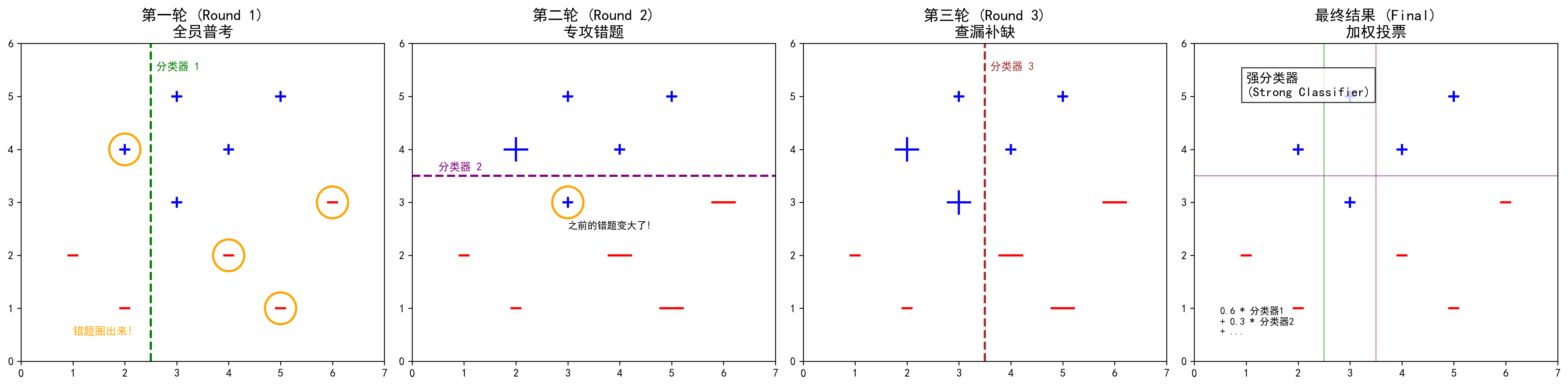
图解说明:
- 🔵 蓝色加号 (+):代表正类样本(比如"猫")。
- 🔴 红色减号 (-):代表负类样本(比如"狗")。
- 🟠 橙色圆圈:代表上一轮做错的题,本轮被"放大"(权重增加)。
- 📏 虚线:代表每一轮的分类器(同学)画出的分界线。
机器学习界的一位"励志大师"------Adaboost。
它的全称是 Adaptive Boosting (自适应增强)。听起来很技术流,但它的核心思想其实就是我们学生时代最熟悉的战术:"刷错题"。
如果你完全不懂算法,没关系。想象一下,你是一个班级的班主任,你的目标是让全班同学在期末考试中拿高分。
1. 它是怎么工作的?(举个栗子)
假设我们要解决一个很难的分类问题(比如区分一张照片是"猫"还是"狗")。
单个同学(我们叫他"弱分类器")可能不太聪明,准确率只有 60%,勉强及格。
- 同学 A 擅长看耳朵(尖的是猫,圆的是狗)。
- 同学 B 擅长看胡须。
- 同学 C 擅长看眼睛。
Adaboost 的策略不是只指望某一个尖子生,而是把这群普通学生组织起来,变成一个超级学霸。
2. Adaboost 的"三步走"战略
第一轮:全员普考
首先,让同学 A 去做所有的题目。
结果他做对了一部分,但也做错了一部分(比如把折耳猫认成了狗)。
这时候,Adaboost 就像严厉的老师,它拿出一支红笔,把同学 A 做错的那些题 圈出来,并且加粗、放大。
- 潜台词:"下一轮考试,谁能把这些错题做对,谁就是英雄!"
第二轮:专攻错题
接着,让同学 B 上场。
同学 B 在做题的时候,会特别关注 那些被红笔圈出来的"难题"。
因为这些题分值变高了,做对这些题能拿高分。
结果,同学 B 成功攻克了折耳猫的问题,但他可能又在其他简单题上犯了错。
Adaboost 再次拿起红笔,把同学 B 做错的题 (以及之前 A 也没做对的顽固题)再次加粗、放大。
第三轮:查漏补缺
让同学 C 上场,重点攻克那些前两个人都没搞定的"变态题"。
...以此类推,经过好几轮(比如 10 轮、50 轮)。
最后一步:组团出道 (加权投票)
现在我们有了 A、B、C... 等一堆同学。怎么得出最终答案?
大家一起投票!
但是,不是一人一票。
- 同学 A 第一轮表现不错,准确率高,他的话语权(权重)就大,比如他一票顶 2 票。
- 同学 B 表现一般,他一票顶 1 票。
- 同学 C 表现较差,他一票顶 0.5 票。
最终,遇到一张新照片,大家根据自己的权重投票,票数多的就是最终结果。
3. 核心秘密:两个"权重"
Adaboost 的精髓就在于它一直在调整两个东西:
-
数据的权重 (Data Weights):
- 做错的题,权重变大(下次重点关注)。
- 做对的题,权重变小(已经会了,不用太操心)。
- 这就是"Adaptive (自适应)"的含义:根据上一轮的表现,自动调整下一轮的关注点。
-
分类器的权重 (Classifier Weights):
- 表现好的同学,说话分量重。
- 表现差的同学,说话分量轻。
4. Adaboost 的优缺点
✅ 优点 (为什么它很强?)
- 精度高:它能把一堆"臭皮匠"(弱分类器)变成一个"诸葛亮"(强分类器),分类效果通常非常好。
- 不容易过拟合:虽然它很努力,但它不容易死记硬背。
- 简单灵活:里面的"同学"可以是各种简单的算法(通常用简单的决策树)。
❌ 缺点 (也要注意)
- 怕噪声 :如果数据里有一些根本就是错的标注(比如把一张狗的照片标成了猫),Adaboost 会拼命想把这道"错题"做对,结果钻了牛角尖,导致整体效果变差。
- 训练慢:因为它是一轮一轮串行训练的(必须等 A 考完,B 才能考),没法像随机森林那样大家同时开工。
5. 总结
Adaboost 就是一个死磕错题的学霸养成计划:
- 第一步:先试考一次。
- 第二步:把做错的题加权(放大),让下一个人重点学。
- 第三步:重复多次,每次都盯着错题打。
- 最后:把所有人的意见加权融合。
它告诉我们一个道理:失败不可怕,可怕的是不从失败中学习。只要盯着错误不断修正,普通人也能组合成超级英雄! 🚀