1.准备的环境
jdk、zookeeper、hadoop集群。
当前服务器:三个服务器节点(hadoop101/hadoop102/hadoop103)
2.将安装软件上传到 hadoop101服务器/opt目录下
例如:spark-3.5.0-bin-hadoop3-scala2.13.tgz
3.将spark的安装目录解压到 /usr/local/software/
tar -zxvf /opt/spark-3.5.0-bin-hadoop3-scala2.13.tgz -C /usr/local/software4.修改文件名
cd /usr/local/software/
mv spark-3.5.0-bin-hadoop3-scala2.13 spark5.spark环境变量的配置
export SPARK_HOME=/usr/local/software/spark
export SPARKPYTHON=/usr/local/software/spark/python
:$SPARK_HOME/bin:$SPARK_HOME/sbin:$SPARKPYTHON6.环境变量的生效
source /etc/profile7.测试
执行:spark-shell

8.安装python插件
三台服务器都需要进行安装
yum install -y python39.修改spark的配置信息
将 spark-env.sh.template 模板复制为:spark-env.sh
cd /usr/local/software/spark/conf
cp spark-env.sh.template spark-env.sh修改:spark-env.sh 文件
需要在spark-env.sh 中添加配置环境配置信息(Java/hadoop/zookeeper)
将以下内容,直接添加到 spark-env.sh 文件末尾即可
export JAVA_HOME=/usr/local/software/jdk
export HADOOP_HOME=/usr/local/software/hadoop
export HADOOP_CONF_DIR=/usr/local/software/hadoop/etc/hadoop
export JAVA_LIBRAY_PATH=/usr/local/software/hadoop/lib/native
export SPARK_DIST_CLASSPATH=$(/usr/local/software/hadoop/bin/hadoop classpath)
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop101:2181,hadoop102:2181,hadoop103:2181
-Dspark.deploy.zookeeper.dir=/spark"
export SPARK_WORKER_MEMORY=8g
export SPARK_WORKER_CORE=8
export SPARK_MASTER_WEBUI_PORT=663310.修改集群节点的信息
将 workers.template 文件复制出来一个 workers
cd /usr/local/software/spark/conf
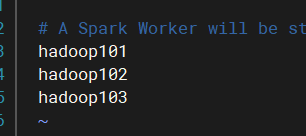
cp workers.template workers修改workers内容,将三个服务器的名称添加进去
如:hadoop101、hadoop102、hadoop103
11.配置历史日志
将spark-default.conf.template 复制为:spark-default.conf
cd /usr/local/software/spark/conf
cp spark-defaults.conf.template spark-defaults.conf修改 spark-default.conf 文件的内容
将以下内容添加到 spark-default.conf 文件的末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://laoma/spark-log需要在 hdfs中创建 /spark-log 目录
hdfs dfs -mkdir /spark-log
12.spark环境配置文件的修改
将以下内容添加到 spark-env.sh 文件的末尾
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://laoma/spark-log"13.修改spark启动文件的名称
spark/sbin 中的启动文件名与hadoop的启动文件名相同,因此进行修改.
mv start-all.sh start-spark.sh
mv stop-all.sh stop-spark.sh14.将spark的文件及环境变量的配置信息传递到其它的服务器上
scp -r /usr/local/software/spark root@hadoop102:/usr/local/software
scp -r /usr/local/software/spark root@hadoop103:/usr/local/software
scp -r /etc/profile.d/my_env.sh root@hadoop102:/etc/profile.d/
scp -r /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/15.hadoop102/hadoop103 环境生效
source /etc/profile16.启动spark服务器
首先:启动zookeeper、hadoop集群
在第一台服务器上,例如 hadoop101 上,启动spark,如下
start-spark.sh
start-history-server.sh查看进程
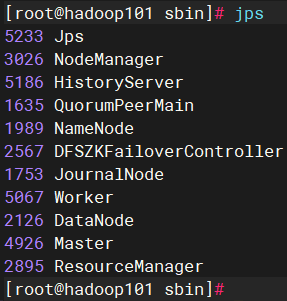
1)hadoop101 服务器上
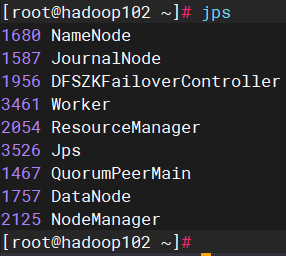
2)hadoop102服务器上
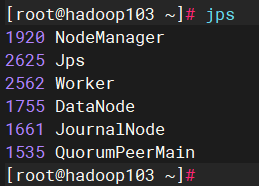
3)hadoop103服务器上
17.访问webui 界面
如下:
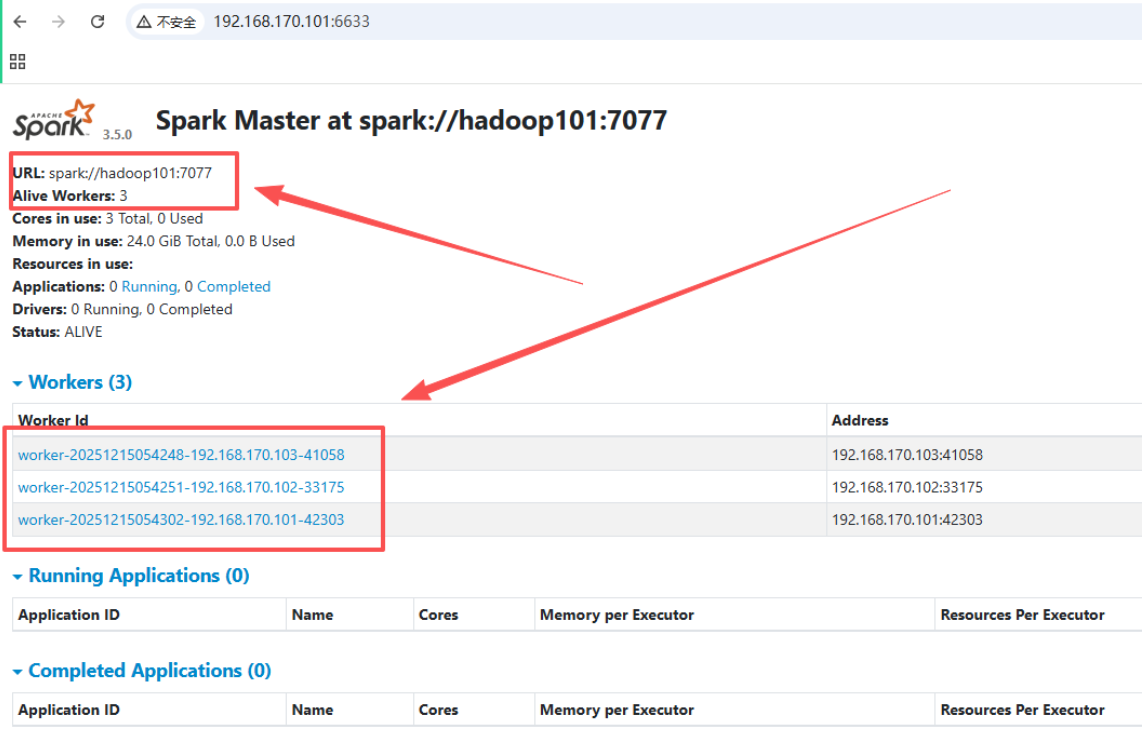
18.服务器关闭
先关闭 spark历史服务,关闭spark服务,hadoop集群,zookeeper
恭喜您,到此安装成功。