作者:来自 Elastic Ugo_Sangiorgi
更多阅读:Elasticsearch:圣诞晚餐 BBQ - 图像识别
什么是 VectorFaces?
既然今天是 12 月 24 日,不如来点圣诞晚餐 BBQ?
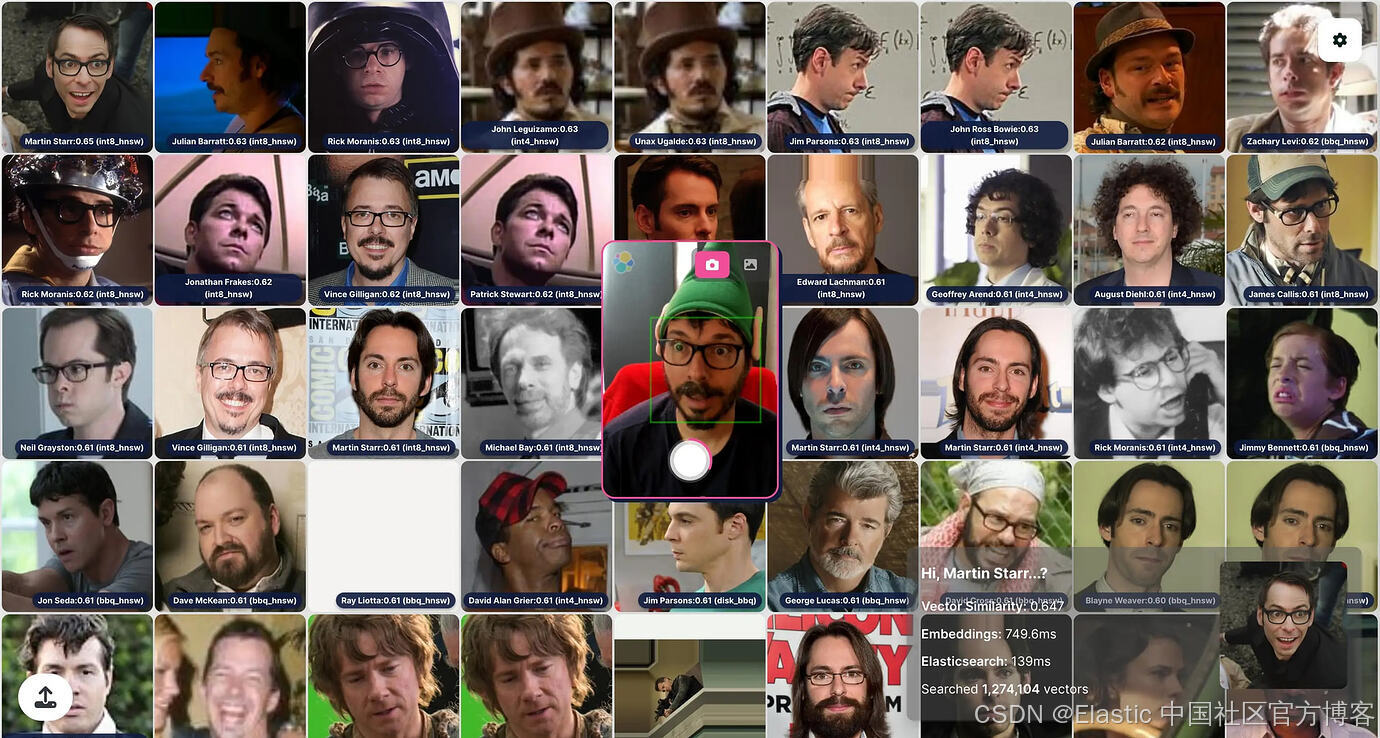
VectorFaces 是我开发的一个人脸识别演示,用于在会议上展示 Elasticsearch 向量能力。它使用 Elasticsearch BBQ、DIskBBQ、int8 和 int4 量化技术,在 120 万个名人脸部 embedding 中进行搜索。
点击这里,通过 start-local 在单个 CPU(!)上体验在线演示,或者查看 github 仓库自行运行。

该数据集摘自 IMDB-WIKI 数据集,包含来自 IMDb 和 Wikipedia 的名人图片。我们使用 InsightFace 生成了 512 维的 embedding。
该演示并行使用了四种量化方法,在四个不同的索引中分别包含 318,526 个向量 embedding(总计 120 万个向量),让你可以直接比较它们的性能:
- BBQ(Better Binary Quantization)------ Elasticsearch 的二进制量化方式,在保持高召回率的同时实现显著压缩
- DiskBBQ ------ 针对磁盘存储优化的 BBQ,在重评分阶段直接从磁盘读取向量
- int8 ------ 8 位整数量化,将每个维度从 4 字节减少到 1 字节
- int4 ------ 4 位量化,提供最大压缩率(比 float32 小 8×)
所有量化都会带来一定的准确性损失。实际中,int8 通常几乎不需要重评分 ,int4 往往受益于 1.5×--2× 的过采样,而 BBQ 通常需要 3×--5× 的过采样才能获得最佳召回率。每种方法在准确性、速度、内存占用和存储之间都有不同的权衡,你可以通过调整参数和过采样来验证这一点。
在 Settings 中,你可以试验这些参数以平衡速度和准确性,并选择在查询时要考虑哪些索引:
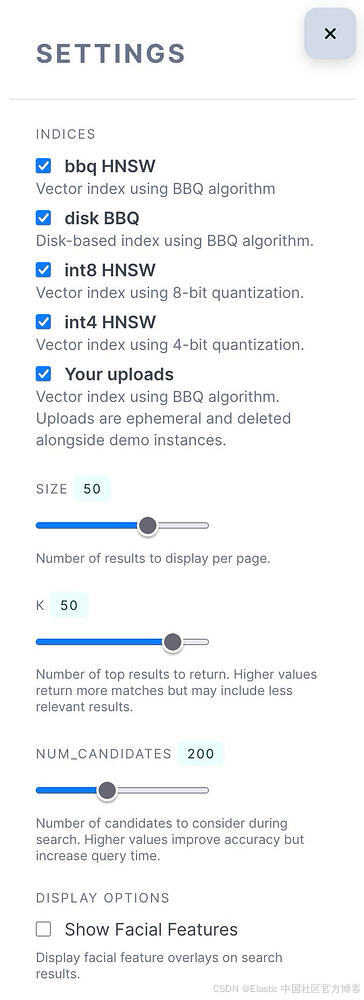
- size:从 Elasticsearch 返回的结果数量。必须 ≤ k。
- k:在所有 shard 上全局返回的最近邻数量。最终的 top k 结果会从所有 shard 合并而来。
- num_candidates :在选择 top k 之前,每个 shard 收集的近似邻居数量。值越高,召回率和准确性越好,但会增加延迟。
- 这是用于优化延迟 / 召回权衡的主要调节参数。
- 对于量化索引,增加 num_candidates 等同于对搜索空间进行过采样,有助于恢复量化过程中损失的准确性。
在更改这些参数后,注意延迟和相关性是如何变化的。在右下角,框中会显示 top 结果以及两个最重要步骤的延迟:你的快照(摄像头或图片)的 embedding 生成,以及 Elasticsearch ------ 它会显示类似 " Elasticsearch: 50ms "。
分数范围是 0 到 1,或者 0% 到 100% 的相似度,这样更容易理解。对于这个数据集,匹配度高于 0.75 可以认为是正匹配,你可以自己测试。
另一个值得关注的点是每个索引使用了多少内存和磁盘,我们可以使用 Elasticsearch _stats API,并在 Kibana 中发出这些请求:
GET faces-bbq_hnsw-10.15/_stats?filter_path=*.primaries.dense_vector
GET faces-disk_bbq-10.15/_stats?filter_path=*.primaries.dense_vector
GET faces-int8_hnsw-10.15/_stats?filter_path=*.primaries.dense_vector
GET faces-int4_hnsw-10.15/_stats?filter_path=*.primaries.dense_vector更改更多参数
虽然 k 和 num_candidates 可以在查询时修改,但一些量化技术还有可以调整的特殊设置。可以在这里查看完整的设置列表,其中一些只适用于索引阶段(例如 m、ef_construction),这需要重新索引,但也有一些可以在查询阶段使用。
也许最重要的一个是 oversample。它控制使用原始 float 向量进行重评分的候选数量。当 oversample: 3.0 时,搜索会先使用量化向量在每个 shard 上检索 num_candidates,然后在返回最终 top k 结果之前,用原始向量对 top k * oversample 个候选进行重评分。值越高,准确性越好,但会带来额外的计算开销。
对于 BBQ,我们可以在索引 mapping 中修改它:
PUT faces-bbq_hnsw-10.15/_mapping
{
"properties": {
"face_embeddings": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine",
"index_options": {
"type": "bbq_hnsw",
"m": 16,
"ef_construction": 100,
"rescore_vector": {
"oversample": 3
}
}
}
}
}对于 DiskBBQ,我们可以修改 rescore_vector.oversample,以及 default_visit_percentage,它控制搜索阶段访问的簇百分比。较低的值通过访问更少的簇来以速度换取准确性。
PUT faces-disk_bbq-10.15/_mapping
{
"properties": {
"face_embeddings": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine",
"index_options": {
"type": "bbq_disk",
"cluster_size": 384,
"default_visit_percentage": 0,
"rescore_vector": {
"oversample": 3
}
}
}
}
}同样,在更改这些参数后,注意延迟和相关性的变化。
下一步
查看完整文档,了解如何在你自己的基础设施上索引和运行此演示的设置说明。
圣诞快乐,祝大家 BBQ 开心!
原文:https://discuss.elastic.co/t/dec-24th-2025-en-bbq-for-christmas-dinner/384022