训练时开启 KV 缓存(Key-Value Cache)与 is_causal=False 冲突的核心原因是:KV 缓存的设计逻辑完全依赖「因果掩码(is_causal=True)+ 自回归逐 token 生成」,而 is_causal=False 打破了这一核心前提,从「逻辑设计、维度计算、场景适配」三个层面产生不可调和的矛盾。以下结合 Qwen3 等 Decoder 模型的底层逻辑,拆解冲突本质:
一、先明确核心概念:KV 缓存的设计目标
KV 缓存(也叫 Past Key Values)是为 Decoder 模型推理阶段 设计的优化机制,核心目的是:
- 自回归生成时(逐 token 输出,如 model.generate),缓存历史 token 的 Key/Value 矩阵,避免重复计算前文 token 的 K/V(比如生成第 10 个 token 时,无需重新计算前 9 个 token 的 K/V);
- 依赖的核心前提:模型仅关注前文 token(is_causal=True),新 token 的 Query 只需要和「缓存的前文 K/V」交互,无需关注未来 token。
简单说:KV 缓存 = 「因果掩码(is_causal=True)+ 逐 token 生成」的专属优化,脱离这个前提就会失效。
二、冲突的核心原因(从浅到深)
1. 逻辑层面:KV 缓存的 "历史依赖" vs is_causal=False的 "全序列可见"
- KV 缓存的逻辑:
缓存的是「已生成的前文 token 的 K/V」,新 token 的 Query 只能和这些缓存的 K/V 交互(因果限制)。比如生成第 t 个 token 时,缓存只有 1~t-1 个 token 的 K/V,Query 仅与这些 K/V 计算注意力。 - is_causal=False 的逻辑:
模型需要关注全序列 token(包括未来未生成的 token),但未来 token 的 K/V 并未被缓存(甚至还未生成),导致 "全序列可见" 的需求无法满足 ------ 缓存里只有前文,没有未来,逻辑上自相矛盾。
2. 维度计算层面:缓存维度与注意力矩阵的不匹配
KV 缓存会改变注意力计算的维度逻辑,而 is_causal=False 会彻底打乱这一计算:
(1)开启 KV 缓存时的维度(is_causal=True 正常场景)
假设序列长度为 seq_len,缓存长度为 past_len(历史 token 数),则:
- Key 维度:batch, num_heads, past_len + curr_len, head_dim(缓存的历史 K + 当前 K);
- Query 维度:batch, num_heads, curr_len, head_dim(当前 token 的 Q);
- 注意力掩码:下三角掩码,仅允许 Q 与 past_len + curr_len 中的「前文部分」交互。
(2)开启 KV 缓存 + is_causal=False 的冲突
is_causal=False 要求 Q 与所有 K/V(包括未来) 交互,但:
- 未来 token 的 K/V 不在缓存中,Key 维度仅包含「历史 + 当前」,缺少未来部分;
- 模型内部会根据 KV 缓存长度计算注意力掩码的偏移量(past_key_values_length),-is_causal=False 时偏移量计算错误,导致掩码维度与 K/V 维度不匹配,直接触发报错(如 shape mismatch)。
3. 场景层面:KV 缓存适配推理,is_causal=False 适配训练
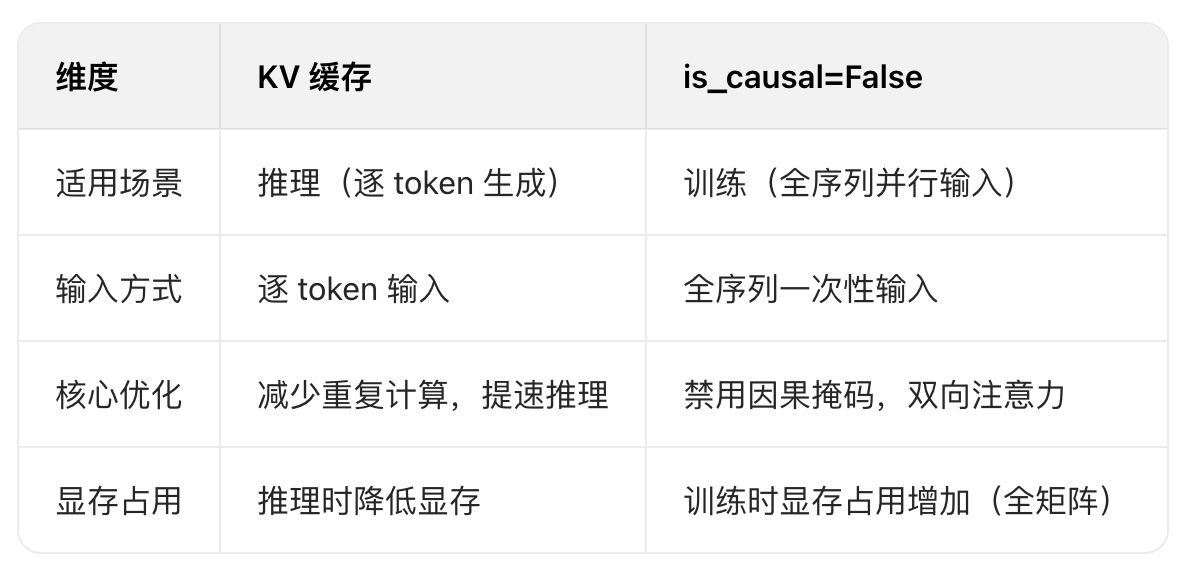
训练时开启 KV 缓存本身就是「反常规操作」:
- 训练采用「Teacher Forcing」模式,全序列一次性输入,无需逐 token 生成,KV 缓存完全无用(反而增加显存开销);
- 若强行开启 KV 缓存 + is_causal=False,模型会试图将 "全序列并行输入" 适配 "逐 token 缓存逻辑",导致内部状态混乱(比如缓存未清空、维度叠加错误)。
4. 代码层面:模型内部的校验逻辑(以 Qwen3 为例)
Qwen3 等模型的 forward 方法中,KV 缓存会触发以下逻辑:
python
# Qwen3 原生逻辑(简化)
def forward(self, input_ids, past_key_values=None, is_causal=True, **kwargs):
if past_key_values is not None: # 开启 KV 缓存
# 计算缓存长度,用于生成因果掩码
past_len = past_key_values[0][0].shape[2]
# 生成因果掩码时,基于缓存长度偏移
causal_mask = self._prepare_causal_mask(
attention_mask, input_shape, inputs_embeds, past_len
)
kwargs["causal_mask"] = causal_mask
kwargs["is_causal"] = True # 强制设为 True,覆盖用户输入
return super().forward(** kwargs)可以看到:只要开启 KV 缓存(past_key_values is not None),模型会强制将 is_causal 设为 True,并生成基于缓存长度的因果掩码 ------ 此时用户手动设置的 is_causal=False 会被覆盖,导致参数失效,表现为 "冲突"。
三、冲突的具体表现
若强行在训练时开启 KV 缓存 + is_causal=False,会出现以下问题:
- 维度不匹配报错:RuntimeError: The size of tensor a (x) must match the size of tensor b (y) at non-singleton dimension z;
- is_causal=False 失效:模型强制恢复 is_causal=True,因果掩码未被禁用;
- 显存异常暴涨:KV 缓存占用额外显存 + 全矩阵注意力的显存开销,导致 OOM;
- 训练结果错误:注意力计算混乱,模型无法收敛(甚至 loss 为 NaN)。
四、解决方案:训练时彻底禁用 KV 缓存
针对你的场景(训练时 is_causal=False),核心解决方案是:
1. 禁用 KV 缓存(核心)
python
class Qwen3NoCausal(Qwen3ForCausalLM):
def forward(self, *args, **kwargs):
# 1. 强制禁用 KV 缓存
kwargs["past_key_values"] = None # 清空缓存
self.config.use_cache = False # 全局禁用缓存
# 2. 强制设为 is_causal=False
kwargs["is_causal"] = False
return super().forward(*args, **kwargs)2. 训练参数中强化禁用
python
training_args = TrainingArguments(
...,
use_cache=False, # Trainer 层面禁用缓存
gradient_checkpointing=True, # 替代缓存的显存优化方案
)3. 推理时若需 is_causal=False,也需禁用缓存
即使是推理场景,若要 is_causal=False,也必须关闭 KV 缓存:
python
outputs = model.generate(
input_ids,
max_new_tokens=20,
is_causal=False,
use_cache=False, # 禁用缓存
)五、总结
KV 缓存与 is_causal=False 冲突的本质是:
KV 缓存的设计根基是「因果掩码(is_causal=True)+ 逐 token 生成」,而 is_causal=False 打破了 "因果限制",且训练场景本身无需 KV 缓存,两者从逻辑、维度、场景上完全不兼容。
对于你的核心需求(训练 Qwen3 时禁用因果掩码),训练阶段必须禁用 KV 缓存(这也是行业通用做法);若需推理时禁用因果掩码,同样要关闭 KV 缓存,或改用全序列一次性输入的推理方式(而非逐 token 生成)。