WebArena:一个真实的网页环境,用于构建更强大的自主智能体
最近,在 ICLR 2024 上发表了一篇来自卡内基梅隆大学的论文------WebArena: A Realistic Web Environment for Building Autonomous Agents(arXiv: 2307.13854)。这篇论文提出并实现了一个高度逼真、可复现的网页环境,专门用于开发和评估基于自然语言指令的自主智能体(Autonomous Agents)。今天这篇博客就来详细介绍这篇论文:它到底想解决什么问题、如何解决,以及其中的关键细节。
解决什么问题?
随着大语言模型(如 GPT-4)的快速发展,研究者们开始探索让 AI 智能体通过自然语言指令完成日常任务,比如"帮我在网上买个东西"或"去 GitLab 上更新 README"。然而,现有的智能体评估环境存在几个严重问题:
- 过于简化、不真实:很多环境(如 MiniWoB、WebShop、Mind2Web)要么功能受限,要么使用静态缓存页面,无法反映真实网页的复杂交互、多样内容和动态变化。
- 任务复杂度低:现有任务往往只需要几步操作就能完成,缺乏人类在真实互联网上经常遇到的长序列、需要规划和探索的任务。
- 评估方式不合理 :很多环境只比较预测动作序列与参考序列的文本相似度,而忽略了功能正确性(functional correctness),即最终是否真正完成了目标。
- 不可复现:依赖真实网站会导致 CAPTCHA、内容变动、配置变更等问题,难以公平比较不同系统。
这些问题导致智能体在模拟环境里表现不错,但一到真实世界就"翻车"。论文的目标就是构建一个既高度真实又完全可复现的网页环境,来推动更鲁棒的自主智能体开发。
如何解决?------ WebArena 的核心设计
WebArena 的核心是一个独立、可自托管的网页环境,使用 Docker 容器封装,所有网站都是开源实现 + 从真实网站采样数据填充,完全脱离真实互联网,避免了上述不可复现问题。
1. 包含的网站与工具(四大领域 + 辅助工具)
论文根据作者们真实浏览器历史分析,选出了互联网上最常见的四大类网站,并各实现了一个功能完整的实例:
- 电商平台:OneStopShop(类似 Amazon/eBay),支持浏览、搜索、购物车、下单等完整流程。
- 社交论坛:类似 Reddit,支持发帖、评论、子版块等。
- 协作开发平台:基于真实 GitLab 开源代码搭建,支持仓库、Issue、Merge Request 等。
- 内容管理系统(CMS):类似在线商店后台,支持商品管理、订单查看等。
此外,还加入了人类常用辅助工具(作为独立网站):
- 地图(类似 Google Maps,支持搜索 POI、路线规划)
- 计算器
- 便签本(Scratchpad,用于记笔记)
以及知识资源:
- 英文 Wikipedia
- 各网站的用户手册
这些工具和知识库的加入,鼓励智能体像人类一样"多开标签页"、查资料、做笔记、规划路线。
2. 观察空间(Observation Space)
为了尽可能贴近人类浏览体验,观察包括:
- 当前 URL 和所有打开的标签页
- 当前焦点标签页的内容,可选择三种表示方式:
- 原始 HTML DOM 树
- 截图(像素级别)
- 可访问性树(Accessibility Tree)(推荐):比 DOM 更简洁,只保留对用户有意义的元素(角色、文本、可交互性),适合文本模型输入。

支持多标签页操作,是首个明确支持多标签的网页智能体环境。
3. 动作空间(Action Space)
设计了一套仿键盘+鼠标的复合动作,包括:
- 元素操作:click、hover、type、press 键、scroll
- 标签页操作:new_tab、tab_focus、tab_close
- 导航操作:go_back、go_forward、goto URL
元素选择支持两种方式:
- 坐标 (x,y)
- 元素 ID(在可访问性树或 DOM 中自动标注的唯一编号,如 click 1582),把元素选择变成分类问题,非常方便。
4. 基准任务集(Benchmark)
论文发布了 812 个测试任务,来自 241 个模板,每个模板平均实例化 3.3 个。
任务特点:
- 高层次、自然语言指令:例如"在 Pittsburgh 找几家艺术博物馆,规划开车距离最短的路线,然后把路线更新到对应仓库的 README 中"。
- 长序列、需要规划:平均需要多步操作,甚至跨多个网站。
- 分为三大类:
- 信息查找(需要返回文本答案)
- 站点导航
- 内容与配置操作(发帖、购物、修改设置等)
还有一部分不可完成任务(如询问网站没有提供的联系电话),考察智能体是否会胡编。
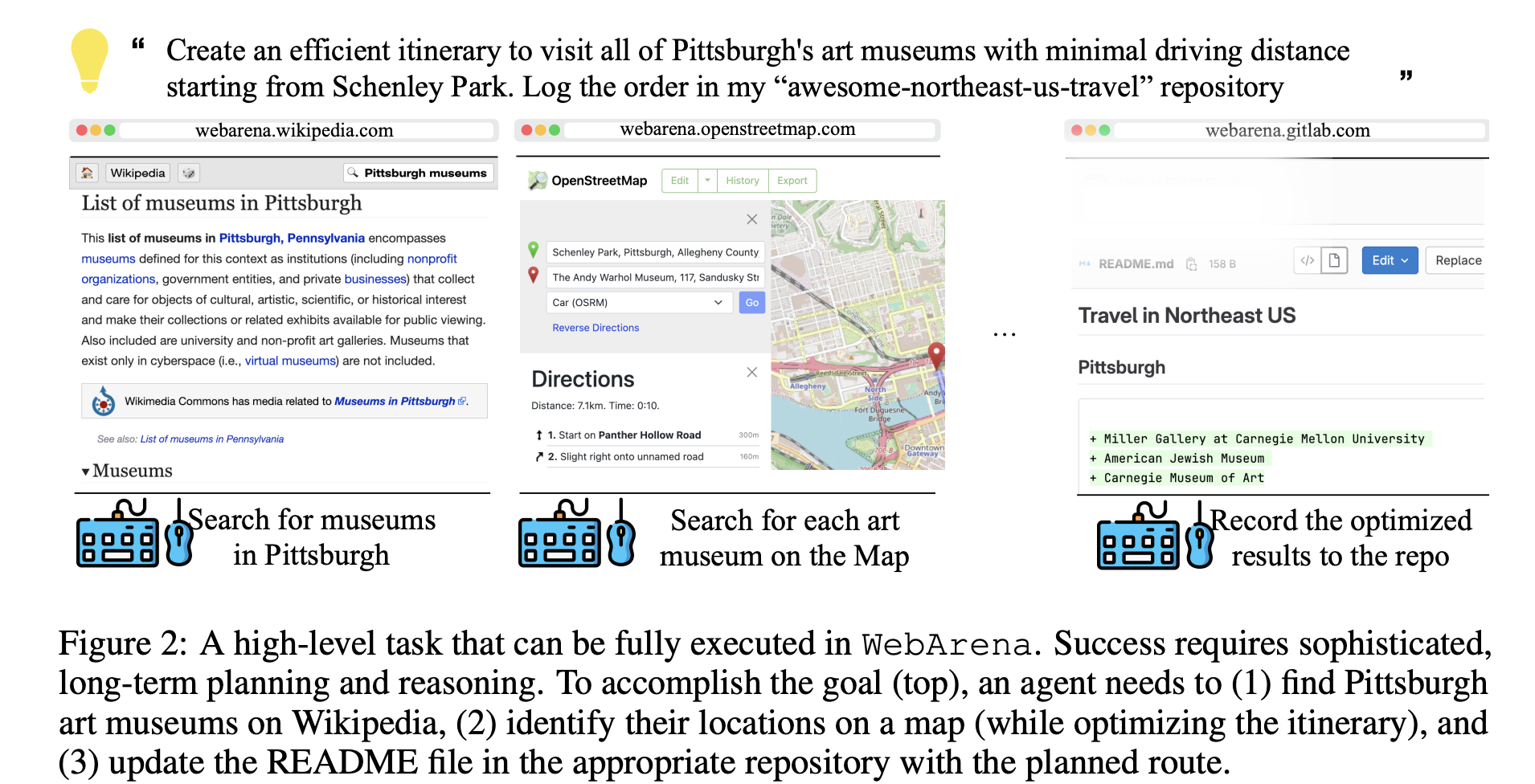
5. 评估方式:强调功能正确性
这是 WebArena 最亮眼的设计之一:
- 信息查找类:提供参考答案,使用 exact_match、must_include 或 GPT-4 做 fuzzy_match 评估语义等价。
- 导航与操作类:编写程序(r_prog)直接检查执行轨迹中的中间状态(数据库、最终页面内容、URL 等),验证是否真正达到了目标。
这种评估方式更可靠、容错(允许多条合理路径),也更贴近真实需求。
实验结果:当前顶尖模型还差得很远
论文用 GPT-4、PaLM-2 等模型做了基线实验(few-shot + CoT),最佳配置(GPT-4 + CoT)端到端成功率只有 14.41% ,而人类在相同任务上的成功率是 78.24%。
这说明:
- 当前大模型在复杂、长序列的真实网页任务上仍有巨大差距。
- 缺少主动探索、失败恢复、长期规划等关键能力。
WebArena 正是为衡量这类进步而设计的基准。
总结与意义
WebArena 的贡献在于:
- 提供了一个真实感极强(完整功能网站 + 真实采样数据 + 辅助工具)的网页环境。
- 完全可复现、自托管,避免了真实网站的不稳定。
- 发布了812 个高质量、长序列、功能正确性评估的基准任务。
- 实验证明当前最强模型在真实网页任务上表现远不如人类,为未来研究指明了方向。
项目已完全开源:代码、环境复现脚本、任务、视频演示都在 https://webarena.dev/。
如果你正在研究自主智能体、网页导航、具身智能或 Agent Benchmark,这篇论文和 WebArena 绝对值得深入体验。它让我们看到了当前技术的真实水平,也为下一代更聪明、更可靠的 AI 代理指明了努力方向。
WebArena Benchmark 使用指南(基于官方 GitHub 仓库)
WebArena 是 ICLR 2024 论文的开源实现(arXiv:2307.13854),一个独立、自托管的网页环境,用于测试自主 Agent 在真实网页任务上的性能。仓库地址:https://github.com/web-arena-x/webarena。
它包含 812 个长序列任务 (信息查找、站点导航、内容操作),强调功能正确性 评估(检查数据库/页面状态,而非动作序列匹配)。人类成功率 ~78%,原 GPT-4 基线仅 14.41%。截至 2025 年底,最强单 Agent 已达 64.2%(Narada Operator),如 IBM CUGA 61.7%、AWA 1.5 57%、OpenAI Operator ~58-65%。
使用门槛:需要 Docker/Python 经验,高配机器(GitLab 容器 ~100GB)。不能用官网 demo 跑正式实验(仅教育用途),必须本地自建环境确保可复现。
1. 前提条件(Prerequisites)
- Python 3.10+
- Conda(推荐)
- Docker(环境托管)
- OpenAI API Key(基线 Agent 用,
export OPENAI_API_KEY=sk-...) - 高内存/CPU(推荐 AWS AMI 预装镜像,避免手动建站)
2. 安装依赖(Installation)
bash
conda create -n webarena python=3.10
conda activate webarena
pip install -r requirements.txt
playwright install # 安装浏览器(Chromium 等)
pip install -e . # 可编辑安装
# 可选:开发模式
pip install -e ".[dev]"
mypy --install-types --non-interactive browser_env agents evaluation_harness
pip install pre-commit
pre-commit install3. 搭建环境(Environment Setup) - 核心步骤
环境用 Docker 运行多个网站(OneStopShop 电商、Reddit、GitLab、CMS、地图、Wikipedia 等)。
- 详见
/environment_docker/README.md。 - 推荐:用 AWS AMI(预装所有网站,快速启动)。
- 启动后,配置网站 URL(替换为你的域名/端口):
bash
export SHOPPING="<your_shopping>:7770"
export SHOPPING_ADMIN="<your_cms>:7780/admin"
export REDDIT="<your_reddit>:9999"
export GITLAB="<your_gitlab>:8023"
export MAP="<your_map>:3000"
export WIKIPEDIA="<your_wiki>:8888/wikipedia_en_all_maxi_2022-05/A/User:The_other_Kiwix_guy/Landing"
export HOMEPAGE="<your_home>:4399"- 重置环境:用脚本恢复初始状态。
- 获取自动登录 Cookie:
bash
mkdir -p ./.auth
python browser_env/auto_login.py4. 生成任务配置(Generate Config Files)
bash
python scripts/generate_test_data.py输出 812 个 .json 到 /config_files/(每个任务的高层意图 + 验证器)。
5. 快速测试(Quick Start)
用 minimal_example.py 体验 Gym-like 接口:
python
from browser_env import ScriptBrowserEnv, create_id_based_action
import random
env = ScriptBrowserEnv(
headless=False, # headless=True 后台运行
observation_type="accessibility_tree", # 或 "html" / "screenshot"
current_viewport_only=True,
viewport_size={"width": 1280, "height": 720},
)
config_file = "config_files/0.json" # 示例任务
obs, info = env.reset(options={"config_file": config_file})
# 示例动作:ID-based click(推荐,精确无歧义)
id_ = random.randint(0, 1000)
action = create_id_based_action(f"click [{id_}]")
obs, _, terminated, _, info = env.step(action)观察:URL + 多标签页 + 内容(Accessibility Tree 最优)。动作:click/hover/type/new_tab 等。
6. 运行基线 Agent & 评估(Run Baselines & Evaluate)
用 run.py 跑 few-shot/CoT Agent(GPT-4o 等):
bash
python run.py \
--instruction_path agent/prompts/jsons/p_cot_id_actree_2s.json \ # CoT 提示模板
--test_start_idx 0 \
--test_end_idx 812 \ # 全 benchmark
--model gpt-4o \ # 或 gpt-3.5-turbo
--result_dir ./results- 输出:HTML 轨迹(
./results/0.html),自动评估成功率。 - 并行跑:
/parallel_run.sh。 - 评估 :
/evaluation_harness检查功能正确性(r_info / r_prog),支持离线验证。 - 结果上传 Leaderboard 分享。
7. 实现自己的 Agent
- 提示工程 :在
/agent/prompts/raw定义 JSON(intro/examples/template/meta_data)。 - Prompt Constructor :继承
/agent/prompts/prompt_constructor.py,实现construct(建输入)和_extract_action(解析输出)。 - 示例:CoT/ReAct 风格,支持 ID-based 动作。
- 集成其他 LLM:
/llms/。
8. 关键目录
| 目录/文件 | 作用 |
|---|---|
/agent |
Agent 提示 & 实现 |
/browser_env |
浏览器环境 & 自动登录 |
/config_files |
任务 JSON |
/environment_docker |
Docker 搭建 |
/evaluation_harness |
评估工具 |
/resources |
人类轨迹/执行记录 |
run.py |
主运行脚本 |
minimal_example.py |
快速 demo |
9. 常见问题 & 更新(2025)
- bug 修复:v0.2.0 修复标注错误;2025 更新 mypy 类型检查、地图后端内存。
- 扩展 :新 benchmark(终端/编码任务,12/2024);ZenoML 集成(
/scripts/webarena-zeno.ipynb)。 - 问题:Docker 镜像大,用 AMI;CVE-2025-4022 已修补。
- 社区:GitHub Issues;X 上活跃讨论新 SOTA。
资源:
- 官网:https://webarena.dev/(视频/任务示例)
- 论文/轨迹:仓库
/resources - 跑完分享结果到 Leaderboard,推动研究!
搭好后,就能公平测试 Agent 了。最新 SOTA 仍远低于人类,空间巨大~ 😎
后记
2025年12月29日于上海。在grok fast辅助下完成。