
2024
1.摘要
background
模态不对称性: 视听语音识别(AVSR)面临的主要挑战是音频和视频模态之间固有的不对称性 。
信息差异: 音频通常采样率高且较为清晰,易于学习;而视频(唇语)包含遮挡、模糊和冗余信息,难以单独学习 。
现有方法的局限: 许多现有方法主要依赖音频作为"教师"来指导学习,仅关注模态间的共享信息 (Shared Information),而忽略了模态特有信息 (Unique Information)和只有在双模态共存时才出现的协同信息(Synergistic Information) 。
innovation
问题重构: 作者将视听语音表征学习重新构建为获取三种信息的任务:共享信息(Shared)、特有信息(Unique)和协同信息(Synergistic) 5555。
**ES\^3**策略: 提出了一种名为"进化自监督学习"(Evolving Self-Supervised Learning)的新策略。该策略通过三个递进阶段,逐步学习上述三种信息,从而构建鲁棒的视听表征 6666。
无需繁琐调参: 这种分阶段进化的策略避免了以往方法中为了平衡模态学习速度而需要的大量手动参数调整(如masking ratios, dropout rate等) 7777。
- 方法 Method
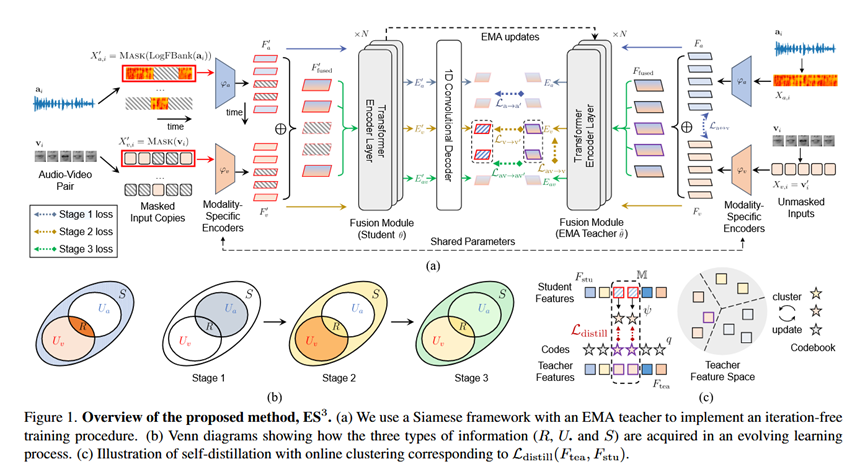
Pipeline 总览
该方法采用了一个简单的Siamese网络架构(孪生网络),包含学生模型(Student)和基于EMA(指数移动平均)更新的教师模型(Teacher)。通过三个渐进阶段(Stage 1, 2, 3)分别优化不同的信息类型,利用掩码预测(Masked Prediction)和自蒸馏(Self-distillation)作为主要的学习目标。
详细步骤与输入输出
基础架构 (Base Architecture):
输入: 配对的音频 X_a和视频 X_v。
编码器: 音频编码器 \\varphi_a (CNN) + 视频编码器 \\varphi_v (Lightweight VGG) + 模态融合编码器 \\theta (Transformer) 13。
融合方式: 简单的求和操作(Sum Fusion)处理不同模态输入 14。
理论基础: 利用部分信息分解(PID)框架,将互信息分解为共享(R)、特有(U_a, U_v)和协同(S)部分 15151515。
Stage 1: 学习音频特有信息 (U_a) 和共享信息 (R)
目的: 利用易学的音频模态初始化表征,并捕捉跨模态共享信息以启动视觉学习 。
输入: 掩码音频(学生端),未掩码音频(教师端)。
Loss 设计:
-
-
- 自蒸馏损失 \\mathcal{L}_{a\\rightarrow a'}: 音频到音频的掩码预测 17。
- 对比损失 \\mathcal{L}_{a\\leftrightarrow v} (InfoNCE): 强制音频和视频在帧级别对齐,捕捉共享信息 R 18181818。
-
Stage 2: 学习视频特有信息 (U_v)
目的: 在已有共享信息的基础上,攻克难学的视频特有信息 19。
操作: 冻结音频编码器 \\varphi_a(不再更新) 20。
输入: 掩码视频(学生端),未掩码视频(教师端)。
Loss 设计:
-
-
- 自蒸馏损失 \\mathcal{L}_{v\\rightarrow v'}: 视频到视频的掩码预测 21。
- 跨模态蒸馏 \\mathcal{L}_{av\\rightarrow v}: 让视频流去预测未掩码的"音频+视频"联合特征,以此注入更多信息。注意:此处引入了自动调节的温度参数 \\tau 来平衡学习难度。
-
Stage 3: 学习协同信息 (S)
目的: 最大化总信息量 I(E_{av}; Y),迫使模型利用双模态互补来恢复信息。
操作: 对音频和视频的相同位置进行掩码,防止模型从单一模态"偷看"信息。
Loss 设计:
-
-
- 联合蒸馏 \\mathcal{L}_{av\\rightarrow av'}: 掩码AV输入预测未掩码AV输出。
-
-
实验 Experimental Results
数据集
训练/评测: LRS2-BBC (223h, 英文), LRS3-TED (433h, 英文) 。
新数据集: CAS-VSR-S101 (101.1h, 中文),包含新闻和对话节目,用于验证多语言鲁棒性 。
实验结论
- 低资源与高资源设定: 在 LRS2 和 LRS3 上,无论是在低资源(几十小时)还是高资源(全量)微调下,该方法的 BASE 模型(102M)和 LARGE 模型(317M)均能达到或超越 SOTA(如 AV-HuBERT, RAVEn, VATLM),且参数量更少或训练数据更少 。
- 中文数据集表现: 在 CAS-VSR-S101 上,该方法优于强监督基线,证明了策略的通用性 。
- 各阶段有效性(Ablation):
Stage 1 确实学到了大部分音频信息(ASR性能接近最终结果) 。
Stage 2 显著提升了视觉表征(VSR 性能大幅提升) 。
Stage 3 通过融合协同信息,进一步提升了双模态(AVSR)和单模态任务的性能 。
- 总结 Conclusion
解决多模态学习中"不对称性"的关键在于分而治之:不要试图一次性从不对等的模态中学习所有信息,而是应该按照"易学(音频/共享) \\rightarrow 难学(视频/特有) \\rightarrow 协同(整体)"的课程表(Curriculum)进行渐进式学习。