前言:为什么需要 I/O 多路复用?
在写网络程序时,我们常常面临一个基本问题:
如何同时监听多个 socket 的可读/可写事件?
最朴素的做法是为每个连接开一个线程(或进程),但线程创建和上下文切换成本太高,尤其在 C10K(1 万并发)甚至 C100K 场景下几乎不可行。
于是,I/O 多路复用 (I/O Multiplexing)应运而生:用单个线程监控多个文件描述符(fd),当其中任意一个就绪时,通知应用程序进行处理。
Linux 提供了三种主要机制:
selectpollepoll
它们的目标一致,但实现方式和性能表现天差地别。
我们之前学习了select函数,用以实现一个基本的多路转接模型:
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);使用步骤:
- 初始化
fd_set集合(用FD_ZERO,FD_SET) - 调用
select阻塞等待 - 返回后遍历所有 fd,用
FD_ISSET检查是否就绪
但是使用select函数,暴露出了一些缺陷:
-
fd 数量限制
fd_set通常用位图实现,默认最大支持 1024 个 fd (由FD_SETSIZE宏定义)。虽然可通过重新编译内核修改,但不现实。 -
每次调用都要传递全部 fd 集合
内核不知道哪些 fd 是"新加入"的,所以用户必须每次把完整的 fd 集合拷贝到内核。当连接数大时,拷贝开销巨大。
-
线性扫描所有 fd
select返回后,应用程序必须遍历 0~nfds-1 所有 fd 来检查状态,时间复杂度 O(n)。即使只有 1 个 fd 就绪,也要扫 10000 次。
举个例子:你告诉邮局"我订阅了 10000 个信箱",每次取信都要把全部信箱编号列一遍,然后邮递员挨个检查哪个有信------效率极低。
因此,我们后面又引入了poll,作为一个select的改进策略:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd; // 文件描述符
short events; // 关心的事件(POLLIN, POLLOUT)
short revents; // 实际发生的事件
};他改进了什么呢?
- 突破 1024 限制 :
pollfd是数组,理论上只受内存限制 - 更清晰的事件表示 :用
events/revents字段分离"关注"和"发生",导致不再需要每次都遍历一遍进行初始化
但关键的几个问题仍然存在:
- 仍需每次传递整个 fds 数组到内核 → 拷贝开销
- 返回后仍需遍历所有 fd → O(n) 扫描
- 没有状态记忆:内核不记录你关心哪些 fd,每次都是"全新开始"
所以poll函数也并未解决核心性能瓶颈
今天,我们就紧接着前面的知识点,来学习一下,epoll函数模型,希望对大家有所帮助!
由于篇幅过长,所以我选择将文章分为两部分,第一部分,也就是本文,主要给大家讲一下epoll的概念定义,参数,以及带着大家回顾一下内核的相关代码帮助理解epoll模型。
第二篇文章,就主要将视角集中在代码上,带着大家写一遍相关代码进行巩固,以及回答一下理论阶段解决不了的问题。
一、epoll接口详解
epoll 是 Linux 2.6+ 特有的机制,专为海量并发连接 设计。它的名字意为 "event poll ",核心思想是:内核维护一个"兴趣列表",只通知真正就绪的 fd。
按照man手册的说法,epoll是一个为了处理大批量的句柄而作了改进的poll函数。
其具备了之前所说的一切优点,被公认为Linux2.6下,性能最好的多路I/O就绪通知方法。
不同于之前两个函数,epoll不是单个的函数,而是三个函数的组合,分别为:
c++
#include <sys/epoll.h>
int epoll_create(int size); // 创建 epoll 实例
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 注册/修改/删除 fd
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // 等待事件再具体讲之前,我们要先明确这个函数的定位,epoll应该是多个fd的IO事件的等待机制,用于实现一个事件派发的作用。
1. epoll_create():
epoll_create 是使用 epoll 的第一步,它在内核中创建了一个**epoll 实例**,你可以将其视为一个事件管理器。
c
int epoll_create(int size);-
size:在 Linux 2.6.8 之后,这个参数已经被内核忽略,但它必须是一个大于零的值,历史上用于提示内核应该预分配多大的空间。 -
返回值
epfd:返回一个文件描述符(Epoll Fd) 。如果我们想要找到我们创建的这个epoll实例,就需要通过这个 int 的返回值来寻找,并且后续所有的操作(添加、等待)都将通过这个epoll描述符进行。
核心原理:
epoll_create在内核中开辟了一个空间,用来存放你关注的所有文件描述符,这通常通过一个红黑树(Red-Black Tree) 来实现。
2. epoll_ctl():
epoll_ctl 是 epoll 的控制接口 ,用于向内核中的 epoll 实例添加、修改或删除你想要监听的文件描述符(fd)。
c
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);epfd:epoll_create返回的epoll实例描述符。op:要执行的操作类型,通常是以下三个宏之一。fd:目标文件描述符(你要监听的 Socket)。event:指向struct epoll_event结构体,用于定义你对fd关心的事件。
宏:
EPOLL_CTL_ADD:向epfd实例中注册 一个新的fd。EPOLL_CTL_MOD:修改 已注册fd的监听事件(例如,从只监听读事件修改为监听读写事件)。EPOLL_CTL_DEL:从epfd实例中删除 一个fd。
我们需要知道的是,不管是select还是poll,在函数调用的时候,其实完成的比较核心的工作就是用户告诉内核,而在其函数返回时是内核告诉用户。
但是epoll却是在调用epoll_wait的时候才进行用户告诉内核,在调用_ctl的时候只是让用户告诉内核我要关注那些事件,所以epoll不仅学习poll,将输入输出参数进行了分离,也把功能进行了分离
我们再来看一下新出现的这个结构体:struct epoll_event,其内部成员又涉及到了联合体union epoll_data,可谓是环环相扣:
c
typedef union epoll_data {
void *ptr;
int fd; // 承载文件描述符
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll 事件(如 EPOLLIN, EPOLLOUT) */
epoll_data_t data; /* 用户自定义数据(通常存放 fd 或自定义指针) */
};结合之前所学的几个函数,我们可以明白uint32_t events参数,其实就是一个宏,告诉内核我们想要关心的是哪些事件。
那么data参数呢?
在 select 和 poll 中,当函数返回事件就绪时,你只知道是第 iii 个 位图位或数组元素就绪了,你还需要根据这个 iii 去查找对应的文件描述符 fd。
而 epoll_event 结构体的 data 成员,就是用来解决这个问题的------它允许你将文件描述符本身 或与该 fd 相关的上下文数据直接绑定到事件结构中。
| 成员名称 | 类型 | 主要用途 | 描述 |
|---|---|---|---|
fd |
int |
最常用 。直接存储监听的文件描述符。 | 当 epoll_wait 返回时,你可以立即通过 event.data.fd 知道是哪个 fd 就绪,无需再次遍历或查找。 |
ptr |
void* |
更高阶用法 。存储指向自定义结构体的指针。 | 允许你将连接的所有状态信息(如缓冲区、对端地址、用户ID等)封装在一个结构体中,然后将指针存在这里。事件就绪时,你可以直接获取整个连接的上下文,这是高性能网络库(如 Libevent, Nginx)常用的模式。 |
u32 / u64 |
uint32_t / uint64_t |
备用。存储 32 位或 64 位无符号整数。 | 用于存储其他 ID 或标志,例如唯一的会话 ID。 |
其最重要的作用,就是消除了繁杂的查找消耗的时间。
正是这个 data 联合体的设计,让 epoll_wait 的效率能够从 O(N)O(N)O(N) 降低到 O(K)O(K)O(K)(其中 NNN 是监听总数,KKK 是就绪数量)。
-
在
epoll_ctl(ADD/MOD) 时 :你将fd或指向其上下文的ptr填充到epoll_event结构体中,然后传给内核。 -
在
epoll_wait返回时 :内核直接将该就绪事件对应的整个struct epoll_event(包括你之前存入的data)拷贝到用户态。 -
事件处理 :你只需要读取
events[i].data.fd或events[i].data.ptr,就能立即开始处理数据,而不需要再进行一次遍历查找。
3. epoll_wait():等待就绪事件
epoll_wait 是 epoll 实现高性能的关键所在。它等待内核通知,直到监听到有文件描述符上的事件发生。
c
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);| 参数 | 描述 |
|---|---|
epfd |
epoll 实例描述符。 |
events |
输出参数 :指向一个由用户分配的 struct epoll_event 数组的指针。内核只将就绪的事件拷贝到这个数组中。 |
maxevents |
events 数组的大小(即最多可以接收多少个就绪事件)。 |
timeout |
超时时间(毫秒,ms)。-1 表示永久阻塞,0 表示非阻塞。 |
| 返回值 | 就绪的事件数量。如果超时,返回 000。 |
核心优势------O(1)O(1)O(1) 效率:
epoll在内核中维护了一个就绪列表(Ready List) ,通常通过一个双向链表 实现。当某个fd上的事件真正发生时,内核会直接将其添加到这个就绪列表中。
epoll_wait的工作就是直接从这个链表中取出数据 ,并拷贝到用户提供的events数组中。因此,无论你监听了 NNN 个连接,只要有 KKK 个连接就绪,epoll_wait的时间复杂度就接近于 O(K)O(K)O(K),而在 K≪NK \ll NK≪N 的情况下,性能是极高的。
4.Epoll 的两大触发模式
epoll 还引入了两种可选的事件触发模式(两种模式我们后面会具体讲解),这是 select/poll 所不具备的:
| 模式 | 宏名称 | 描述 | 行为特点 |
|---|---|---|---|
| 电平触发(Level Triggered, LT) | (默认) | 如果文件描述符上存在 事件(例如,还有数据可读),epoll_wait 会持续通知你。 |
类似于 select/poll,更健壮、不易出错。 |
| 边沿触发(Edge Triggered, ET) | EPOLLET |
只有当状态发生变化 时(例如,从"不可读"变为"可读"),epoll_wait 才通知你一次。 |
高性能模式,要求用户必须一次性读完所有数据,否则内核不会再次通知,适用于非阻塞 I/O。 |
epoll 通过内核红黑树管理兴趣列表 、内核就绪列表通知活跃事件 ,成功实现了对大规模并发连接的 O(1)O(1)O(1) 效率处理。
重谈网络内核过程
从进程创建到套接字创建
讲完了epoll的三个接口,为了方便大家理解,我们继续重谈一下一个网络报文从网卡到应用层中的一些细节。
网络以mac帧的形式把数据交给我的主机(网卡),网卡收到后,会发送硬件中断执行中断向量表中的数据读取功能。这就是把数据从网卡搬到内存的一个操作。
之后,就会开始一系列的解包工作,比如IP层与TCP层的解包,如果是TCP报文,就将解包好的信息存放到TCP的缓冲区中,至此,应用层就可以读取内容了。
!\[Pasted image 20251225215557.png]
!\[Pasted image 20251225215918.png]
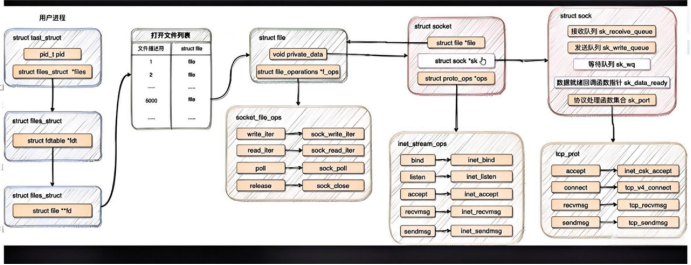
我们打开一个应用程序,其实就是新建了一个或者多个进程,在操作系统内核中会创建一个进程类对象,也就是task_struct结构体:
c
struct task_struct {
volatile long state; // 进程当前状态:运行、睡眠、僵尸等
pid_t pid; // 进程 ID(唯一标识)
pid_t tgid; // 线程组 ID(同一进程内所有线程共享)
char comm[TASK_COMM_LEN]; // 进程名,例如 "bash" 或 "firefox"
struct task_struct *parent; // 指向父进程的指针
struct list_head children; // 子进程链表头(用于遍历所有子进程)
struct list_head sibling; // 兄弟节点(挂入父进程的 children 链表)
struct mm_struct *mm; // 指向用户空间内存描述符(虚拟地址空间)
// 内核线程该字段为 NULL
struct files_struct *files; // 打开的文件描述符表
const struct cred *cred; // 进程凭证:用户 ID(UID)、组 ID(GID)、权限等
int prio; // 动态优先级(调度器使用)
int static_prio; // 静态优先级(nice 值映射而来)
struct sched_class *sched_class; // 所属调度类(如 CFS、实时调度等)
struct list_head run_list; // 用于挂入调度器的运行队列
unsigned int flags; // 进程标志,如 PF_KTHREAD(表示是内核线程)
struct thread_struct thread; // CPU 相关状态(上下文切换时保存寄存器)
// ... 其他字段(教学中通常不深入)
};其中大部分字段我们之前应该都有所了解,包括作为虚拟内存空间重要组成的字段mm_struct指针。
但我们今天要回顾的主题不是这个,大家可以看见,里面有一个字段是:struct files_struct *files。
这个是我们这个进程的文件描述符表结构:
c
// 在 include/linux/fdtable.h 和 fs/file.c 中
struct files_struct {
atomic_t count; // 引用计数
struct fdtable __rcu *fdt; // 当前文件描述符表
struct fdtable fdtab; // 基础文件描述符表
// 文件描述符表的位图管理
unsigned int next_fd; // 下一个可用的文件描述符
unsigned long close_on_exec_init[1]; // exec()时关闭的文件描述符位图
unsigned long open_fds_init[1]; // 已打开文件描述符位图
struct file __rcu * fd_array[NR_OPEN_DEFAULT]; // 默认文件指针数组
};
struct fdtable {
unsigned int max_fds; // 当前表能容纳的最大文件描述符数
struct file __rcu **fd; // 指向文件对象的指针数组
unsigned long *close_on_exec; // exec时关闭的fd位图
unsigned long *open_fds; // 已打开fd位图
unsigned long *full_fds_bits; // 完整的位图
struct rcu_head rcu; // RCU回调
};通过这个表,我们就能查找对应文件描述符的file结构体对象,大概的过程就是这样的:
步骤1:获取当前进程的 files_struct
c
struct task_struct *current = ...;
struct files_struct *files = current->files;步骤2:获取当前的文件描述符表
c
struct fdtable *fdt;
rcu_read_lock();
fdt = rcu_dereference(files->fdt); // 使用RCU保护步骤3:验证和查找
c
struct file *lookup_fd(unsigned int fd)
{
struct files_struct *files = current->files;
struct fdtable *fdt;
struct file *file = NULL;
if (fd >= rlimit(RLIMIT_NOFILE)) // 检查资源限制
return NULL;
rcu_read_lock();
fdt = rcu_dereference(files->fdt);
// 边界检查
if (fd < fdt->max_fds) {
// 检查位图确认fd已打开
if (test_bit(fd, fdt->open_fds)) {
// 核心查找:数组索引访问
file = rcu_dereference(fdt->fd[fd]);
if (file) {
// 增加引用计数
if (unlikely(!get_file_rcu(file)))
file = NULL;
}
}
}
rcu_read_unlock();
return file;
}
// 完整的查找函数我们说linux下一切皆文件,所以文件描述符自然也是一个file对象,一个file的定义通常是这样:
c
struct file {
// 指向文件操作函数集合(如 read, write, mmap 等)
const struct file_operations *f_op;
// 指向该文件对应的 inode(代表磁盘上的实际文件)
struct inode *f_inode;
// 当前文件的读写偏移量(即 "文件指针")
// 多个进程打开同一文件时,各自拥有独立的 f_pos
loff_t f_pos;
// 文件的访问模式和状态标志
// 例如:O_RDONLY, O_WRONLY, O_RDWR, O_APPEND, O_NONBLOCK 等
unsigned int f_flags;
// 指向私有数据(由具体文件系统或驱动使用)
void *private_data;
// 引用计数(通常通过 get_file()/fput() 管理)
atomic_long_t f_count;
// 文件所属的挂载文件系统实例
struct path f_path; // 包含 dentry 和 vfsmount
// ... 其他字段(如 f_mode, f_version 等,教学中较少强调)
};这里面有一个非常重要的参数,就是void* private,注意这可是void* 类型的指针代表着其可以通过强制类型转换指向任意类型的数据。
我们的网络有关的socket结构体自然也是其中的一员。
我们在讲套接字的时候应该是提了socket结构体:
c
struct socket {
// 套接字状态(如 SS_UNCONNECTED, SS_CONNECTING, SS_CONNECTED, SS_DISCONNECTING)
socket_state state;
// 套接字类型:SOCK_STREAM(TCP)、SOCK_DGRAM(UDP)、SOCK_RAW 等
short type;
// 指向更底层的传输层控制块(如 struct tcp_sock 或 udp_sock)
// 这是实现协议细节的关键
struct sock *sk;
// 指向该 socket 对应的文件对象(因为 socket 被当作文件处理)
struct file *file;
// 协议族:AF_INET(IPv4)、AF_INET6(IPv6)、AF_UNIX 等
short family;
// 套接字操作函数集合(类似 file_operations)
const struct proto_ops *ops;
// 标志位(如是否是非阻塞、是否已监听等)
unsigned long flags;
};可以看到,socket套接字中也含有一个file指针,也就是说,这两个结构体是互相指着对方的,这使得socket可以像文件一样被操作。
而socket中还有一个十分重要的字段,就是struct sock *sk,sk这个字段我们在讲全连接队列的时候说过,它是 Linux 内核网络子系统中 最核心、最底层的传输层套接字控制块指针 。它是 struct socket(面向用户 API 的套接字抽象)与具体网络协议(如 TCP、UDP、RAW IP)实现之间的桥梁。
c
struct sock {
// 网络协议族(AF_INET, AF_INET6 等)
__u16 sk_family;
// 套接字类型(SOCK_STREAM, SOCK_DGRAM)
__u16 sk_type;
// 协议号(IPPROTO_TCP, IPPROTO_UDP)
__u8 sk_protocol;
// 当前状态(对 TCP 而言:TCP_ESTABLISHED, TCP_LISTEN...)
__u8 sk_state;
// 引用计数
atomic_t sk_refcnt;
// 指向所属的 struct socket(反向指针)
struct socket *sk_socket;
// 接收缓冲区(sk_buff 队列)
struct sk_buff_head sk_receive_queue;
// 发送缓冲区(sk_buff 队列)
struct sk_buff_head sk_write_queue;
// 本地地址(源 IP + 端口)
__be32 sk_rcv_saddr; // 本地 IPv4 地址(接收时绑定的)
__be32 sk_daddr; // 对端 IPv4 地址
__be16 sk_num; // 本地端口(主机字节序)
__be16 sk_dport; // 对端端口(网络字节序)
// 套接字选项(如 SO_REUSEADDR, SO_KEEPALIVE)
unsigned int sk_reuse:2;
unsigned int sk_reuseport:1;
unsigned int sk_shutdown:2;
// 指向协议特定的私有数据(如 tcp_sock、udp_sock)
void *sk_protinfo;
// 协议操作函数集合(如 tcp_prot、udp_prot)
const struct proto *sk_prot;
// 网络命名空间
struct net *sk_net;
// 错误码(如 ICMP 错误、连接拒绝等)
int sk_err;
// 接收/发送缓冲区大小限制
__u32 sk_rcvbuf;
__u32 sk_sndbuf;
// ... 大量其他字段(拥塞控制、安全上下文、时间戳等)
};套接字之间的层级关系
我们可以看见sock中有很多的重要字段,包括接收发送缓冲区的存在,继续探讨下去我们还会发现有很多的指针分别指向缓冲区的首尾这些,但我们这里就不沿着深入了。
我们要说的是,我们的tcp套接字,udp套接字与底层的这个sock结构的联系:
在 Linux 内核网络栈中,struct sock 是所有传输层套接字的通用基类 ,而 inet_sock、inet_connection_sock、tcp_sock 等是其逐层特化的子结构体,用于表示不同协议(如 TCP/UDP)所需的额外状态字段。
这种设计采用了 C 语言模拟面向对象"继承" 的经典模式:子结构体将父结构体作为第一个成员,从而可以安全地进行指针类型转换。
struct sock
↑
struct inet_sock // 所有 IPv4/IPv6 协议共用(TCP/UDP/RAW)
↑
struct inet_connection_sock // 面向连接的协议(如 TCP、SCTP)
↑
struct tcp_sock // TCP 协议专属这里有个关键规则 :每个子结构体的第一个字段必须是其直接父结构体。
这使得
(struct sock *)sk == (struct inet_sock *)sk == (struct tcp_sock *)sk在地址上完全等价。
1. struct sock ------ 通用套接字基类
- 定义于
include/net/sock.h - 包含所有协议共有的字段:
sk_state(连接状态)sk_receive_queue/sk_write_queuesk_refcntsk_prot(协议操作集)- 基础地址字段(但无 IP/端口细节)
所有套接字(包括 AF_UNIX、AF_PACKET)都基于
sock。
2. struct inet_sock ------ 网络层(IP)增强
-
定义于
include/net/inet_sock.h -
专用于 AF_INET / AF_INET6 协议族(即 IPv4/IPv6)
-
第一个字段是
struct sock,因此是sock的"子类" -
新增字段:
c__be32 inet_daddr; // 对端 IPv4 地址 __be32 inet_rcv_saddr; // 本地接收绑定地址 __be16 inet_dport; // 对端端口(网络字节序) __be16 inet_num; // 本地端口(主机字节序!) u8 inet_tos; // IP TOS 字段 u8 inet_ttl; // IP TTL struct ip_options *inet_opt; // IP 选项(如路由记录) -
适用协议:TCP、UDP、DCCP、SCTP、RAW IP 等所有基于 IP 的协议。
宏
inet_sk(sk)就是(struct inet_sock *)(sk)
3. struct inet_connection_sock(常缩写为 icsk)------ 面向连接协议增强
-
定义于
include/net/inet_connection_sock.h -
专用于需要"连接管理"的协议 (如 TCP、SCTP),不适用于 UDP
-
第一个字段是
struct inet_sock -
新增字段(聚焦连接控制):
cstruct request_sock_queue icsk_accept_queue; // accept 队列(监听 socket 用) u32 icsk_rto; // 重传超时时间(Retransmit Timeout) u32 icsk_ack_timeout; // ACK 超时 const struct tcp_congestion_ops *icsk_ca_ops; // 拥塞控制算法 struct inet_bind_bucket *icsk_bind_hash; // 端口绑定哈希 unsigned long icsk_timeout; // 各种定时器(如 FIN_WAIT_2, TIME_WAIT) -
提供了连接建立、超时、监听队列等通用机制。
宏
inet_csk(sk)就是(struct inet_connection_sock *)(sk)
4. struct tcp_sock(常缩写为 tp)------ TCP 协议专属
-
定义于
include/net/tcp.h -
仅用于 TCP 协议
-
第一个字段是
struct inet_connection_sock -
新增大量 TCP 特有状态:
cu32 snd_wnd; // 发送窗口(对端通告的) u32 rcv_wnd; // 接收窗口(本端通告的) u32 snd_cwnd; // 拥塞窗口(Congestion Window) u32 snd_ssthresh; // 慢启动阈值 u32 rcv_nxt; // 期望收到的下一个序号 u32 snd_nxt; // 下一个要发送的序号 u32 snd_una; // 最早未确认的序号 struct tcp_rtx_queue; // 重传队列(sk_write_queue 的 TCP 特化) u32 tcp_header_len; // TCP 头长度(含选项) int tcp_urg_mode; // 紧急指针处理模式 -
实现了 TCP 的核心逻辑:滑动窗口、拥塞控制、重传、流量控制等。
宏
tcp_sk(sk)就是(struct tcp_sock *)(sk)
类型转换示例(内核代码常见)
c
// 假设 sk 是一个指向 TCP 套接字的 struct sock *
struct sock *sk = ...;
// 安全转换(因为 tcp_sock 第一个字段是 inet_connection_sock,
// 而它第一个字段是 inet_sock,再往上是 sock)
struct inet_sock *inet = inet_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
// 访问不同层级的字段
printk("Local port: %d\n", ntohs(inet->inet_sport)); // 来自 inet_sock
printk("RTO: %u\n", icsk->icsk_rto); // 来自 inet_connection_sock
printk("CWND: %u\n", tp->snd_cwnd); // 来自 tcp_sock协议与结构体对应关系
| 协议类型 | 使用的结构体层级 |
|---|---|
| UDP | struct sock → struct inet_sock |
| TCP | sock → inet_sock → inet_connection_sock → tcp_sock |
| RAW IP | sock → inet_sock |
| Unix Domain | 仅 struct sock(不经过 inet_*) |
注意:UDP 不使用
inet_connection_sock和tcp_sock,因为它无连接。
总的来说:
struct sock:通用基类,所有套接字的根。struct inet_sock:为 IP 协议族(IPv4/IPv6)添加地址和端口字段。struct inet_connection_sock:为面向连接的协议(TCP/SCTP)添加连接管理、定时器、accept 队列等。struct tcp_sock:TCP 协议的完整状态机,包含序号、窗口、拥塞控制等核心字段。
这种分层设计使得 Linux 网络栈既能复用通用逻辑 (如内存管理、队列操作),又能高效支持多种协议,是内核模块化和可扩展性的典范。
内核结构关系图:

再谈epoll
回顾完刚刚的知识,让我们把视角再次移回epoll上。
在我们调用 poll 或 select 时,应用程序需要每次传入一个文件描述符集合(之前的辅助数组),内核会线性遍历这个集合中的每一个 fd,逐个检查其对应的 socket 接收队列中是否有数据。这种"轮询式"检测在连接数很大时效率极低------时间复杂度是 O(N),其中 N 是被监控的 fd 总数。
为了解决这个问题,Linux 提供了 epoll ,它基于一种事件驱动 + 底层回调的机制,彻底避免了无意义的遍历。
具体来说:
-
调用
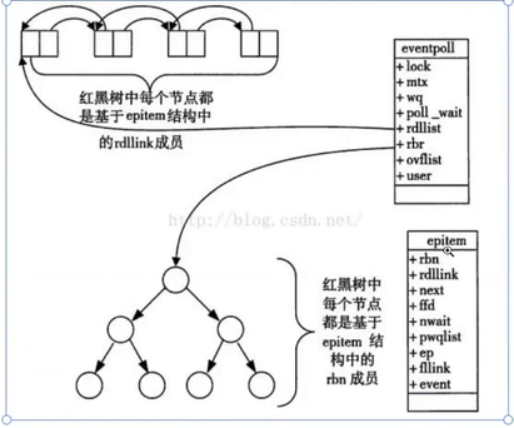
epoll_create()时,内核会创建一个eventpoll对象,其中包含两个关键数据结构:- 一棵红黑树(rb-tree):用于高效管理用户注册的"关心事件"。
- 一个就绪队列(ready list,通常是一个双向链表):用于存放已就绪的事件。
-
每次调用
epoll_ctl(EPOLL_CTL_ADD, fd, &event),内核就会:- 在红黑树中插入一个新节点,该节点包含 fd 和 要监听的事件类型(如 EPOLLIN)。
- 同时,在该 fd 对应的底层文件对象(
struct file)中,注册一个回调函数 (通常是ep_poll_callback)。
这个回调函数之所以能被挂上去,是因为每个
struct file都有一个private_data字段(类型为void *)。虽然private_data通常由文件系统或设备驱动使用,但在 socket 场景下,内核巧妙地利用它来建立 socket ↔ eventpoll 的关联。更准确地说,回调机制是通过struct sock的等待队列(sk_sleep)或struct file的f_op->poll机制间接实现的,最终使得当 socket 状态变化时能通知到 epoll。
-
当网络数据到达(例如 TCP 报文被协议栈处理并放入
sk_receive_queue)时,内核协议栈会主动触发这个回调函数。回调函数的作用就是:- 找到对应的 epoll 实例;
- 将该 fd 的就绪事件(如 EPOLLIN)封装成一个节点;
- 插入到 epoll 的就绪队列中。
-
此后,当用户调用
epoll_wait()时,内核不需要遍历任何 fd 列表,只需检查就绪队列是否为空:- 如果非空,直接将就绪事件批量拷贝到用户空间;
- 如果为空且设置了超时,则可能阻塞等待,直到有事件到来或超时。
因此:
- 注册阶段(
epoll_ctl):操作红黑树,O(log N)。 - 通知阶段:由底层数据到达触发回调,O(1) 插入就绪队列。
- 获取事件阶段(
epoll_wait) :仅需遍历已就绪的事件,时间复杂度为 O(1) 判断是否非空,拷贝到用户态为 O(K),其中 K 是本次就绪的事件数(K ≪ N)。
这整套机制------红黑树管理关注列表 + 就绪队列 + 底层回调通知 ------就构成了 epoll 模型。就是由红黑树来进行关注我们要监视的文件描述符的事件就绪情况,如果就绪了,就把节点插入到队列中,随后从就绪队列中依次处理事件。
它本质上是一种增强版的信号驱动式 I/O(SIGIO) :
而传统 SIGIO 依赖进程注册信号处理函数,而 epoll 将"通知"机制内核化、批量化、可扩展化,避免了信号的不可靠性和上下文切换开销。
补充说明:虽然早期有人将 epoll 与"信号驱动 I/O"类比,但严格来说,epoll 属于 "边缘/水平触发的事件通知机制",并不依赖 UNIX 信号,而是完全在内核 poll 机制框架下实现的高效多路复用。
总结一下:epoll 模型基于三个核心组件来实现高效的I/O多路复用:
-
红黑树(用于管理关注列表):
- 在
epoll中,使用一个内部的数据结构(通常是红黑树)来高效地管理所有被监视的文件描述符(fd)。当调用epoll_ctl()函数添加、修改或删除感兴趣的事件时,相应的文件描述符及其感兴趣的事件类型会被记录在这个数据结构中。这使得对大量文件描述符的操作(如添加和删除)可以保持较高的效率。
- 在
-
就绪队列(用于存储已就绪的文件描述符):
- 当某个被监视的文件描述符上有感兴趣的操作(读/写)变为可用时,该文件描述符会被加入到一个就绪队列中。这个队列包含了所有当前可以进行非阻塞操作的文件描述符。通过调用
epoll_wait()函数,应用程序可以从这个队列中获取所有已经准备好的文件描述符,并对其进行处理。
- 当某个被监视的文件描述符上有感兴趣的操作(读/写)变为可用时,该文件描述符会被加入到一个就绪队列中。这个队列包含了所有当前可以进行非阻塞操作的文件描述符。通过调用
-
底层回调通知机制:
- 这个机制指的是操作系统内核在检测到有文件描述符的状态变化时(例如,socket 上有数据到达),会触发相应的回调函数将对应的文件描述符标记为就绪,并将其加入到上述的就绪队列中。这种方式避免了传统轮询带来的性能损耗,因为只有真正准备好进行I/O操作的文件描述符才会被返回给用户空间的应用程序。
所以,这颗红黑树就相当于我们之前所用到的辅助数组,只不过以前是我们自己实现,现在是内核直接实现了。
我们刚刚说就绪之后会把红黑树的节点插入到就绪队列中,这是如何做到的呢?
不少同学可能会有误解,其实,插入到另外的结构并不代表就会脱离原本的结构。在内核中,一个数据结构的节点并不是只能属于一个数据结构。
一个内核对象(如 epitem、task_struct 等)可以同时属于多个数据结构,而不会"脱离"任何一个。
这是因为 Linux 内核广泛使用了 "嵌入式链表节点" + "container_of 宏" 的设计模式,使得同一个结构体实例可以被多个链表、红黑树、哈希表等同时引用。
以 epoll 中的 epitem 为例
epitem 是 epoll 内部用来表示"一个被监视的文件描述符及其事件"的结构体(定义在 fs/eventpoll.c):
c
struct epitem {
union {
/* 用于挂入 eventpoll 的红黑树 */
struct rb_node rbn;
/* 用于从红黑树中删除时临时链接 */
struct rcu_head rcuhead;
};
/* 用于挂入就绪队列(rdllist) */
struct list_head rdllink;
/* 指向对应的 struct file */
struct file *ffd;
/* 监听的事件 */
struct epoll_event event;
/* 所属的 eventpoll 实例 */
struct eventpoll *ep;
// ... 其他字段
};这里有个关键设计:
rbn:这个epitem作为节点存在于红黑树中。rdllink:同一个epitem也作为节点存在于就绪队列(双向链表)中。
所以它同时属于两个数据结构!
- 当你调用
epoll_ctl(ADD, fd, ...)→ 内核创建一个epitem,插入红黑树(通过rbn)。 - 当 socket 有数据到达 → 回调函数将 同一个
epitem通过list_add_tail(&epi->rdllink, &ep->rdllist)加入就绪队列。 - 调用
epoll_wait()→ 遍历rdllist,取出epitem,拷贝其event给用户。 - 即使该
epitem在就绪队列中,它依然在红黑树里 ,直到你调用epoll_ctl(DEL, fd)才会从红黑树中移除。
所以:"加入就绪队列" ≠ "从红黑树移除"。两者是正交的、并行的组织方式。
类比:task_struct 的多链表归属
c
struct task_struct {
// ...
struct list_head tasks; // 全局进程链表
struct list_head children; // 父进程的子进程链表(作为头)
struct list_head sibling; // 挂入父进程 children 的节点
struct hlist_node pid_links; // PID 哈希表节点
// ...
};- 同一个
task_struct同时:- 在全局
init_task.tasks循环链表中(通过tasks), - 在父进程的
children链表中(通过sibling), - 在 PID 哈希表中(通过
pid_links)。
- 在全局
这就是 Linux 内核"一物多用、高效复用"的设计哲学。
为什么能这样实现呢?
因为内核使用的是 "结构体内嵌链表/树节点",而不是"链表节点包含指针指向对象"!所以我们只需要进行指针的移动就行了。
还有一个问题,红黑树是需要key值的,我们拿什么作为key值呢?答案肯定是:fd。
文件描述符通常被我们用整形来表示,这得天独厚的成为了一种key值。
那么怎么理解epoll_create的返回值是一个文件描述符呢?
答案是,因为我们的file结构体中存在void* private字段,根据这个void* ,我们就可以指向eventpoll结构了。
如何理解epoll的高效
epoll 的高效核心在于事件驱动 + 内核回调机制 。通过 epoll_ctl 注册关注的文件描述符后,内核会在对应 socket 的等待队列中挂载一个回调函数(如 ep_poll_callback)。当网络数据到达、socket 状态变为就绪时,协议栈会自动触发该回调,将对应的事件节点插入到 epoll 实例的就绪队列中。
因此,epoll_wait() 无需像 select/poll 那样轮询所有被监控的 fd,而只需检查就绪队列是否为空------这一操作的时间复杂度为 O(1)。若有就绪事件,内核直接将它们批量返回给用户空间。
整个过程避免了每次系统调用都遍历全部文件描述符的开销,使得性能不再受总连接数 N 的影响,而只与实际就绪的事件数 K 相关。虽然将就绪事件从内核拷贝到用户态的时间复杂度是 O(K)(你提到的"O(N)"应为笔误,实际是 O(K),K ≪ N),但在高并发、低活跃的典型场景下(如 Web 服务器),K 远小于 N,效率极大提升。
正是这种"注册 + 回调 + 就绪通知"的机制,让 epoll 成为支撑百万级并发连接的基石。
结语:从轮询到事件驱动,epoll 如何重塑高并发网络编程
回顾 I/O 多路复用的发展历程,从 select 的位图限制,到 poll 的线性扫描瓶颈,再到 epoll 的事件驱动革命,我们看到的不仅是一组系统调用的演进,更是操作系统对"效率"与"可扩展性"的深刻思考。
epoll 之所以成为现代高性能网络服务的基石,不在于它有多复杂,而在于它精准地将问题解耦:
- 用红黑树高效管理"我关心什么",
- 用就绪队列精准回答"什么已就绪",
- 用内核回调实现"数据一到,立即通知"。
这种设计彻底摆脱了传统轮询模型中"为沉默的大多数买单"的困境,让程序的时间真正花在有意义的活跃连接上。也正是这种思想,支撑起了 Nginx、Redis、Kafka 等百万级并发系统的稳定运行。
理解 epoll,不仅是掌握一个 API,更是理解 Linux 内核如何以最小开销、最大复用、最强抽象来应对现实世界的复杂性。希望本文能为你打开一扇窗,让你在编写下一个网络程序时,不仅能"会用 epoll",更能"懂其所以然"。
下一篇文章,我们就深入探讨epoll的实战使用,希望那个帮助大家更好的理解epoll模型!!