
目录
一、明星登场:三种"中国方案"同台竞技,切磋国产大模型真功夫!
[1. 文心4.5:多模态异构MoE,请叫我国产首个"全能选手"!](#1. 文心4.5:多模态异构MoE,请叫我国产首个“全能选手”!)
[2. Qwen3.0:国内首个"混合推理模型"](#2. Qwen3.0:国内首个“混合推理模型”)
[3.DeepSeek R1:模型领域的出圈王者](#3.DeepSeek R1:模型领域的出圈王者)
[1. 中文理解与创作:文心本土化优势显著](#1. 中文理解与创作:文心本土化优势显著)
我们来看一个测试例子:请对"长安的荔枝"为什么难运输以及应该如何运输进行经济学解读和分析。
咱们再举一个例子:请帮我续写一段未来人类征服宇宙的科幻小说。
下面咱们再来看一下古文理解:请帮我解读"日照香炉生紫烟,遥看瀑布挂前川,飞流直下三千尺,疑是银河落九天"。这几句诗。
[2. 逻辑推理:Qwen3"慢思考"能力出众,文心4.5、Deepseek-R1不弱下风](#2. 逻辑推理:Qwen3“慢思考”能力出众,文心4.5、Deepseek-R1不弱下风)
[我们再试验一道题,这次上一点难度:已知函数y=2x-1,若函数的图像上存在一点P,使得OP=3,则点P的坐标 是()](#我们再试验一道题,这次上一点难度:已知函数y=2x-1,若函数的图像上存在一点P,使得OP=3,则点P的坐标 是())
[3. 多模态理解:文心原生支持一骑绝尘](#3. 多模态理解:文心原生支持一骑绝尘)
开场:
2025年是中国大模型开源爆发之年------百度文心4.5系列横空出世,阿里通义Qwen3.0登顶开源榜首,而DeepSeek R1在编程领域悄然登顶。
国产大模型三强争霸,谁主沉浮?
在这场技术与生态的较量中,谁更适合中文长文本?
谁更懂逻辑推理?
谁在产业落地中更胜一筹?
谁才是国产第一大模型?
你可能不在乎这些讨论,但是如果把他们当成三个调皮的学生来一场"随堂小测验",我相信你一定会被下面它们精彩的答题表现所吸引。
各位小伙伴,就让我们一起来体验一把,AI究竟有多靠谱或者有多搞笑?
本文从语文、数学、综艺三门开考,看看三大模型谁更强,谁最符合国人体验,咱们实测见真章!
一、明星登场:三种"中国方案"同台竞技,切磋国产大模型真功夫!
1. 文心4.5:多模态异构MoE,请叫我国产首个"全能选手"!
2025年6月30日,百度正式开源文心4.5系列模型,包含47B/3B MoE及0.3B的小模型,最大总参数量达424B,最小就0.3B, 主打一个双向做到极致!它还创新性提出"跨模态参数共享机制"------在保持文本能力的同时增强多模态理解能力。
好家伙,这一波文心是卯足了劲"放大招"啊!
我们来看官方介绍:

亮点满满!
更新后它的界面长这样,可以看到维持了之前一贯的简约大气风格:
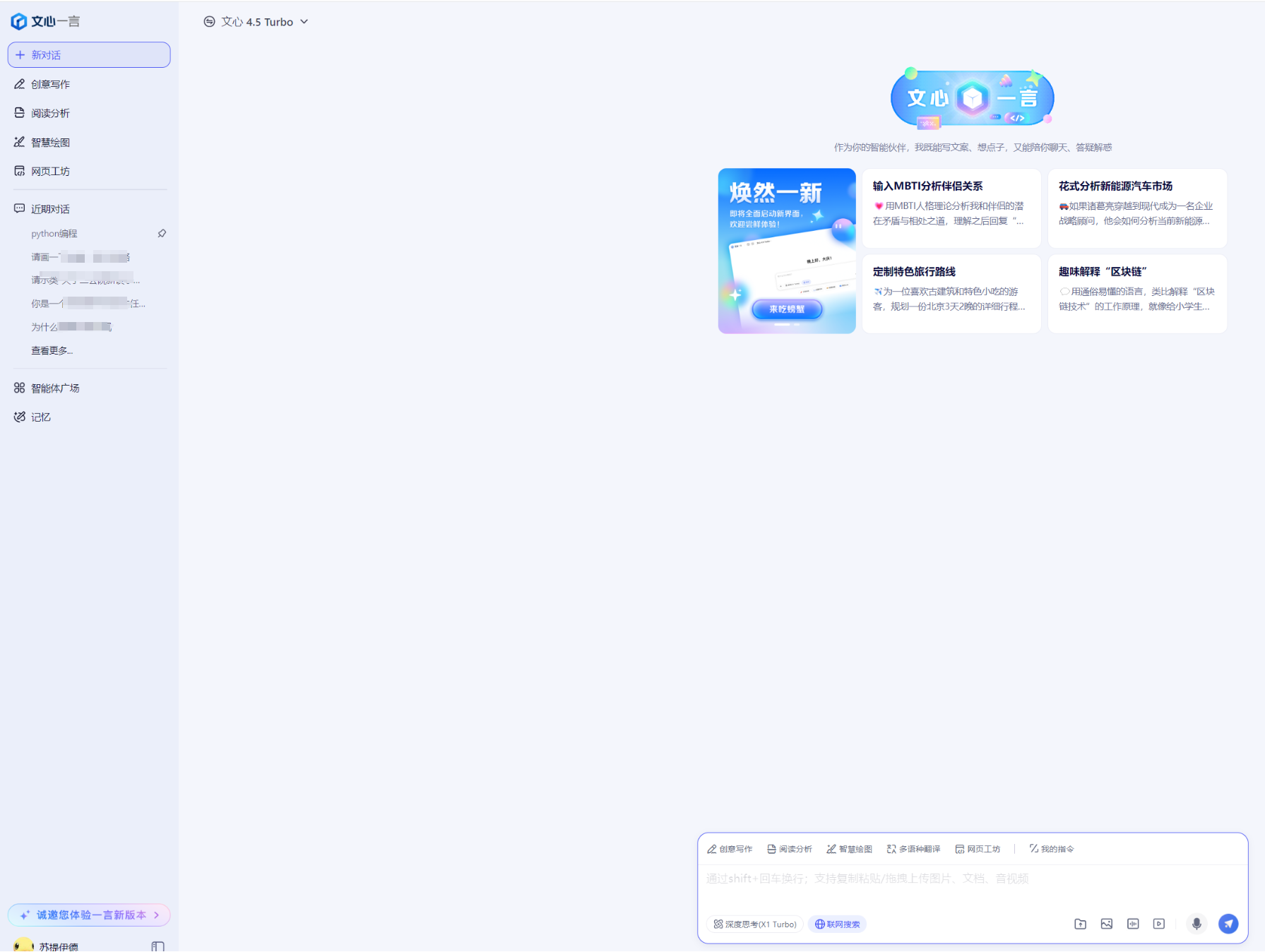
文心大模型更新后其独有的技术卖点主要体现在,其独有的优化多模态异构混合专家模型(MoE)结构方式:将视觉与文本专家层异构融合,从而支持多模态的文本理解和生成。
在性能上,文心4.5-300B在28项基准测试中有22项领先DeepSeek-V3,21B轻量版的实测效果已经优于Qwen3-30B1,中文逻辑推理能力更是直接被业界"封神"!
就问你服不服?
2. Qwen3.0:国内首个"混合推理模型"
阿里Qwen3于2025年4月发布,它性能号称全面超越R1、OpenAI-o1等全球顶尖模型,以235B总参数 + 22B激活参数 的MoE设计,成本仅为DeepSeek R1的1/3的优势,问鼎全球开源模型性能榜首。。
Qwen3自称是国内首个"混合推理模型","快思考"与"慢思考"集成进同一个模型,对简单需求可低算力"秒回"答案,对复杂问题可多步骤"深度思考",大大节省算力消耗。
它现在的界面长这样:
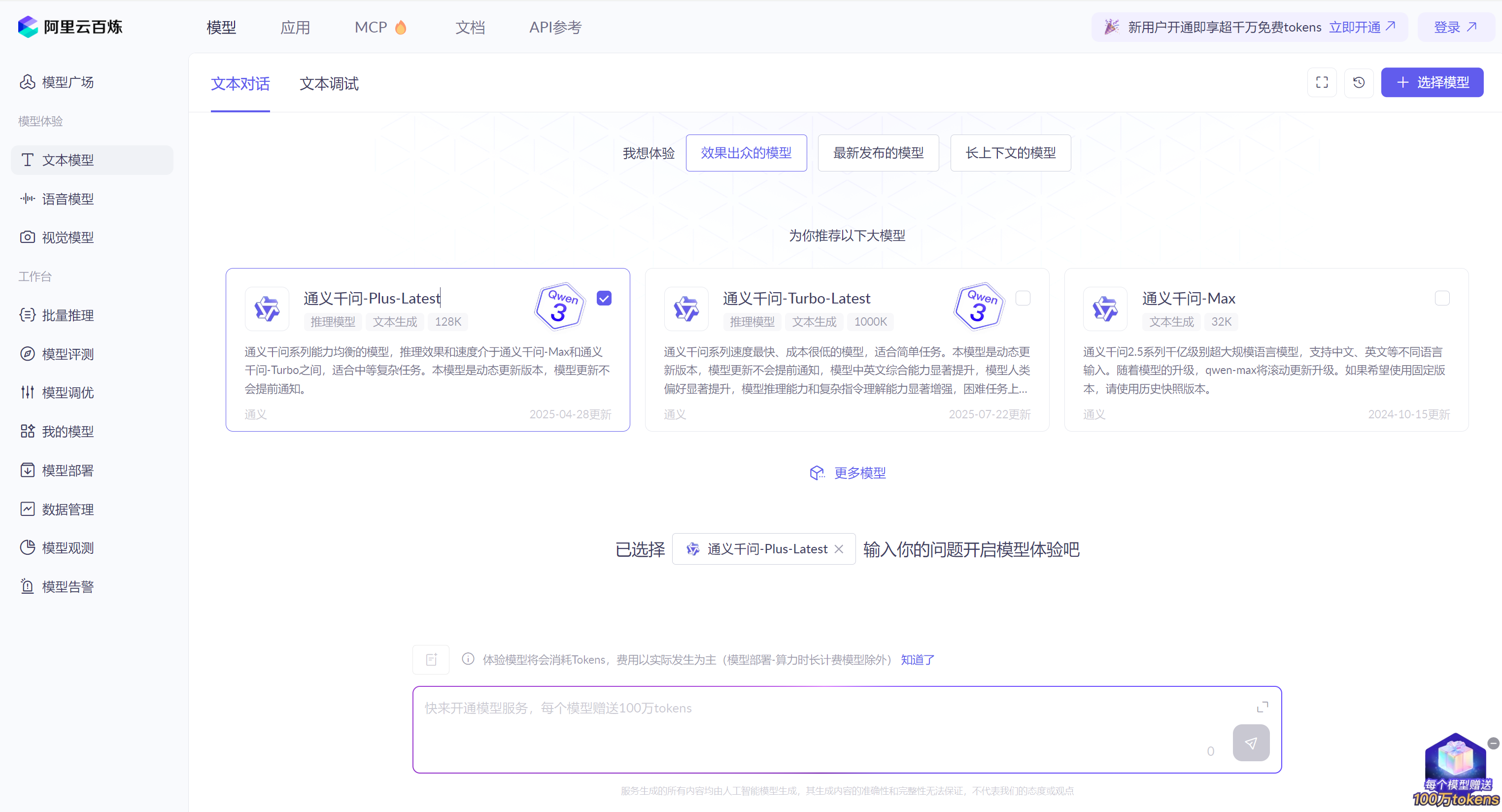
可能有小伙伴看到它这个界面会感到疑惑?
怎么有两个Qwen3,到底用哪个呢?
如图我们可以看到Qwen3的通义千问-Plus-Latest,它是通义千问系列能力均衡的模型,推理效果和速度介于通义千问-Max和通义千问-Turbo之间,适合中等复杂任务。本模型是动态更新版本。
通义千问-Turbo-Latest同样是Qwen3,号称通义千问系列速度最快、成本很低的模型,适合简单任务。
本模型是动态更新版本,模型更新不会提前通知,模型中英文综合能力显著提升,模型人类偏好显著提升,模型推理能力和复杂指令理解能力显著增强,困难任务上的表现更优,数学、代码能力显著提升。
可以观察到Qwen3的两种模型各有特色,很好的把握了不同用户需求进行了细分。
但是美中不足的事是,Qwen3体验模型将会消耗Tokens,这不禁让我们有些望而生畏。虽说新用户号称赠送了100万tokens,但是不断跳动增长的数字总让人不敢放心大胆地使用,这一点相对于其他两家模型的完全免费使用,未免显得有些不够大气了。
综合来看,其最大创新是**"快思考+慢思考"混合推理**:
-
快思考模式:对简单查询(如天气、翻译)低算力响应。
-
慢思考模式 :对数学证明、代码生成等启用多步深度推理。
用户可设置"思考预算"(1024-38912 tokens),按需分配算力。
Qwen3在AIME25奥数测评中斩获81.5分 (超DeepSeek R1达12%),在Agent能力评测BFCL中以70.8分超越Gemini 2.5-Pro。
不得不说,单从技术能力来看,Qwen3发展势头确实迅猛!
3.DeepSeek R1:模型领域的出圈王者
DeepSeek R1自今年年初爆火以后,当时几乎达到国民皆知,家喻户晓的程度,但是后续一直没有大的动作,热度近期似乎也有所下降,这可能和其对不太在意应用市场的发展战略有关。
它的界面也维持了之前一开始的风格没有丝毫变化。

虽然它未发布新一代架构,DeepSeek却在2025年5月底通过一次低调更新,代码能力跃居全球第一梯队 ------在LMArena的WebDev Arena排行榜中与Claude 4、Gemini 2.5 Pro并列第一,成为开源模型编程王者。
其优势集中在:
-
复杂提示词理解(全球第4)。
-
工程级代码生成与修复(如精准定位Bug及修复能力)。
-
数学能力(全球第5)。
在实测中,R1能根据自然语言描述修复代码缺陷,展现强大的逻辑-语言协同能力。就我使用过的诸多模型来说,不得不说R1的思维逻辑能力确实仍然站在国产大模型的巅峰位置。
二、能力实测:语言、推理、代码、多模态,谁是王者?
1. 中文理解与创作:文心本土化优势显著
我们来看一个测试例子:请对"长安的荔枝"为什么难运输以及应该如何运输进行经济学解读和分析。
面对一模一样的问题,我们看看各家大模型分别是如何响应的呢?
第一个出场的是文心4.5 Turbo,我们来看看它的表现究竟如何:

第二个出场的是Deepseek-R1,我们也看看它如何反应:

第三个出场的是通义千问-Turbo-Latest(Qwen3.0),表演如下:

通过对比可以看出,文心的中文理解能力和语言组织能力简直登峰造极,不仅很好的理解了问题,而且成本分析清晰,思考非常深入,和Deepseek大量引用文献来作为答案依据不同,文心确实表现出来了独有的思考,我觉得这正是考验模型能力的地方。相比之下Qwen3的分析也给人一种浅尝辄止,人云亦云的感觉。
比如说,文心写到的:
"据测算,单次运输需消耗驿马217匹、驿卒数十人,仅贵妃诞辰所需的5000斤荔枝,耗资相当于现代千万级成本。每颗荔枝的运输成本高达100贯(约合现代126元),其中94%用于竹筒耗材、人力畜力等对抗损耗的无效投入,而损耗率超过90%。这种"用90%的资源浪费换取10%的有效供给"的模式,违背了经济学中"边际成本=边际收益"的基本原则,属于典型的非理性资源配置。"
文心4.5对历史故事背后的经济规律进行数学分析,建立了非常具体的模型,体现了其主观深入思考和量化模型的能力,这也是其他两个模型所不能及的。
同时,文心还给出了相对更加完善的解决方案,建议符合实际且基本合理,相对于其他两家大模型略显泛泛而谈的答案,文心4.5明显更胜一筹。
总的来说,相对于另外两家模型,文心在语言造诣上明显已经更加成熟,"机器味 "明显更淡化。
咱们再举一个例子:请帮我续写一段未来人类征服宇宙的科幻小说。
第一个出场的是文心4.5 Turbo,我们看看它如何写:

第二个出场的是Deepseek-R1,我们也看看它的表现:

第三个出场的是通义千问-Turbo-Latest(Qwen3.0),表演如下:

从在毫无额外提示的情况下,这个科幻小说的撰写情况咱们也能看出文心写作这一块真的是嗷嗷的猛!
我觉得这个例子是非常有表现力的。
文心4.5中文写作水平确实有些令人惊叹。剧情的逻辑清晰合理,故事背景交代得很清楚,显示它思维较为缜密。同时,对场景和人物的神态、心理活动等细节刻画也基本到位了,有比较好的"沉浸式"阅读体验。
相比之下,Deepseek只给出了一段前言不搭后语的小说片段,内容天马行空,一段主题和下一段主题之间过渡非常生硬,细看小说的很多概念生搬硬造,有些不切合实际,逻辑完全不合理,而且似乎受到了之前上下文其他问题内容的影响,无法主观判断哪些问题内容和本次的问题是无关的,所以东扯西拉,一本正经的胡说八道,这一点是它的弱点。
而通义千问Qwen3.0的回答更短,写作方面浅尝辄止,对人物和场景缺乏刻画,段落之间没有明显联系和过渡,写得更加只像是一段大纲,而非剧情。
我们知道如何评价一个AI到底像不像人?
主要体现在它能否像人一样连续思考,文字描写不是为了堆砌,而是聚焦剧情走向服务。描写的人物语言和行为要符合他当前的身份和处境。AI由于没有生活经历,所以很难身临其境的去想象人物真实的心理活动,因此它只能瞎编。
写作的基本六要素,时间地点人物,起因经过结果。连小学生都知道。
那么AI能否准确理解并表达呢?
我觉得就目前来看大部分AI是做不到的。
很多AI根本无暇顾及六要素,写的内容各种语料杂糅堆砌,毫无章法。
AI写作非常给人一眼就感觉非常"生硬",七拼八凑,完全不知道在写什么的感觉。
有些高级一点的倒是勉强能够满足六要素。但是剧情依旧是支离破碎的,经不起推敲。原因就在这里。
剧情发展要符合人的期望,做到"意料之外,情理之中",却又不能太过俗套,要有新创意,这一点对于AI就很难做到,因为它的模型生成底层逻辑是没有这个的。
一切描写都是围绕人物活动展开的,而人物活动又为推动剧情的演绎服务,在不同人物的交锋之下,制造冲突、伏笔、悬念、高潮,从而引人入胜,这才是人的写作思路。
总的来说,文心4.5是在目前中文语境之下唯一对情节把握较好的大模型,已经基本能做到让文字围绕主题刻画人物和推动剧情发展,并且细节经得起推敲没有太大的漏洞和诡异,写出来的故事已经非常流畅和丰富了。这一点文心4.5完胜!
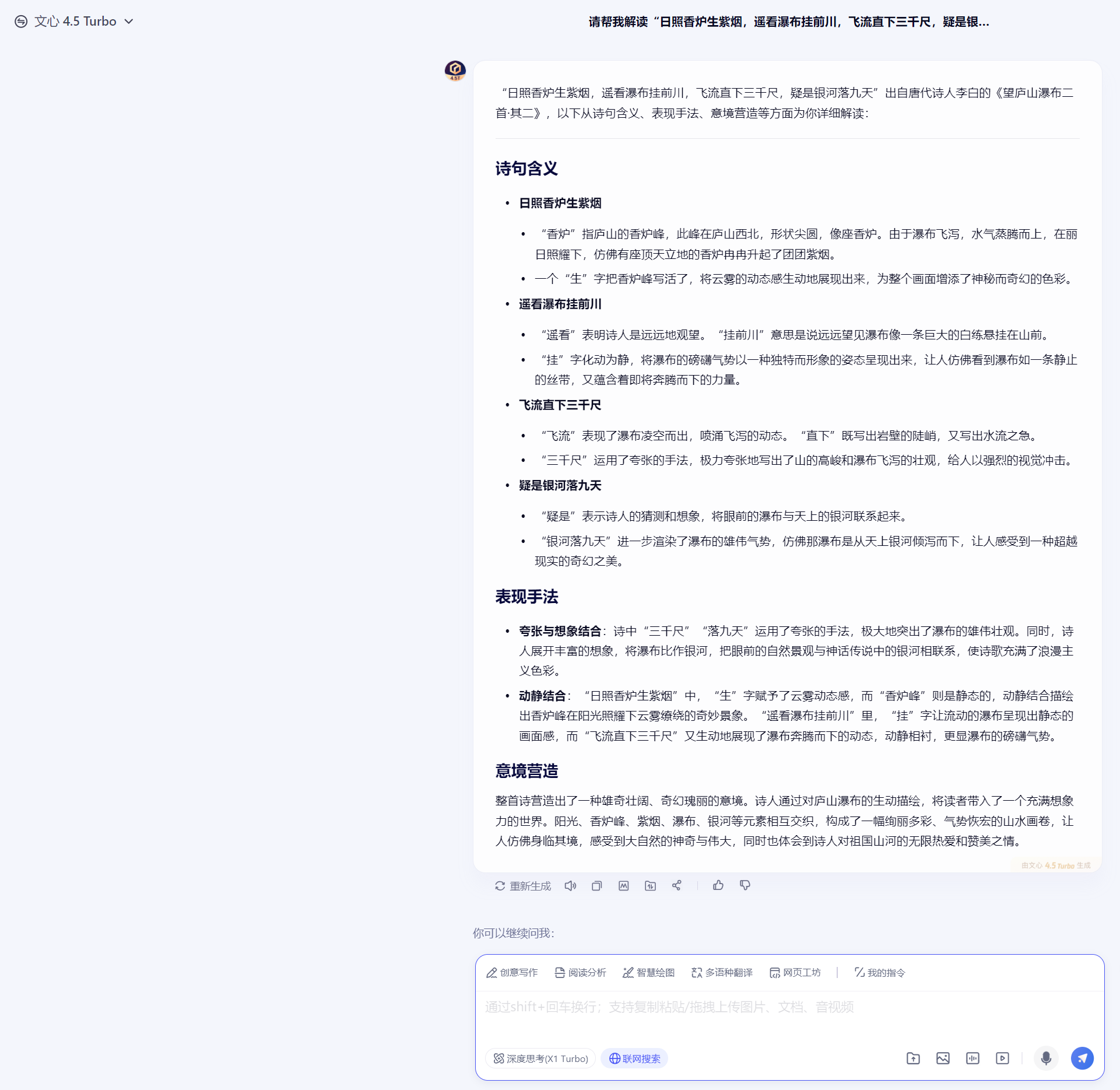
下面咱们再来看一下古文理解:请帮我解读"日照香炉生紫烟,遥看瀑布挂前川,飞流直下三千尺,疑是银河落九天"。这几句诗。
第一个出场的是文心4.5 Turbo:
第二个出场的是Deepseek-R1:

第三个出场的是通义千问-Turbo-Latest(Qwen3.0):

兄弟们,没有对比就没有伤害啊!
文心真的像一个中学语文老师班主任一样逐词帮我们解析了这首诗的含义,它对意境理解完全正确,语言表述和描绘能力较强,从学习角度来说堪称范本!
妈妈再也不用担心我的学习啦有没有?
Qwen3.0虽然知道要解析诗句,也解析得还不错,但是对具体的具象却还不够具体和细致,总的来说与文心差距不是太大。
而Deepseek-R1的回答就有些天马行空了,哈哈!什么丁达尔效应和星际都整出来了,简直又在一本正经的胡说八道。后面更是各种玄学杂糅,感觉它都不知道自己在说些什么的样子。它受上下文影响其实挺大的,很容易被用户不经意间带歪从而跑偏。
综合上述三项测试,总结如下:
文心4.5 :在含义解读、文学作品、古文翻译之类的中文内容生成方面表现精准出色。Qwen3 次之,而DeepSeek R1目前在语文水平方面确实还有待提升,嗯,特别是想提醒这位AI仁兄还是尽量不要强行答题,应该做到"知之为知之,不知为不知"比较好,哈哈!
2. 逻辑推理:Qwen3"慢思考"能力出众,文心4.5、Deepseek-R1不弱下风
我们再来比较一下逻辑理解的能力。
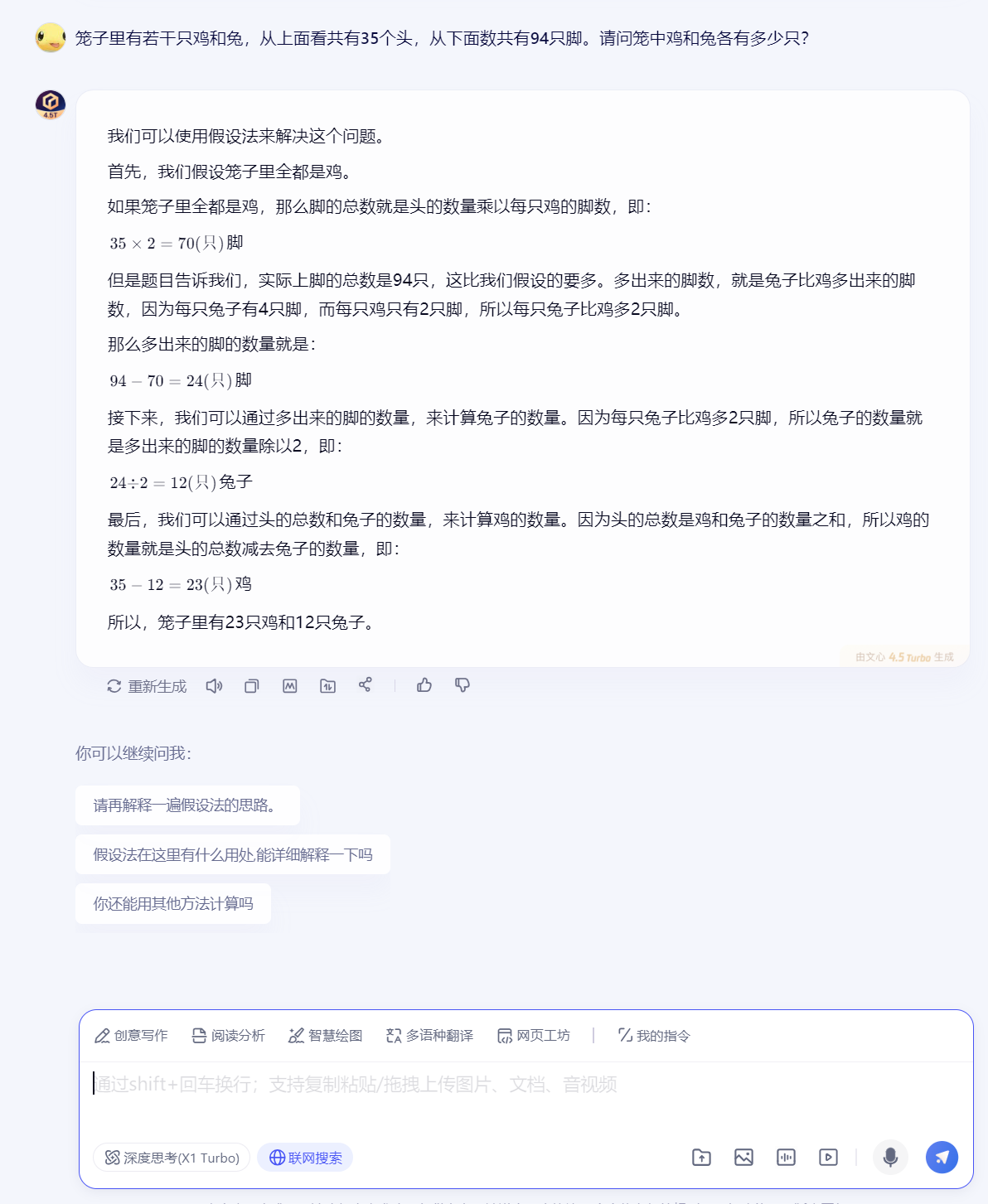
出一个鸡兔同笼数学题考考它们:
文心4.5同学作答如下:
Deepseek-R1同学作答如下:

Qwen3.0同学作答如下:

可以看到这个问题三家都非常快速的给出了正确答案,都非常优秀!
区别是文心给出的计算过程是最简洁直观的,Deepseek选择列方程解答,过程很完美,Qwen3.0两种方法都使用了,都算成了正确答案并且相互验证,表现略优!
我们再试验一道题,这次上一点难度:已知函数y=2x-1,若函数的图像上存在一点P,使得OP=3,则点P的坐标 是()
文心4.5同学作答如下:

Deepseek-R1同学作答如下:


这是一道高考数学的模拟题,作为一个理科硕士毕业生,我看着都直呼"脑阔疼!"
本题涉及到构建并解二维集合方程,难度不算小,从上面来看三家均在2分钟内完成了,并计算得出正确答案。说明国产大模型的逻辑计算能力都已经非常强悍了!
我给三位 学霸跪一个!请收下我的膝盖吧!
这一块区分度不算太大。我们看下一个领域的PK。
3. 多模态理解:文心原生支持一骑绝尘
多模态方面文心4.5已经做到能解析图片内容。
上传这样一张图片看各个模型解析图片情况。

文心4.5解析如下:
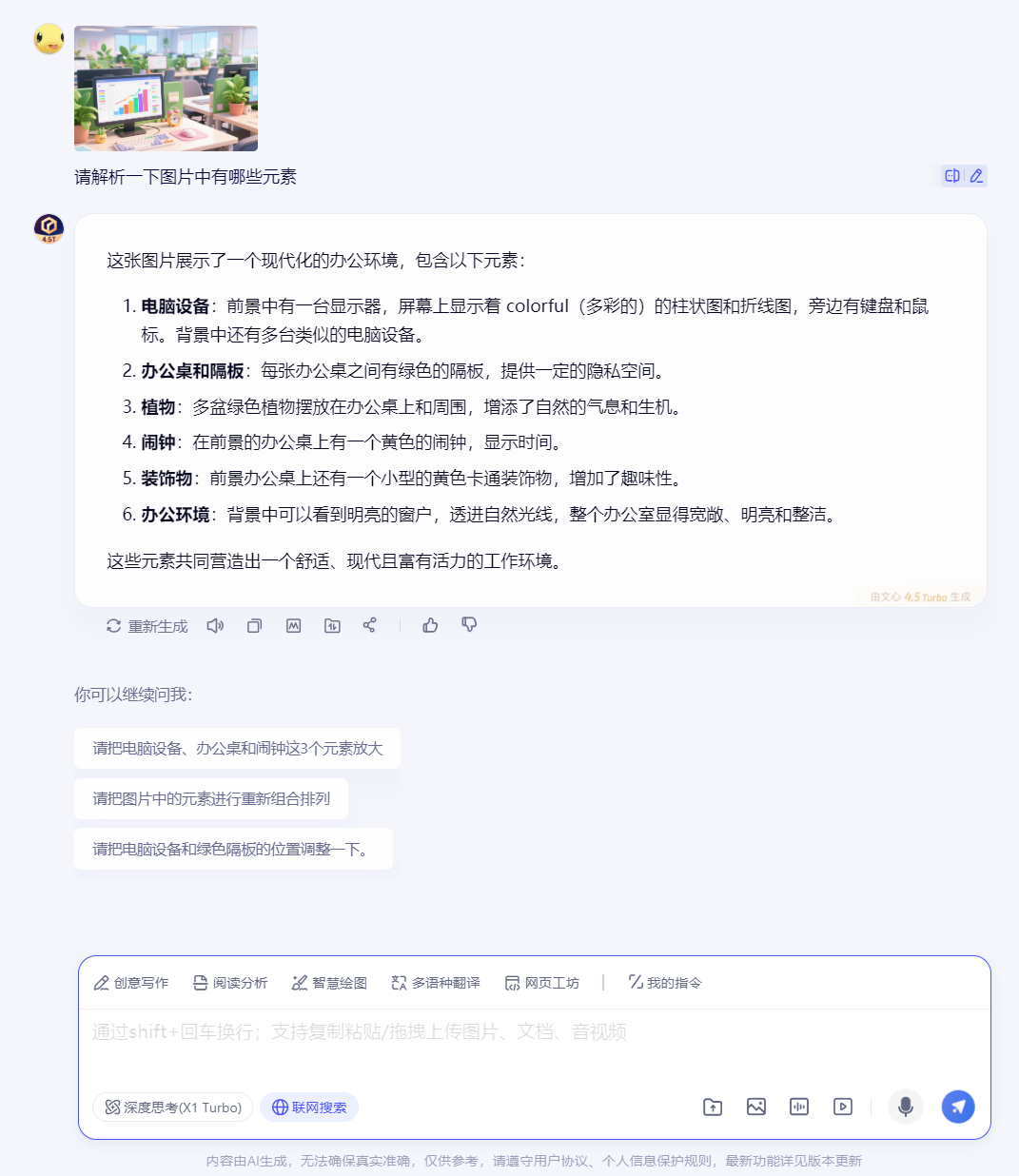
这里不得不说,文心4.5 作为国产首个原生多模态大模型,可解析漫画隐喻、关联知识点,支持图文声像融合理解,多模态的能力也已经拉满。
Deepseek告诉我它解析不了图片,只能提取图片中的文字:

而通义千问-Turbo-Latest是个纯文本模型,无法上传图片。让我很无奈啊!

于是我特地找到了它的兄弟来代考一下,我们使用通义千问VL-Max试试。

可以看到,这位兄弟解析多模态图片的效果也还不错。
综上,文心4.5在多模态处理能力方面确实已经能做到充分理解图文含义,主打一个全能小能手!
Qwen3与DeepSeek R1则是仍以文本为主,多模态需依赖额外插件或专有模型。
三、生态与应用:落地成本决定产业选择
我们知道对于大模型应用来说生态也是至关重要的。就像移动互联网时代Andorid能击败WinPhone、黑莓、塞班等一众系统,根源上就是开发者应用太过庞大,这是生态的胜利。说明走群众路线才是对的!
特别是在当前环境下,国产大模型生态处于起步阶段,各种应用和理论知识都面临一个真空期,是抢占机会的好时候!
谁能主导行业联盟形成规则垄断,谁就掌握了下一代AI应用入口的绝对话语权!
文心4.5正是因为意识到这一点而选择了拥抱开源生态,文心4.5已将代码在gitcode开源,其与PaddlePaddle的合作,依托飞桨平台服务2185万开发者,背后的应用生态非常强大。
同时,Qwen3则背靠Modelscope社区的良好环境,全球下载量突破3亿次,超越Llama成最大开源社区。实力也不容小觑。
Deepseek虽然曾经爆火一时,但未着手建立自身的生态应用护城河,导致没有办法持续维持和制造高粘性用户群体,目前来看在与开源文心4.5系列大模型的竞争中将逐渐处于劣势。
开源生态对比如下:
| 模型 | 开源协议 | 衍生模型数 | 部署门槛 |
|---|---|---|---|
| Qwen3 | Apache 2.0 | 超10万个 | 4张H20即可部署 |
| 文心4.5 | Apache 2.0 | 110万个 | 支持手机端0.3B模型 |
| DeepSeek | 未完全开源 | 较少 | 需企业级显卡 |
技术没有绝对胜者,只有场景之王。
经过上述实际评测对比,我认为文心4.5总体而言具有非常大的优势,它胜在多模态与中文场景能力过于强大,DeepSeek目前在代码与工程化上还可以,Qwen3则需要通过效率和生态下功夫。
我们可以做一下简单的典型场景推荐,在教育智能体等中文应用方面,毫无疑问优先选文心4.5,处理比如文学创作、多模态图文生成、课堂互动知识讲解等等方面。逻辑计算及编程助手总体来说可以考虑选DeepSeek R1,企业Agent开发方面可以考虑选Qwen3,其支持MCP协议,工具调用和环境构建较为高效。
推理成本方面:
大模型的建设从来都不是平民玩家的游戏,巨大的算力成本投资门槛让很多中小企业直接放弃自研路线,无论模型选择免费还是按token计费,其背后的基础设施运维和人力成本仍然不容小视。Qwen3 的API调用仅4元/百万token ,成本为DeepSeek R1的1/4。文心4.5 的多模态API成本仅为GPT-4.5的**1%。**谁成本更低毫无疑问将在模型烧钱大战吸引用户留存中取得巨大优势。
综上所述,根据本文的实际测评,对三大模型核心能力对比总结如下表所示:
| 能力维度 | 文心4.5 | DeepSeek R1 | Qwen3.0 |
|---|---|---|---|
| 架构亮点 | 多模态异构MoE | 稠密模型 + 代码优化 | 混合推理MoE |
| 中文理解 | ⭐⭐⭐⭐⭐ (成语/古文精准) | ⭐⭐⭐⭐ (风格模仿强) | ⭐⭐⭐⭐ (多语言支持佳) |
| 逻辑推理 | ⭐⭐⭐⭐ (数学推演强) | ⭐⭐⭐ (数学第5) | ⭐⭐⭐⭐⭐ (AIME 81.5分) |
| 代码能力 | ⭐⭐⭐ (基础可用) | ⭐⭐⭐⭐⭐ (全球第1) | ⭐⭐⭐⭐ (LiveCodeBench 70+) |
| 多模态 | ⭐⭐⭐⭐⭐ (原生跨模态) | ⭐⭐ (文本为主) | ⭐⭐ (需扩展) |
| 部署成本 | 中 (支持端侧0.3B) | 高 (需16张A100) | 低 (4张H20部署旗舰版) |
| 推荐场景 | 教育/多模态交互 | 编程/工程开发 | 企业Agent/多语种服务 |
结语:中国大模型的未来已来
作为国产大模型,文心、DeepSeek、Qwen系列大模型都非常优秀,目前已形成三足鼎立之势,它们同时也代表中国大模型的三种技术信仰,多模态融合、代码优先、效率革命。三者并行,推动国产模型从"跟跑"转向"领跑"。
目前根据我的体验来看,我认为在上述三个模型当中,文心4.5在中文语境下的语言能力最强,生成中文内容最为贴切,是当前最符合中国人体验的大模型!
而这场竞争究竟谁是最终的赢家?
相信答案将会很快揭晓。
好了,本文就介绍到这里,感谢大家的关注,我们下期再会!
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle