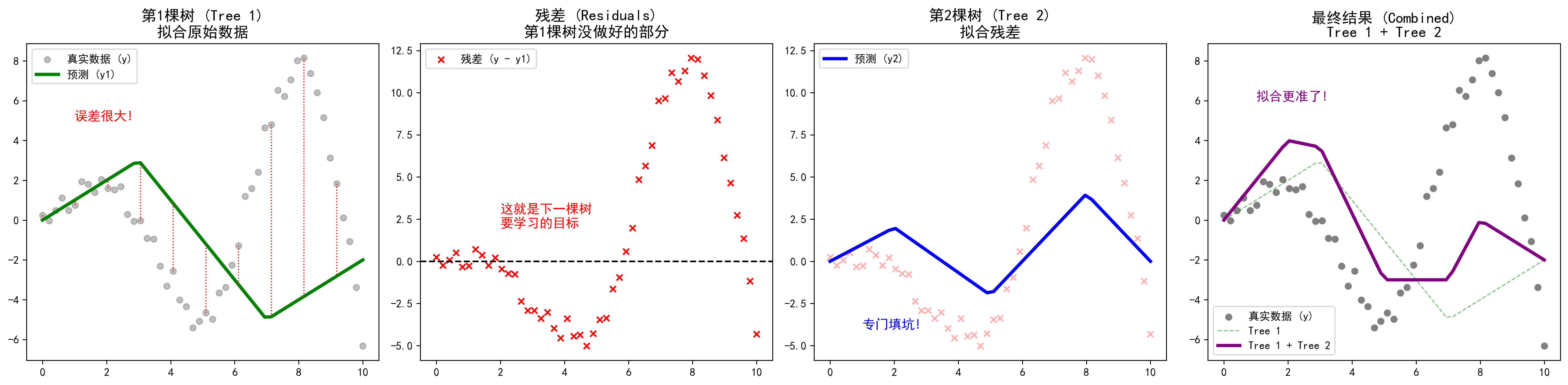
图解说明:
- 图1:第一棵树尝试拟合数据,但误差很大(红色虚线)。
- 图2:算出第一棵树的"残差"(也就是没做好的部分)。
- 图3 :第二棵树专门去拟合这个残差(填坑)。
- 图4:把两棵树加起来,效果瞬间变好了!
机器学习竞赛中的**"刷榜神器"**------XGBoost。
它的全称是 eXtreme Gradient Boosting(极致梯度提升)。听名字就感觉很霸气,对吧?事实上,它也确实很强。在很长一段时间里,Kaggle(全球最大的数据科学竞赛平台)上拿冠军的队伍,大半都在用它。
如果你完全不懂算法,没关系。我们先从它的老祖宗"提升树 (Boosting)"说起。
1. 核心思想:三个臭皮匠,顶个诸葛亮
XGBoost 属于 Boosting 家族。这个家族的逻辑我们之前在 Adaboost 里聊过:把一堆水平一般的"弱分类器"组合起来,变成一个"强分类器"。
但是,XGBoost 的组合方式和 Adaboost 不太一样。
- Adaboost 是看谁做错了,就加重谁的权重(死磕错题)。
- XGBoost (以及 GBDT) 是**"填坑"**。
举个生动的例子:打高尔夫球 ⛳️
假设你的目标是把球打进 100米 远的洞里。
-
第一杆 (模型 1) :你挥杆一击,球飞了 60米。
- 现在的误差 (Residual) 是:100 - 60 = 40米。
- 这就是我们要填的"坑"。
-
第二杆 (模型 2) :这一次,你的目标不再是洞口 ,而是填补那 40米 的差距。
- 你轻轻一挥,球飞了 30米。
- 现在的误差是:40 - 30 = 10米。
-
第三杆 (模型 3) :你的目标是填补这 10米 的差距。
- 你推了一把,球滚了 10米。
- 进洞!
最终结果 = 第一杆(60) + 第二杆(30) + 第三杆(10) = 100米。
这就是 XGBoost 的核心逻辑:每一个新模型,都是为了去拟合上一个模型的"残差"(也就是上一个模型没做好的部分)。
2. 为什么要叫 "Gradient" (梯度)?
你可能会问:"这不就是填坑吗?跟梯度有什么关系?"
在数学上,"残差"(预测值和真实值的差距)其实就是**"负梯度"**方向。
- 想象你在山上(误差很大),你想下山(减小误差)。
- 梯度就是告诉你"哪个方向下山最快"的指南针。
- XGBoost 每次都在顺着这个最快的方向走,所以它能用最少的步数(最少的树)把误差降到最低。
3. 为什么要叫 "eXtreme" (极致)?
既然已经有了 GBDT (梯度提升树),为什么还要搞个 XGBoost?
因为它在工程实现 上做到了极致 。简单说就是:快!准!狠!
1. 并行处理 (快) ⚡
你可能会疑惑:"XGBoost 不是一棵树接一棵树串行训练的吗?怎么并行?"
没错,树与树之间是串行的 (必须先有第一棵,才能算残差种第二棵)。
但是,在种每一棵树的时候,XGBoost 做到了并行。
举个栗子:
假设我们要根据"年龄"、"工资"、"学历"等 10 个特征来预测一个人会不会买房。
在寻找"最佳分裂点"(比如是按年龄分?还是按工资分?)时:
- 普通算法:先算"年龄"的最佳切分点,算完再算"工资"的,再算"学历"的......一个接一个,慢吞吞。
- XGBoost :它预先处理好了数据,就像雇了 10 个工人。
- 工人 A 负责算"年龄"。
- 工人 B 负责算"工资"。
- 工人 C 负责算"学历"。
- 大家同时开工! 瞬间就选出了这一步的最佳特征。
这就是它为什么能把 CPU 的所有核心都跑满,速度飞快的原因。
2. 正则化 (准) 🎯
XGBoost 在它的核心公式里,加了一个**"紧箍咒"**(正则化项)。
它的原则是:如果一棵树太复杂(叶子太多),或者判断太极端(权重太大),我就要罚你的分!
举个栗子:
我们要预测房价。
- 普通模型 (容易过拟合) :它可能会为了迎合训练数据,生成一条奇葩规则:"如果门牌号是 888 且门口有棵歪脖子树,房价 = 1000万"。
- 这在训练数据里可能是对的,但换个小区这就完全失效了。
- XGBoost (有正则化) :
- 当它想添加"门口有歪脖子树"这条规则时,它会算一笔账:
- "加了这条规则,误差确实小了一点点(赚了 5 块钱)。"
- "但是,树变得更复杂了,触发了正则化惩罚(罚款 10 块钱)。"
- 结果:5 - 10 = -5。亏了!
- 决策:砍掉这条规则!只保留"面积大"、"地段好"这种通用的硬道理。
这样训练出来的模型,虽然在训练集上可能不如前者那么"完美",但在面对新数据时,准确率会高得多。
3. 自动处理缺失值 (狠) 🛠️
如果数据里有很多空缺(比如有人没填年龄),普通算法可能直接报错。
XGBoost 会自动学习:遇到空缺值,是把它归到左边分支好,还是右边分支好。
4. XGBoost 的优缺点
✅ 优点 (为什么它是神?)
- 精度惊人:在结构化数据(表格数据)上,它的表现几乎是统治级的。
- 速度快:经过各种工程优化,比传统的 GBDT 快 10 倍以上。
- 鲁棒性强:不容易过拟合,对缺失值不敏感。
❌ 缺点 (也要注意)
- 参数多:它像一辆赛车,虽然快,但仪表盘上有几十个按钮(参数)。如果不会调参,可能开不出最快速度。
- 黑盒:虽然比神经网络好解释一点,但几百棵树堆在一起,你也很难直观地说清楚到底是哪个特征起了决定性作用。
5. 总结
XGBoost 就是一个追求极致的填坑大师:
- 核心逻辑:一杆接一杆,每一杆都只管填补剩下的距离(拟合残差)。
- 极致优化:利用并行计算、正则化等手段,把速度和效果推到了极限。
如果你在做数据挖掘比赛,或者处理表格数据,XGBoost 绝对是你工具箱里必不可少的那把"屠龙刀"!🐉