三维重建【6】DUSt3R:论文摘要前言、与3DGS结合在本地数据集上训练
- 一、摘要
-
- [1. 原文](#1. 原文)
- [2. 译文](#2. 译文)
- 二、前言
- 三、代码运行
-
- [1. DUSt3R运行](#1. DUSt3R运行)
- [2. 与3DGS结合运行](#2. 与3DGS结合运行)
一、摘要
1. 原文
Multi-view stereo reconstruction (MVS) in the wild requires to first estimate the camera parameters e.g. intrinsic and extrinsic parameters. These are usually tedious and cumbersome to obtain, yet they are mandatory to triangulate corresponding pixels in 3D space, which is the core of all best performing MVS algorithms. In this work, we take an opposite stance and introduce DUSt3R1, a radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction of arbitrary image collections, i.e. operating without prior information about camera calibration nor viewpoint poses. We cast the pairwise reconstruction problem as a regression of pointmaps, relaxing the hard constraints of usual projective camera models. We show that this formulation smoothly unifies the monocular and binocular reconstruction cases. In the case where more than two images are provided, we further propose a simple yet effective global alignment strategy that expresses all pairwise pointmaps in a common reference frame. We base our network architecture on standard Transformer encoders and decoders, allowing us to leverage powerful pretrained models. Our formulation directly provides a 3D model of the scene as well as depth information, but interestingly, we can seamlessly recover from it, pixel matches, relative and absolute cameras. Exhaustive experiments on all these tasks showcase that the proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on monocular/multi-view depth estimation as well as relative pose estimation. In summary, DUSt3R makes many geometric 3D vision tasks easy.
2. 译文
野外多视图立体重建(MVS)需要首先估计相机参数,例如内参和外参。这些通常获取起来很乏味且麻烦,但它们必须在 3D 空间中对相应像素进行三角测量,这是所有性能最佳的 MVS 算法的核心。在这项工作中,我们采取相反的立场并引入 DUSt3R,这是一种用于任意图像集合的密集和无约束立体 3D 重建的全新范例,即在没有有关相机校准或视点姿势的先验信息的情况下进行操作。我们将成对重建问题转化为点图的回归,放松了通常投影相机模型的硬约束。我们证明这个公式顺利地统一了单目和双目重建案例。在提供两个以上图像的情况下,我们进一步提出了一种简单而有效的全局对齐策略,该策略在公共参考系中表达所有成对点图。我们的网络架构基于标准 Transformer 编码器和解码器,使我们能够利用强大的预训练模型。我们的公式直接提供了场景的 3D 模型以及深度信息,但有趣的是,我们可以从中无缝恢复、像素匹配、相对和绝对相机。对所有这些任务的详尽实验表明,所提出的 DUSt3R 可以统一各种 3D 视觉任务,并在单目/多视图深度估计以及相对位姿估计上表现SoTA。总之,DUSt3R 使许多几何 3D 视觉任务变得简单。
二、前言
从多个视图进行无约束的基于图像的密集 3D 重建是计算机视觉的几个长期研究的最终目标之一 。简而言之,**该任务旨在根据给定的一组特定场景的照片来估计该场景的 3D 几何形状和相机参数。**它不仅有许多应用,如测绘、导航、考古学、文化遗产保护、机器人技术,而且也许更重要的是,它在所有 3D 视觉任务中占有根本特殊的地位。事实上,它几乎涵盖了所有其他几何 3D 视觉任务。因此,现代 3D 重建方法包括汇集各个子领域数十年进步的成果,例如关键点检测和匹配、鲁棒估计、运动结构恢复和束调整 (BA) 、密集多视图立体 (MVS) 等。
总而言之,现代 SfM 和 MVS 流程归结为解决一系列最小问题:匹配点、查找基本矩阵、三角测量点、稀疏重建场景、估计相机参数以及最后执行密集重建。考虑到最近的进展,这个相当复杂的链在某些情况下当然是一个可行的解决方案,但我们认为它非常不令人满意:每个子问题都没有得到完美解决,并且给下一步增加了噪音,增加了处理流程作为一个整体工作所需的复杂性和工程工作量。在这方面,每个子问题之间缺乏沟通就很能说明问题:如果它们互相帮助似乎更合理,即密集重建自然应该受益于为恢复相机姿势而构建的稀疏场景,反之亦然。最重要的是,该流程中的关键步骤很脆弱,在许多情况下容易破裂。例如,SfM 的关键阶段用于估计所有相机参数,通常在许多常见情况下会失败,例如当场景视图数量较低时、对于具有非朗伯表面的物体、在相机运动不足的情况下等。这是令人担忧的,因为最终,"MVS 算法仅与输入图像和相机参数的质量一样好"。
在本文中,我们提出了 DUSt3R,这是一种从未校准和未摆姿势的相机进行密集无约束立体 3D 重建的全新方法。主要组件是一个网络,它可以仅从一对图像回归密集且准确的场景表示,而无需有关场景或相机的先验信息(甚至没有内在参数)。生成的场景表示基于具有丰富属性的 3D 点图:它们同时封装 (a) 场景几何形状、(b) 像素和场景点之间的关系以及 © 两个视点之间的关系。仅从该输出中,几乎可以直接提取所有场景参数(即摄像机和场景几何形状)。这是可能的,因为我们的网络联合处理输入图像和生成的 3D 点图,从而学习将 2D 结构与 3D 形状关联起来,并有机会同时解决多个最小问题,从而实现它们之间的内部"协作"。
我们的模型使用简单的回归损失以完全监督的方式进行训练,利用大型公共数据集,这些数据集的真实注释要么是综合生成的,要么是从 SfM 软件重建的,要么是使用专用传感器捕获的。我们偏离了集成特定任务模块的趋势,而是采用基于通用变压器架构的完全数据驱动策略,在推理时不强制任何几何约束,但能够从强大的预训练方案中受益。该网络学习强大的几何和形状先验,这让人想起 MVS 中常用的那些,例如来自纹理、阴影或轮廓的形状。
为了融合来自多个图像对的预测,我们重新考虑点图情况下的捆绑调整(BA),从而实现全尺寸 MVS。我们引入了一种全局对齐过程,与 BA 相反,它不涉及最小化重投影误差。相反,我们直接在 3D 空间中优化相机位姿和几何对齐,速度很快,并且在实践中表现出出色的收敛性。我们的实验表明,使用各种未知传感器的现实场景中的视图之间的重建是准确且一致的。我们进一步证明,相同的架构可以无缝处理现实生活中的单目和多视图重建场景。
总之,我们的贡献有四个方面。首先,我们提出了第一个来自未校准和未摆姿势图像的整体端到端 3D 重建流程,它统一了单目和双目 3D 重建。其次,我们介绍了 MVS 应用程序的点图表示,它使网络能够预测规范框架中的 3D 形状,同时保留像素和场景之间的隐式关系。这有效地消除了通常透视相机公式的许多限制。第三,我们引入了在多视图 3D 重建的背景下全局对齐点图的优化过程。我们的程序可以轻松提取经典 SfM 和 MVS 管道的所有常见中间输出。从某种意义上说,我们的方法统一了所有 3D 视觉任务,并大大简化了传统的重建流程,使 DUSt3R 相比之下显得简单易行。第四,我们在一系列 3D 视觉任务上展示了良好的性能。特别是,我们的一体化模型在单目和多视图深度基准以及多视图相机姿态估计上实现了最先进的结果。
三、代码运行
1. DUSt3R运行
1)克隆仓库
python
git clone --recursive https://github.com/naver/dust3r
cd dust3r2)虚拟环境搭建
python
conda create -n dust3r python=3.11 cmake=3.14.0
conda activate dust3r
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -r requirements.txt3)下载预训练权重
python
mkdir -p checkpoints/
wget https://download.europe.naverlabs.com/ComputerVision/DUSt3R/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth -P checkpoints/4)交互demo执行
python
python3 demo.py --weights ./checkpoints/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth执行时遇到以下问题:
ImportError: /home/ubuntu/anaconda3/envs/dust3r/lib/python3.11/site-packages/torch/lib/libtorch_cpu.so: undefined symbol: iJIT_NotifyEvent
解决方案: 这个错误与PyTroch相关,一般是不兼容导致的问题pip uninstall torch torchvision
pip install torch torchvision

执行结果:

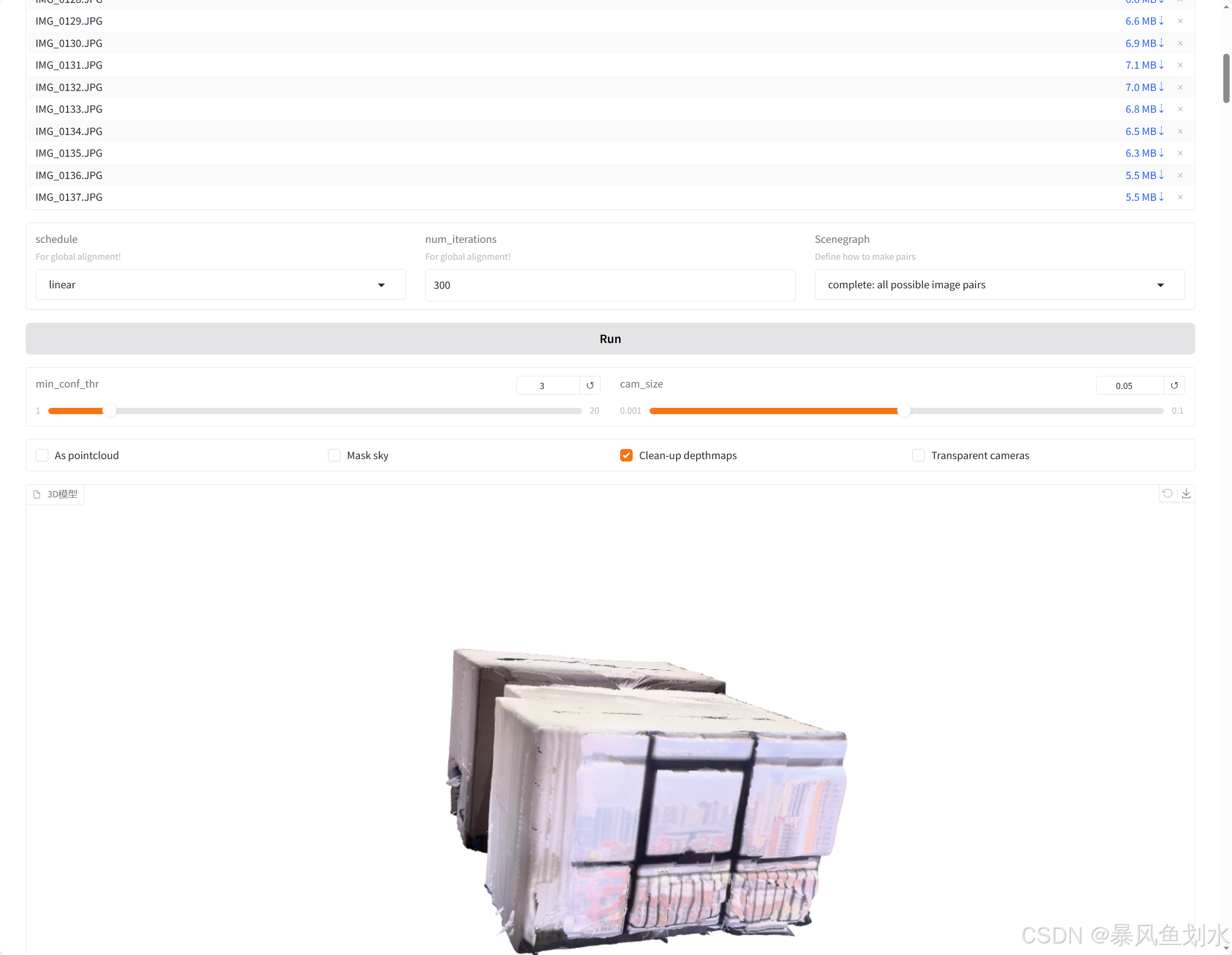
2. 与3DGS结合运行
1)克隆仓库
python
git clone https://github.com/Two-Shots-Are-Enough/DUSt3R-to-COLMAP.git
cd DUSt3R-to-COLMAP
# 权重文件下载
wget -nc https://download.europe.naverlabs.com/ComputerVision/DUSt3R/DUSt3R_ViTLarge_BaseDecoder_512_dpt.pth -P checkpoints/
git clone https://github.com/naver/dust3r --recursive2)虚拟环境搭建
采用与DUSt3R一样的虚拟环境,补充安装:
python
pip install lovely_tensors3)执行代码
python
python dust3r_inference.py可能遇到的问题:
1. Traceback (most recent call last): File "/home/ubuntu/yjh/DUSt3R-to-COLMAP/./dust3r_inference.py", line 5, in import dust3r2colmap as dc ModuleNotFoundError: No module named 'dust3r2colmap'
解决方案: 在脚本中动态添加dust3r2colmap.py所在的目录到sys.path,让Python知道去哪里寻找该模块
import sys \n sys.path.append('dust3r2colmap.py所在路径')
2. >> Loading a list of 0 images Traceback (most recent call last): File "/home/ubuntu/yjh/DUSt3R-to-COLMAP/./dust3r_inference.py", line 68, in scene = dc.train(model_path, image_files, args) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/ubuntu/yjh/DUSt3R-to-COLMAP/src/dust3r2colmap.py", line 67, in train images = load_images(image_files, size=512) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/ubuntu/yjh/DUSt3R-to-COLMAP/./dust3r/dust3r/utils/image.py", line 125, in load_images assert imgs, 'no images foud at '+root ^^^^ AssertionError: no images foud at
解决方案: 保证数据集在路径'./data/images/'下,此外保证import_train_images()函数中所写的图像后缀与你的数据集中的图像格式保持一致

训练结果在本地数据集上很差,除基本轮廓外,房间内部情况没有建出,效果较差。