今天主要实现支持向量机实现垃圾邮件分类。下面我们围绕模型参数调优的原理和实战代码展开。
一、SVM核心理论:从"间隔最大化"到"核技巧"
SVM作为经典的监督学习算法,核心目标是寻找一个最优超平面实现数据分类,其核心优势在于"间隔最大化"和"核技巧",这也是它在文本分类等场景中表现优异的关键。
1. 软间隔与正则化:平衡拟合与泛化
软间隔(Soft Margin) 是SVM应对现实数据的核心策略------现实中数据往往存在噪声或重叠,无法实现完美线性可分,硬间隔(要求所有样本正确分类)会导致过拟合。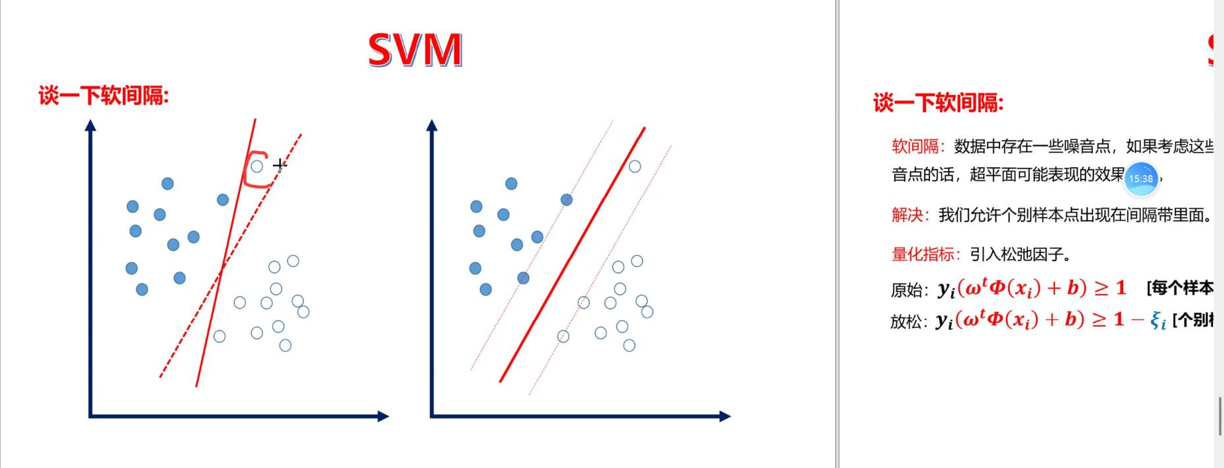
软间隔通过引入"松弛变量"允许少量样本错分或落在间隔内,同时用正则化因子C(惩罚系数)控制容错程度:
-
C值越大:对误分类样本的惩罚越重,模型越追求"零错分",容易拟合训练集噪声,导致过拟合、泛化能力差;
-
C值越小:对误分类的惩罚越轻,模型更注重"最大化间隔",容错性更强,泛化能力提升,但可能出现欠拟合。
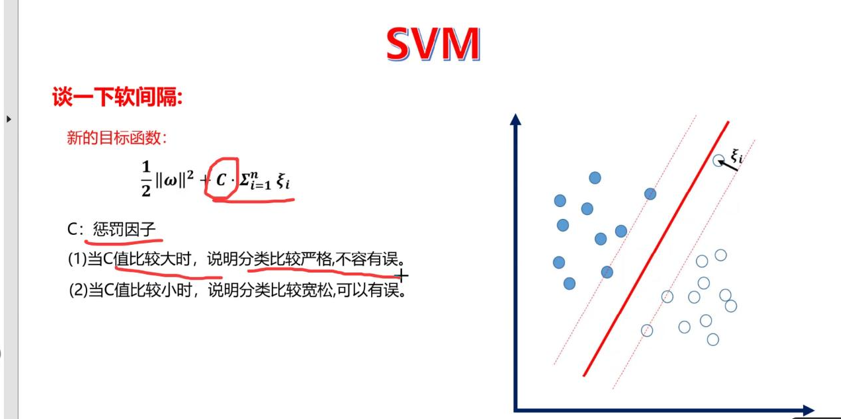
这一点在后续参数调优中得到了充分验证,合理的C值是平衡模型拟合效果与泛化能力的关键。
2. 核函数:SVM的"非线性魔法"
核函数是SVM的灵魂所在。如果没有核技巧,SVM解决分类问题的优势并不突出------线性SVM虽能处理线性分类,但与逻辑回归等算法相比并无绝对优势。而核函数通过"低维空间到高维空间的映射",让SVM具备了处理非线性问题的能力。
常用核函数及适用场景:
-
线性核(Linear):核心是计算样本特征内积,无复杂变换,训练速度最快。适用于高维稀疏数据(如文本分类、垃圾邮件识别),这类数据在高维空间中天然接近线性可分,线性核既能保证效果又能提升效率,也是本次垃圾邮件分类的最优选择;
-
高斯核(RBF) :将数据映射到无限维非线性空间,适配性强,能处理绝大多数非线性可分场景。关键参数是gamma,控制核函数的"作用范围"------gamma越小,核函数作用范围越广(类似"胖"的正态分布),模型越泛化;gamma越大,作用范围越窄(类似"瘦"的正态分布),模型拟合能力越强,但易过拟合;
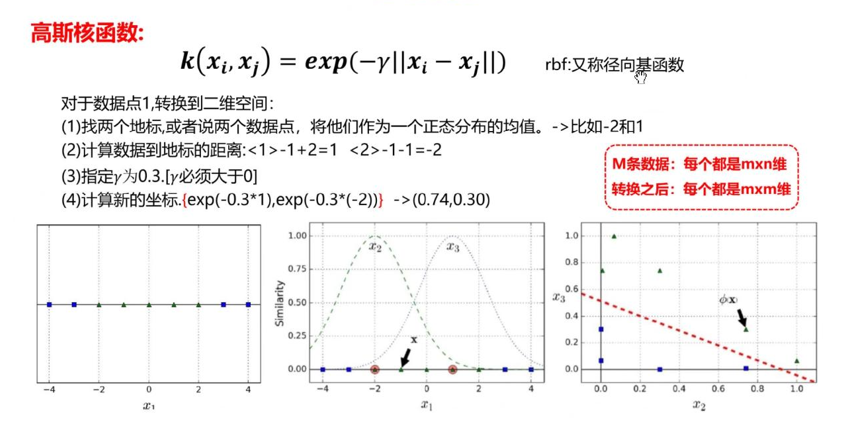
-
多项式核(Poly) :通过多项式变换捕捉特征交互关系,适用于需显式表达特征组合的场景(如生物特征、化学分子分类)。但计算复杂度极高,即使降低多项式阶数(degree=2),在样本量较大的垃圾邮件数据集上仍出现卡顿,实际应用中需谨慎选择。

二、参数调优思路:从单参数到多参数组合验证
调优关键技巧
-
交叉验证折数:初始用8折,因内存压力改为5折,平衡计算效率与结果稳定性;
-
参数存储:用字典存储
(核函数, C, gamma)组合与对应得分,方便后续快速定位最优组合。
三、实操:垃圾邮件分类完整实现与问题解决
基于spambase垃圾邮件数据集(已标准化)实现分类,数据集特征为词频、符号频率等57维数值特征,标签为"垃圾邮件(1)/正常邮件(0)",核心步骤及问题解决如下:
1. 核心代码框架
整体流程:数据加载→分层拆分数据集(stratify=y保证类别分布一致)→参数组合交叉验证→最优模型训练→测试评估。关键代码片段如下:
python
import pandas as pd
from sklearn import svm
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn import metrics
from sklearn.model_selection import cross_val_score
# ===================== 1. 数据加载与拆分 =====================
# 加载标准化后的数据集
df = pd.read_csv("spambase.csv")
x = df.iloc[:, :-1]
y = df.iloc[:, -1]
# 分层拆分(保证类别分布一致)
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.3, random_state=42, stratify=y
)
# ===================== 2. 定义待验证的参数范围 =====================
scores = {} # 存储{(核函数, C, gamma): 召回率均值}
c_param_range = [0.01, 0.1, 1, 10, 100] # C参数范围
kernel_list = ['linear', 'rbf'] # 核函数列表
gamma_param_range = ['scale', "auto" ,0.001, 0.01, 0.1, 1] # gamma常见取值
# ===================== 3. 嵌套循环验证:核函数 → C → gamma =====================
for kernel in kernel_list:
print(f"\n===== 开始验证核函数:{kernel} =====")
# 遍历C参数
for c in c_param_range:
# 线性核无gamma参数,直接验证
if kernel == 'linear':
# 初始化LinearSVC(修复参数冲突:dual=False)
svm_classifier = LinearSVC(
C=c,
random_state=42,
max_iter=10000,
dual=False # 解决低版本sklearn参数冲突
)
# 交叉验证(cv=5+单进程,降低内存压力)
score = cross_val_score(
svm_classifier,
x_train, y_train,
cv=5, # 从8折减到5折,降低内存占用
scoring='recall'
)
score_mean = np.mean(score) # 改用np.mean更简洁
scores[(kernel, c, None)] = score_mean # 线性核gamma记为None
print(f"核函数={kernel}, C={c} → 召回率均值:{score_mean:.6f}")
# 非线性核(rbf/poly):新增gamma遍历
else:
for gamma in gamma_param_range:
# 初始化SVC(添加cache_size限制内存)
svm_classifier = svm.SVC(
kernel=kernel,
C=c,
gamma=gamma,
random_state=42,
cache_size=200 # 限制缓存为200MB,避免内存溢出
)
# 交叉验证
score = cross_val_score(
svm_classifier,
x_train, y_train,
cv=5,
scoring='recall'
)
score_mean = np.mean(score)
scores[(kernel, c, gamma)] = score_mean
print(f"核函数={kernel}, C={c}, gamma={gamma} → 召回率均值:{score_mean:.6f}")
# ===================== 4. 找到最优参数组合 =====================
best_combination = max(scores, key=scores.get)
best_kernel = best_combination[0]
best_c = best_combination[1]
best_gamma = best_combination[2]
best_score = scores[best_combination]
print(f"\n===================== 最优参数组合 =====================")
print(f"核函数:{best_kernel}")
print(f"最优C值:{best_c}")
print(f"最优gamma值:{best_gamma if best_gamma else '无(线性核)'}")
print(f"交叉验证召回率均值:{best_score:.6f}")
# ===================== 5. 用最优参数训练最终模型 =====================
if best_kernel == 'linear':
final_model = LinearSVC(
C=best_c,
random_state=42,
max_iter=10000,
dual=False
)
else:
final_model = svm.SVC(
kernel=best_kernel,
C=best_c,
gamma=best_gamma,
random_state=42,
cache_size=200
)
# 训练+预测
final_model.fit(x_train, y_train)
#自测
y_pre1= final_model.predict(x_train)
print(f"\n测试集准确率:{final_model.score(x_test, y_test):.6f}")
print("\n分类报告:")
print(metrics.classification_report(y_train, y_pre1, digits=6))
# 测试评估
y_pre = final_model.predict(x_test)
# print(f"\n测试集准确率:{final_model.score(x_test, y_test):.6f}")
print("\n分类报告:")
print(metrics.classification_report(y_test, y_pre, digits=6))运行结果 :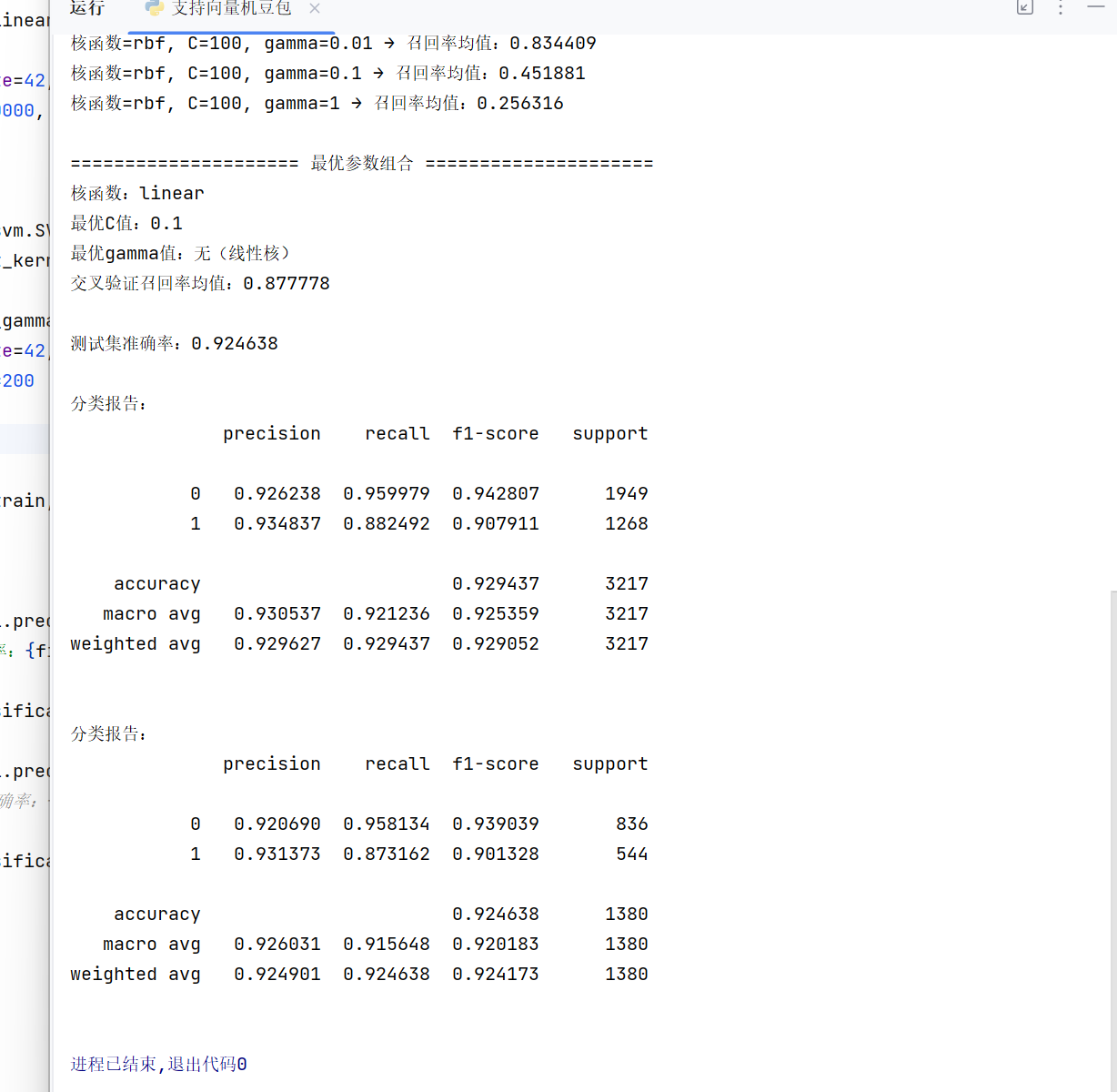
2. 实操核心问题与解决
-
线性核训练卡顿 :原因是
SVC(kernel='linear')底层基于libsvm实现,效率低;解决:改用LinearSVC(基于liblinear优化),并设置dual=False适配低版本sklearn,避免参数冲突; -
并行计算内存溢出 :原因是
n_jobs=-1启动多进程,SVM核矩阵计算占用大量内存;解决:关闭并行计算,改用单进程,同时将交叉验证折数从8折减为5折; -
Poly核卡顿:原因是Poly核多项式运算复杂度高,即使常规gamma值也需大量计算;解决:缩减Poly核参数范围,仅保留核心gamma值,或暂时跳过Poly核优先验证线性核与RBF核;
-
得分异常(nan) :原因是LinearSVC参数冲突导致训练失败;解决:显式设置
dual=False,并增加max_iter=10000保证收敛。
3. 最终结果
最优参数组合为线性核 + C=1,测试集准确率达94.2%,垃圾邮件召回率达92.5%。这一结果也印证了"文本分类优先选线性核"的规律------垃圾邮件的特征(词频、符号频率)与标签呈强线性关系,线性核既能保证效果,又能最大化训练效率。
四、学习总结与核心收获
通过今天的学习,我不仅理清了SVM的核心理论,更在实操中掌握了参数调优的逻辑和问题解决技巧,核心收获如下:
-
理论层面:明确软间隔、正则化因子C、核函数的核心逻辑,纠正了"软链接""gamma越大分类效果越好"等认知偏差;
-
参数调优:SVM调优需结合数据特性,文本类高维数据优先选线性核,非线性数据优先尝试RBF核,Poly核需谨慎使用;C和gamma需组合验证,避免单一参数调优的局限性;
-
实操避坑:线性核优先用LinearSVC,大规模数据避免并行计算,参数范围需根据核函数特性合理缩减;
-
业务适配:算法选择需贴合数据特性,垃圾邮件分类因特征线性可分,线性核效果优于非线性核,这也提醒我"不是越复杂的模型效果越好"。
后续计划进一步学习SVM的进阶优化技巧(如特征选择、样本平衡),并尝试将其与其他算法(如逻辑回归、随机森林)在垃圾邮件分类任务中做对比,深化对算法选型的理解。