
论文地址:https://ar5iv.labs.arxiv.org/html/2509.01563
github:https://github.com/Kwai-Keye/Keye
模型地址:https://huggingface.co/Kwai-Keye
开源时间:2025年7月2日
- 核心痛点:多模态大语言模型(MLLMs)静态图像处理能力强,但难以应对动态、信息密集的短视频理解需求。
- 模型定位:80亿参数多模态基础模型,主打短视频理解尖端性能,同时兼顾通用视觉语言能力。
- 研发核心:
- 数据支撑:超6000亿标记的高质量海量数据集,重点聚焦视频内容。
- 训练方案:四阶段预训练(实现稳健视觉语言对齐)+ 两阶段后训练(第一阶段强化指令遵循等基础能力,第二阶段激发高级推理能力)。
- 关键创新:第二阶段后训练采用五模态"冷启动"数据混合方案(含"思考""非思考""自动思考""图像辅助思考"及高质量视频数据),教会模型判断推理时机与方式;后续通过强化学习(RL)和对齐步骤优化推理能力、纠正异常行为。
- 性能表现:
- 公开视频基准测试获业界领先水平,通用图像任务保持强劲竞争力。
- 在自研新型基准测试KC-MMBench(针对现实世界短视频场景)中展现显著优势。
- 人工评估证实,相较于同规模领先模型,用户体验更优。
- 核心价值:详细阐述架构设计、数据构建策略及训练方法,为视频时代下一代多语言模型构建提供参考。
一、论文创新点
(一)模型结构创新
Keye-VL模型架构基于Qwen3-8B语言模型,并整合了源自开源SigLIP的视觉编码器。该模型支持原生动态分辨率,通过将每张图像分割为14x14像素的块序列来保持原始宽高比。随后,简单的 MLP 层对视觉标记进行映射与融合。模型采用3D RoPE技术对文本、图像和视频信息进行统一处理,通过建立位置编码与绝对时间的一一对应关系,确保对视频信息中时间变化的精准感知。
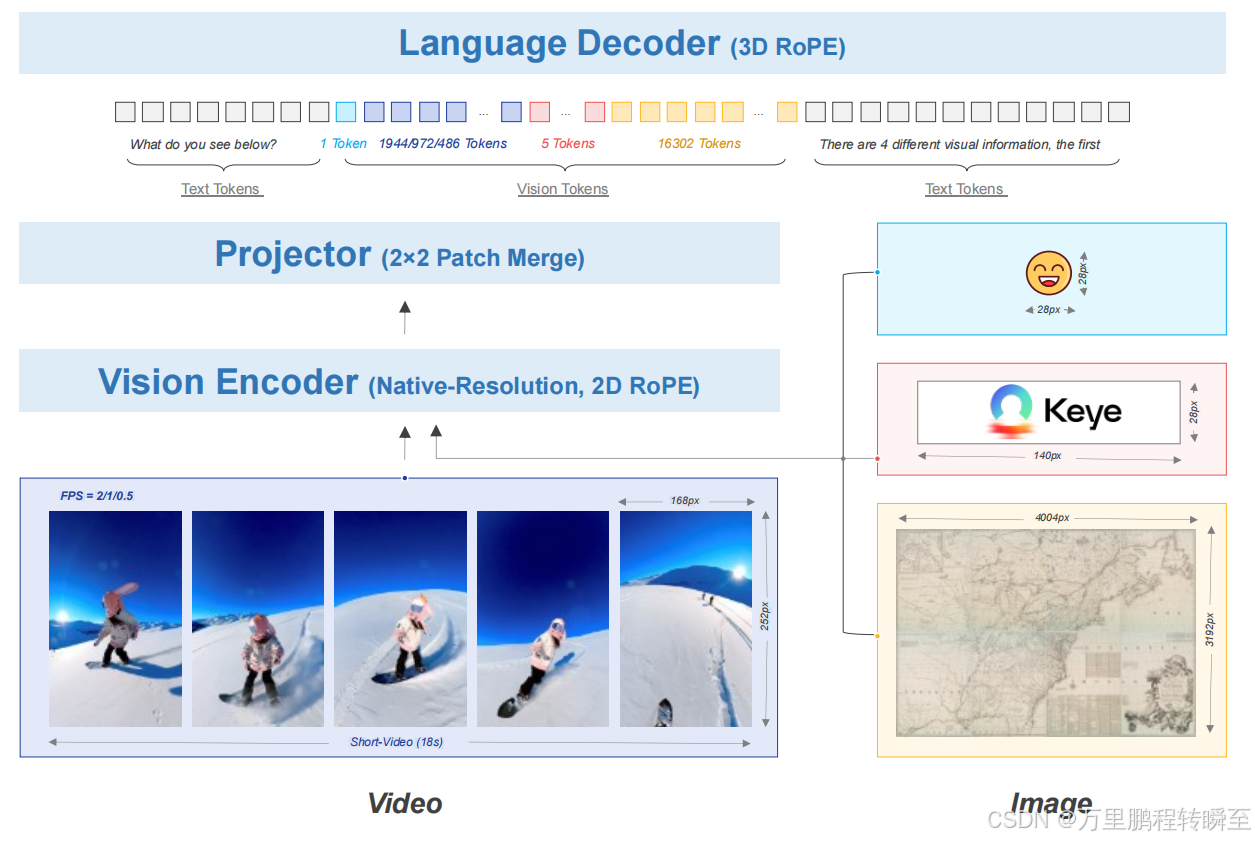
- 原生分辨率视觉编码器:基于 SigLIP-400M-384-14 初始化,融合 1D 插值与 2D 旋转位置编码(RoPE),支持动态分辨率处理,避免图像拼接/分割冗余操作,同时采用 NaViT 打包与 FlashAttention 技术优化多分辨率图像训练。
- 统一多模态处理架构:通过 3D RoPE 实现文本、图像、视频信息的统一编码,建立位置编码与绝对时间的一一对应,精准感知视频时间变化;视觉编码器输出经 MLP 投影层映射合并后输入 Qwen3-8B 语言解码器。
- 灵活视觉编码策略:图像固定 16384 个令牌以覆盖百万像素级细节,视频采用动态令牌分配策略(单帧令牌 128-768,最大视觉令牌 24576),并严格对齐 3D RoPE 时间维度(位置 +1 对应现实 0.5 秒)。
(二)核心创新点
- 五模式"冷启动"数据混合:包含"思考型""非思考型""自动思考型""图像辅助思考型"及高质量视频数据,教会模型自主选择推理策略。
- 混合模式训练框架:结合无推理训练(基础能力优化)与推理训练(复杂认知突破),通过强化学习(RL)与迭代对齐修正重复输出、逻辑缺陷等问题。
- 专属短视频基准测试:构建并开源 KC-MMBench 基准,覆盖短视频评论审核、集合排序、主题聚合等 6 类真实场景任务,共 1840 个实例。
二、训练过程
(一)数据处理过程
- 数据规模与类别:构建超 6000 亿令牌的多样化数据集,涵盖图像描述、OCR&VQA、目标定位&计数、交错文本-图像、视频数据、纯文本 6 大类。
- 数据质量控制:采用 CLIP 分数过滤、开源 MLLM 判别、图像去重等机制;对低质量数据进行重描述(利用 Qwen2.5-VL 72B、GPT-4o 等模型),视频数据需经 ASR 转写、帧级 OCR 标注等处理。
- 去污染策略:预训练阶段通过 pHash&minHash 检测重复样本(Jaccard 相似度阈值 0.95),微调阶段过滤与 29 个基准测试集高度相似的样本(图像相似度 0.98、文本相似度 0.50)。
(二)训练数据配置
| 数据类别 | 关键来源/处理方式 | 核心作用 |
|---|---|---|
| 图像描述数据 | LAION、DataComp 等开源数据 + 自研重描述 pipeline | 建立视觉特征与语言概念的映射 |
| OCR&VQA 数据 | 开源 Latex 公式、手写文本等 + 中文合成数据(渲染生成多字体/背景样本) | 强化细节识别与上下文推理能力 |
| 目标定位&计数数据 | RefCoCo、VisualGenome(定位)、PixMo(计数) | 建立视觉与文本语义的直接关联 |
| 交错文本-图像数据 | 学术 PDF、STEM 结构化数据 + 文本-图像语义验证 | 提升多模态上下文建模能力 |
| 视频数据 | 开源数据集 + 快手内部高质量短视频,含帧重排序、多视频匹配等任务 | 强化视频时序关系与语义理解 |
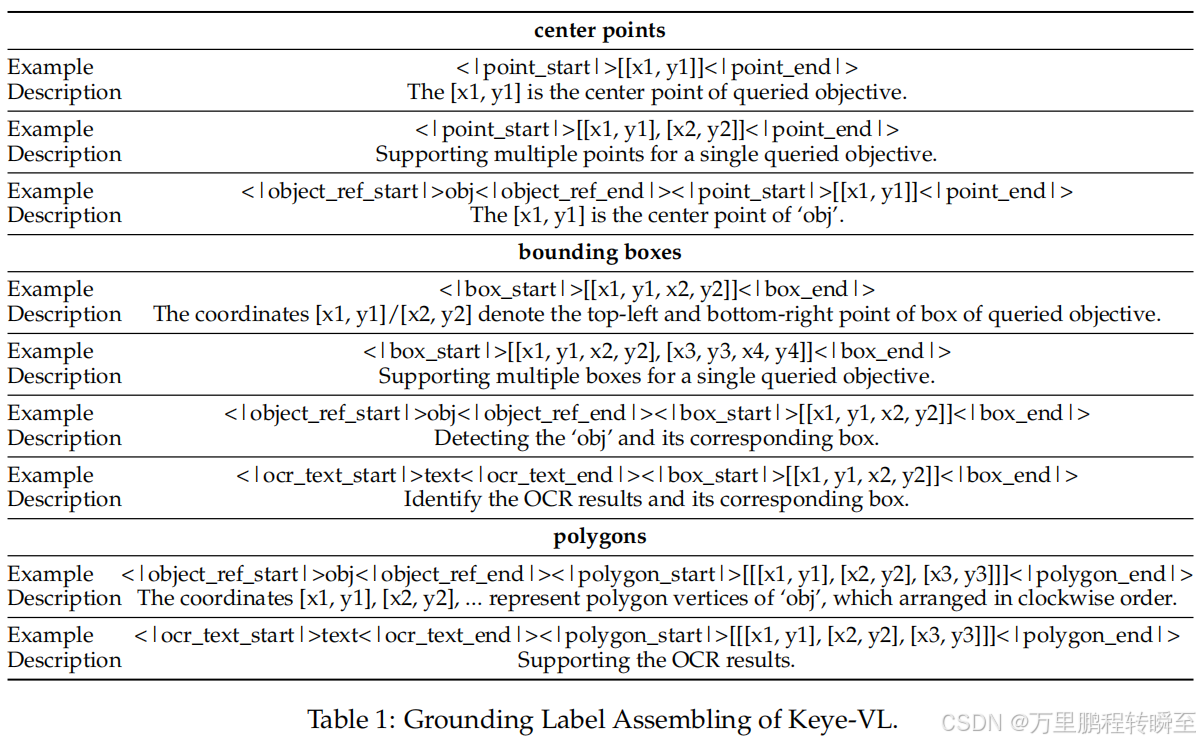
Keye-VL Grounding标签格式
(三)训练步骤
-
预训练(四阶段) :
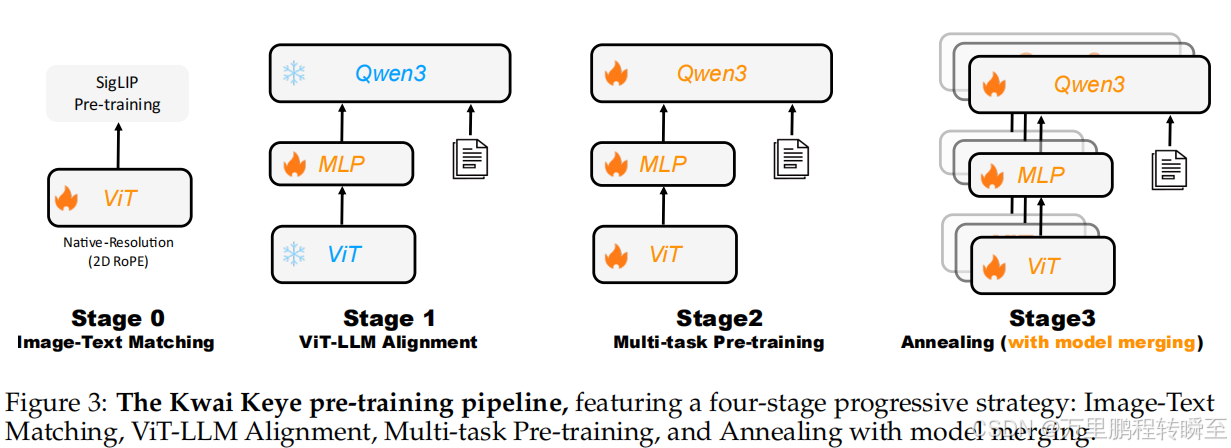
- 阶段 0:视觉编码器适配训练(SigLIP 对比损失,5000 亿令牌数据);
- 阶段 1:跨模态对齐(冻结 ViT 与 LLM,仅优化 MLP 投影层);
- 阶段 2:多任务预训练(解冻全参数,训练图像描述、OCR 等任务);
- 阶段 3:退火与模型融合(高质量数据微调 + 多数据混合模型权重平均)。
-
后训练(两阶段):
-
无理由推理训练流程:含监督微调(SFT,500 万+ 多模态 QA 样本)与混合偏好优化(MPO,40 万开源样本 + 3 万人工标注样本等);
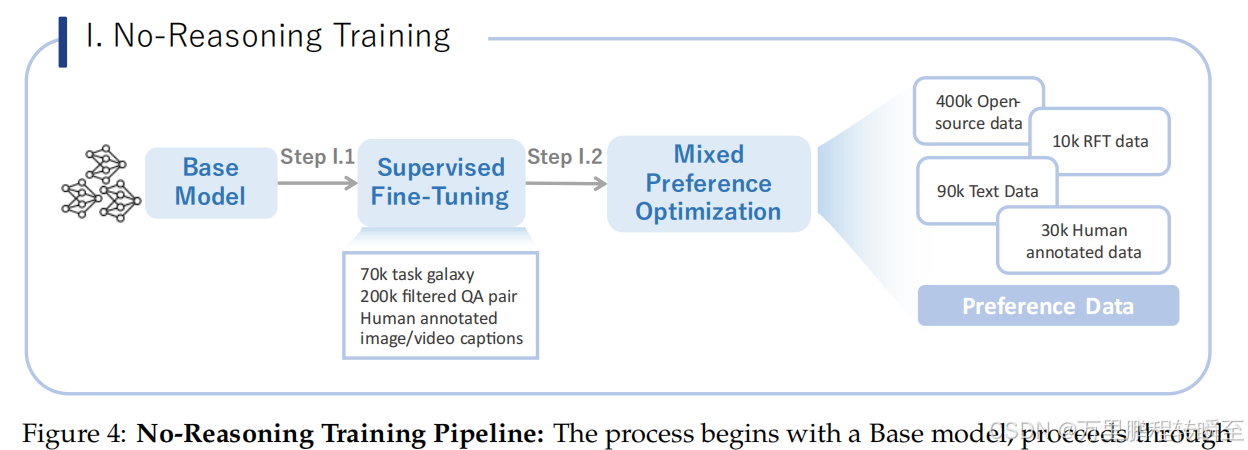
-
推理训练:CoT冷启动(通过数据池采样、质量检测和高频思维路径筛选生成CoT冷启动数据集)、混合模式强化学习(包含思考模式、非思考模式、自动思考模式及具有结果与一致性奖励的智能体模式),以及迭代对齐(基于重复次数、指令遵循质量及逻辑评分,采用混合偏好优化、拒绝采样和偏好数据过滤的强化学习模型)。
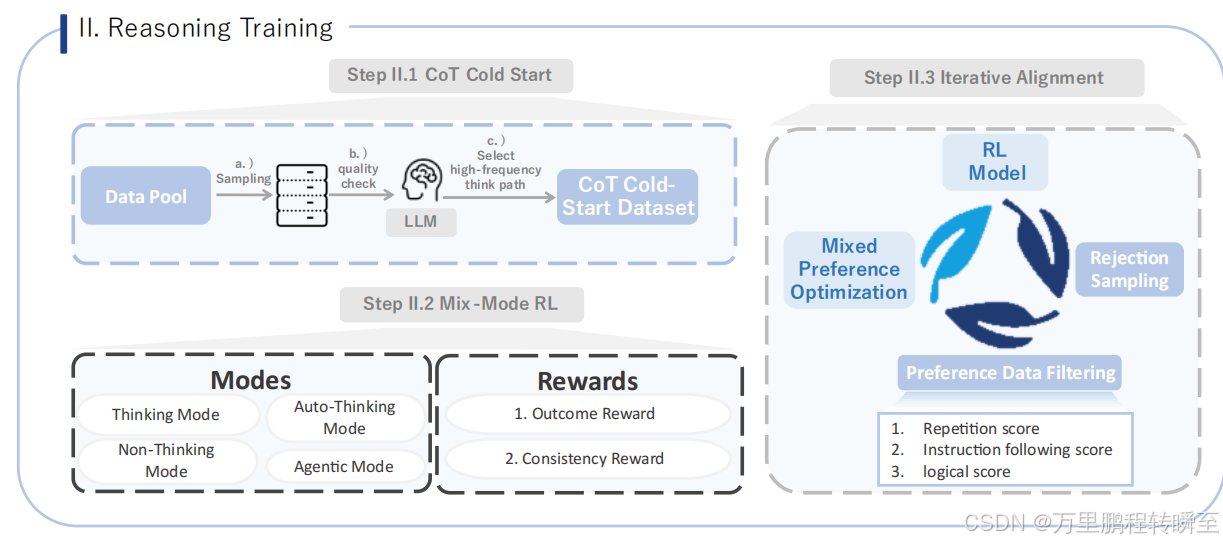
-
(四)消融实验
-
视觉编码器变体对比 (对应 表 2:ImageNet 基准上的 ViT 变体对比):
- 基础模型(SigLIP-400M-384-14)在 ImageNet-1K 得分为 83.08;
- 仅添加 1D 插值:ImageNet-1K 得分降至 82.02,因 1D 位置编码无法区分 2D 补丁排列;
- 1D 插值 + 2D RoPE:ImageNet-1K 得分 82.65,ObjectNet 得分 78.70(超基础模型),验证 2D RoPE 对空间感知的提升。

-
推理与非推理数据相互增强:CoT 混合数据训练后,非推理模式在 MMMU 提升 5.67%,推理模式提升 8.22%;HallucinationBench 非推理模式提升 2.95%,推理模式提升 7.97%。
-
强化学习(RL)效果:混合模式 RL 训练后,10 个基准测试平均提升 1.44%(非推理模式)/2.17%(推理模式),仅 MMMU/OCRBench 出现小幅下降(≤1.2%)。
三、核心性能表现
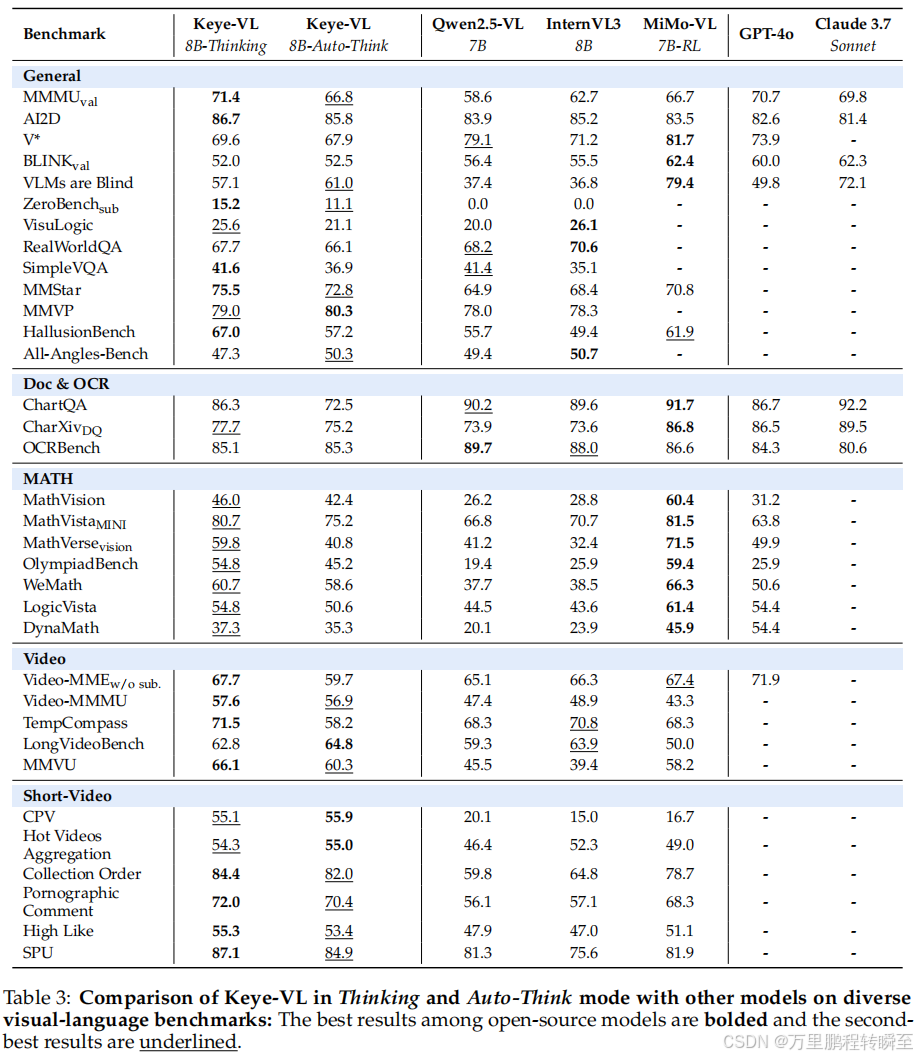
(一)公共基准测试表现(对应 表 3:Keye-VL 与其他模型在多模态基准上的对比)
| 任务类型 | 关键指标 | Keye-VL-8B(Thinking) | 同规模模型最优值 |
|---|---|---|---|
| 通用视觉-语言 | MMMU_val | 71.4% | 66.7%(MiMo-VL-7B-RL) |
| 通用视觉-语言 | AI2D | 86.7% | 85.2%(InternVL3-8B) |
| 数学推理 | MathVista_MINI | 80.7% | 81.5%(MiMo-VL-7B-RL) |
| 视频理解 | Video-MMMU | 57.6% | 48.9%(InternVL3-8B) |
| 视频理解 | LongVideoBench | 62.8% | 63.9%(InternVL3-8B) |
| 短视频专属 | KC-MMBench 平均 | 68.03% | 57.62%(MiMo-VL-7B-RL) |
(二)内部基准测试表现(对应 表 5:内部基准上 Keye-VL 与其他模型的对比 、表 6:内部基准上的详细能力对比)
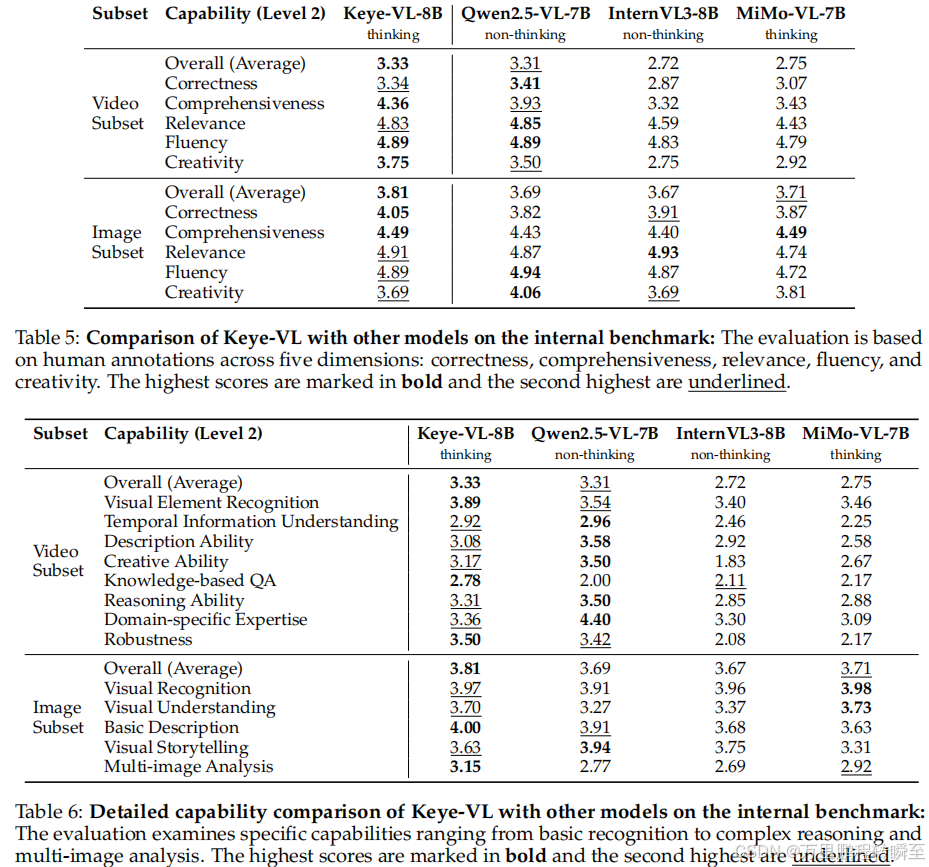
- 视频子集整体表现:Keye-VL-8B 综合得分 3.33(满分 5 分),其中全面性 4.36、创造性 3.75 领先所有对比模型(Qwen2.5-VL-7B 综合 2.72);
- 图像子集整体表现:综合得分 3.81,正确性 4.05、全面性 4.49 居首,多图像分析能力 3.15 显著领先;
- 核心能力细分:视觉元素识别 3.89、基于知识的问答 2.78、鲁棒性 3.50 等维度排名第一,时序信息理解 2.92 接近最优水平。
(三)关键对比图表核心结论
-
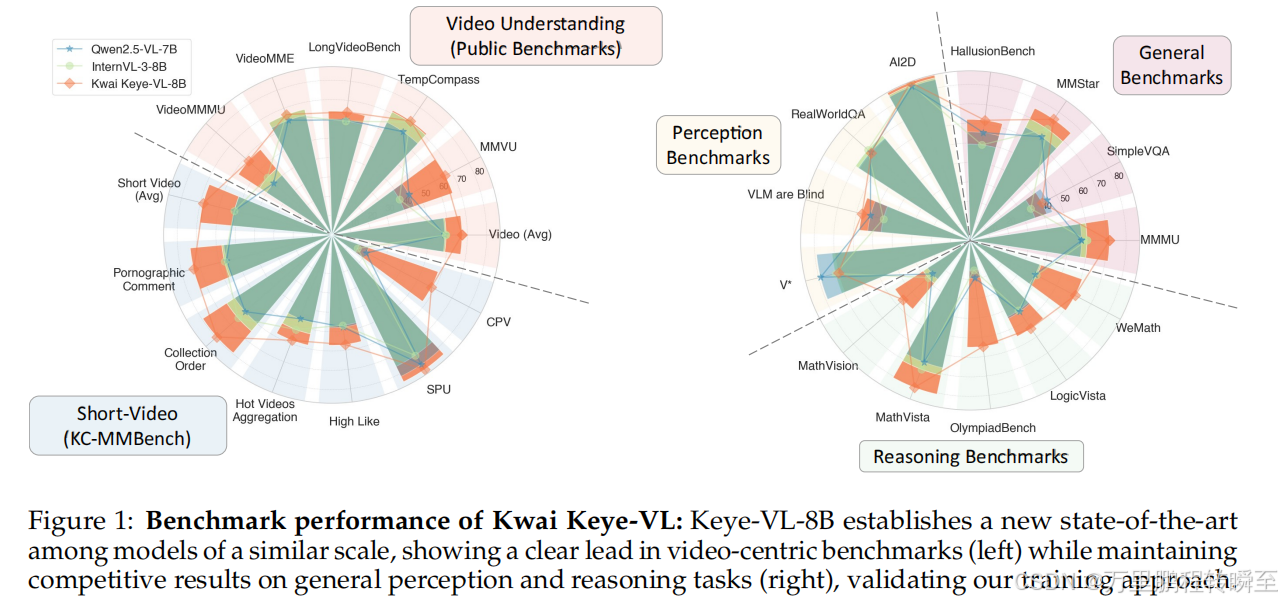
图 1:Keye-VL 基准测试表现 :在视频中心基准中显著领先同规模模型,通用感知与推理任务保持竞争力,验证了训练策略的有效性;
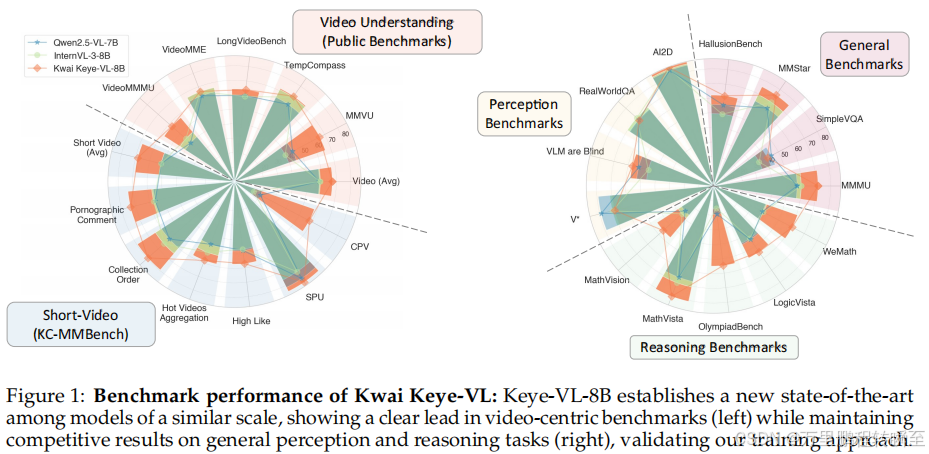
-
表 4:快手社区多模态基准(KC-MMBench) :6 类短视频任务中,Keye-VL 在"集合排序"(84.4%)、"SPU 识别"(87.1%)等任务上表现突出,适配真实商业场景;

-
表 7:Auto-Think 模式下的推理模式选择比例 :MathVista_MINI(35%)、MMStar(34%)等复杂任务中优先选择思考模式,OCRBench(0%)全采用非思考模式,验证自主推理策略选择能力。

四、总结
Kwai Keye-VL 通过原生分辨率视觉编码、五模式冷启动数据混合、多阶段训练框架三大核心创新,在短视频理解领域实现突破,同时兼顾通用多模态能力。其专属的 KC-MMBench 基准与严格的数据去污染策略,为视频时代多模态模型的研发提供了重要参考。