核心概念回顾
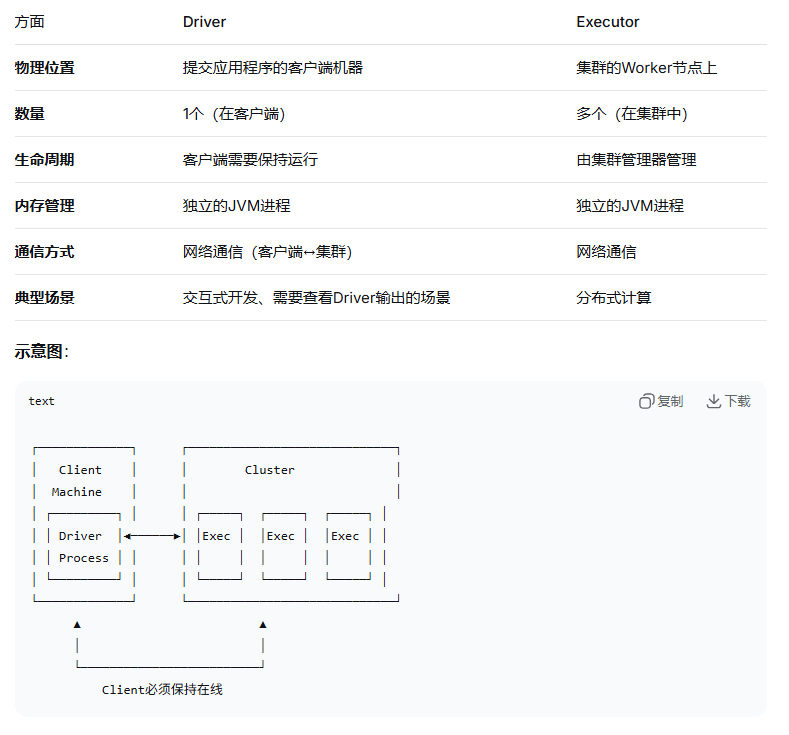
Driver(驱动程序):
- Spark 应用程序的主控制器
- 运行用户的 main() 函数
- 创建 SparkContext,协调任务调度
Executor(执行器):
- 分布式工作节点
- 执行具体的计算任务
- 存储数据分区和缓存
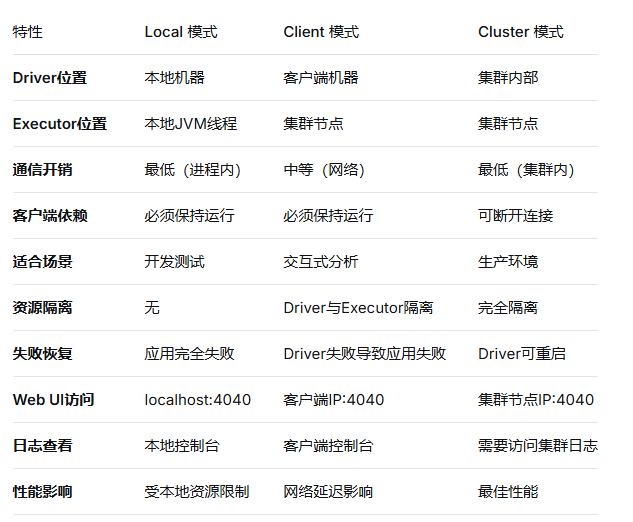
三种模式的详细对比
- Local 模式(本地模式)

bash
# 本地模式运行
spark-submit --master local[4] \
--driver-memory 4g \
--class com.example.MyApp \
my-app.jar
# 实际上是1个进程,4个执行器线程- Client 模式(客户端模式)
bash
# 客户端模式运行
spark-submit --master yarn \
--deploy-mode client \
--driver-memory 4g \
--executor-memory 8g \
--num-executors 10 \
--class com.example.MyApp \
my-app.jar
# Driver在客户端,10个Executor在YARN集群中- Cluster 模式(集群模式)

bash
# 集群模式运行
spark-submit --master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 8g \
--num-executors 20 \
--class com.example.MyApp \
my-app.jar
# Driver和Executor都在YARN集群中详细对比表格
具体代码示例对比
bash
示例1:Local模式(开发测试)
# 本地开发环境
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("LocalDev") \
.master("local[*]") \ # 本地模式
.config("spark.driver.memory", "2g") \
.getOrCreate()
# Driver和Executor都在本地进程
# 可以直接在IDE中调试
bash
示例2:Client模式(数据科学工作)
# 数据科学家交互式分析
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("DataAnalysis") \
.master("yarn") \ # YARN集群
.config("spark.submit.deployMode", "client") \
.config("spark.driver.memory", "4g") \
.config("spark.executor.memory", "8g") \
.getOrCreate()
# Driver在本地,可以看到实时输出
# Executor在集群,处理大数据
df = spark.sql("SELECT * FROM large_table")
df.show() # 结果直接显示在本地
bash
示例3:Cluster模式(生产作业)
# 生产环境提交作业
#!/bin/bash
spark-submit \
--master yarn \
--deploy-mode cluster \
--name "DailyETLJob" \
--driver-memory 4g \
--executor-memory 16g \
--num-executors 50 \
--conf spark.dynamicAllocation.enabled=true \
--class com.company.ETLJob \
/jobs/etl-job.jar \
--input hdfs:///data/raw \
--output hdfs:///data/processed
# 提交后客户端可以断开
# Driver和Executor都在集群运行