目录
[1. awk使用方式:](#1. awk使用方式:)
[2. awk内部相关变量:](#2. awk内部相关变量:)
[3. awk工作原理:](#3. awk工作原理:)
[4. awk变量定义:](#4. awk变量定义:)
[5. awk中BEGIN...END使用:](#5. awk中BEGIN...END使用:)
[6. awk和正则的综合运用:](#6. awk和正则的综合运用:)
[1. grep工具(行过滤):](#1. grep工具(行过滤):)
一、awk介绍
awk是一种编程语言,主要用于在linux/unix下对==文本和数据==进行处理,是linux/unix下的一个工具。数据可以来自标准输入、一个或多个文件,或其它命令的输出。
awk的处理文本和数据的方式:逐行扫描文件,默认从第一行到最后一行,寻找匹配的==特定模式==的行,并在这些行上进行你想要的操作。
awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Brian
Kernighan、Peter Weinberger。
gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展。
下面介绍的awk是以GNU的gawk为例的,在linux系统中已把awk链接到gawk,所以下面全部以awk进行介绍。
1. awk使用方式:
命令模式语法:
awk 选项 'commands' 文件名
常用选项:
-F 定义字段分割符号,默认的分隔符是空格
-v 定义变量并赋值
//以:分隔打印第一和第二列
awk -F: '{print 1,2}' 文件名称
//以:分隔包含root关键字的第一、第二列
awk -F: '/root/{print 1,2}' 文件名称
//以:分隔以root开始的第一、第二列
awk -F: '/^root/{print 1,2}'// 文件名称
//多分隔符
awk -F :/#
脚本模式:
脚本执行
方法1:
awk 选项 -f awk的脚本文件 要处理的文本文件
awk -f awk.sh filename
sed -f sed.sh -i filename
脚本编写
#!/bin/awk 定义魔法字符
以下是awk引号里的命令清单,不要用引号保护命令,多个命令用分号间隔
BEGIN{FS=":"}
NR==1,NR==3{print 1"\\t"2}
2. awk内部相关变量:
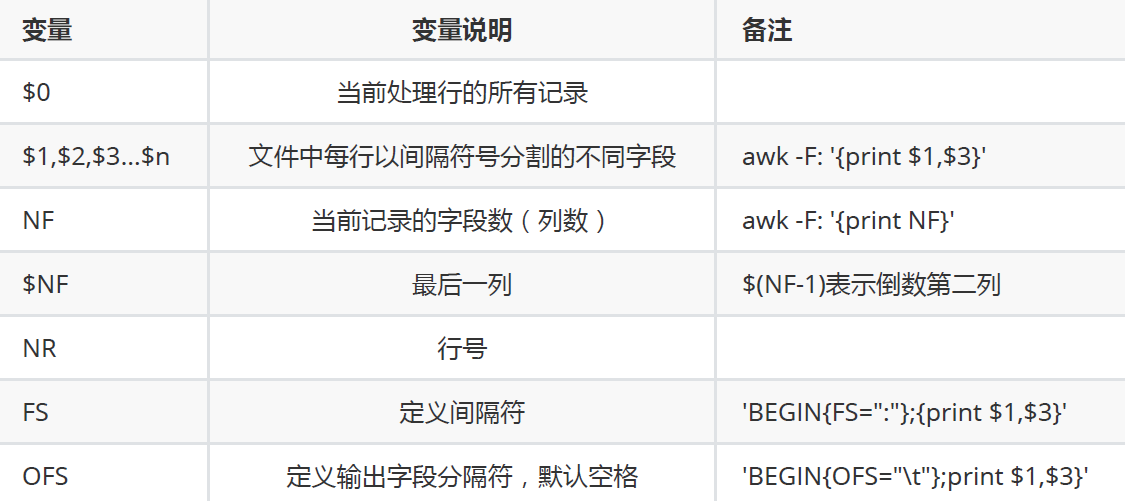
示例1:

示例2:
FS和OFS:

格式化输出print 和printf
print函数 : 标准化输出,输出完换行
printf函数 : 格式化输出,输出完不换行

%s 字符类型 strings %-20s
%d 数值类型
占15字符
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加\n
3. awk工作原理:
awk -F: '{print 1,3}' /etc/passwd
-
awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符结束。
-
每行被间隔符==:==(默认为空格或制表符)分解成字段,每个字段存储在已编号的变量中,从$1开始。
问:awk如何知道用空格来分隔字段的呢?
答:因为有一个内部变量==FS==来确定字段分隔符。初始时,FS赋为空格
-
awk使用print函数打印字段,打印出来的字段会以==空格分隔==,因为1,3之间有一个逗号。逗号比较特殊,它映射为另一个内部变量,称为==输出字段分隔符==OFS,OFS默认为空格。
-
awk处理完一行后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程将持续到所有行处理完毕。
4. awk变量定义:

5. awk中BEGIN...END使用:
①==BEGIN==:表示在程序开始前执行
②==END== :表示所有文件处理完后执行
③用法: 'BEGIN{开始处理之前};{处理中};END{处理结束后}'
示例:
- 打印最后一列和倒数第二列(登录shell和家目录)
awk -F: 'BEGIN{ print "Login_shell\t\tLogin_home\n*******************"};{print NF"\\t\\t"(NF-1)};END{print "************************"}' 文件名称
awk 'BEGIN{ FS=":";print "Login_shell\tLogin_home\n*******************"};{print
NF"\\t"(NF-1)};END{print "************************"}' 文件名称
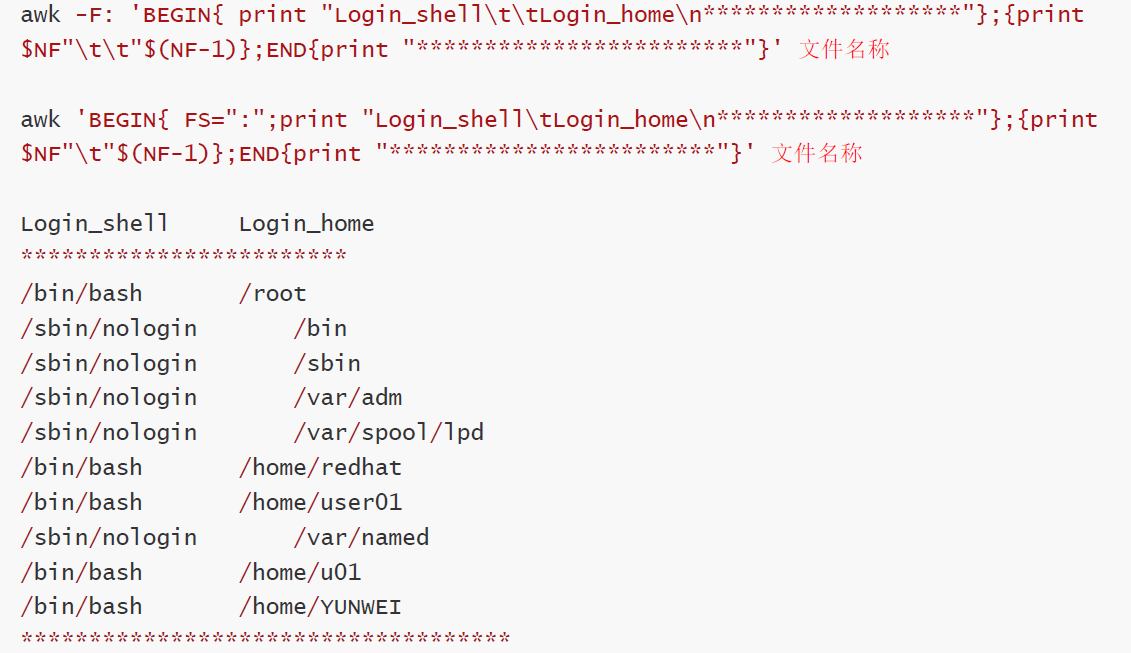
- 打印/etc/passwd里的用户名、家目录及登录shell
awk -F: 'BEGIN{OFS="\t\t";print"u_name\t\th_dir\t\tshell\n***************************"} {printf "%-20s %-20s %-20s\n",1,(NF-1),$NF};END{print "****************************"}'
awk -F: 'BEGIN{print "u_name\t\th_dir\t\tshell" RS "*****************"} {printf "%-15s %-20s %-20s\n",1,(NF-1),$NF}END{print "***************************"}' /etc/passwd
格式化输出:{printf "%-15s %-20s %-20s\n",1,(NF-1),$NF}

6. awk和正则的综合运用:
示例:
从第一行开始匹配到以lp开头行
awk -F: 'NR==1,/^lp/{print $0 }' passwd

从第一行到第5行
awk -F: 'NR==1,NR==5{print $0 }' passwd

从以lp开头的行匹配到第10行
awk -F: '/^lp/,NR==10{print $0 }' passwd
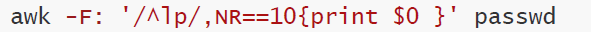
从以root开头的行匹配到以lp开头的行
awk -F: '/^root/,/^lp/{print $0}' passwd
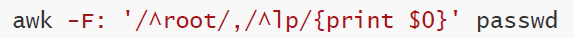
打印以root开头或者以lp开头的行
awk -F: '/^root/ || /^lp/{print $0}' passwd
awk -F: '/^root/;/^lp/{print $0}' passwd
grep -E '^root|^lp' (grep正则)

显示5-10行
awk -F':' 'NR>=5 && NR<=10 {print $0}' /etc/passwd
awk -F: 'NR<10 && NR>5 {print $0}' passwd 
列出uid在0-20之间的用户信息
awk -F: '3\>=0 \&\& 3 <= 20{print $0}' /etc/passwd

列出uid是0或者14的用户信息
awk -F: '3==0 \|\| 3 == 14{print $0}' /etc/passwd

列出第7列不以nologin结尾的正行内容
awk -F: '7!\~/nologin/{print $0}' /etc/passwd

列出第3列的值不等于38的正行内容
awk -F: '3!=38{print 0}' /etc/passwd

打印奇数行
awk -F: 'NR%2==1{print $0}' /etc/passwd

打印30-39行以bash结尾的内容:
awk 'NR>=30 && NR<=39 && /bash/{print 0}' passwd
awk 'NR>=3 && NR<=8 && /bash$/' 文件名称

理解;号和||的含义:
awk 'NR>=3 && NR<=8 || /bash$/' 文件名称
awk 'NR>=3 && NR<=8;/bash$/' 文件名称

二、正则表达式
1. grep工具(行过滤):
grep用于根据关键字进行行过滤
grep options 'keys' filename
OPTIONS:
-i: 不区分大小写
-v: 查找不包含指定内容的行,反向选择
-w: 按单词搜索、精准匹配
-c: 统计匹配到的次数
-n: 显示行号
^key:以关键字开头
key$:以关键字结尾
^$:匹配空行
示例:
grep -i root passwd 忽略大小写匹配包含root的行
grep -w ftp passwd 精确匹配ftp单词
grep -c root passwd 匹配次数
grep -c 'bash$' passwd 统计以bash结尾的行数
grep -n root passwd 打印匹配到root关键字的行号
grep -ni root passwd 忽略大小写匹配统计包含关键字root的行
grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数
grep -i ^root passwd 忽略大小写匹配以root开头的行
grep bash$ passwd 匹配以bash结尾的行
grep -n ^$ passwd 匹配空行并打印行号
grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行
grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行
2.正则表达式应用:
正则表达式(Regular Expression、regex或regexp,缩写为RE),也译为正规表示法、常规表示法,是一种字符模式,用于在查找过程中匹配指定的字符。
许多程序设计语言都支持利用正则表达式进行字符串操作。正则表达式这个概念最初是由Unix中的工具软件(例如se,grep,awk)普及开的。
元字符 :指那些在正则表达式中具有特殊意义的专用字符,如:点(.) 星(*) 问号(?)等
前导字符:即位于元字符前面的字符 abc* aooo.
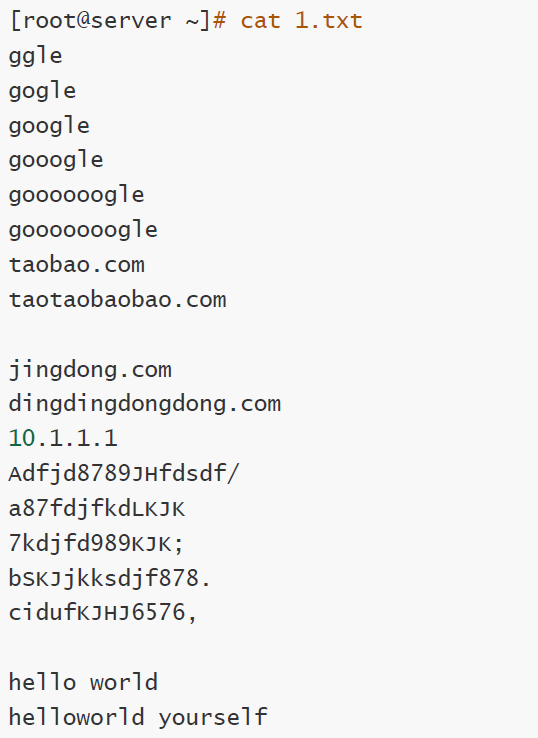
可以新建文本文件,用来测试
#标准正则概念解释


#举例
grep 'go.' 1.txt
grep 'goo.*' 1.txt
grep 'abc' 1.txt
grep '\^abc' 1.txt
grep '^abc' 1.txt
grep '^\^abc' 1.txt
grep '\<hello' 1.txt
grep 'word>\' 1.txt
grep '\<world\>' 1.txt
grep -w 'world' 1.txt
grep 'go\{2\}' 1.txt
grep 'go\{2,\}' 1.txt
grep 'go\{2,3\}' 1.txt
grep '0-9' 1.txt
grep -P '\d' 1.txt
grep 'a-zA-Z0-9_' 1.txt
grep -P '\w' 1.txt
#扩展正则表达式 grep -E 或 egrep
#扩展正则表达式元字符

举例
egrep 'go+' 1.txt
grep -E 'go+' 1.txt
egrep 'go?' 1.txt
egrep '^go|world' 1.txt
egrep '(go)+' 1.txt
egrep '(taobao|jingdong).com' 1.txt
egrep 'go{2}' 1.txt
egrep 'go{2,3}' 1.txt

匹配IP地址
grep '0-9\{1,3\}\.0-9\{1,3\}\.0-9\{1,3\}\.0-9\ {1,3\}' 1.txt
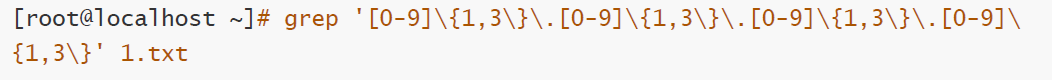
egrep '0-9{1,3}\.0-9{1,3}\.0-9{1,3}\.0-9{1,3}' 1.txt
egrep '(0-9{1,3}\.){3}0-9' 1.txt
grep -P '\d{1,3}\.\d{1,3}\.\d{1,3}\.\d' 1.txt
grep -P '(\d{1,3}\.){3}\d' 1.txt
