一、概述
Dinky是一个开箱即用的一站式实时计算平台以 Apache Flink 为基础,连接 OLAP 和数据湖等众多框架致力于流批一体和湖仓一体的建设与实践。本文以此为FlinkSQL可视化工具。
Flink SQL使得使用标准 SQL 开发流式应用变得简单,免去代码开发。
Flink CDC 本文使用 MySQL CDC 连接器 允许从 MySQL 数据库读取快照数据和增量数据。
环境及主要软件版本说明
- kafka_2.12-3.4.0.tgz
- flink-1.14.6-bin-scala_2.12.tgz
- flink-sql-connector-mysql-cdc-2.3.0.jar
- flink-sql-connector-elasticsearch7_2.12-1.14.6.jar
- flink-sql-connector-kafka_2.12-1.14.6.jar
- dlink-release-0.7.3.tar.gz
- Elasticsearch7.x
- java8
- MySQL5.7.17
- kafka-map kafka可视化工具(最新版需要jdk17环境,低版本也需要jdk11)
二、软件安装部署
本文全部采用单机最简环境。
1.Flink
tar -xzf flink-1.14.6-bin-scala_2.12.tgz
cd flink-1.14.6 && ls -l
### 修改配置 flink-1.14.6/conf/flink-conf.yaml,修改成本机的IP、位置
jobmanager.rpc.address: 192.168.xxx.xxx
taskmanager.host: 192.168.xxx.xxx
jobmanager.memory.process.size: 2048m
taskmanager.memory.process.size: 2048m
taskmanager.numberOfTaskSlots: 10
rest.port: 8888
rest.address: 0.0.0.0
web.tmpdir: /home/soft/flink_/flink-1.14.6/tmp
akka.ask.timeout: 600s
### 将flink-sql-connector-kafka_2.12-1.14.6.jar、flink-sql-connector-elasticsearch7_2.12-1.14.6.jar、
### flink-sql-connector-mysql-cdc-2.3.0.jar、放到flink-1.14.6/lib/ 下
### 启动
./启动成功后,即可访问Flink UI 可视化界面 http://192.168.xxx.xxx:8888/
2.Kafka
tar -xzf kafka_2.12-3.4.0.tgz
cd kafka_2.12-3.4.0
bin/ random-uuid > uuid
vi config/kraft/server.properties
controller.quorum.voters=1@192.168.XXX.XXX:9093
advertised.listeners=PLAINTEXT://192.168.XXX.XXX:9092
log.dirs=/home/soft/kafka_2.12-3.4.0/kraft-combined-logs
### 使用前面生成的uuid格式化Kafka日志目录
bin/ format -t `cat uuid` -c config/kraft/server.properties
Formatting /home/soft/kafka_2.12-3.4.0/kraft-combined-logs with metadata.version 3.4-IV0.
### Start the Kafka Server
bin/ -daemon config/kraft/server.properties
### Kafka 服务器成功启动后,您将拥有一个正在运行并可以使用的基本 Kafka 环境。
jps -l
14085 kafka.Kafka
#### 启动命令说明###############################################################
### 1、前台启动命令:
### bin/ config/server.properties
### 描述:
### 此种方式是窗口运行。一旦窗口关闭或者执行了CTR+C,那么kafka进程就被kill了,kafka服务端就被关闭了
### 2、后台启动命令:
### (1) nohup bin/ config/server.properties 2>&1 &
### (2)bin/ -daemon config/server.properties3.Dinky
部署参考:http://www.dlink.top/docs/next/deploy_guide/build
-
数据库初始化
#登录mysql mysql -uroot -p123456 #创建数据库 mysql> create database dinky; #授权 mysql> grant all privileges on dinky.* to 'dinky'@'%' identified by 'dinky@123' with grant option; mysql> flush privileges; #此处用 dinky 用户登录 mysql -h fdw1 -udinky -pdinky@123 mysql> use dinky; # sql文件在下载的压缩包中获取即可 mysql> source /home/soft/dinky/sql/dinky.sql -
Dinky部署
tar -zxvf dlink-release-0.7.3.tar.gz
mv dlink-release-0.7.3.tar.gz dinky
#切换目录,修改数据库配置及端口信息
cd /home/soft/dinky/config/
vi application.yml-------------------------------------------------------------------------------
spring:
datasource:
url: jdbc:mysql://{MYSQL_ADDR:192.168.XXX.XXX:3306}/{MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTime
zone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: {MYSQL_USERNAME:dinky} password: {MYSQL_PASSWORD:dinky@123}
server:
port: 8899-------------------------------------------------------------------------------
加载依赖Dinky 需要具备自身的 Flink 环境,该 Flink 环境的实现需要用户自己在 Dinky 根目录下
plugins/flink${FLINK_VERSION} 文件夹并上传相关的 Flink 依赖,如 flink-dist, flink-table 等
cp ${FLINK_HOME}/lib/flink-*.jar /home/soft/dinky/plugins/flink1.14/包含如下的jar
flink-csv-1.14.6.jar
flink-dist_2.12-1.14.6.jar
flink-json-1.14.6.jar
flink-shaded-zookeeper-3.4.14.jar
flink-sql-connector-elasticsearch7_2.12-1.14.6.jar
flink-sql-connector-kafka_2.12-1.14.6.jar
flink-sql-connector-mysql-cdc-2.3.0.jar完成后启动
sh auto.sh start 1.14
启动完成后访问 http://192.168.XXX.XXX:8899/ 通过admin/admin即可登录进系统进行可视化操作。
三、任务创建提交
场景说明:目前 MySQL 中有四张表,t1、t2、t3、t4。需要将 t1、t2 关联查询后结果同步到 Elasticsearch 索引 search01_index,t3、t4 关联查询后结果也同步到Elasticsearch索引 search01_index。Elasticsearch 索引信息是通过Spring Elasticsearch Data 项目启动时自动生成好了。只需要将数据同步即可。另外推送 Kafka 供给其他源处理。
1. 通过 Flink 自带 方式
Flink SQL和数据库字段类型对照说明:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/jdbc/#data-type-mapping
MySQL 同步到 Elasticsearch
### 进入flink/bin 目录下,通过 ./ 命令启动sql客户端工具
Flink SQL> SET execution.checkpointing.interval = 3s;
### source 1
Flink SQL> CREATE TABLE IF NOT EXISTS test1 (
id STRING,
name STRING,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test1的schame',
'table-name' = 'test1'
);
### source 2
Flink SQL> CREATE TABLE IF NOT EXISTS test2 (
id STRING,
doc_id STRING,
event_detail STRING,
country STRING,
`time` STRING,
entity_type STRING,
entity_name STRING,
type TINYINT,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test2的schame',
'table-name' = 'test2'
);
### source 3
Flink SQL>CREATE TABLE IF NOT EXISTS test3 (
id STRING,
title STRING,
type TINYINT,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test3的schame',
'table-name' = 'test3'
);
### source 4
Flink SQL>CREATE TABLE IF NOT EXISTS test4 (
id STRING,
`time` STRING,
country STRING,
entity_type STRING,
entity_name STRING,
detail STRING,
fo_id STRING,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test4的schame',
'table-name' = 'test4'
);
### sink
Flink SQL>CREATE TABLE IF NOT EXISTS search01_index (
id STRING,
name STRING,
eventDetail STRING,
country STRING,
`time` STRING,
entityType STRING,
entityName STRING,
type TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.XXX.XXX:9200',
'index' = 'search01_index',
'sink.bulk-flush.max-actions' = '1'
);
### transform 1 ,防止进同一个索引时表 t1 和 t3 的 ID 相同,将 ID 进行拼接处理。
Flink SQL>INSERT INTO search01_index
SELECT CONCAT('doc_', , '_', ) AS id,
,
t2.event_detail AS eventDetail,
t2.country,
t2.`time`,
t2.entity_type AS entityType,
t2.entity_name AS entityName,
t2.type
FROM test1 t1
LEFT JOIN test2 t2 ON = t2.doc_id
WHERE t1.del_flag = 0
AND t2.del_flag = 0;
### transform 2 ,防止进同一个索引时表 t1 和 t3 的 ID 相同,将 ID 进行拼接处理。
Flink SQL>INSERT INTO search01_index
SELECT CONCAT('fo_', , '_', ) AS id,
t3.title AS name,
t4.detail AS eventDetail,
t4.country,
t4.`time`,
t4.entity_type AS entityType,
t4.entity_name AS entityName,
t3.type
FROM test3 t3
LEFT JOIN test4 t4 ON = t4.fo_id
WHERE t3.del_flag = 0
AND t4.del_flag = 0;执行完成后访问Flink UI http://192.168.XXX.XXX:8888/#/job/running 可以看到正在运行的
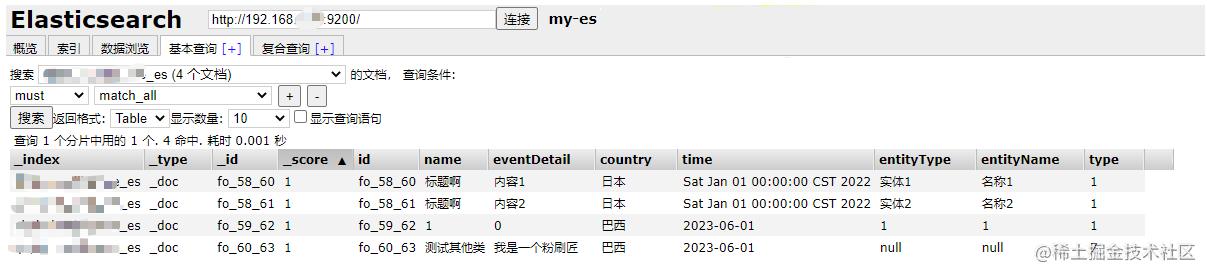
Running Jobs,然后对MySQL 表数据进行增删改操作,可以看到 Elasticsearch 中数据同步效果。
MySQL 同步到 Kafka
### 进入flink/bin 目录下,通过 ./ 命令启动sql客户端工具
Flink SQL> SET execution.checkpointing.interval = 3s;
### source 1
Flink SQL> CREATE TABLE IF NOT EXISTS test1 (
id STRING,
name STRING,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test1的schame',
'table-name' = 'test1'
);
### source 2
Flink SQL> CREATE TABLE IF NOT EXISTS test2 (
id STRING,
doc_id STRING,
event_detail STRING,
country STRING,
`time` STRING,
entity_type STRING,
entity_name STRING,
type TINYINT,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test2的schame',
'table-name' = 'test2'
);
### source 3
Flink SQL>CREATE TABLE IF NOT EXISTS test3 (
id STRING,
title STRING,
type TINYINT,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test3的schame',
'table-name' = 'test3'
);
### source 4
Flink SQL>CREATE TABLE IF NOT EXISTS test4 (
id STRING,
`time` STRING,
country STRING,
entity_type STRING,
entity_name STRING,
detail STRING,
fo_id STRING,
del_flag TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.XXX.XXX',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test4的schame',
'table-name' = 'test4'
);
### sink
Flink SQL>CREATE TABLE IF NOT EXISTS test_kakfa (
id STRING,
name STRING,
eventDetail STRING,
country STRING,
`time` STRING,
entityType STRING,
entityName STRING,
type TINYINT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'test_kakfa',
'properties.bootstrap.servers' = '192.168.XXX.XXX:9092',
'' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'debezium-json',
'debezium-json.ignore-parse-errors'='true'
);
### transform 1 ,防止进同一个索引时表 t1 和 t3 的 ID 相同,将 ID 进行拼接处理。
Flink SQL>INSERT INTO test_kakfa
SELECT CONCAT('doc_', , '_', ) AS id,
,
t2.event_detail AS eventDetail,
t2.country,
t2.`time`,
t2.entity_type AS entityType,
t2.entity_name AS entityName,
t2.type
FROM test1 t1
LEFT JOIN test2 t2 ON = t2.doc_id
WHERE t1.del_flag = 0
AND t2.del_flag = 0;
### transform 2 ,防止进同一个索引时表 t1 和 t3 的 ID 相同,将 ID 进行拼接处理。
Flink SQL>INSERT INTO test_kakfa
SELECT CONCAT('fo_', , '_', ) AS id,
t3.title AS name,
t4.detail AS eventDetail,
t4.country,
t4.`time`,
t4.entity_type AS entityType,
t4.entity_name AS entityName,
t3.type
FROM test3 t3
LEFT JOIN test4 t4 ON = t4.fo_id
WHERE t3.del_flag = 0
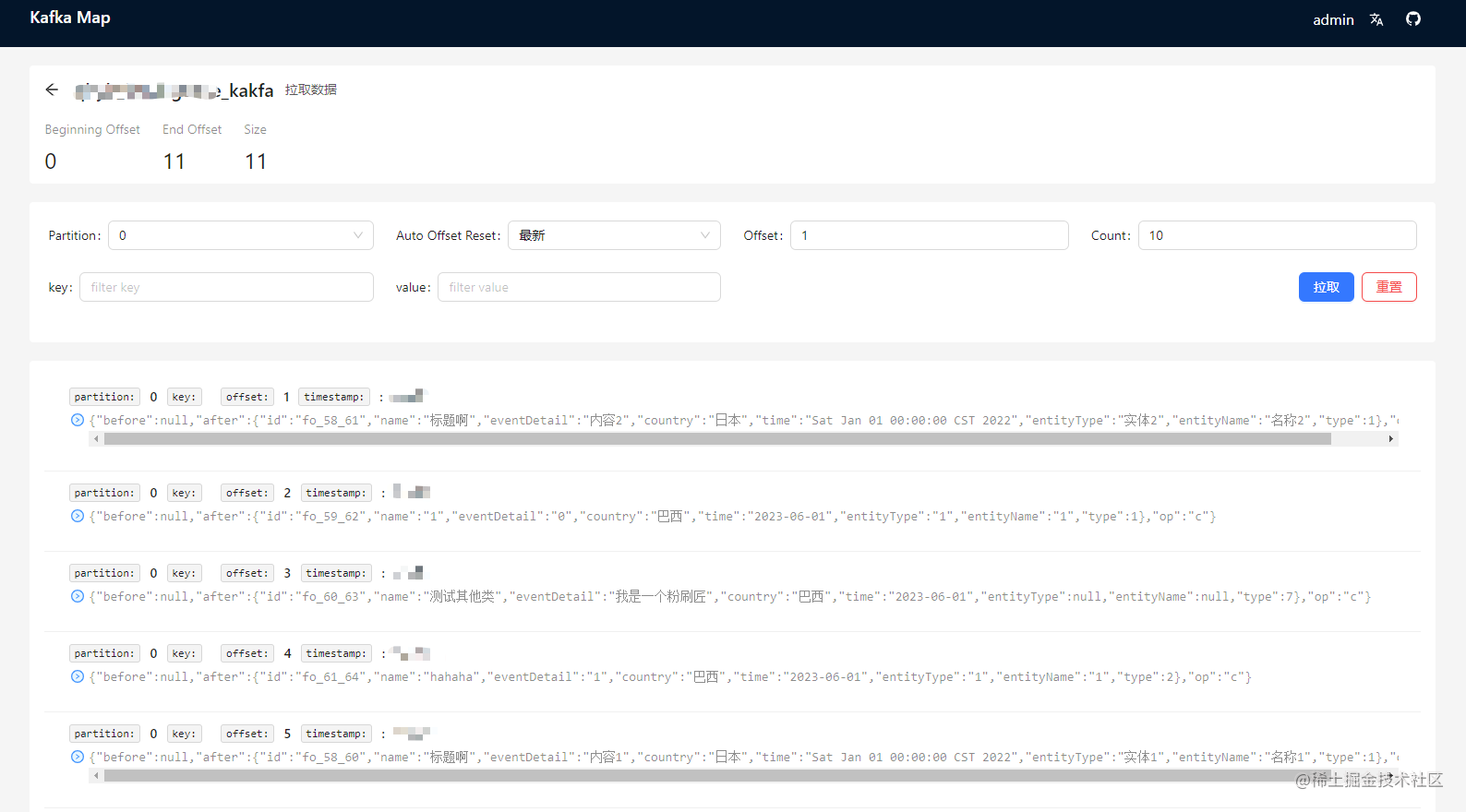
AND t4.del_flag = 0;执行完成后访问 Kafka-map UI 可以看到数据已经进入Kafka,数据格式为:
{"before":null,"after":{"id":"fo_48_50","name":"标题啊","eventDetail":"内容2","country":"日本","time":"2023-06-01","entityType":"实体2","entityName":"名称2","type":3},"op":"c"}2. 通过 Dinky 方式
登录Dinky可视化界面后选择【注册中心】菜单添加flink的环境
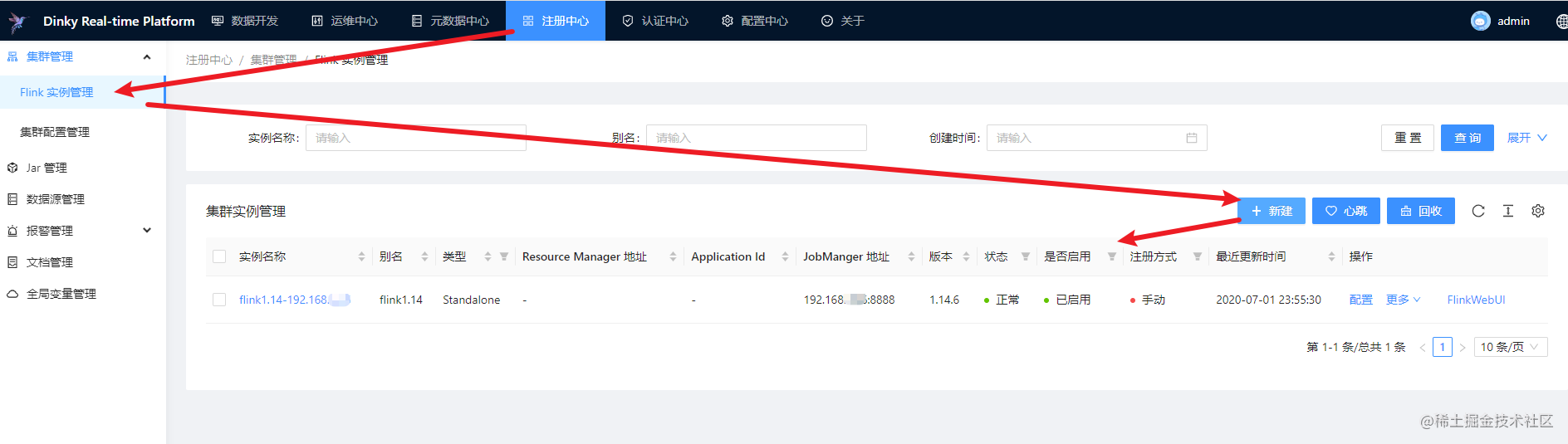
然后选择【数据开发】菜单配置SQL任务
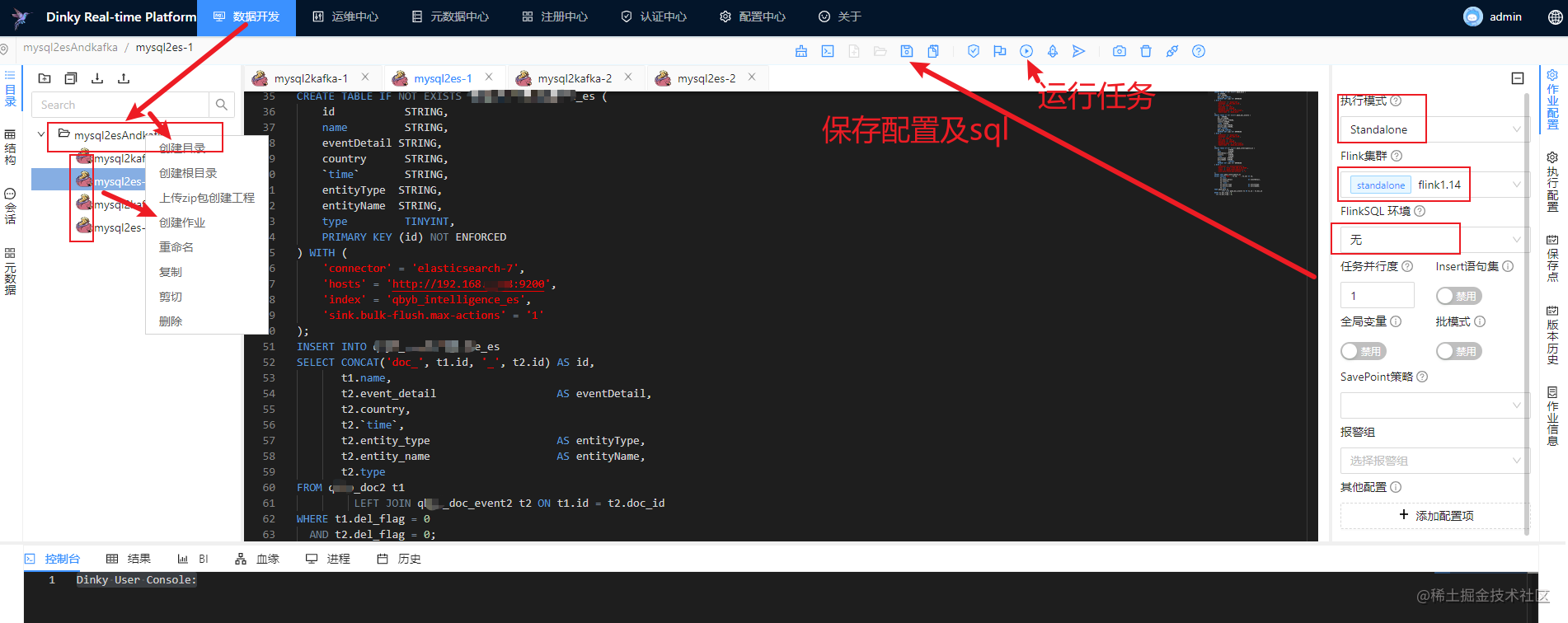
-
mysql2kafka-1 内容
CREATE TABLE IF NOT EXISTS test1 ( id STRING, name STRING, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test1的schame', 'table-name' = 'test1' ); CREATE TABLE IF NOT EXISTS test2 ( id STRING, doc_id STRING, event_detail STRING, country STRING, `time` STRING, entity_type STRING, entity_name STRING, type TINYINT, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test2的schame', 'table-name' = 'test2' ); CREATE TABLE IF NOT EXISTS test_kakfa ( id STRING, name STRING, eventDetail STRING, country STRING, `time` STRING, entityType STRING, entityName STRING, type TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'kafka', 'topic' = 'test_kakfa', 'properties.bootstrap.servers' = '192.168.XXX.XXX:9092', '' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'debezium-json', 'debezium-json.ignore-parse-errors'='true' ); INSERT INTO test_kakfa SELECT CONCAT('doc_', , '_', ) AS id, , t2.event_detail AS eventDetail, t2.country, t2.`time`, t2.entity_type AS entityType, t2.entity_name AS entityName, t2.type FROM test1 t1 LEFT JOIN test2 t2 ON = t2.doc_id WHERE t1.del_flag = 0 AND t2.del_flag = 0; -
mysql2kafka-2 内容
CREATE TABLE IF NOT EXISTS test3 ( id STRING, title STRING, type TINYINT, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test3的schame', 'table-name' = 'test3' ); CREATE TABLE IF NOT EXISTS test4 ( id STRING, `time` STRING, country STRING, entity_type STRING, entity_name STRING, detail STRING, fo_id STRING, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test4的schame', 'table-name' = 'test4' ); CREATE TABLE IF NOT EXISTS test_kakfa ( id STRING, name STRING, eventDetail STRING, country STRING, `time` STRING, entityType STRING, entityName STRING, type TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'kafka', 'topic' = 'test_kakfa', 'properties.bootstrap.servers' = '192.168.6.36:9092', '' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'debezium-json', 'debezium-json.ignore-parse-errors'='true' ); INSERT INTO test_kakfa SELECT CONCAT('fo_', , '_', ) AS id, t3.title AS name, t4.detail AS eventDetail, t4.country, t4.`time`, t4.entity_type AS entityType, t4.entity_name AS entityName, t3.type FROM test3 t3 LEFT JOIN test4 t4 ON = t4.fo_id WHERE t3.del_flag = 0 AND t4.del_flag = 0; -
mysql2es-1 内容
CREATE TABLE IF NOT EXISTS test1 ( id STRING, name STRING, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test1的schame', 'table-name' = 'test1' ); CREATE TABLE IF NOT EXISTS test2 ( id STRING, doc_id STRING, event_detail STRING, country STRING, `time` STRING, entity_type STRING, entity_name STRING, type TINYINT, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test2的schame', 'table-name' = 'test2' ); CREATE TABLE IF NOT EXISTS search01_index ( id STRING, name STRING, eventDetail STRING, country STRING, `time` STRING, entityType STRING, entityName STRING, type TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://192.168.XXX.XXX:9200', 'index' = 'search01_index', 'sink.bulk-flush.max-actions' = '1' ); INSERT INTO search01_index SELECT CONCAT('doc_', , '_', ) AS id, , t2.event_detail AS eventDetail, t2.country, t2.`time`, t2.entity_type AS entityType, t2.entity_name AS entityName, t2.type FROM test1 t1 LEFT JOIN test2 t2 ON = t2.doc_id WHERE t1.del_flag = 0 AND t2.del_flag = 0; -
mysql2es-2 内容
CREATE TABLE IF NOT EXISTS test3 ( id STRING, title STRING, type TINYINT, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test3的schame', 'table-name' = 'test3' ); CREATE TABLE IF NOT EXISTS test4 ( id STRING, `time` STRING, country STRING, entity_type STRING, entity_name STRING, detail STRING, fo_id STRING, del_flag TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.XXX.XXX', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test4的schame', 'table-name' = 'test4' ); CREATE TABLE IF NOT EXISTS search01_index ( id STRING, name STRING, eventDetail STRING, country STRING, `time` STRING, entityType STRING, entityName STRING, type TINYINT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://192.168.XXX.XXX:9200', 'index' = 'search01_index', 'sink.bulk-flush.max-actions' = '1' ); INSERT INTO search01_index SELECT CONCAT('fo_', , '_', ) AS id, t3.title AS name, t4.detail AS eventDetail, t4.country, t4.`time`, t4.entity_type AS entityType, t4.entity_name AS entityName, t3.type FROM test3 t3 LEFT JOIN test4 t4 ON = t4.fo_id WHERE t3.del_flag = 0 AND t4.del_flag = 0;
- 分别点击任务运行后,查看Flink UI
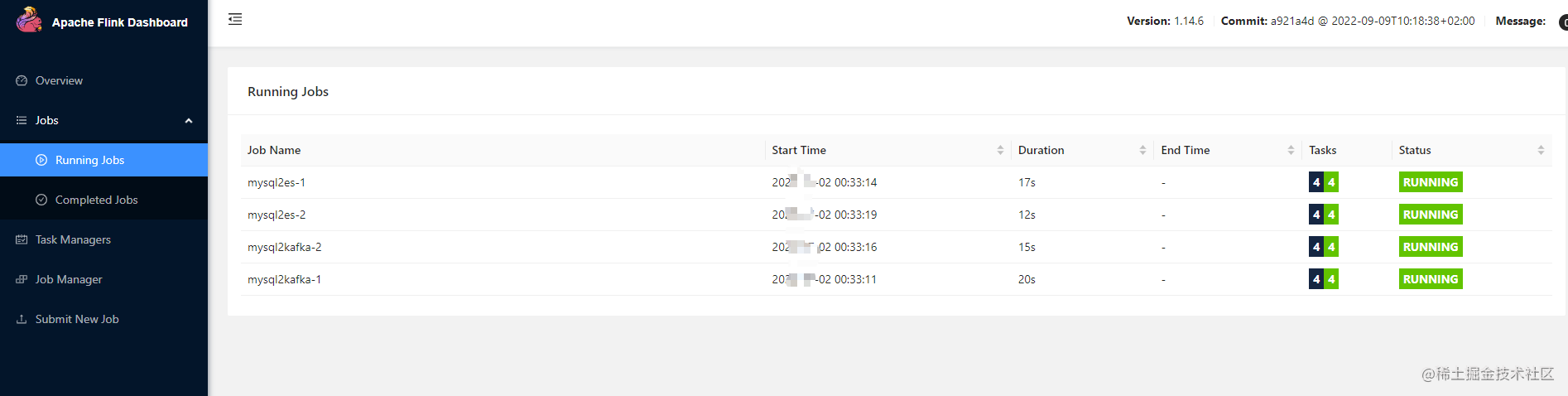
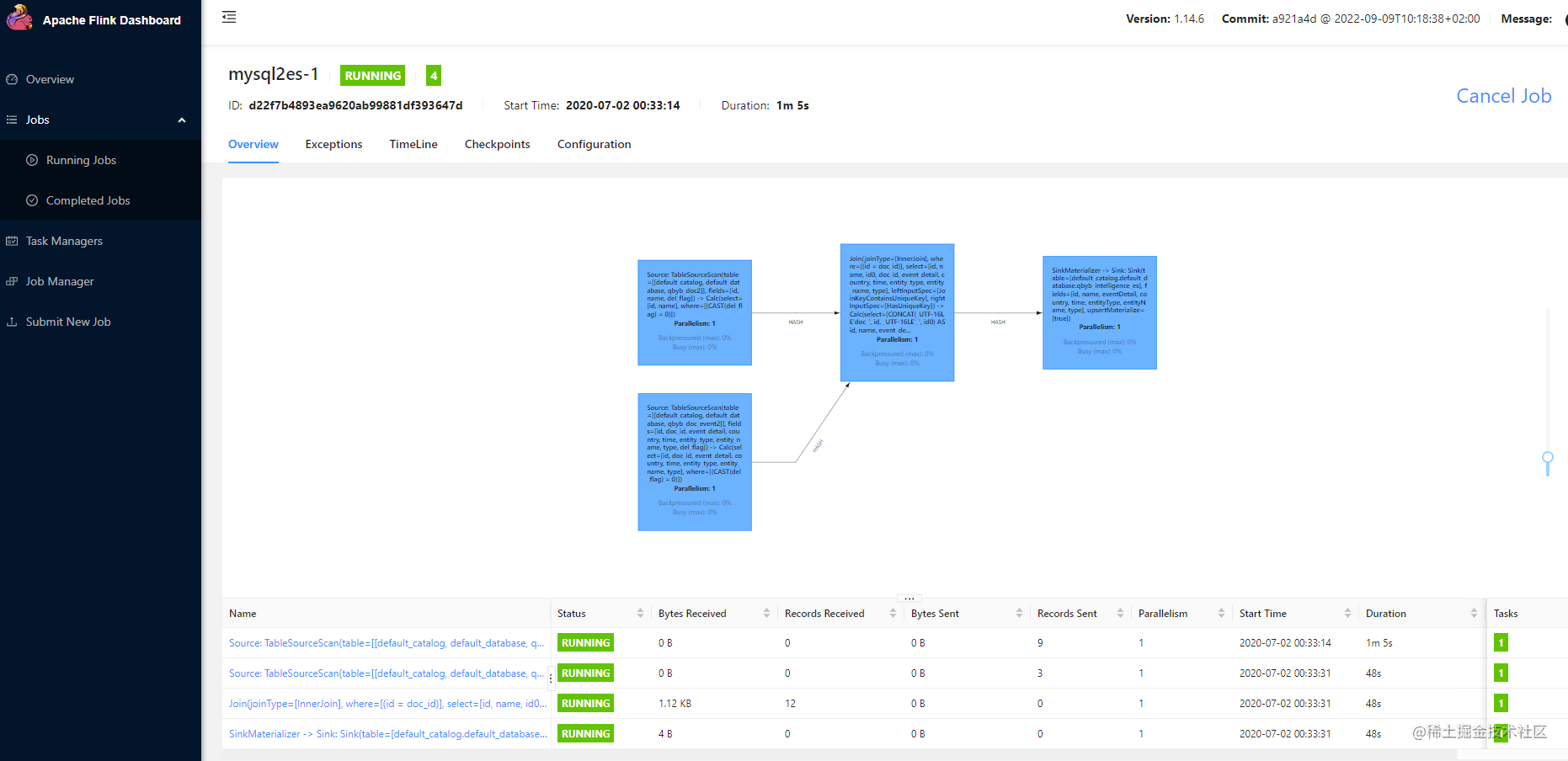
- 查看Kafka-map
- 查看Elasticsearch Head 插件
至此就大功告成了。