_demo.sh
./infinite_loop & # 假设infinite_loop是无限循环程序
pid=$! # 获取后台进程的PID
sleep 3
kill -9 $pid # 发送SIGKILL信号
wait $pid # 等待进程终止,获取退出码
echo "进程$pid的退出码:$?"执行脚本:
bash
chmod +x kill_demo.sh
./kill_demo.sh结果:
进程43690的退出码:137137=128+9,对应 SIGKILL 信号的终止退出码。
情况三:程序运行时触发致命错误
程序运行时出现严重错误(如除零错误、空指针引用),会触发内核发送信号终止进程。例如,以下代码(fatal_error_demo.c)会导致除零错误:
cpp
#include <stdio.h>
int main(void)
{
int a = 10;
int b = 0;
int c = a / b; // 除零错误,触发SIGFPE信号(信号编号8)
printf("c = %d\n", c);
return 0;
}编译执行:
bash
gcc fatal_error_demo.c -o fatal_error
./fatal_error
echo "退出码:$?"执行结果:
Floating point exception (core dumped)
退出码:136136=128+8,对应 SIGFPE 信号的退出码,进程因致命错误异常终止。
2.2.3 退出码详解:进程的 "状态报告"
退出码是进程终止时返回给父进程的 "状态报告",用于指示进程的执行结果。退出码的取值范围是 0-255,其中:
- 0:表示进程正常执行,结果正确;
- 1-255:表示进程执行异常或结果不正确,不同的数值对应不同的错误类型。
Linux 系统中常见的退出码及其含义如下表所示:
| 退出码 | 含义解释 | 典型场景 |
|---|---|---|
| 0 | 命令成功执行 | ls、pwd 等命令执行成功 |
| 1 | 通用错误 | 除零错误、权限不足(非 root 用户执行 yum) |
| 2 | 命令或参数使用不当 | 传递错误数量的参数 |
| 126 | 权限被拒绝或无法执行 | 对非可执行文件执行./ 操作 |
| 127 | 未找到命令或 PATH 错误 | 输入不存在的命令(如 lss) |
| 128+n | 被信号 n 终止 | Ctrl+C(n=2,退出码 130)、kill -9(n=9,退出码 137) |
| 130 | 通过 Ctrl+C 或 SIGINT 终止 | 终端中按下 Ctrl+C 终止进程 |
| 143 | 通过 SIGTERM 终止(默认终止信号) | kill 命令未指定信号(默认发送 SIGTERM,n=15,128+15=143) |
| 255 | 退出码超出 0-255 范围 | _exit (-1)(低 8 位为 255) |
在 bash 环境中,可以通过**$?变量获取上一个进程的退出码**。例如:
bash
# 执行成功的命令
ls /home
echo "退出码:$?" # 输出0
# 执行失败的命令
ls /nonexistent_dir
echo "退出码:$?" # 输出2
# 执行不存在的命令
lss
echo "退出码:$?" # 输出127此外,还可以使用 strerror函数在 C 程序中获取退出码对应的描述信息。实战代码(strerror_demo.c):
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main(void)
{
int exit_codes[] = {0, 1, 2, 126, 127, 130, 143, 255};
int n = sizeof(exit_codes) / sizeof(exit_codes[0]);
for (int i = 0; i < n; i++)
{
int code = exit_codes[i];
printf("退出码 %d:%s\n", code, strerror(code));
}
return 0;
}编译执行:
bash
gcc strerror_demo.c -o strerror_demo
./strerror_demo执行结果:
退出码 0:Success
退出码 1:Operation not permitted
退出码 2:No such file or directory
退出码 126:Permission denied
退出码 127:No such file or directory
退出码 130:Interrupted system call
退出码 143:Connection reset by peer
退出码 255:Unknown error 255通过退出码和 strerror函数,我们可以快速定位进程执行失败的原因。
总结
掌握进程创建与终止的底层原理,不仅能帮助我们编写更高效、更健壮的 Linux 程序,还能深入理解 shell、服务器等核心应用的工作机制。希望本文的详细讲解和实战案例能让你对这部分知识有更清晰的认识,在实际开发中避开 "坑",写出更优秀的代码。
如果你在学习过程中遇到了问题,或者有其他想要深入了解的知识点(如进程等待、信号处理、exec 函数族详解等),欢迎在评论区留言讨论!