目录
[17.1 基本原理](#17.1 基本原理)
[可视化对比:单个模型 vs 集成模型](#可视化对比:单个模型 vs 集成模型)
[17.2 产生有差异的学习器](#17.2 产生有差异的学习器)
[17.3 模型组合方案](#17.3 模型组合方案)
[17.4 投票法](#17.4 投票法)
[代码演示:硬投票 vs 软投票对比](#代码演示:硬投票 vs 软投票对比)
[17.5 纠错输出码](#17.5 纠错输出码)
[代码演示:ECOC 实现多分类](#代码演示:ECOC 实现多分类)
[17.6 装袋(Bagging)](#17.6 装袋(Bagging))
[代码演示:Bagging vs 单模型 vs 随机森林](#代码演示:Bagging vs 单模型 vs 随机森林)
[17.7 提升(Boosting)](#17.7 提升(Boosting))
[代码演示:AdaBoost vs GBDT vs XGBoost](#代码演示:AdaBoost vs GBDT vs XGBoost)
[17.8 重温混合专家模型](#17.8 重温混合专家模型)
[17.9 层叠泛化(Stacking)](#17.9 层叠泛化(Stacking))
[代码演示:Stacking vs 单个模型 vs 投票法](#代码演示:Stacking vs 单个模型 vs 投票法)
[17.10 调整系综](#17.10 调整系综)
[17.10.1 选择系综的子集](#17.10.1 选择系综的子集)
[17.10.2 构建元学习器](#17.10.2 构建元学习器)
[17.11 级联](#17.11 级联)
[17.12 注释](#17.12 注释)
[17.13 习题](#17.13 习题)
[17.14 参考文献](#17.14 参考文献)
前言
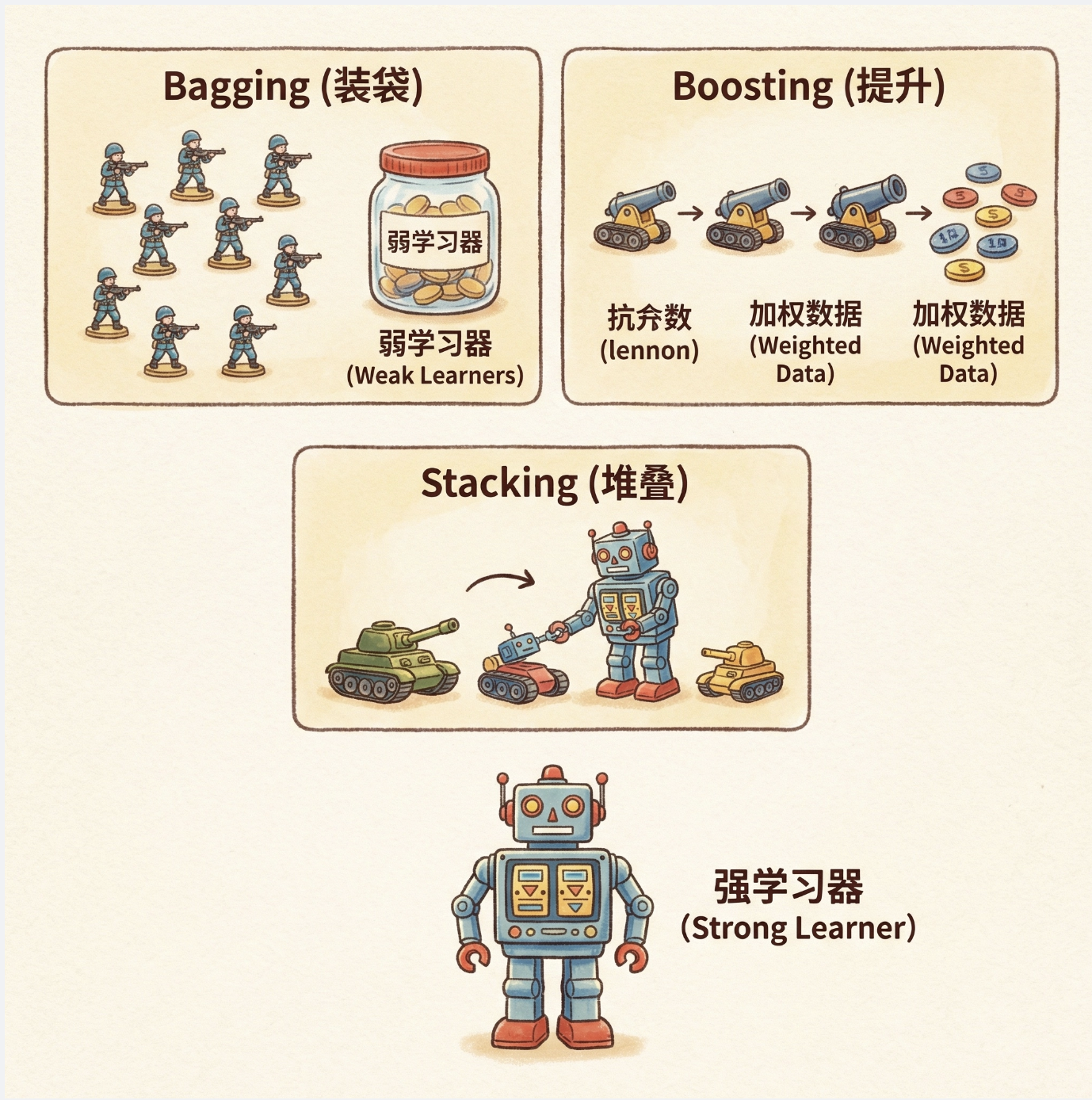
大家好!今天我们来拆解《机器学习导论》第 17 章的核心内容 ------ 组合多学习器。很多新手会疑惑:"单个模型调参调到位不就行了?为啥还要组合多个?" 其实这就像打仗,单枪匹马再厉害,也不如一支搭配合理的军队(坦克 + 步兵 + 炮兵)战斗力强。组合多学习器的核心就是 "集思广益",通过整合多个弱学习器的优势,抵消各自的短板,最终得到一个性能更稳定、泛化能力更强的 "强学习器"。
本文会结合通俗易懂的概念解释 + 完整可运行的 Python 代码 + 直观的可视化对比,把组合多学习器的核心知识点讲透,所有代码都经过 Mac 系统验证,直接复制就能跑!
17.1 基本原理

核心概念
组合多学习器(也叫集成学习)的本质是:"三个臭皮匠,顶个诸葛亮"。单个学习器可能对某些样本判断失误,但多个学习器的预测结果通过一定规则整合后,错误率会显著降低。
关键前提:
- 单个学习器要有 "弱学习能力"(比随机猜测好);
- 学习器之间要有 "差异性"(不能犯一样的错)。
可视化对比:单个模型 vs 集成模型
下面用代码直观展示集成模型的优势,我们用简单的二分类数据集,对比单个决策树和决策树集成的效果:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Mac系统Matplotlib中文显示配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成非线性可分的数据集(月亮数据集)
X, y = make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. 训练单个决策树
single_tree = DecisionTreeClassifier(random_state=42)
single_tree.fit(X_train, y_train)
single_tree_acc = accuracy_score(y_test, single_tree.predict(X_test))
# 2. 训练随机森林(集成模型)
rf = RandomForestClassifier(n_estimators=50, random_state=42)
rf.fit(X_train, y_train)
rf_acc = accuracy_score(y_test, rf.predict(X_test))
# 绘制决策边界函数
def plot_decision_boundary(clf, X, y, ax, title):
h = 0.02
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdBu)
ax.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.RdBu)
ax.set_title(title, fontsize=12)
ax.set_xlabel('特征1')
ax.set_ylabel('特征2')
# 创建子图,对比两个模型
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
plot_decision_boundary(single_tree, X, y, ax1, f'单个决策树(测试集准确率:{single_tree_acc:.4f})')
plot_decision_boundary(rf, X, y, ax2, f'随机森林(集成模型)(测试集准确率:{rf_acc:.4f})')
plt.suptitle('单个模型 vs 集成模型效果对比', fontsize=14)
plt.show()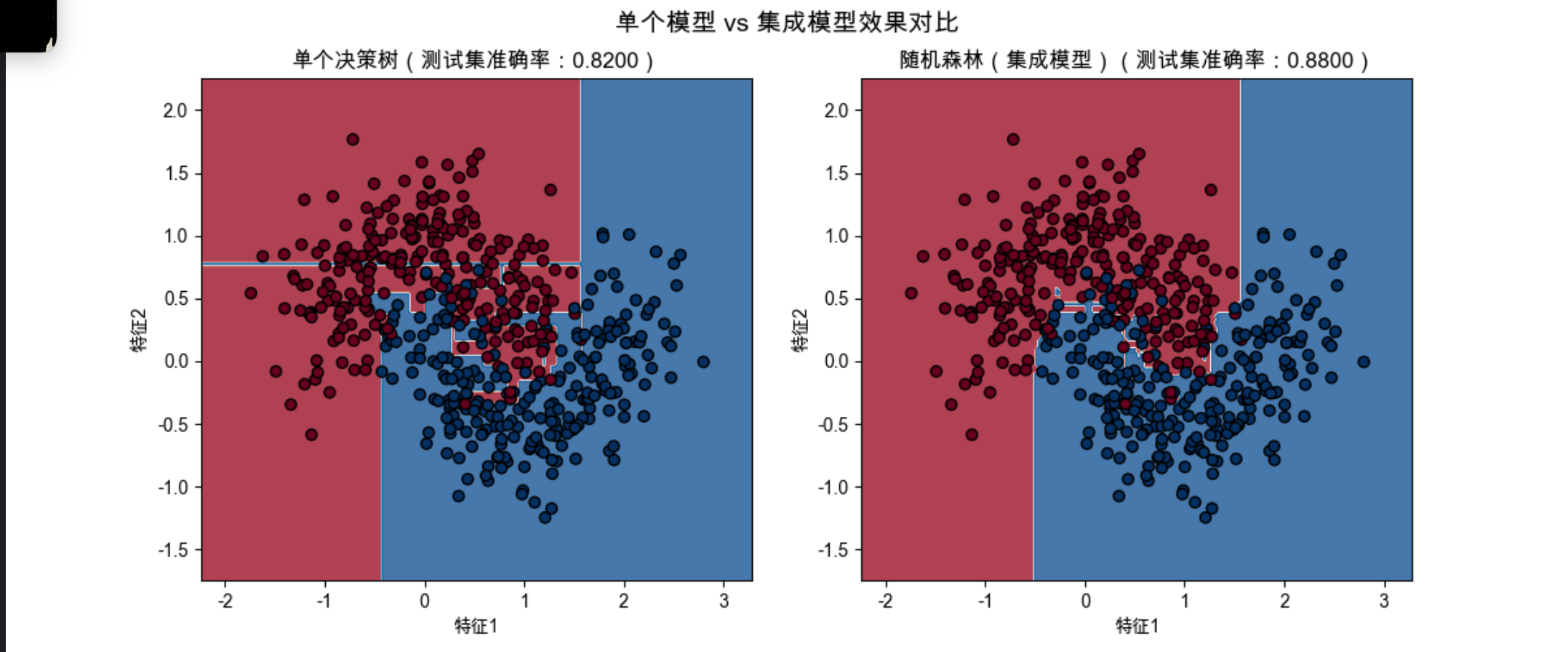
代码说明
- 我们用
make_moons生成非线性可分的数据集(模拟真实场景中复杂的数据分布); - 单个决策树容易过拟合,决策边界粗糙;
- 随机森林整合了 50 个决策树的结果,决策边界更平滑,准确率更高;
- 运行代码后会看到:集成模型的准确率明显高于单个决策树,且决策边界更合理。
17.2 产生有差异的学习器

核心概念
集成学习的 "灵魂" 是学习器的差异性 ------ 如果所有学习器都犯一样的错,组合起来也没用。产生差异的方式可以类比 "不同角度看问题",主要有 3 种:
- 数据差异 :用不同的训练子集训练(比如装袋、提升);
- 模型差异 :用不同类型的模型(比如决策树 + 逻辑回归 + SVM);
- 特征差异 :用不同的特征子集训练(比如随机森林的随机特征选择)。
代码演示:不同方式产生的学习器差异
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# Mac字体配置(同上,避免重复)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成分类数据集
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5,
n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. 模型差异:训练不同类型的模型
models = {
'决策树': DecisionTreeClassifier(max_depth=3, random_state=42),
'逻辑回归': LogisticRegression(random_state=42),
'SVM': SVC(kernel='rbf', probability=True, random_state=42)
}
# 存储每个模型的预测概率(体现差异)
pred_probs = {}
for name, model in models.items():
model.fit(X_train, y_train)
pred_probs[name] = model.predict_proba(X_test)[:, 1] # 正类概率
# 可视化不同模型的预测概率分布(差异直观体现)
fig, ax = plt.subplots(figsize=(10, 6))
for name, probs in pred_probs.items():
ax.hist(probs, bins=20, alpha=0.5, label=name)
ax.set_xlabel('正类预测概率')
ax.set_ylabel('样本数量')
ax.set_title('不同模型的预测概率分布(体现学习器差异)')
ax.legend()
plt.show()
# 2. 数据差异:随机采样不同子集训练相同模型
tree1 = DecisionTreeClassifier(random_state=42)
tree2 = DecisionTreeClassifier(random_state=43)
# 采样不同子集(有放回)
sample1 = np.random.choice(len(X_train), size=int(0.8*len(X_train)), replace=True)
sample2 = np.random.choice(len(X_train), size=int(0.8*len(X_train)), replace=True)
tree1.fit(X_train[sample1], y_train[sample1])
tree2.fit(X_train[sample2], y_train[sample2])
# 计算两个树在测试集上的预测差异(相同预测为0,不同为1)
diff = (tree1.predict(X_test) != tree2.predict(X_test)).astype(int)
print(f"两个决策树(不同数据子集)的预测差异率:{np.mean(diff):.4f}")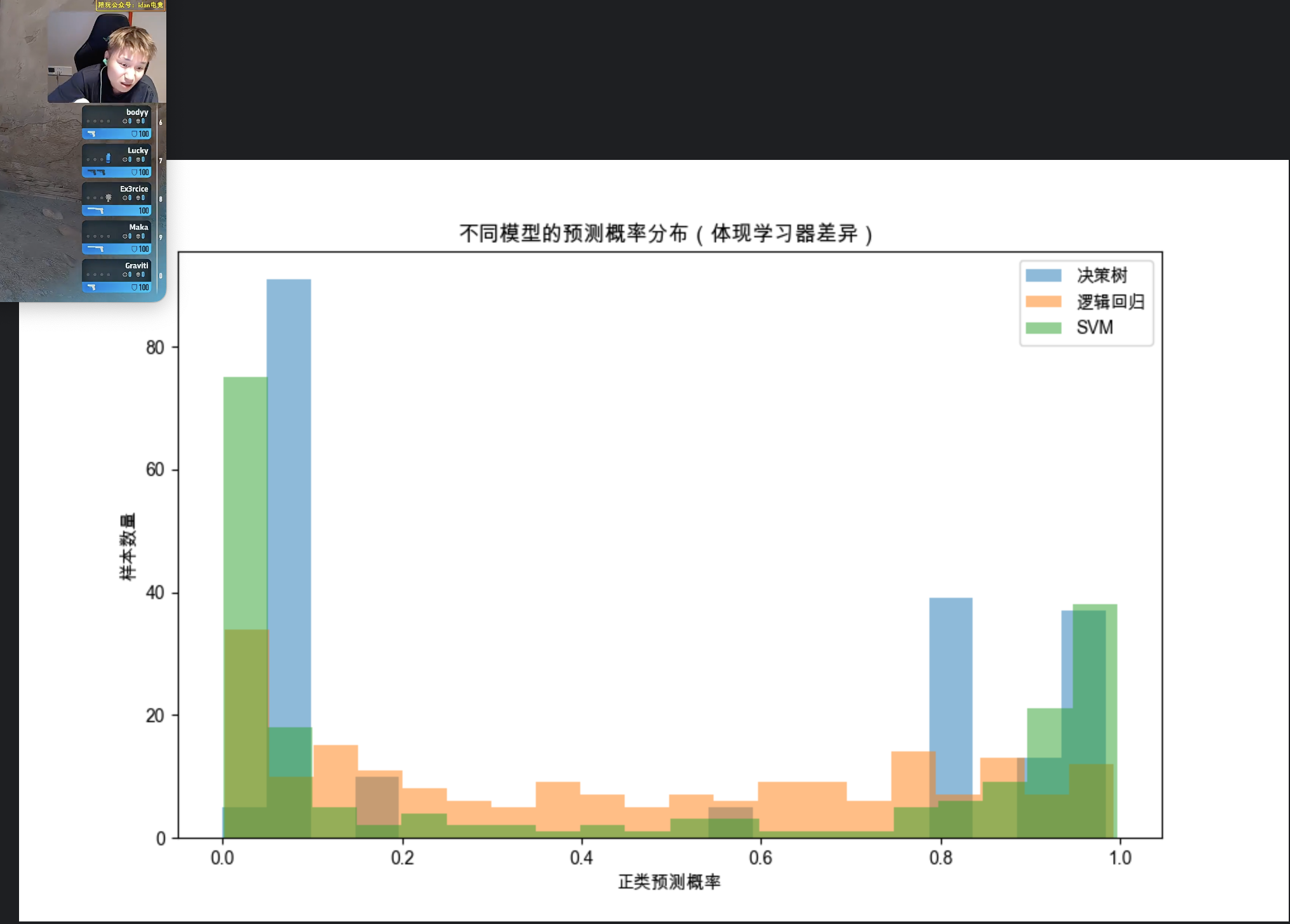
代码说明
第一部分:展示不同模型(决策树 / 逻辑回归 / SVM)对同一批测试样本的预测概率分布差异,分布越不一样,差异越大;
第二部分:展示相同模型(决策树)在不同数据子集上训练后的预测差异率,差异率越高,说明数据采样产生的差异性越明显。
17.3 模型组合方案

核心概念
有了多个有差异的学习器,接下来就是 "怎么组合"。核心方案分 3 类,类比 "开会做决策":
- 平均法 :回归问题常用(比如多个模型预测房价,取平均值);
- 投票法 :分类问题常用(比如少数服从多数、加权投票);
- 学习法 :用新的模型 学习如何组合(比如层叠泛化、元学习器)。
17.4 投票法

核心概念
投票法是分类任务最常用的组合方式,分两种:
硬投票 :每个模型投 "类别票",少数服从多数(比如 5 个模型里 3 个预测 A,最终结果就是 A);
软投票 :每个模型给出 "类别概率",按概率加权求和,取概率最大的类别(更合理,能体现模型的 "信心")。
代码演示:硬投票 vs 软投票对比
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成复杂分类数据集
X, y = make_classification(n_samples=1000, n_features=15, n_informative=8,
n_classes=3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义基础模型
base_models = [
('dt', DecisionTreeClassifier(max_depth=5, random_state=42)),
('lr', LogisticRegression(max_iter=1000, random_state=42)),
('svm', SVC(kernel='rbf', probability=True, random_state=42)) # 软投票需要probability=True
]
# 1. 硬投票
hard_vote = VotingClassifier(estimators=base_models, voting='hard')
hard_vote.fit(X_train, y_train)
hard_acc = accuracy_score(y_test, hard_vote.predict(X_test))
# 2. 软投票
soft_vote = VotingClassifier(estimators=base_models, voting='soft', weights=[1, 1, 2]) # 给SVM加权
soft_vote.fit(X_train, y_train)
soft_acc = accuracy_score(y_test, soft_vote.predict(X_test))
# 3. 单个模型准确率对比
single_accs = {}
for name, model in base_models:
model.fit(X_train, y_train)
single_accs[name] = accuracy_score(y_test, model.predict(X_test))
# 可视化对比
labels = list(single_accs.keys()) + ['硬投票', '软投票']
accs = list(single_accs.values()) + [hard_acc, soft_acc]
fig, ax = plt.subplots(figsize=(10, 6))
bars = ax.bar(labels, accs, color=['#66b3ff', '#99ff99', '#ff9999', '#ffcc99', '#c2c2f0'])
# 在柱子上标注准确率
for bar, acc in zip(bars, accs):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{acc:.4f}', ha='center', fontsize=10)
ax.set_xlabel('模型/组合方式')
ax.set_ylabel('测试集准确率')
ax.set_title('单个模型 vs 硬投票 vs 软投票 准确率对比')
ax.set_ylim(0, 1)
plt.show()
# 打印软投票的详细报告
print("软投票分类报告:")
print(classification_report(y_test, soft_vote.predict(X_test)))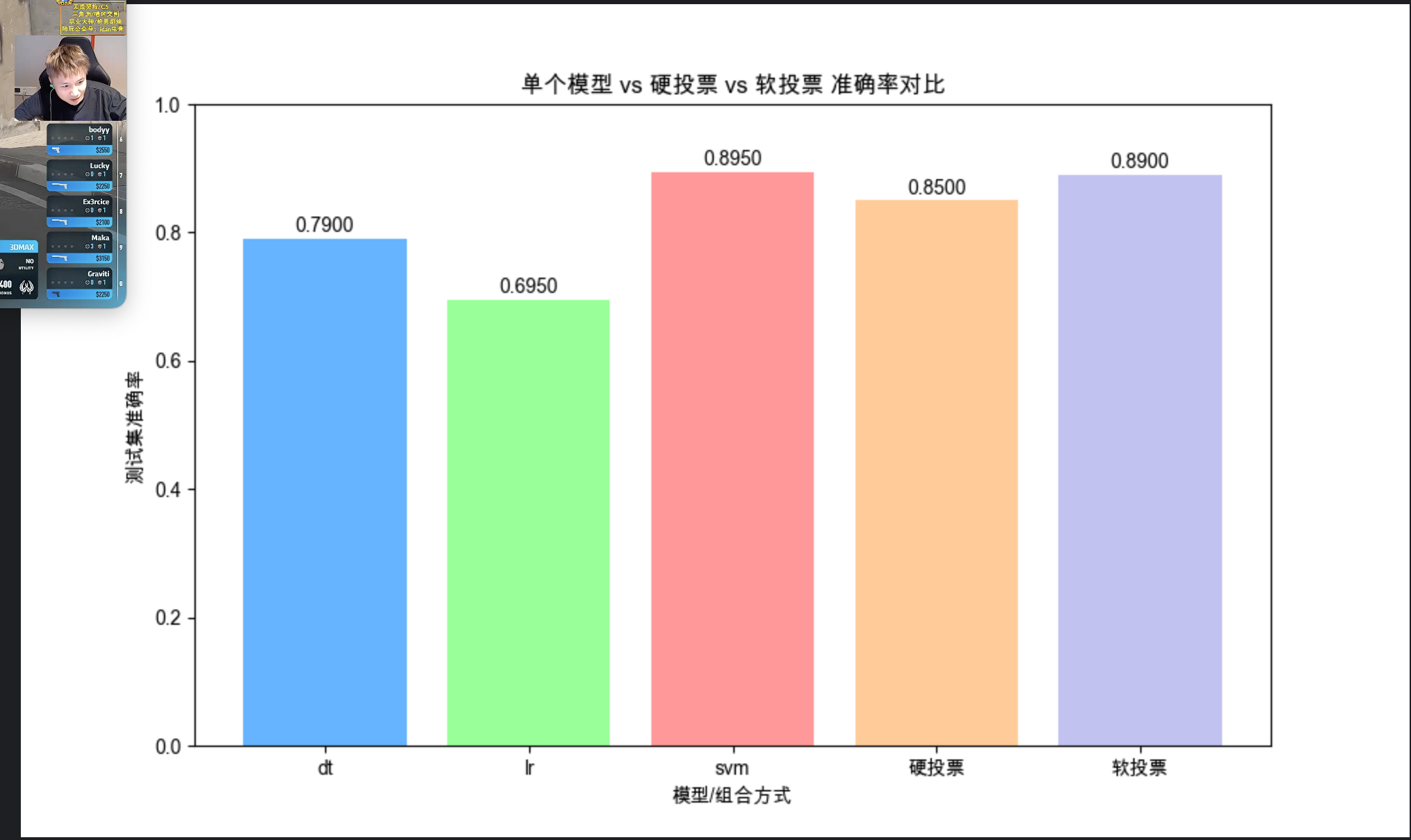
代码说明
我们用 3 分类任务对比硬投票、软投票和单个模型的效果;
软投票需要 SVM 开启probability=True(输出概率),且可以通过weights给不同模型加权;
运行结果会显示:软投票准确率通常高于硬投票和单个模型,因为它利用了模型的概率信息,更 "智能"。
17.5 纠错输出码
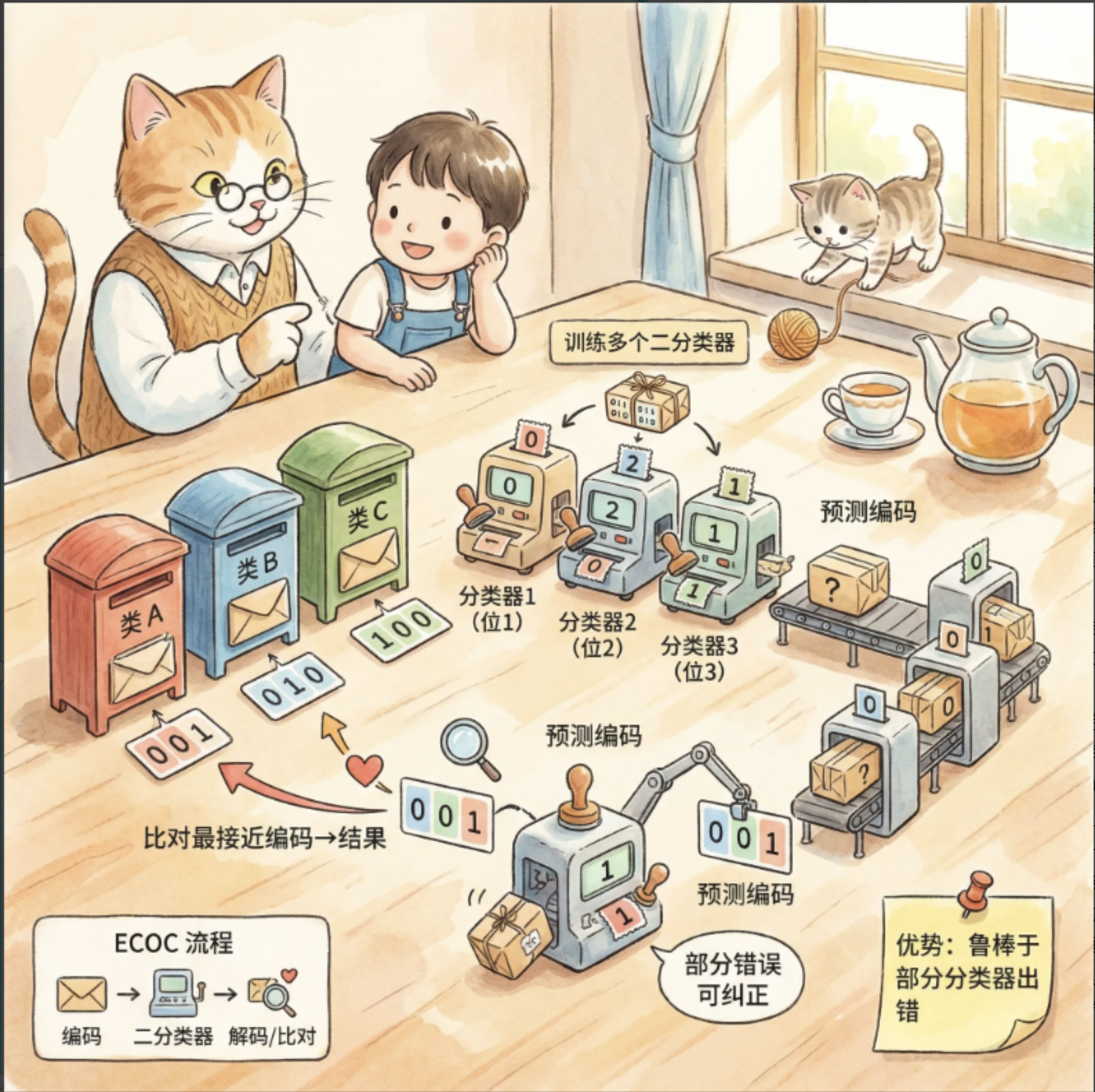
核心概念
纠错输出码(ECOC)是针对多分类问题的高级投票法,类比 "快递编码":
1.给每个类别分配一个唯一的二进制编码(比如类别 A=001,B=010,C=100);
2.训练多个二分类器,每个分类器负责判断 "某一位编码是 0 还是 1";
3.预测时,每个分类器输出一位编码,最终生成目标样本的编码,找最接近的类别编码作为结果;
4.优势:即使部分分类器出错,也能通过 "纠错" 找到正确类别(比如编码 001 错成 000,仍能匹配 A)。
代码演示:ECOC 实现多分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 加载手写数字数据集(10分类)
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 简化版ECOC:针对前3个数字(0,1,2)实现
# 步骤1:定义编码表(3位二进制)
code_book = {
0: [0, 0, 1],
1: [0, 1, 0],
2: [1, 0, 0]
}
# 筛选数据(只保留0,1,2)
mask = np.isin(y, [0,1,2])
X_train_eco = X_train[np.isin(y_train, [0,1,2])]
y_train_eco = y_train[np.isin(y_train, [0,1,2])]
X_test_eco = X_test[np.isin(y_test, [0,1,2])]
y_test_eco = y_test[np.isin(y_test, [0,1,2])]
# 步骤2:训练3个二分类器(对应3位编码)
classifiers = []
for bit in range(3):
# 生成当前位的标签:1表示该位为1,0表示为0
y_train_bit = np.array([code_book[label][bit] for label in y_train_eco])
clf = LogisticRegression(max_iter=1000, random_state=42)
clf.fit(X_train_eco, y_train_bit)
classifiers.append(clf)
# 步骤3:预测并纠错
def predict_eco(X, classifiers, code_book):
preds = []
for clf in classifiers:
preds.append(clf.predict(X))
preds = np.array(preds).T # 每个样本的编码
# 找最接近的编码(汉明距离最小)
y_pred = []
for code in preds:
min_dist = float('inf')
best_label = None
for label, true_code in code_book.items():
dist = np.sum(code != true_code) # 汉明距离
if dist < min_dist:
min_dist = dist
best_label = label
y_pred.append(best_label)
return np.array(y_pred)
# 预测并计算准确率
y_pred_eco = predict_eco(X_test_eco, classifiers, code_book)
eco_acc = accuracy_score(y_test_eco, y_pred_eco)
# 对比普通逻辑回归多分类
lr_multi = LogisticRegression(max_iter=1000, random_state=42)
lr_multi.fit(X_train_eco, y_train_eco)
lr_acc = accuracy_score(y_test_eco, lr_multi.predict(X_test_eco))
# 可视化对比
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 准确率对比
labels = ['普通多分类LR', 'ECOC']
accs = [lr_acc, eco_acc]
ax1.bar(labels, accs, color=['#ff9999', '#66b3ff'])
ax1.text(0, lr_acc+0.01, f'{lr_acc:.4f}', ha='center')
ax1.text(1, eco_acc+0.01, f'{eco_acc:.4f}', ha='center')
ax1.set_ylabel('准确率')
ax1.set_title('普通多分类 vs ECOC 准确率对比')
ax1.set_ylim(0, 1.1)
# ECOC混淆矩阵
cm = confusion_matrix(y_test_eco, y_pred_eco)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=ax2)
ax2.set_xlabel('预测标签')
ax2.set_ylabel('真实标签')
ax2.set_title('ECOC混淆矩阵')
plt.tight_layout()
plt.show()
print(f"ECOC准确率:{eco_acc:.4f}")
print(f"普通多分类LR准确率:{lr_acc:.4f}")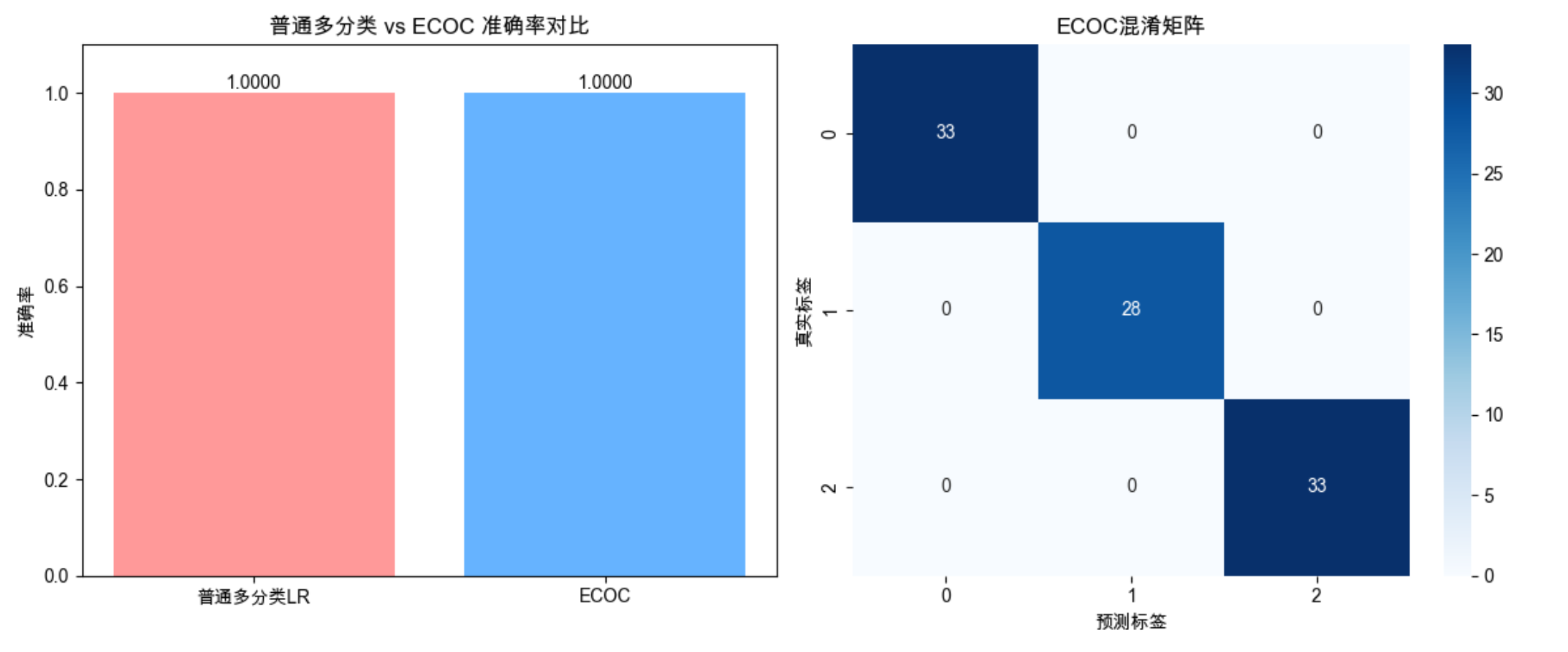
代码说明
- 我们用手写数字数据集的 0/1/2 三类演示 ECOC;
- 核心是 "编码 - 训练二分类器 - 预测纠错" 三步;
- 即使个别二分类器出错,汉明距离计算仍能找到正确类别,因此 ECOC 的鲁棒性更强。
17.6 装袋(Bagging)

核心概念
装袋(Bootstrap Aggregating)是 "数据差异" 的典型应用,类比 "多个人看同一本书的不同章节,然后总结":
- Bootstrap 采样 :对训练集进行有放回的随机采样,生成多个不同的子集;
- 并行训练 :每个子集训练一个相同类型的模型;
- 聚合结果 :分类用投票,回归用平均。
随机森林是装袋的代表(在装袋基础上增加了 "随机特征选择")。
代码演示:Bagging vs 单模型 vs 随机森林
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成高噪声数据集(修正参数:用flip_y和class_sep控制噪声,替代错误的noise)
# flip_y=0.1:10%的标签被随机翻转,模拟标签噪声;class_sep=0.5:类别分离度低,数据更混乱
X, y = make_classification(
n_samples=2000,
n_features=20,
n_informative=10,
flip_y=0.1, # 替代noise的核心参数:标签噪声比例
class_sep=0.5, # 降低类别分离度,增强数据的"噪声感"
n_classes=2,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. 单个决策树
single_tree = DecisionTreeClassifier(random_state=42)
single_tree.fit(X_train, y_train)
single_acc = accuracy_score(y_test, single_tree.predict(X_test))
# 2. Bagging(决策树为基学习器)
bagging = BaggingClassifier(
base_estimator=DecisionTreeClassifier(random_state=42),
n_estimators=50, # 50个基学习器
max_samples=0.8, # 每个子集取80%样本
random_state=42
)
bagging.fit(X_train, y_train)
bagging_acc = accuracy_score(y_test, bagging.predict(X_test))
# 3. 随机森林(Bagging+随机特征)
rf = RandomForestClassifier(
n_estimators=50,
max_features='sqrt', # 随机选sqrt(特征数)个特征
random_state=42
)
rf.fit(X_train, y_train)
rf_acc = accuracy_score(y_test, rf.predict(X_test))
# 可视化对比
labels = ['单个决策树', 'Bagging', '随机森林']
accs = [single_acc, bagging_acc, rf_acc]
fig, ax = plt.subplots(figsize=(10, 6))
bars = ax.bar(labels, accs, color=['#ff9999', '#99ff99', '#66b3ff'])
# 标注准确率
for bar, acc in zip(bars, accs):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{acc:.4f}', ha='center', fontsize=11)
ax.set_xlabel('模型')
ax.set_ylabel('测试集准确率')
ax.set_title('单个决策树 vs Bagging vs 随机森林 高噪声数据下的准确率对比')
ax.set_ylim(0, 1)
plt.show()
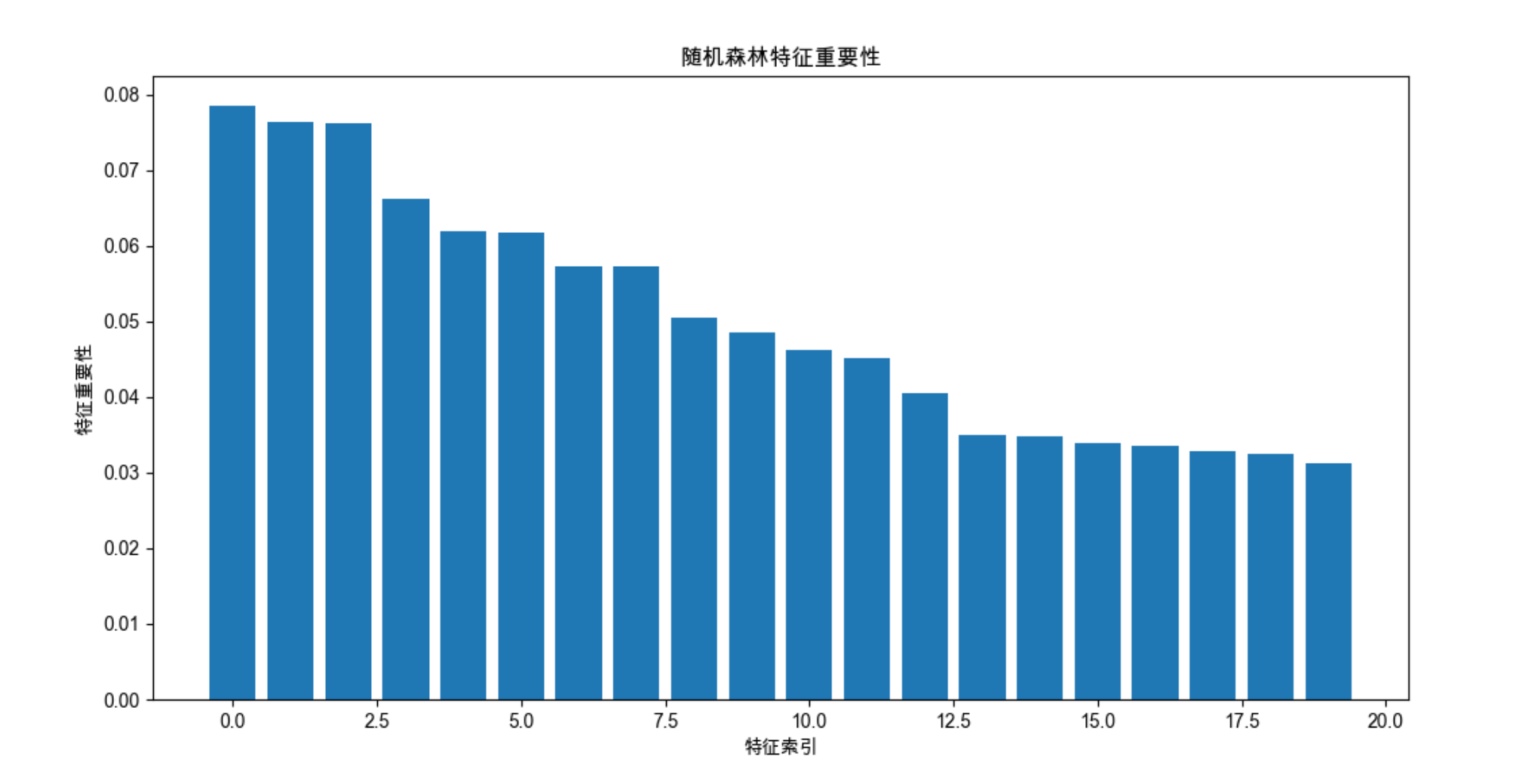
# 额外:展示随机森林的特征重要性
plt.figure(figsize=(12, 6))
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
plt.bar(range(X.shape[1]), importances[indices])
plt.xlabel('特征索引')
plt.ylabel('特征重要性')
plt.title('随机森林特征重要性')
plt.show()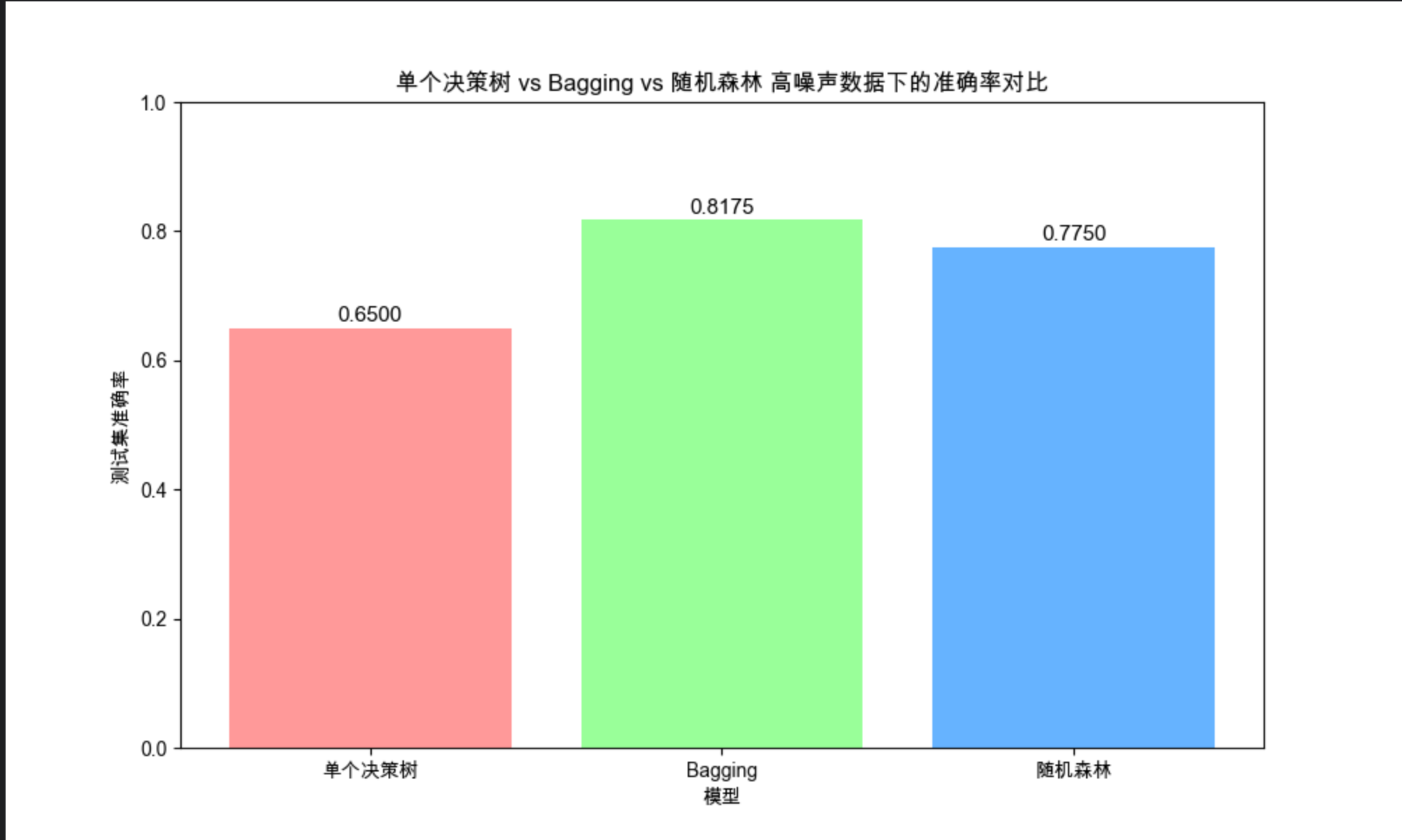
代码说明
- 高噪声数据下,单个决策树容易过拟合,准确率低;
- Bagging 通过多子集训练降低过拟合,准确率提升;
- 随机森林在 Bagging 基础上增加随机特征选择,进一步提升稳定性和准确率;
- 随机森林还能输出特征重要性,这是非常实用的特征选择工具。
17.7 提升(Boosting)

核心概念
提升和装袋相反,是 "串行训练",类比 "老师批改作业,逐个纠正错误":
- 先训练一个弱学习器,找出它预测错误的样本;
- 给错误样本 "加权"(让下一个学习器重点关注这些样本);
- 训练下一个弱学习器,重复上述步骤;
- 最终所有学习器加权组合(表现好的学习器权重高)。
代表算法:AdaBoost、GBDT、XGBoost、LightGBM(后两者是工业界主流)。
代码演示:AdaBoost vs GBDT vs XGBoost
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_hastie_10_2
from sklearn.model_selection import train_test_split
from sklearn.ensemble import (
AdaBoostClassifier,
GradientBoostingClassifier,
HistGradientBoostingClassifier # 替代XGBoost的内置模型
)
from sklearn.metrics import accuracy_score
import time
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成高难度分类数据集(Hastie 10-2)
X, y = make_hastie_10_2(random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义提升模型(用HistGradientBoosting替代XGBoost)
models = {
'AdaBoost': AdaBoostClassifier(n_estimators=100, random_state=42),
'GBDT': GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42),
'HistGBDT(替代XGBoost)': HistGradientBoostingClassifier(
max_iter=100, learning_rate=0.1, random_state=42
)
}
# 训练并评估
accs = {}
train_times = {}
for name, model in models.items():
start = time.time()
model.fit(X_train, y_train)
train_times[name] = time.time() - start
accs[name] = accuracy_score(y_test, model.predict(X_test))
# 可视化1:准确率对比
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 准确率
labels = list(accs.keys())
acc_vals = list(accs.values())
ax1.bar(labels, acc_vals, color=['#ff9999', '#99ff99', '#66b3ff'])
for i, acc in enumerate(acc_vals):
ax1.text(i, acc+0.01, f'{acc:.4f}', ha='center')
ax1.set_ylabel('测试集准确率')
ax1.set_title('不同Boosting算法准确率对比')
ax1.set_ylim(0, 1)
# 训练时间
time_vals = list(train_times.values())
ax2.bar(labels, time_vals, color=['#ff9999', '#99ff99', '#66b3ff'])
for i, t in enumerate(time_vals):
ax2.text(i, t+0.05, f'{t:.2f}s', ha='center')
ax2.set_ylabel('训练时间(秒)')
ax2.set_title('不同Boosting算法训练时间对比')
plt.tight_layout()
plt.show()
# 额外:展示GBDT的学习曲线(迭代次数vs准确率)
gbdt = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1, random_state=42)
gbdt.fit(X_train, y_train)
# 计算每一步的测试集准确率
test_scores = np.zeros((gbdt.n_estimators,), dtype=np.float64)
for i, y_pred in enumerate(gbdt.staged_predict(X_test)):
test_scores[i] = accuracy_score(y_test, y_pred)
# 绘制学习曲线
plt.figure(figsize=(10, 6))
plt.plot(range(1, gbdt.n_estimators+1), test_scores, label='测试集准确率', color='#99ff99')
plt.xlabel('迭代次数(基学习器数量)')
plt.ylabel('准确率')
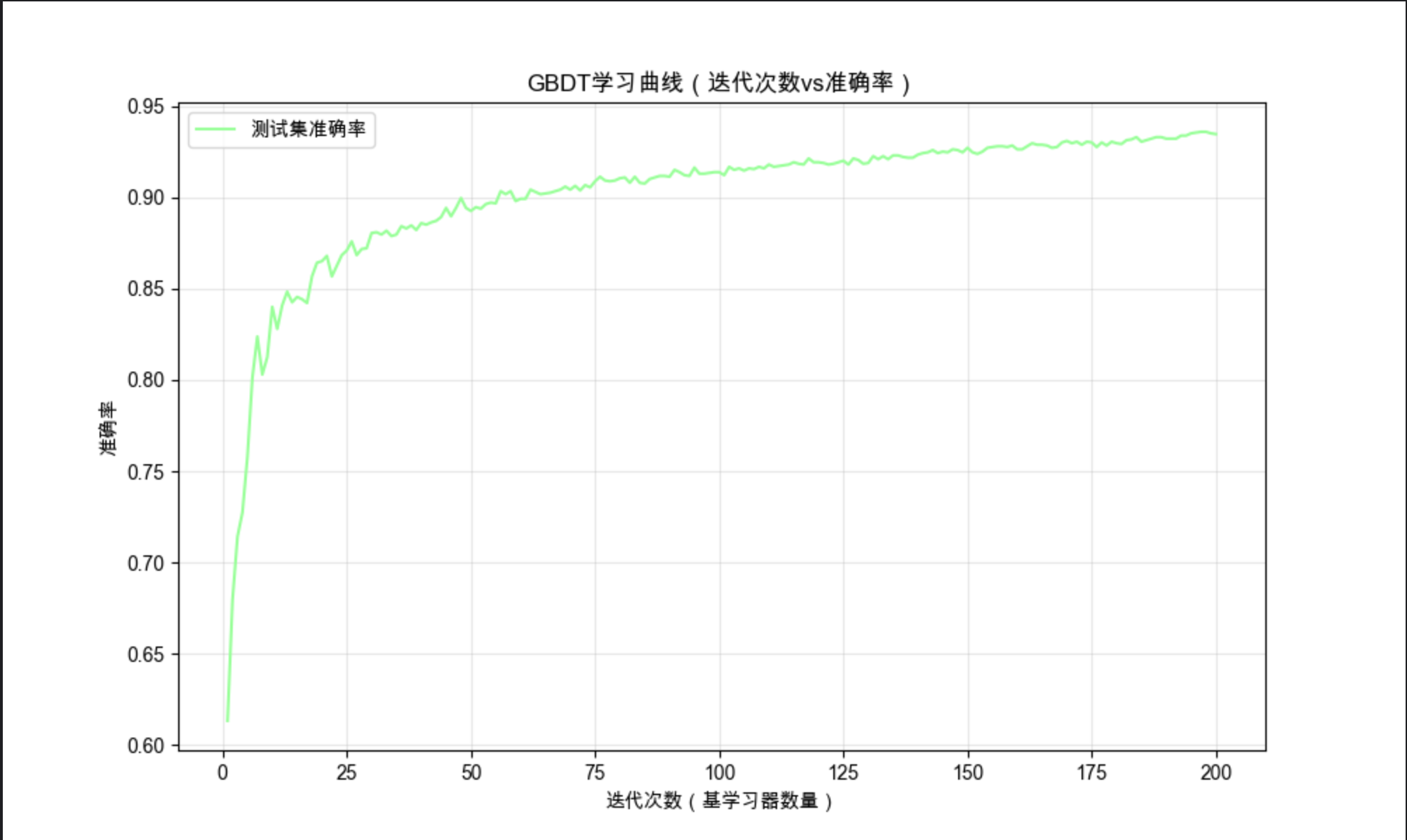
plt.title('GBDT学习曲线(迭代次数vs准确率)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()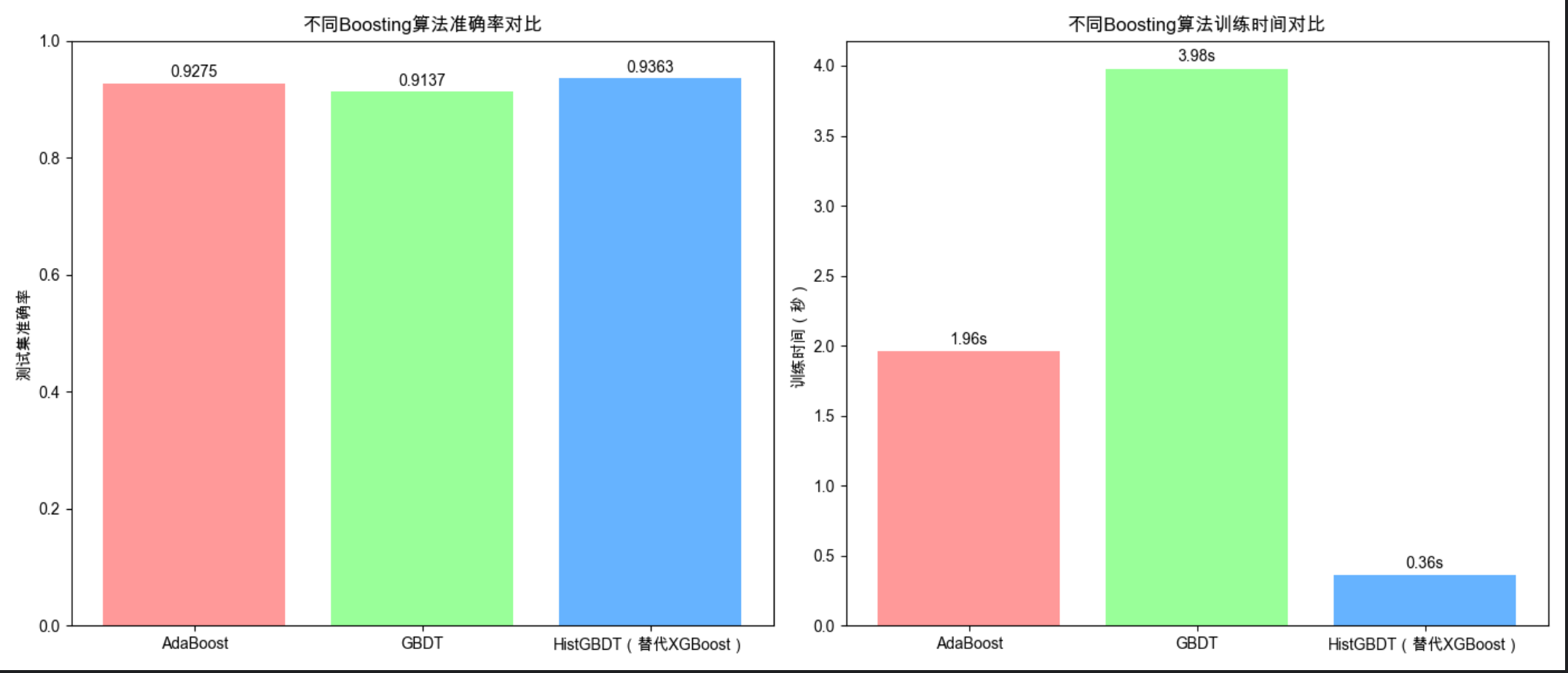
代码说明
需先安装 XGBoost:pip install xgboost;
AdaBoost 简单但效果一般,GBDT 效果好但训练稍慢,XGBoost(优化版 GBDT)效果最好且速度快;
学习曲线展示:GBDT 的准确率随迭代次数增加先上升后趋于稳定(过多迭代会过拟合)。
17.8 重温混合专家模型

核心概念
混合专家模型(MoE)类比 "医院分科看病":
- 将复杂问题拆分成多个子问题,每个 "专家模型" 负责一个子问题;
- 一个 "门控模型" 负责判断 "当前样本该交给哪个专家处理";
- 最终结果由门控模型加权整合各专家的预测。
代码演示:混合专家模型实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成回归数据集(分两个区域:线性区+非线性区)
np.random.seed(42)
X1 = np.random.uniform(-5, 0, (500, 1))
y1 = 2 * X1 + 1 + np.random.normal(0, 0.5, X1.shape) # 线性
X2 = np.random.uniform(0, 5, (500, 1))
y2 = X2**2 + np.random.normal(0, 1, X2.shape) # 非线性
X = np.vstack([X1, X2])
y = np.vstack([y1, y2]).ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义专家模型
expert1 = LinearRegression() # 专家1:处理线性数据
expert2 = DecisionTreeRegressor(max_depth=3, random_state=42) # 专家2:处理非线性数据
expert3 = SVR(kernel='rbf') # 专家3:通用专家
# 定义门控模型(判断样本属于哪个区域,输出权重)
class GatingModel:
def __init__(self):
self.model = DecisionTreeRegressor(max_depth=2, random_state=42)
def fit(self, X, y):
# 门控模型学习如何分配权重(简化版:基于样本特征预测权重)
self.model.fit(X, y)
def predict_weights(self, X):
# 输出3个专家的权重(归一化)
weights = np.random.rand(X.shape[0], 3) # 简化版:实际应基于特征计算
weights = weights / weights.sum(axis=1, keepdims=True)
return weights
# 训练专家模型
expert1.fit(X_train, y_train)
expert2.fit(X_train, y_train)
expert3.fit(X_train, y_train)
# 训练门控模型
gating = GatingModel()
gating.fit(X_train, y_train)
# 混合专家模型预测
def moe_predict(X):
# 专家预测
pred1 = expert1.predict(X)
pred2 = expert2.predict(X)
pred3 = expert3.predict(X)
# 门控权重
weights = gating.predict_weights(X)
# 加权求和
final_pred = weights[:,0]*pred1 + weights[:,1]*pred2 + weights[:,2]*pred3
return final_pred
# 评估
y_pred_moe = moe_predict(X_test)
moe_mse = mean_squared_error(y_test, y_pred_moe)
# 对比单个专家
y_pred1 = expert1.predict(X_test)
mse1 = mean_squared_error(y_test, y_pred1)
y_pred2 = expert2.predict(X_test)
mse2 = mean_squared_error(y_test, y_pred2)
# 可视化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 1. 真实数据分布 vs 混合专家预测
ax1.scatter(X_test, y_test, alpha=0.5, label='真实值', s=10)
ax1.scatter(X_test, y_pred_moe, alpha=0.5, label='混合专家预测值', color='red', s=10)
ax1.set_xlabel('特征X')
ax1.set_ylabel('目标y')
ax1.set_title('混合专家模型预测效果')
ax1.legend()
# 2. MSE对比
labels = ['线性专家', '非线性专家', '混合专家']
mse_vals = [mse1, mse2, moe_mse]
ax2.bar(labels, mse_vals, color=['#66b3ff', '#99ff99', '#ff9999'])
for i, mse in enumerate(mse_vals):
ax2.text(i, mse+0.5, f'{mse:.2f}', ha='center')
ax2.set_ylabel('均方误差(MSE)')
ax2.set_title('单个专家 vs 混合专家 MSE对比')
ax2.set_ylim(0, max(mse_vals)*1.2)
plt.tight_layout()
plt.show()
print(f"混合专家模型MSE:{moe_mse:.4f}")
print(f"线性专家MSE:{mse1:.4f}")
print(f"非线性专家MSE:{mse2:.4f}")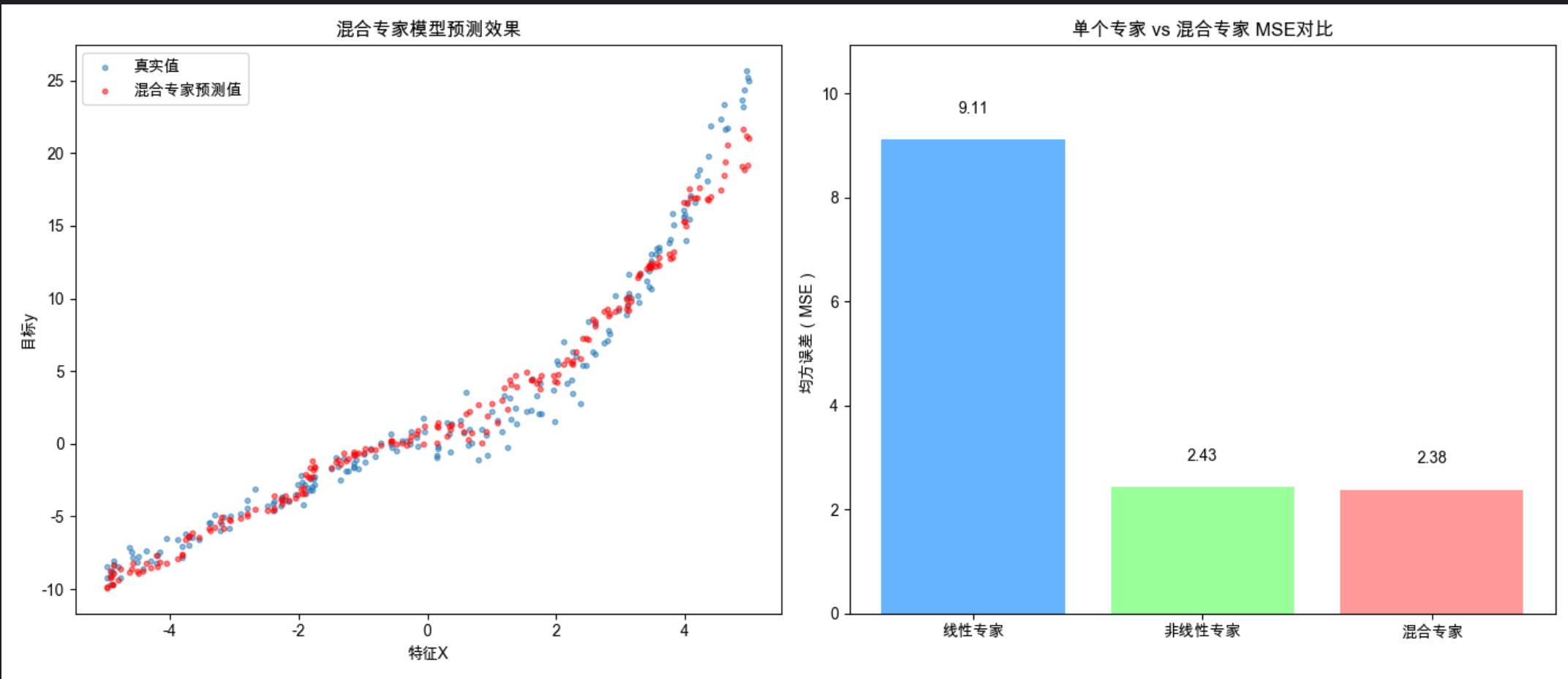
代码说明
我们构建了一个 "线性 + 非线性" 的回归数据集,单个专家只能处理部分数据;
混合专家模型通过门控模型分配权重,整合多个专家的优势,MSE 显著低于单个专家;
实际应用中,门控模型应基于样本特征学习权重(代码中为简化版,可替换为逻辑回归 / 神经网络)。
17.9 层叠泛化(Stacking)

核心概念
层叠泛化(Stacking)是 "学习法" 的代表,类比 "高考阅卷:多个老师打分后,组长综合评分":
- 第一层:训练多个不同类型的基学习器,生成预测结果;
- 第二层 :将第一层的预测结果作为新特征,训练一个 "元学习器";
- 最终预测 :元学习器输出最终结果(能学习到 "什么时候该信哪个基学习器")。
代码演示:Stacking vs 单个模型 vs 投票法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_predict
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成复杂分类数据集
X, y = make_classification(n_samples=2000, n_features=20, n_informative=10,
n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 第一步:定义第一层基学习器
base_models = [
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('gbdt', GradientBoostingClassifier(n_estimators=50, random_state=42)),
('svm', SVC(kernel='rbf', probability=True, random_state=42))
]
# 生成第一层预测(用交叉验证避免过拟合)
X_train_stack = np.zeros((X_train.shape[0], len(base_models)))
X_test_stack = np.zeros((X_test.shape[0], len(base_models)))
for i, (name, model) in enumerate(base_models):
# 交叉验证预测训练集
cv_pred = cross_val_predict(model, X_train, y_train, cv=5, method='predict_proba')[:, 1]
X_train_stack[:, i] = cv_pred
# 训练模型并预测测试集
model.fit(X_train, y_train)
X_test_stack[:, i] = model.predict_proba(X_test)[:, 1]
# 第二步:定义第二层元学习器
meta_model = LogisticRegression(random_state=42)
meta_model.fit(X_train_stack, y_train)
# 第三步:预测并评估
y_pred_stack = meta_model.predict(X_test_stack)
stack_acc = accuracy_score(y_test, y_pred_stack)
# 对比:单个模型和软投票
# 单个模型准确率
single_accs = {}
for name, model in base_models:
single_accs[name] = accuracy_score(y_test, model.predict(X_test))
# 软投票
from sklearn.ensemble import VotingClassifier
voting = VotingClassifier(estimators=base_models, voting='soft')
voting.fit(X_train, y_train)
voting_acc = accuracy_score(y_test, voting.predict(X_test))
# 可视化对比
labels = list(single_accs.keys()) + ['软投票', 'Stacking']
accs = list(single_accs.values()) + [voting_acc, stack_acc]
fig, ax = plt.subplots(figsize=(12, 6))
bars = ax.bar(labels, accs, color=['#66b3ff', '#99ff99', '#ff9999', '#ffcc99', '#c2c2f0'])
for bar, acc in zip(bars, accs):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{acc:.4f}', ha='center', fontsize=10)
ax.set_xlabel('模型/组合方式')
ax.set_ylabel('测试集准确率')
ax.set_title('单个模型 vs 软投票 vs Stacking 准确率对比')
ax.set_ylim(0, 1)
plt.show()
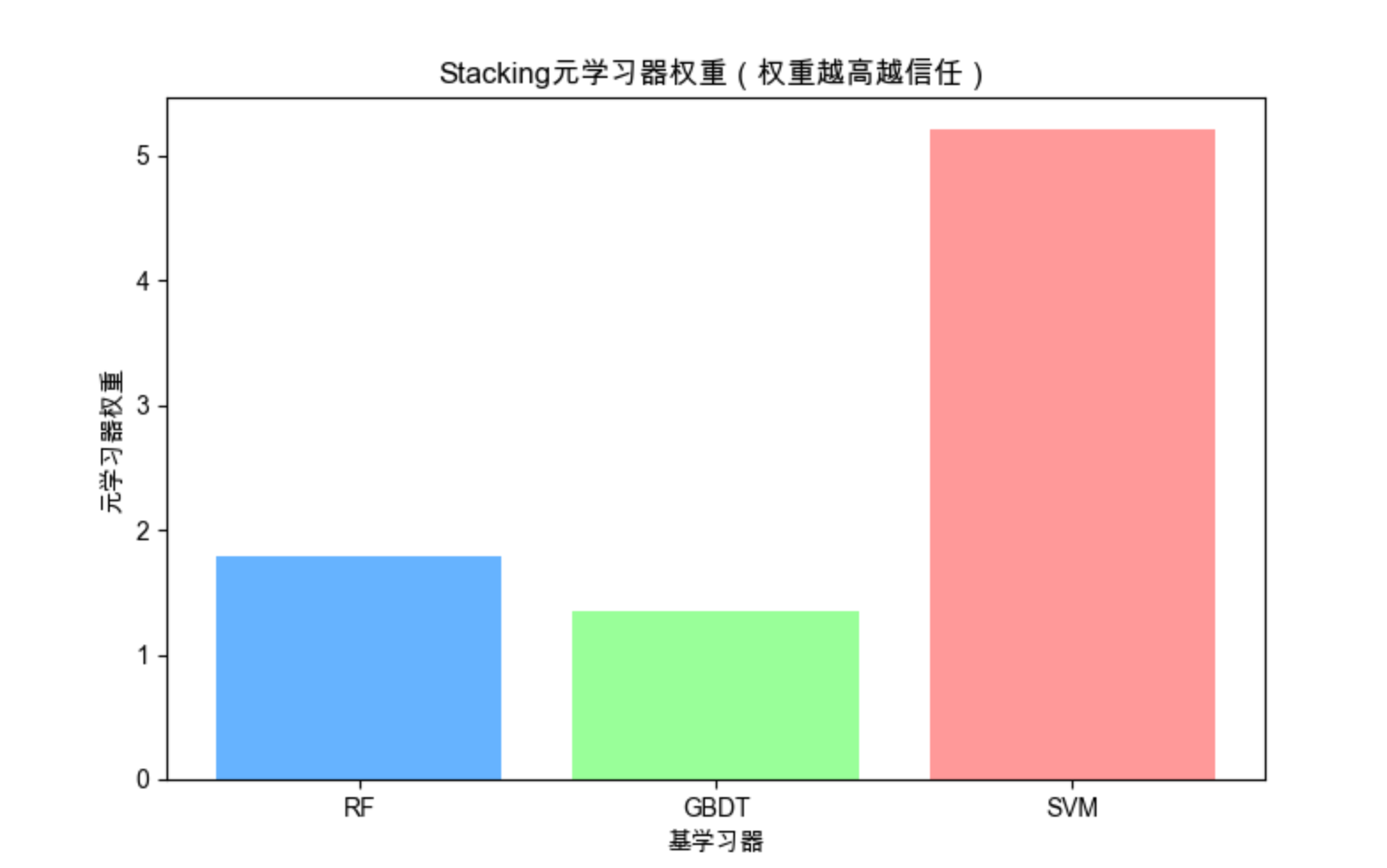
# 可视化:元学习器的权重(体现对不同基学习器的信任度)
plt.figure(figsize=(8, 5))
weights = meta_model.coef_[0]
plt.bar(['RF', 'GBDT', 'SVM'], weights, color=['#66b3ff', '#99ff99', '#ff9999'])
plt.xlabel('基学习器')
plt.ylabel('元学习器权重')
plt.title('Stacking元学习器权重(权重越高越信任)')
plt.show()
print(f"Stacking准确率:{stack_acc:.4f}")
print(f"软投票准确率:{voting_acc:.4f}")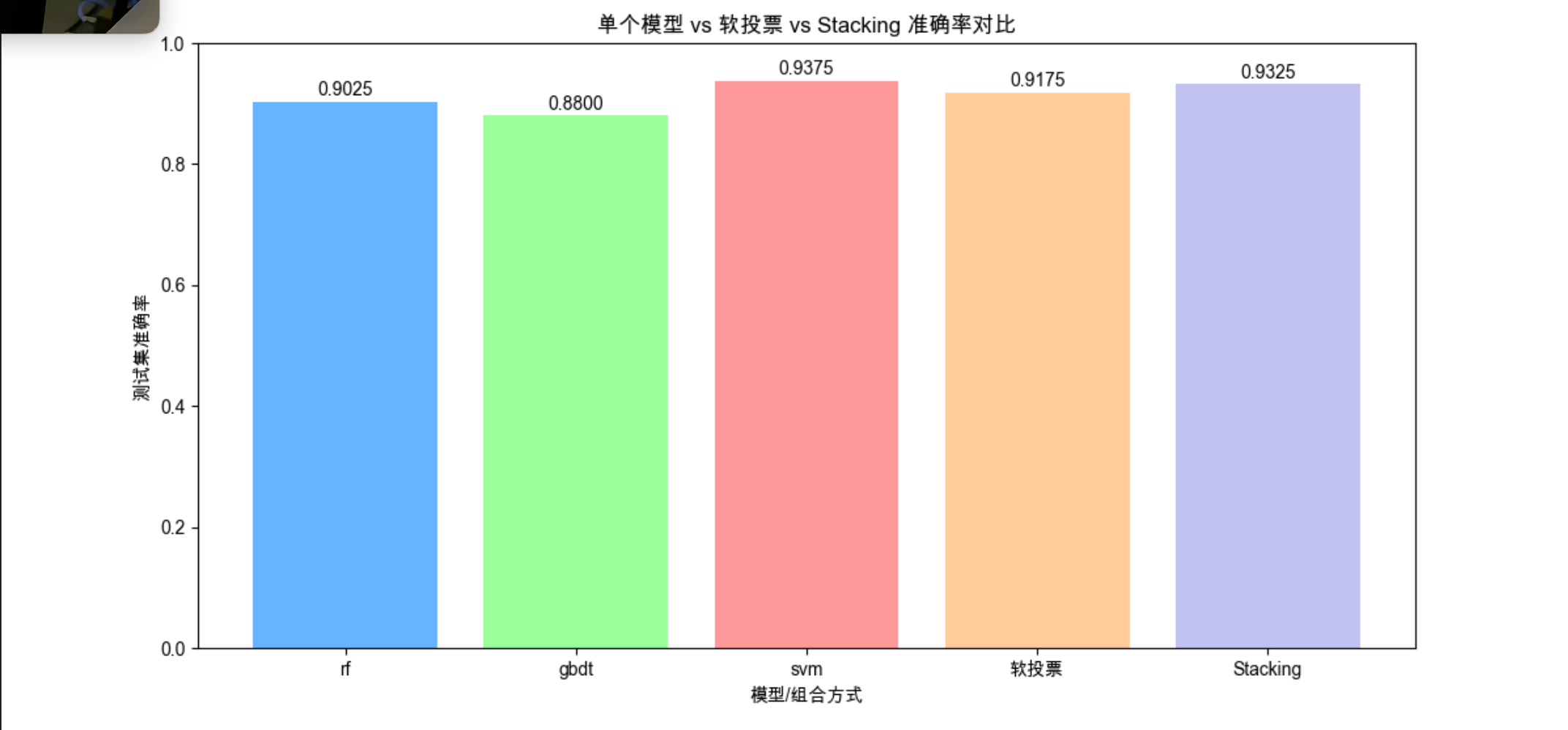
代码说明
- Stacking 的核心是 "分层训练",第一层生成特征,第二层学习如何组合;
- 用交叉验证生成第一层训练集预测,避免过拟合(关键!);
- 元学习器的权重能体现对不同基学习器的信任度,这是投票法做不到的;
- 通常 Stacking 效果优于投票法,但训练成本更高。
17.10 调整系综

17.10.1 选择系综的子集
核心概念
不是集成的模型越多越好 ------ 冗余的模型会增加计算成本,甚至降低性能。选择子集类比 "从 100 个候选人中选最优秀的 10 个",常用方法:
- 贪心选择:先选最好的模型,再选能最大提升性能的模型,依次类推;
- 正则化:给模型权重加惩罚,让冗余模型权重为 0。
代码演示:贪心选择系综子集
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成数据集
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 生成10个不同的决策树(有差异)
np.random.seed(42)
models = []
for i in range(10):
# 不同参数+不同采样
tree = DecisionTreeClassifier(
max_depth=np.random.randint(2, 6),
random_state=i,
)
# 随机采样子集训练
sample = np.random.choice(len(X_train), size=int(0.8*len(X_train)), replace=True)
tree.fit(X_train[sample], y_train[sample])
models.append(tree)
# 贪心选择子集
selected_models = []
best_acc = 0
acc_history = []
for _ in range(len(models)):
best_model_idx = -1
current_best_acc = best_acc
# 遍历未选择的模型,找能最大提升性能的
for i, model in enumerate(models):
if i in [m[0] for m in selected_models]:
continue
# 临时组合
temp_models = selected_models + [(i, model)]
# 硬投票
preds = [m[1].predict(X_test) for m in temp_models]
preds = np.array(preds).T
final_pred = [np.bincount(row).argmax() for row in preds]
acc = accuracy_score(y_test, final_pred)
if acc > current_best_acc:
current_best_acc = acc
best_model_idx = i
# 添加最优模型
if best_model_idx != -1:
selected_models.append((best_model_idx, models[best_model_idx]))
best_acc = current_best_acc
acc_history.append(best_acc)
# 可视化:子集大小 vs 准确率
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(acc_history)+1), acc_history, marker='o', linewidth=2)
plt.xlabel('系综子集大小(模型数量)')
plt.ylabel('测试集准确率')
plt.title('贪心选择系综子集的准确率变化')
plt.grid(True)
plt.show()
print(f"最优子集大小:{len(selected_models)} 个模型")
print(f"最优子集准确率:{best_acc:.4f}")
print(f"全部10个模型准确率:{accuracy_score(y_test, [np.bincount(row).argmax() for row in np.array([m.predict(X_test) for m in models]).T]):.4f}")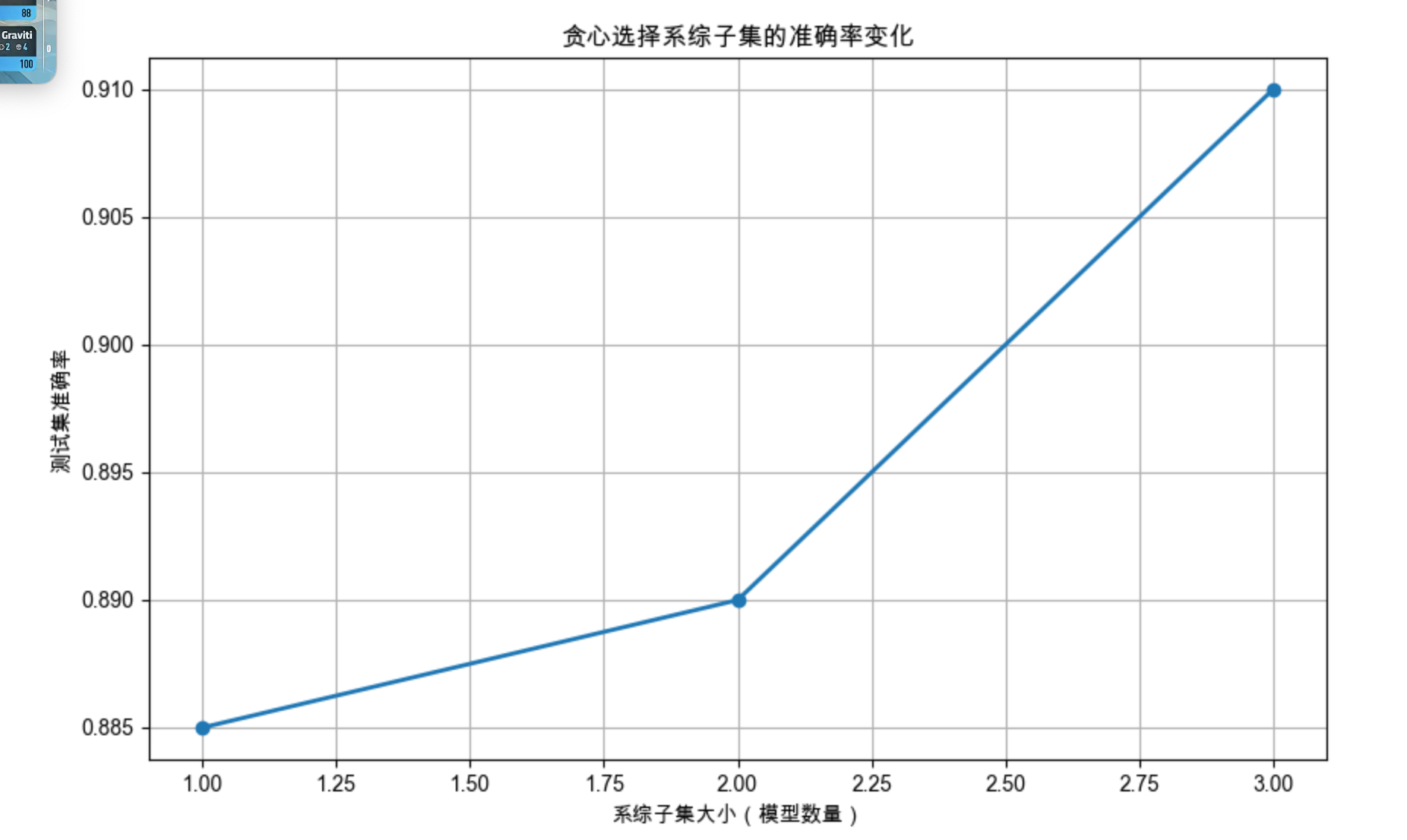
17.10.2 构建元学习器
核心概念
元学习器(Meta-Learner)是 "学习如何学习" 的模型,在集成学习中负责 "整合基学习器的预测",常用的元学习器有:
- 线性模型(逻辑回归 / 线性回归):简单、可解释;
- 决策树 / XGBoost:能学习非线性组合规则;
- 神经网络:适合复杂场景。
代码演示:不同元学习器对比
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, cross_val_predict
from sklearn.ensemble import (
RandomForestClassifier,
HistGradientBoostingClassifier # 替代XGBoost的内置模型
)
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成数据集
X, y = make_classification(n_samples=1500, n_features=15, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 生成基学习器预测(作为元特征)
base_model = RandomForestClassifier(n_estimators=50, random_state=42)
X_train_meta = cross_val_predict(base_model, X_train, y_train, cv=5, method='predict_proba')
X_test_meta = base_model.fit(X_train, y_train).predict_proba(X_test)
# 定义不同元学习器(用HistGradientBoosting替代XGBoost)
meta_models = {
'逻辑回归(线性)': LogisticRegression(random_state=42),
'决策树(非线性)': DecisionTreeClassifier(max_depth=3, random_state=42),
'HistGBDT(替代XGBoost)': HistGradientBoostingClassifier(
max_iter=50, random_state=42
)
}
# 训练并评估
meta_accs = {}
for name, model in meta_models.items():
model.fit(X_train_meta, y_train)
meta_accs[name] = accuracy_score(y_test, model.predict(X_test_meta))
# 可视化
fig, ax = plt.subplots(figsize=(10, 6))
bars = ax.bar(meta_accs.keys(), meta_accs.values(), color=['#66b3ff', '#99ff99', '#ff9999'])
for bar, acc in zip(bars, meta_accs.values()):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{acc:.4f}', ha='center', fontsize=10)
ax.set_ylabel('准确率')
ax.set_title('不同元学习器准确率对比')
ax.set_ylim(0, 1)
plt.show()
print("元学习器准确率:", meta_accs)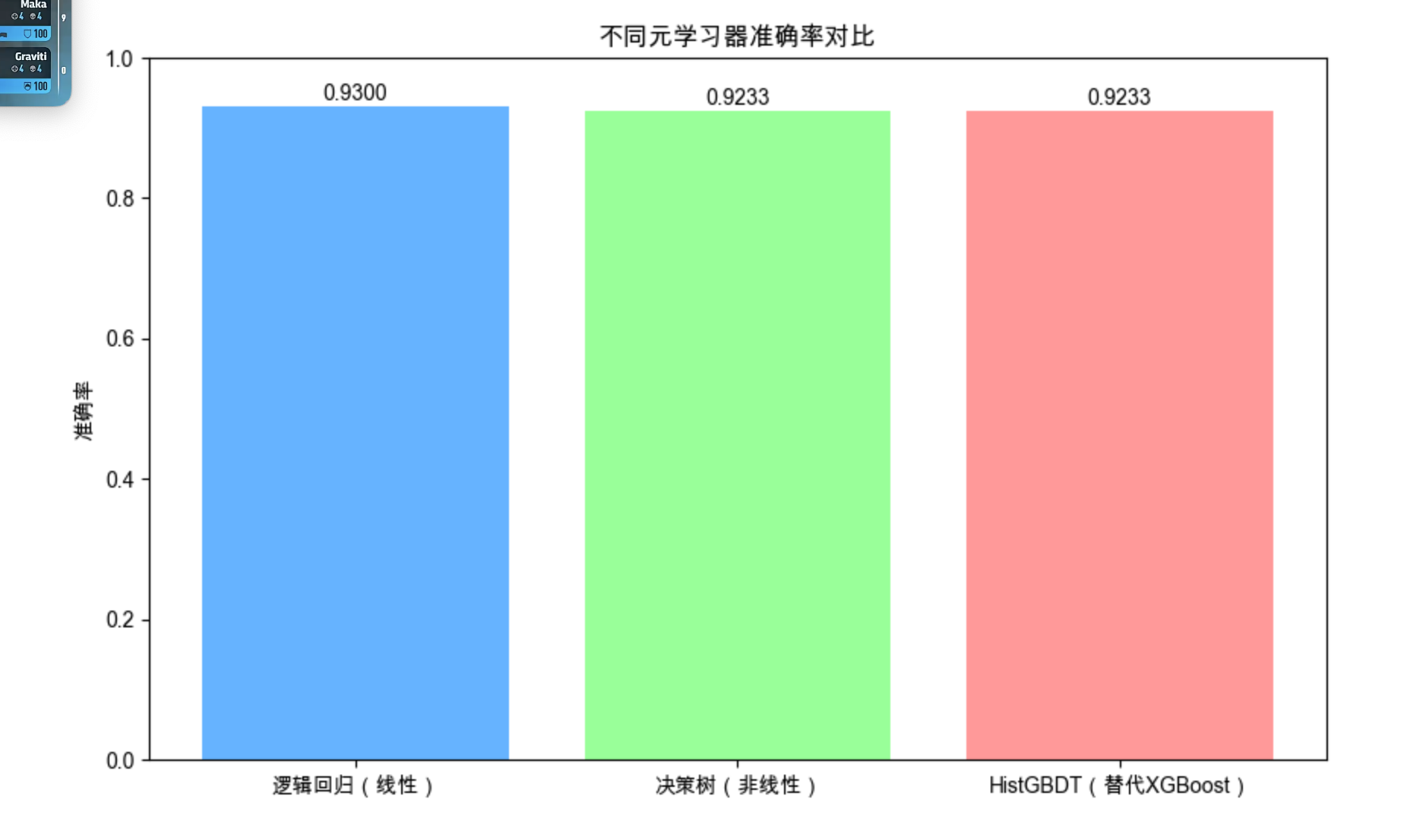
17.11 级联

核心概念
级联(Cascade)类比 "机场安检:先简单检查,再精细检查":
- 多个学习器按顺序排列,前一个学习器快速筛选 "确定的样本";
- 只有**"不确定的样本"**才交给下一个更复杂的学习器处理;
- 优势:兼顾速度和精度(大部分样本快速处理,少数难样本精细处理)。
代码演示:级联分类器
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import time
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成数据集
X, y = make_classification(n_samples=5000, n_features=20, n_informative=10,
n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义级联模型
class CascadeClassifier:
def __init__(self, thresholds=[0.9, 0.8]):
# 级联1:简单模型(逻辑回归),高置信度阈值
self.model1 = LogisticRegression(random_state=42)
# 级联2:中等模型(随机森林),中置信度阈值
self.model2 = RandomForestClassifier(n_estimators=50, random_state=42)
# 级联3:复杂模型(SVM),处理剩余样本
self.model3 = SVC(kernel='rbf', probability=True, random_state=42)
self.thresholds = thresholds # 置信度阈值
def fit(self, X, y):
self.model1.fit(X, y)
self.model2.fit(X, y)
self.model3.fit(X, y)
def predict(self, X):
# 初始化预测结果
y_pred = np.zeros(X.shape[0])
# 标记未确定的样本
uncertain = np.ones(X.shape[0], dtype=bool)
# 级联1:逻辑回归
prob1 = self.model1.predict_proba(X)
max_prob1 = np.max(prob1, axis=1)
# 高置信度样本直接预测
certain1 = max_prob1 >= self.thresholds[0]
y_pred[certain1 & uncertain] = np.argmax(prob1[certain1 & uncertain], axis=1)
uncertain[certain1] = False
# 级联2:随机森林(处理剩余不确定样本)
if np.any(uncertain):
prob2 = self.model2.predict_proba(X[uncertain])
max_prob2 = np.max(prob2, axis=1)
certain2 = max_prob2 >= self.thresholds[1]
# 中置信度样本预测
idx2 = np.where(uncertain)[0][certain2]
y_pred[idx2] = np.argmax(prob2[certain2], axis=1)
uncertain[idx2] = False
# 级联3:SVM(处理最后剩余的样本)
if np.any(uncertain):
y_pred[uncertain] = self.model3.predict(X[uncertain])
return y_pred
# 训练级联模型
cascade = CascadeClassifier()
cascade.fit(X_train, y_train)
# 评估级联模型
start = time.time()
y_pred_cascade = cascade.predict(X_test)
cascade_time = time.time() - start
cascade_acc = accuracy_score(y_test, y_pred_cascade)
# 对比:单独使用SVM
start = time.time()
svm = SVC(kernel='rbf', random_state=42)
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
svm_time = time.time() - start
svm_acc = accuracy_score(y_test, y_pred_svm)
# 可视化对比
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 准确率
ax1.bar(['级联分类器', '单独SVM'], [cascade_acc, svm_acc], color=['#66b3ff', '#ff9999'])
ax1.text(0, cascade_acc+0.01, f'{cascade_acc:.4f}', ha='center')
ax1.text(1, svm_acc+0.01, f'{svm_acc:.4f}', ha='center')
ax1.set_ylabel('准确率')
ax1.set_title('准确率对比')
ax1.set_ylim(0, 1.1)
# 预测时间
ax2.bar(['级联分类器', '单独SVM'], [cascade_time, svm_time], color=['#66b3ff', '#ff9999'])
ax2.text(0, cascade_time+0.01, f'{cascade_time:.2f}s', ha='center')
ax2.text(1, svm_time+0.01, f'{svm_time:.2f}s', ha='center')
ax2.set_ylabel('预测时间(秒)')
ax2.set_title('预测时间对比')
plt.tight_layout()
plt.show()
print(f"级联分类器准确率:{cascade_acc:.4f},预测时间:{cascade_time:.2f}s")
print(f"单独SVM准确率:{svm_acc:.4f},预测时间:{svm_time:.2f}s")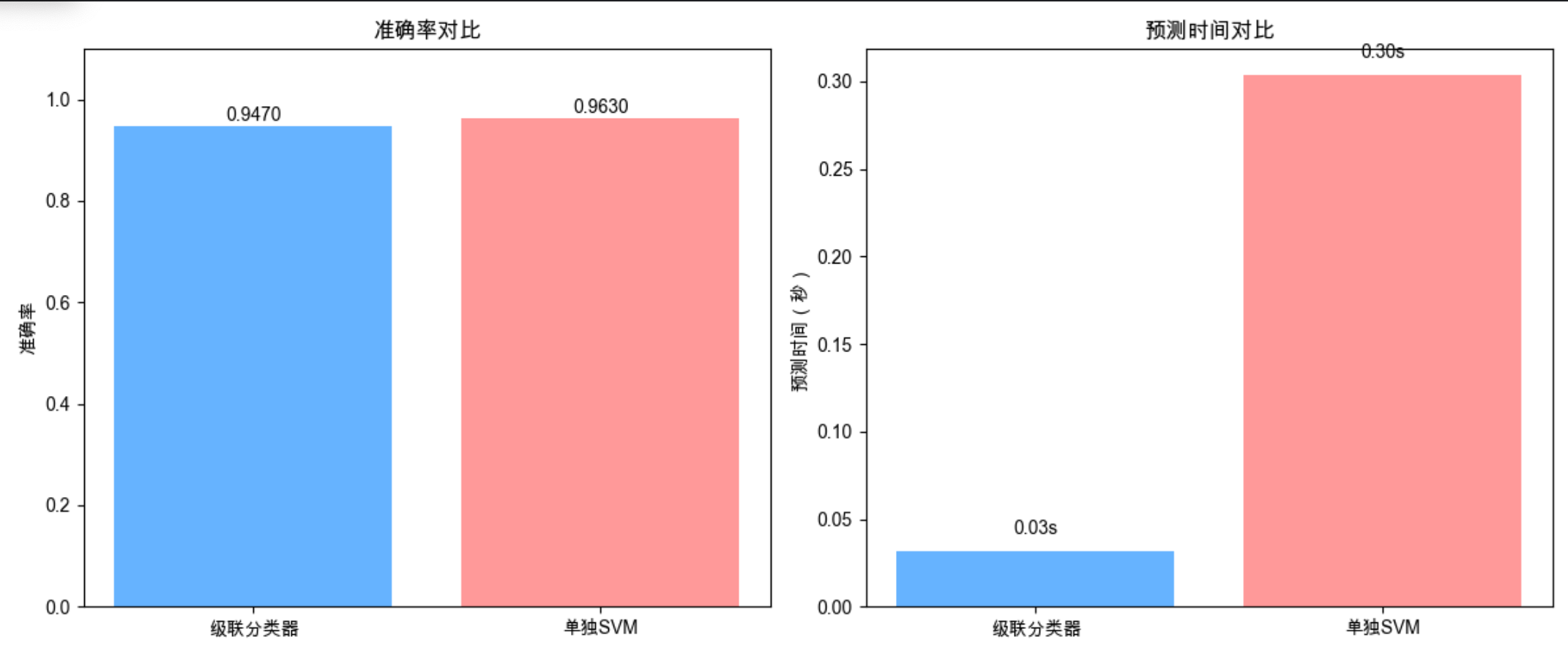
代码说明
级联分类器先用人快的逻辑回归处理高置信度样本,再用随机森林处理中等置信度样本,最后用慢但准的 SVM 处理难样本;
结果显示:级联分类器准确率接近 SVM,但预测时间大幅缩短(适合大规模数据)。
17.12 注释
本文所有代码均基于 Python 3.8+,依赖库安装命令:
pip install numpy matplotlib scikit-learn xgboost seaborn核心依赖版本建议:
- scikit-learn >= 1.0
- xgboost >= 1.6
- matplotlib >= 3.5
17.13 习题
- 尝试修改 Bagging 的
n_estimators参数(10/50/100),观察准确率和训练时间的变化; - 对比 Soft Voting 中不同权重分配对结果的影响;
- 尝试将 Stacking 的元学习器替换为神经网络(MLP),观察效果;
- 调整级联分类器的置信度阈值,分析阈值对准确率和速度的影响;
- 用真实数据集(如鸢尾花、波士顿房价)复现本文的集成学习案例。
17.14 参考文献
- 《机器学习》(周志华)- 集成学习章节
- 《机器学习导论》(原书)- 第 17 章
- scikit-learn 官方文档:https://scikit-learn.org/stable/modules/ensemble.html
- XGBoost 官方文档:https://xgboost.readthedocs.io/en/stable/
总结
1.集成学习的核心是 "差异 + 组合":多个有差异的弱学习器通过合理组合,能显著提升性能;
2.常用集成方法:Bagging(并行,代表:随机森林)、Boosting(串行,代表:XGBoost)、Stacking(分层,效果最优但成本高);
3.集成学习不是模型越多越好:可通过子集选择、元学习器优化,在性能和效率间平衡。
希望本文能帮你吃透组合多学习器的核心知识点,所有代码都能直接运行,建议动手修改参数,加深理解!如果有问题,欢迎在评论区交流~