TL;DR
- 场景:RocketMQ 消费端选型与线上消费积压、延迟、重复消费排查
- 结论:RocketMQ "Push"本质是客户端长轮询拉取;差异主要在节奏控制与位点管理责任
- 产出:Push/Pull 机制对照 + 集群流程梳理 + 常见故障速查与修复路径

RocketMQ 的消费模式
RocketMQ 提供了两种消息订阅模式,分别是 PUSH 模式和 PULL 模式,它们在实现机制和使用方式上存在显著差异:
- PUSH 模式(MQPushConsumer):
- 表面上是由 Broker 主动推送消息到 Consumer
- 实际实现是通过 Consumer 内部维护的长轮询机制
- 典型使用场景:需要实时消费消息的业务,如订单处理、即时通知等
- 优势:对开发者友好,自动处理消息拉取和消费进度管理
- 示例:电商系统中,订单状态变更后立即推送给用户
- PULL 模式(MQPullConsumer):
- 由 Consumer 主动向 Broker 发起拉取请求
- 需要开发者自行控制拉取频率和消息处理逻辑
- 典型使用场景:批量处理任务、定时任务等非实时场景
- 优势:消费节奏完全由应用控制,适合特殊业务需求
- 示例:每天凌晨批量拉取日志数据进行统计分析
实现机制说明:
虽然两种模式在概念上不同,但底层都基于拉取机制。PUSH 模式本质上是通过以下方式实现的:
- Consumer 启动后向 Broker 注册
- 内部线程定期(默认5秒)向 Broker 发起拉取请求
- 当有新消息时立即返回,无消息时 Broker 会hold住请求(最长15秒)
- 在此期间若有新消息到达,Broker 会立即响应
技术细节对比:
- 消息获取方式:
- PUSH:自动轮询,默认5秒间隔
- PULL:需显式调用pullBlockIfNotFound方法
- 消费进度管理:
- PUSH:自动提交offset
- PULL:需手动管理offset
- 异常处理:
- PUSH:内置重试机制
- PULL:需自行实现重试逻辑
实际应用建议:
- 大部分业务场景推荐使用PUSH模式
- 仅在需要精确控制消费节奏时才考虑PULL模式
- 性能敏感场景可以通过调整PUSH模式的拉取参数来优化
常规的消费模型
这是最基本的一个简单的模型:

这是扩展之后的消息模型:
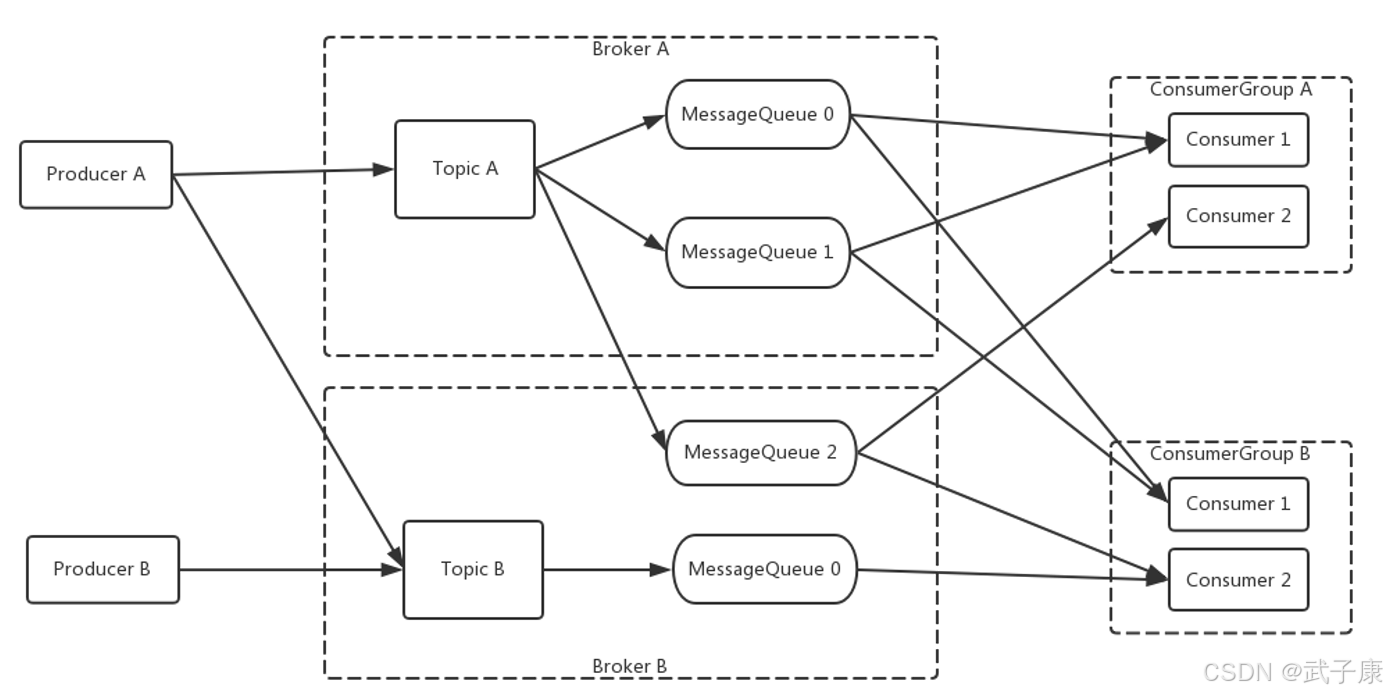
这是RocketMQ的部署模型:

RocketMQ集群工作流程
-
NameServer启动
NameServer启动后会监听指定端口,作为路由控制中心等待Broker、Producer和Consumer的连接。
-
Broker启动
Broker启动后会与所有NameServer保持长连接,定期发送包含Broker信息和Topic数据的心跳包。注册完成后,NameServer集群将建立Topic与Broker的映射关系。
-
Topic创建
创建Topic时需指定存储该Topic的Broker节点,也支持在发送消息时自动创建Topic。
-
消息生产流程
生产者启动时:
- 与任一NameServer建立长连接
- 获取目标Topic对应的Broker信息
- 采用轮询方式选择队列
- 与目标Broker建立连接并发送消息
- 消息消费流程
消费者启动时:
- 连接任一NameServer
- 获取订阅Topic的Broker信息
- 直接与相关Broker建立消费通道
- 开始消费消息RocketMQ集群工作流程
-
NameServer启动
NameServer启动后会监听指定端口,作为路由控制中心等待Broker、Producer和Consumer的连接。
-
Broker启动
Broker启动后会与所有NameServer保持长连接,定期发送包含Broker信息和Topic数据的心跳包。注册完成后,NameServer集群将建立Topic与Broker的映射关系。
-
Topic创建
创建Topic时需指定存储该Topic的Broker节点,也支持在发送消息时自动创建Topic。
-
消息生产流程
生产者启动时:
- 与任一NameServer建立长连接
- 获取目标Topic对应的Broker信息
- 采用轮询方式选择队列
- 与目标Broker建立连接并发送消息
- 消息消费流程
消费者启动时:
- 连接任一NameServer
- 获取订阅Topic的Broker信息
- 直接与相关Broker建立消费通道
- 开始消费消息
然后对整体的 Push、Pull、混合模式进行一个介绍。
Push 模式
核心特点
Push 模式是一种消息推送机制,由服务端主动将消息实时推送给消费端。这种模式的典型应用场景包括即时通讯、实时数据监控和股票行情推送等对时效性要求较高的领域。
优势分析
- 实时性高:消息产生后立即推送,保证最低延迟(通常在毫秒级别)
- 服务端主动:消费端无需轮询,减少无效请求
- 资源节省:避免了消费端频繁查询的资源浪费
潜在问题
- 消费端压力:当遇到突发流量时(如秒杀活动、热点事件),服务端可能瞬间推送大量消息
- 处理能力瓶颈 :消费端的处理能力通常有限,可能出现:
- 消息积压(积压量可能达到数万甚至更多)
- CPU/内存资源耗尽
- 网络带宽被占满
- 级联故障:严重时会导致消费端服务崩溃,进而影响整个系统稳定性
应对策略
- 限流措施 :
- 服务端实施消息推送速率限制
- 采用令牌桶等算法控制流量
- 弹性扩容 :
- 消费端实现自动扩缩容机制
- 基于消息队列长度动态调整处理能力
- 降级方案 :
- 设置消息重要性分级
- 在过载时优先保证核心消息处理
典型应用场景
- 金融交易系统(需要亚秒级延迟)
- 物联网设备状态监控
- 在线协作工具的实时通知
补充说明
在实际架构设计中,通常会结合Push和Pull模式的优点,采用混合模式来平衡实时性和系统稳定性。例如,关键业务消息使用Push,非关键消息采用Pull方式获取。
Pull 模式
Pull 模式是一种消息消费方式,消费端主动从消息队列中拉取消息进行处理。这种模式具有以下特点和优缺点:
优点
- 实时性高:消费端可以按需主动拉取消息,减少消息传递的延迟,适合对实时性要求较高的场景
- 消费可控:消费端可以根据自身处理能力决定拉取消息的频率和数量
- 资源利用率高:服务端无需维护每个消费者的状态信息
缺点
-
消费端处理能力有限:当消费端处理能力不足时,容易造成以下问题:
- 消息积压:未及时处理的消息会在队列中堆积
- 系统压力:瞬时大量消息可能导致消费端过载
- 严重情况下可能压垮客户端系统
-
轮询开销:消费端需要不断轮询检查新消息,可能产生额外的网络开销
应用场景示例
- 实时交易系统:需要快速响应交易指令
- 监控告警系统:需要即时处理异常事件
- 低延迟数据处理:如金融行情分析等
优化方案
- 动态调整拉取频率:根据处理能力自动调整拉取间隔
- 批量处理:适当增加每次拉取的消息数量
- 消费端负载均衡:部署多个消费实例分担处理压力
- 背压机制:当处理能力不足时主动降低拉取速率
对比Push模式
与Push模式相比,Pull模式更适用于:
- 消费端处理能力差异大的场景
- 需要精确控制消费速率的场景
- 对消息顺序性要求不高的场景
Push模式与Pull模式的详细对比
Push模式实现原理
Push模式下,消息消费的主动权在服务端。具体实现过程如下:
- Consumer客户端会启动一个长轮询线程,持续向Broker发送请求
- 该线程内部封装了复杂的等待-通知机制:
- 当没有消息时,连接会保持打开状态(默认等待15秒)
- 当有新消息到达时,Broker会立即响应
- 消费者通过注册MessageListener接口实现消息处理:
java
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
// 业务处理逻辑
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});- 优势:实时性好,编程模型简单,适合对延迟敏感的场景
Pull模式实现细节
Pull模式下,消费节奏完全由客户端控制:
- 获取消息队列集合:
java
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("TopicTest");- 遍历处理每个消息队列:
- 首先获取消费位移:
java
long offset = consumer.fetchConsumeOffset(mq, true);- 然后批量拉取消息(默认每次最多32条):
java
PullResult pullResult = consumer.pull(mq, "*", offset, 32);- 处理完成后手动提交位移:
java
consumer.updateConsumeOffset(mq, pullResult.getNextBeginOffset());- 典型应用场景:
- 需要精确控制消费节奏的业务
- 批量数据处理场景
- 需要自定义重试策略的情况
RocketMQ的混合模式
RocketMQ采用"长轮询Pull"模拟Push效果:
-
实现机制:
- 消费者启动PullRequestService服务
- 采用阻塞式Pull(默认超时时间20秒)
- 服务端有新消息立即返回,无消息则等待
-
优势对比:
特性 纯Push 纯Pull RocketMQ模式 实时性 高 低 高 服务端压力 大 小 适中 客户端控制度 低 高 中等 -
异常处理:
- 网络中断时会自动重试
- 支持本地偏移量缓存
- 提供多种负载均衡策略
这种设计既保证了接近Push模式的实时性,又避免了服务端过载的风险,是RocketMQ高吞吐量的关键设计之一。
错误速查
以下是转换为Markdown表格语法的内容:
markdown
| 症状 | 根因定位 | 修复 |
|------|----------|------|
| 消费延迟突然升高、积压飙升 | 消费线程池/业务处理变慢;批量过大导致单批耗时过长;下游依赖抖动 | 看Consumer端处理耗时、并发数、失败率;看Broker/Topic的堆积与消费TPS;核对消费线程配置与业务日志 |
| 同一消息重复消费 | 至少一次语义下ack/提交位点前崩溃;消费成功但返回失败;超时触发重试 | 对照消费回调返回值与异常栈;看重试次数与DLQ;核对幂等键/去重表 |
| 消费位点错乱、跳跃或回退 | 手动offset管理逻辑错误;多实例竞争更新;重启后未正确持久化 | 打印每个队列的offset流转;检查update/commit的调用时机;核对存储介质/回写频率 |
| "看起来Push但像在轮询",CPU/网络无效开销 | 拉取间隔/挂起参数不匹配;无消息时频繁短轮询 | 观察拉取请求QPS与空拉比例;看请求是否被挂起(suspend)还是快速返回 |
| Rebalance频繁,消费抖动 | 消费者实例频繁上下线;会话超时/心跳不稳;组内实例数波动 | 看客户端日志中的rebalance频率与原因;核对心跳/超时配置;看容器重启与健康检查 |
| 某些队列长期不消费或消费倾斜 | 队列分配不均;某实例处理慢导致"拖尾";热点key导致局部顺序约束 | 对比每个MessageQueue的消费进度与TPS;看实例间负载差异 |
| 消费失败后无限重试/进入死循环 | 重试策略缺少"不可重试"出口;异常分类不清 | 看失败原因分布;看同一消息反复出现且原因相同 |
| Pull模式拉取不到消息或漏消费 | 订阅表达式/Tag不匹配;offset起点错误;队列遍历与nextBeginOffset处理不当 | 校验订阅表达式;打印pullResult与nextBeginOffset;核对起始offset获取逻辑 |修复措施详细说明
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 消费延迟突然升高、积压飙升 | 消费线程池/业务处理变慢;批量过大导致单批耗时过长;下游依赖抖动 | 看Consumer端处理耗时、并发数、失败率;看Broker/Topic的堆积与消费TPS;核对消费线程配置与业务日志 |
| 同一消息重复消费 | 至少一次语义下ack/提交位点前崩溃;消费成功但返回失败;超时触发重试 | 对照消费回调返回值与异常栈;看重试次数与DLQ;核对幂等键/去重表 |
| 消费位点错乱、跳跃或回退 | 手动offset管理逻辑错误;多实例竞争更新;重启后未正确持久化 | 打印每个队列的offset流转;检查update/commit的调用时机;核对存储介质/回写频率 |
| "看起来Push但像在轮询",CPU/网络无效开销 | 拉取间隔/挂起参数不匹配;无消息时频繁短轮询 | 观察拉取请求QPS与空拉比例;看请求是否被挂起(suspend)还是快速返回 |
| Rebalance频繁,消费抖动 | 消费者实例频繁上下线;会话超时/心跳不稳;组内实例数波动 | 看客户端日志中的rebalance频率与原因;核对心跳/超时配置;看容器重启与健康检查 |
| 某些队列长期不消费或消费倾斜 | 队列分配不均;某实例处理慢导致"拖尾";热点key导致局部顺序约束 | 对比每个MessageQueue的消费进度与TPS;看实例间负载差异 |
| 消费失败后无限重试/进入死循环 | 重试策略缺少"不可重试"出口;异常分类不清 | 看失败原因分布;看同一消息反复出现且原因相同 |
| Pull模式拉取不到消息或漏消费 | 订阅表达式/Tag不匹配;offset起点错误;队列遍历与nextBeginOffset处理不当 | 校验订阅表达式;打印pullResult与nextBeginOffset;核对起始offset获取逻辑 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接