ViTa-Zero: Zero-shot Visuotactile Object 6D Pose Estimation
- 文章概括
- ABSTRACT
- [I. INTRODUCTION](#I. INTRODUCTION)
- [II. RELATED WORK](#II. RELATED WORK)
-
- [A. Vision-based Pose Estimation](#A. Vision-based Pose Estimation)
- [B. Visuotactile-based Pose Estimation](#B. Visuotactile-based Pose Estimation)
- [III. PROBLEM DEFINITION](#III. PROBLEM DEFINITION)
- [IV. METHODOLOGY](#IV. METHODOLOGY)
-
- [A. Visual Estimation](#A. Visual Estimation)
- [B. Feasibility Checking](#B. Feasibility Checking)
- [C. Test-time Optimization](#C. Test-time Optimization)
- [V. EXPERIMENTS](#V. EXPERIMENTS)
-
- [A. Qualitative Results](#A. Qualitative Results)
- [B. Quantitative Results](#B. Quantitative Results)
- [VI. CONCLUSION](#VI. CONCLUSION)
文章概括
引用:
bash
@inproceedings{li2025vita,
title={ViTa-Zero: Zero-shot visuotactile object 6D pose estimation},
author={Li, Hongyu and Akl, James and Sridhar, Srinath and Brady, Tye and Pad{\i}r, Ta{\c{s}}k{\i}n},
booktitle={2025 IEEE International Conference on Robotics and Automation (ICRA)},
pages={16050--16057},
year={2025},
organization={IEEE}
}
markup
Li, H., Akl, J., Sridhar, S., Brady, T. and Padır, T., 2025, May. ViTa-Zero: Zero-shot visuotactile object 6D pose estimation. In 2025 IEEE International Conference on Robotics and Automation (ICRA) (pp. 16050-16057). IEEE.主页:
原文:
代码、数据和视频:
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
ABSTRACT
物体 6D 位姿估计是机器人领域的一项关键挑战,尤其是在操作(抓取/操控)任务中。 尽管以往将视觉与触觉(视触觉,visuotactile)信息相结合的研究展现出良好前景,但由于视触觉数据的可用性有限,这些方法往往在泛化方面表现不佳。 在本文中,我们提出 ViTa-Zero,一种 零样本(zero-shot) 的视触觉位姿估计框架。 我们的核心创新在于:以视觉模型作为骨干,并基于从触觉与本体感知(proprioceptive)观测中得到的物理约束,进行可行性检查与测试时(test-time)优化。 具体而言,我们将夹爪与物体的相互作用建模为一个弹簧---质点(spring--mass)系统:触觉传感器引入吸引力,而本体感知产生排斥力。 我们在真实机器人平台上进行实验来验证该框架,并展示其在多种具有代表性的视觉骨干网络与操作场景中都有效,包括抓取、拾取物体以及双臂交接(bimanual handover)。 与纯视觉模型相比,我们的方法在跟踪手内(in-hand)物体位姿时,能够克服一些严重的失败模式。 在实验中,与 FoundationPose 相比,我们的方法在 ADD-S 的 AUC 上平均提升 55%,在 ADD 上平均提升 60%,并且位置误差降低 80%。
I. INTRODUCTION
为了像人类一样智能地操控物体,机器人必须能够准确感知物体在环境中的状态。 这种感知中的一个关键方面是物体的 6D 位姿估计,即在三维空间中同时估计物体的位置与朝向,它是描述物体状态的一种关键表示形式 1。 准确的位姿估计可以提升基于状态的操控策略性能,并提高学习效率和任务成功率 2--8。 以往研究主要关注实例级位姿估计 9--12、类别级位姿估计 13--15,以及近年来提出的新物体位姿估计 16--20。 尽管取得了这些进展,与端到端的视觉---运动方法相比,基于状态的方法在实际真实世界应用中仍然面临显著挑战 2, 3, 21, 22。 其原因在于真实世界中的位姿估计本身极具挑战性,尤其是在接触频繁、遮挡严重且交互动态变化的手内操控任务中 5, 23。
为了更好地估计手内物体的位姿,已有研究探索了将视觉与触觉(视触觉)传感观测相结合的方法 23--32。 这些研究在抓取和手内操控任务中表现出性能提升,因为触觉传感器能够揭示被遮挡的物体部分,从而在操控过程中增强位姿估计。 然而,这也引入了一些实际层面的挑战: (1)由于触觉传感器脆弱且种类多样,采集视触觉数据集十分困难,难以在真实世界中规模化 33。 尽管仿真提供了一种潜在解决方案,但仿真到现实的差距仍然十分显著 7, 25, 26, 34; (2)视触觉模型往往对特定硬件配置和接触信号丰富的场景(如手内物体位姿估计)过拟合,在静态、无遮挡场景下难以达到纯视觉模型的性能; (3)由于引入了触觉数据,以及触觉传感器和夹爪在结构上的非统一性,将视觉模型中的泛化技术直接迁移到视触觉模型中并非易事。 因此,大多数现有模型都是传感器特定、实例级的,这在很大程度上限制了其实用性。
在本文中,我们通过提出 ViTa-Zero 来应对上述挑战,该框架通过零样本方式融合视觉与触觉信息,实现对新物体 6D 位姿的估计与跟踪。 我们的框架可以使用任意具备能力的视觉模型作为骨干,从而继承在大规模视觉数据集上训练得到的泛化能力。 在实验中我们发现,视觉模型在物体操控过程中所面临的不利视觉条件下经常会失效(见图 1)。 为了解决这一问题,我们基于三类物理约束,对视觉估计结果引入可行性检查: (1)接触约束:若检测到正向接触信号,物体必须与触觉传感器发生接触; (2)穿透约束:在任何时刻,物体都不能与机器人发生穿透(由本体感知判断); (3)运动学约束:物体的运动必须在物理上是可行的。
 图 1:FoundationPose 16(左)在手内物体跟踪过程中由于突发性误差(如遮挡)或累积性误差(如噪声)而失败;我们的方法(右)利用触觉与本体感知观测实现稳定跟踪。
图 1:FoundationPose 16(左)在手内物体跟踪过程中由于突发性误差(如遮挡)或累积性误差(如噪声)而失败;我们的方法(右)利用触觉与本体感知观测实现稳定跟踪。
当基于这些约束判断视觉估计不可行时,我们利用触觉与本体感知信息,通过测试时优化过程对其进行修正。具体而言,我们将夹爪---物体的相互作用建模为弹簧---质点系统,其中物体会根据触觉信号,被一个虚拟的"吸引弹簧"拉向触觉传感器。同时,一个"排斥弹簧"将物体推离机器人,以避免发生穿透。该优化过程使得系统即使在动态变化且存在遮挡的场景中,也能够实现稳健的实时跟踪。
为了验证其有效性,我们将该框架应用于两个具有代表性的新物体视觉位姿估计模型 16, 17,并在真实机器人平台上进行了大量实验,且未采集任何触觉数据用于微调。实验结果表明,ViTa-Zero 在性能上显著优于其所依赖的视觉模型。我们的主要贡献可总结如下:
-
1)我们提出了首个零样本视触觉新物体位姿估计框架,显著提升了视触觉方法的实用性。
-
2)我们提出了一种在测试时利用触觉与本体感知对视觉估计结果进行修正的优化方法,兼具效果与效率。
-
3)我们在真实机器人操控场景中对该方法进行了评估,展示了相较于基础视觉模型 16, 17 的大幅性能提升。
II. RELATED WORK
在本节中,我们从两个角度回顾位姿估计领域的代表性工作:基于视觉的方法以及基于视触觉的方法。同时,我们还简要讨论这些方法在机器人操控任务中的相关性及其影响。
A. Vision-based Pose Estimation
传统上,位姿估计研究主要集中于实例级估计 9--12,这类方法将训练后的模型限制在特定的已知物体上,从而限制了其在真实世界应用中的实用性。 近年来的研究将研究范围扩展至类别级位姿估计 13--15,甚至新物体位姿估计 16--20,以应对更广泛应用场景所带来的挑战。 值得注意的是,FoundationPose 16 在新物体位姿估计任务中取得了当前最优性能,其通过大规模合成数据集与高逼真渲染,实现了有效的仿真到现实迁移。 然而,接触频繁的操控任务通常会引入不利条件(如遮挡严重、高动态性),这使得纯视觉方法的效果大打折扣。 此外,由于触觉传感器在结构上的非统一性以及更为显著的仿真到现实差距,将类似的规模化训练规律应用于触觉感知并非易事。
位姿估计已被广泛应用于基于状态的控制策略中,例如文献 6--8 利用视觉位姿估计完成手内物体重定向任务。 然而,这些实验通常依赖复杂的实验设置,如防护笼或多视角系统,并且一般仅限于单一物体,从而限制了其在真实世界中的适用性。 因此,与视觉---运动端到端方法相比,基于状态的控制策略在真实环境中的部署更加困难 2--4。
B. Visuotactile-based Pose Estimation
相比之下,视触觉方法通过融合视觉输入与触觉感知,提供了一种不同的解决思路。 Kuppuswamy 等人 35 使用迭代最近点(ICP)算法,结合一种基于视觉的软泡传感器,对接触区域提供的稠密几何数据进行触觉位姿估计。 Dikhale 等人 25 提出同时利用 RGB-D 与触觉信息,以提升手内物体位姿估计的性能。 后续研究探索了多种技术手段,例如在触觉单元(taxel)信号上应用图神经网络 27, 28,将触觉感知与本体感知相结合 27,引入显式的形状补全模块 24,以及对稀疏触觉信号进行超分辨率重建 31。 尽管这些方法展现出良好潜力,但它们通常受限于数据集问题,并且容易对特定类型的触觉传感器和夹爪结构产生过拟合。
与我们工作最为相关的是 Liu 等人 29 的研究,该方法同样利用触觉信号来修正视觉估计结果。 然而,该方法依赖于训练一个特定模型来跟踪物体速度,并计算安装在平行夹爪上的两个基于视觉的触觉传感器中标记点的光流 36。 当该方法应用于非视觉类触觉传感器时会面临困难,因为此类传感器难以获得光流信息。 相比之下,我们的零样本框架利用物理约束,对触觉传感器类型和末端执行器的要求更少,因此在真实世界应用中更具通用性。
III. PROBLEM DEFINITION
给定一个刚性物体 O \mathcal{O} O,我们在相机坐标系下估计其位姿 T = ( R , t ) ∈ S E ( 3 ) T = (R, t) \in \mathbb{SE}(3) T=(R,t)∈SE(3),其中包括其朝向 R ∈ S O ( 3 ) R \in \mathbb{SO}(3) R∈SO(3) 和位置 t ∈ R 3 t \in \mathbb{R}^3 t∈R3。 遵循新物体位姿估计的常见问题设定 16, 17,我们假设物体 O \mathcal{O} O 的三维网格模型 M O M_\mathcal{O} MO 已知或可通过重建获得 37, 38。 物体 O \mathcal{O} O 通过 RGB-D 传感器进行观测,并且至少在初始帧中是可见的。
机器人 物体 O \mathcal{O} O 由具有刚性连杆和关节的机器人 R \mathcal{R} R 进行操控。 我们假设机器人的运动学模型及其各部件的网格模型是已知的,例如通过统一机器人描述格式(URDF)提供,从而能够精确计算机器人的末端执行器位姿。 末端执行器坐标系与相机坐标系之间的相对变换通过手眼标定获得 39。
传感器 机器人 R \mathcal{R} R 配备触觉传感器 S \mathcal{S} S,并且其安装位置是已知的。 我们假设触觉传感器只会与物体 O \mathcal{O} O 接触,而不会发生自接触。 尽管本文主要关注基于触觉单元(taxel)的传感器,我们的框架同样可以扩展到其他类型的触觉传感器,这将在下一节中讨论。
IV. METHODOLOGY
我们的框架由三个模块组成:视觉估计、可行性检查以及触觉修正。 我们框架的整体概览如图 2 所示。 在初始阶段,视觉模型给出一个位姿估计,记为 T T T。 随后,我们利用由触觉信号和本体感知信息导出的约束,对位姿 T T T 的可行性进行评估。 若 T T T 不满足这些约束条件,我们将利用触觉与本体感知观测,通过测试时优化算法对其进行修正,最终得到位姿估计 T ∗ T^* T∗。
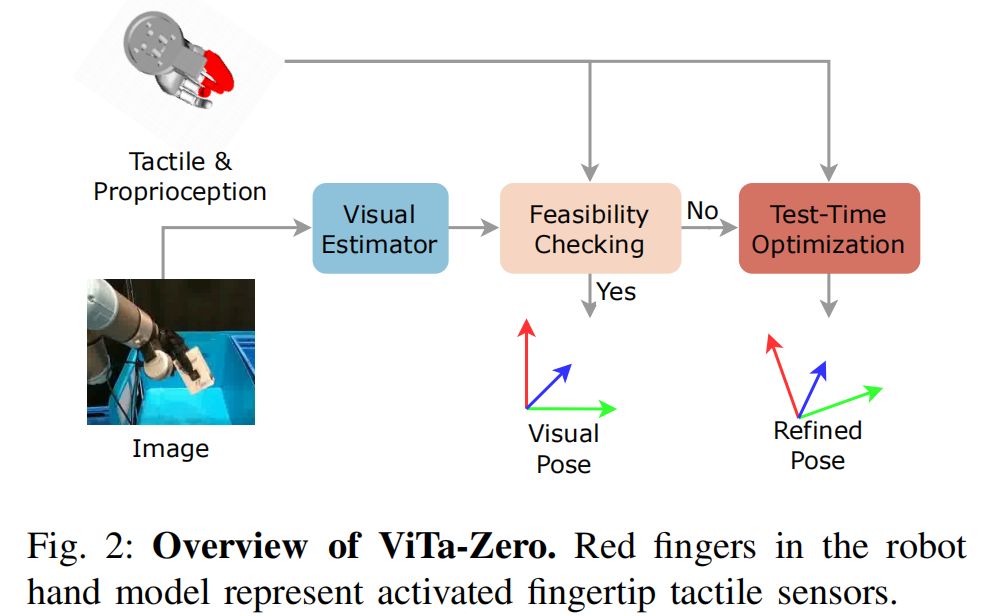
A. Visual Estimation
我们将视觉观测输入到视觉模型中,以获得初始位姿估计 𝑇 𝑇 T 。 在本文中,对于 RGB 输入我们使用 MegaPose 17,对于 RGB-D 输入我们使用 FoundationPose 16。 我们遵循"先估计、后跟踪(estimate-then-track)"的流程: 我们在第一帧使用位姿估计模型,在后续帧使用位姿跟踪模型,以估计相邻两帧之间的相对位姿。 我们的实验表明,由于缺乏足够的视觉线索,视觉模型难以应对严重遮挡和高动态场景,导致在操控任务中出现显著失败以及误差累积(图 3)。 因此,利用触觉感知对视觉结果进行修正,对于实现可靠的操控至关重要。
 图 3:定性结果。 我们展示了在"camera"和"eyedrop"两种物体上执行拾取(object picking)与双臂交接(bimanual handover)任务时的表现。 在这些操控任务中,如图所示,经常会遇到物体在运动过程中被严重遮挡的情况。 由于缺乏足够的视觉信息,诸如 FoundationPose 之类的视觉方法可能会丢失跟踪并导致失败。 相比之下,我们的方法利用额外的触觉与本体感知反馈来维持物体跟踪,从而保证更稳健的性能。 需要说明的是,本研究未使用腕部相机(wrist cameras)。
图 3:定性结果。 我们展示了在"camera"和"eyedrop"两种物体上执行拾取(object picking)与双臂交接(bimanual handover)任务时的表现。 在这些操控任务中,如图所示,经常会遇到物体在运动过程中被严重遮挡的情况。 由于缺乏足够的视觉信息,诸如 FoundationPose 之类的视觉方法可能会丢失跟踪并导致失败。 相比之下,我们的方法利用额外的触觉与本体感知反馈来维持物体跟踪,从而保证更稳健的性能。 需要说明的是,本研究未使用腕部相机(wrist cameras)。
B. Feasibility Checking
我们介绍用于可行性检查的各类观测的几何表示形式,包括:触觉信号、物体以及机器人(本体感知)。
Representation for the tactile signals. 以往研究通常将触觉信号表示为图像形式 40--45 或原始数值形式 46, 47。 然而,这些表示方式在不同类型传感器之间的泛化能力较差,例如基于图像的方法并不适用于 taxel 传感器或力/力矩(F/T)传感器。 为了提升在不同触觉传感器之间的泛化能力,我们将触觉信号表示为相机坐标系下的点云 P S P_\mathcal{S} PS,其空间位置可通过正向运动学计算获得。 对于本文所使用的基于 taxel 的触觉传感器,通过二值阈值对传感器输出进行离散化,从而得到点的布尔取值 24, 25, 47, 48。 对于基于视觉的触觉传感器 36, 49--51,其点云可通过深度估计方法获得 23, 35, 52--55。
1) 触觉信号怎么表示:从"各玩各的格式"变成"统一的点云 P S P_\mathcal{S} PS"
1.1 以前常见两种表示为什么不够好?
论文说以往把触觉表示成:
- 图像形式(比如把触觉阵列当成一张灰度图、热力图)
- 原始数值形式(比如一个向量:每个 taxel 的压力值、或 F/T 的 6 维力矩数据)
问题在哪?跨传感器不通用:
图像法适合"本来就像图像"的传感器(比如有二维阵列、分辨率明确),但
- 你换成 taxel 触觉阵列(可能排布不规则、分辨率不同)就很别扭
- 你换成 F/T 传感器(只有 6 维)根本没"图像"可画
原始数值向量法也类似:不同传感器输出维度/含义差太多,模型很难"同一套网络到处用"。
所以他们要找一个传感器无关(或更接近无关)的中间表示。
2) 他们的关键改法:把触觉变成"空间点云" P S P_\mathcal{S} PS
2.1 这是什么意思?
点云 P S P_\mathcal{S} PS 就是一堆 3D 点:
每个点代表"这里发生了接触"(或"这里有触觉激活"),并且这个点的位置是在相机坐标系 下的 ( x , y , z ) (x,y,z) (x,y,z)。
这一步非常重要:
- 触觉本来是"传感器自己的读数"(局部坐标、设备私有格式)
- 他们把它转换成"相机坐标系下的几何事实":哪里在碰物体
一旦变成点云,后面你就能做几何操作:距离、最近点、碰撞、约束优化......这些都跟"传感器长什么样"关系小很多。
3) 触觉点云的"位置"怎么得到?------靠正向运动学(Forward Kinematics)
这句你要牢牢记住:
触觉点的空间位置不是传感器直接告诉你的,而是"机器人运动学算出来的"。
为什么算得出来?
- 触觉传感器装在机器人某个 link/指尖上
- 每个 taxel 在传感器局部坐标系中有固定位置(安装时就确定了)
- 机器人每时刻有关节角 q q q,你用正向运动学就能算出传感器整体在空间的位姿
- 再把 taxel 的局部点坐标变换到相机坐标系,就得到了 3D 点的位置
你可以把它理解成一个"坐标流水线":
- 已知 taxel 在传感器坐标系里的位置: p i S p^{S}_i piS
- 用 FK 算出传感器/末端在机器人基座里的位姿: T S base ( q ) T^{\text{base}}_{S}(q) TSbase(q)
- 用手眼标定把基座系转到相机系: T base c T^{c}_{\text{base}} Tbasec(或等价链路)
- 得到相机系下 taxel 的位置: p i c = T base c ∗ T S base ( q ) ∗ p i S p^c_i = T^{c}{\text{base}} * T^{\text{base}}{S}(q) * p^{S}_i pic=Tbasec∗TSbase(q)∗piS (写法可能略不同,但思想就是一串变换乘起来。)
这就是系统结构上的关键:
- 触觉"读数"告诉你哪些 taxel 亮了
- FK + 标定把这些 taxel "亮的位置"投到相机系里
于是触觉变成:在相机坐标系里的一堆接触点。
4) 对 taxel 传感器:用阈值离散化得到"布尔接触点"
论文说对本文的 taxel 触觉:
- 用一个二值阈值把输出离散化
- 得到点的布尔取值 0 / 1 0/1 0/1
这是什么意思? taxel 每个都有一个压力值/电容变化值,但他们先不追求精确力大小,只想要稳定的"有没有接触":
- 大于阈值 → 认为"接触发生" → 该 taxel 对应一个点加入 P S P_\mathcal{S} PS
- 小于阈值 → 不接触 → 不加入
为什么这样做很聪明?
- 力大小在不同传感器之间标定差异大、噪声也大
- 二值化更稳、更容易跨设备泛化
- 后面做几何约束时,"接触点在哪里"往往比"力到底多大"更基础、也更可靠
你可以把它想成:
我不关心你按得多用力,我只关心你哪里按到了。
5) 对"视觉触觉"(visuotactile)传感器:用深度估计恢复点云
视觉触觉传感器(比如 GelSight 一类)本质是:
- 相机拍橡胶表面的形变
- 形变反推接触的几何/高度图/深度
所以论文说:
- 这类传感器的点云可以通过深度估计方法获得
意思是:把"橡胶表面形变图像"变成"接触表面的 3D 形状",再转换到相机坐标系里,也能得到 P S P_\mathcal{S} PS。 你要抓住共同点: 不管传感器内部原始数据是什么(taxel 数值、F/T 六维、GelSight 图像),他们都想把它们变成同一种东西:
"在相机坐标系里的接触点云"。
这就是"泛化能力更强"的根本原因:统一表示。
Representation for the object. 给定物体的网格模型 M O M_\mathcal{O} MO,我们通过在网格表面随机采样点,获得用于接触约束检查的物体模型点云 P O P_\mathcal{O} PO。 随后,对 P O P_\mathcal{O} PO 进行体素化下采样,生成体素网格 V O V_\mathcal{O} VO,以加速碰撞检测。
6) 物体怎么表示:mesh M O M_\mathcal{O} MO → 点云 P O P_\mathcal{O} PO → 体素网格 V O V_\mathcal{O} VO
这一段是在给后面的"接触约束检查/碰撞检测"准备一个可计算的物体几何。
6.1 为什么不直接用 mesh 做接触检查?
mesh 是三角面片集合,精确但计算常常更重:
- 最近点查询、碰撞检测会更复杂
- 大量迭代优化时会慢
所以常用做法是:用更"离散但好算"的表示替代或辅助。
7) 第一步:在 mesh 表面随机采样点 → 得到物体点云 P O P_\mathcal{O} PO
这很直观:
- 物体表面是一个连续曲面
- 我们随机取很多点来近似这个表面
P O P_\mathcal{O} PO 的用途在原文写得很明确:
用于"接触约束检查"
也就是说:当你有触觉点云 P S P_\mathcal{S} PS(接触点),你就需要一个物体表面表示 P O P_\mathcal{O} PO 来判断:
- 这些接触点是否真的落在物体表面附近?
- 在当前估计位姿 T T T 下,物体表面与触觉点是否一致?
后面很多算法会用"点到表面距离"或"点到最近表面点距离"做残差。
8) 第二步:体素化下采样 + 生成体素网格 V O V_\mathcal{O} VO,加速碰撞检测
这里有两个动作:
8.1 体素化下采样(voxel downsampling)
点云如果太密:
- 最近邻查询更慢
- 优化每一步成本更高
体素下采样就是:把空间切成立方格子(体素),每个格子只保留少量代表点(常见保留一个中心/平均点)。 结果:点数大幅下降,但形状仍然大体保持。
8.2 生成体素网格 V O V_\mathcal{O} VO
体素网格是更"离散"的结构:
空间里哪些小方块被物体占据。
碰撞检测为什么喜欢体素?
- 判断"某个点是否在物体内部/附近"可以变成查表(hash / grid lookup)
- 比和三角网格做复杂几何相交要快很多
所以原文说:
用 V O V_\mathcal{O} VO 来加速碰撞检测
这对应算法结构里的一个性能模块:
- 精确几何(mesh)用于建模来源
- 点云用于接触约束
- 体素用于快速碰撞/占据查询
Representation for the robot. 我们采用由关节角参数化的机器人网格表示 M R M_\mathcal{R} MR,而不是直接使用关节角或末端执行器位置 27, 46, 47, 56,因为后者对具体机器人结构依赖较强,且物理意义不够直观。 该网格进一步转换为下采样的点云 P R P_\mathcal{R} PR,并采用与物体网格相同的下采样技术,以加速可行性检查。
1) 机器人怎么表示:为什么不用关节角/末端位姿,而用机器人网格 M R M_\mathcal{R} MR → 点云 P R P_\mathcal{R} PR
1.1 他们为什么不直接用"关节角 q q q"或"末端位置"?
因为这两种表示对具体机器人结构依赖太强:
- 关节角 q q q:不同机器人关节数量、排列方式、意义都不一样。 同一组数字,在不同机器人上完全不是一回事。
- 末端位姿 :只描述了末端在哪儿,但机器人身体其他部分在哪里没描述。 可是碰撞/穿透常常发生在"手背/手指侧面/前臂",不是只有末端。
而网格 M R M_\mathcal{R} MR 表示的是:
机器人在空间里真实的几何外形(每个 link 的表面)
这非常"物理直观":你看一眼网格就知道机器人在哪儿、会不会撞到东西。
1.2 网格怎么变成点云 P R P_\mathcal{R} PR?
同你前面学的物体一样:
- 在机器人网格表面采样点
- 再用体素化下采样减少点数
得到 P R P_\mathcal{R} PR 的目的很明确:
加速可行性检查(比如下面的穿透检查)
一句话理解: 网格太精细不好算,所以用"下采样点云"做快速几何检查。
1)接触约束: 触觉点云 P S P_\mathcal{S} PS 中的每一个点,都必须与物体模型点云中的某个点发生接触。 变换后的物体点云 P O P_\mathcal{O} PO 中的点 p O i \mathbf{p}^i_\mathcal{O} pOi 与触觉点云 P S P_\mathcal{S} PS 中的点 p S j \mathbf{p}^j_\mathcal{S} pSj 之间的最小欧氏距离必须满足:
min i , j ∥ T ( p O i ) − p S j ∥ ≤ θ c , (1) \min_{i,j}\left\lVert T(\mathbf{p}^i_\mathcal{O}) - \mathbf{p}^j_\mathcal{S} \right\rVert \le \theta_c, \tag{1} i,jmin T(pOi)−pSj ≤θc,(1)
其中, θ c \theta_c θc 表示接触距离阈值。
2) 约束 1:接触约束(Contact Constraint)------触觉点必须贴在物体表面上
2.1 你要先明白两个点云各代表什么
- P S P_\mathcal{S} PS:触觉点云 每个点代表"这里发生了接触"(在相机坐标系)
- P O P_\mathcal{O} PO:物体模型点云(从 mesh 采样的表面点) 代表物体表面长啥样
你要估计一个位姿 T T T。注意: T T T 的作用是把物体模型点从"物体坐标系"搬到"相机坐标系":
- T ( p O i ) T(\mathbf{p}_\mathcal{O}^i) T(pOi):第 i i i 个物体表面点在相机坐标系下的位置
2.2 公式 (1) 在说什么?(把数学翻译成人话)
min i , j ∥ T ( p O i ) − p S j ∥ ≤ θ c \min_{i,j}\left\lVert T(\mathbf{p}^i_\mathcal{O}) - \mathbf{p}^j_\mathcal{S} \right\rVert \le \theta_c i,jmin T(pOi)−pSj ≤θc
这句话的真实意思是:
对于触觉点云里的"接触点",在变换后的物体表面上应该能找到某些点离它很近。 这个"很近"的标准就是阈值 θ c \theta_c θc。
更直观一点:
- 你手指上某个 taxel 亮了 → 说明那里碰到了物体
- 那么在你估计的位姿 T T T 下,物体表面必须靠近那个 taxel 所在位置
- 否则你的位姿估计就不可能是真的
θ c \theta_c θc 是什么? 它是"允许的贴合误差",用来容忍:
- 触觉阈值的离散化误差
- FK 和手眼标定误差
- 点云采样稀疏造成的最近点误差
如果 θ c \theta_c θc 设太小:几乎所有解都被判不合格 设太大:约束变松,解会漂
最容易卡的点:触觉不是告诉你"物体点在哪",而是告诉你"接触必须发生在这里附近"。 所以这是一个"几何一致性"检查。
2)穿透约束: 机器人模型上的任何点都不应穿透物体模型,反之亦然。 该约束通过检查变换后的物体体素网格 T ( V O ) T(V_\mathcal{O}) T(VO) 与机器人模型点云 P R P_\mathcal{R} PR 之间的重叠(交集)来实现。 我们以机器人下采样点云 P R P_\mathcal{R} PR 作为查询点,并计算其在物体模型体素中的占比:
card T ( V O ) ∩ P R card T ( V O ) ≤ θ p , (2) \frac{\operatorname{card}\bigT(V_\\mathcal{O}) \\cap P_\\mathcal{R}\\big}{\operatorname{card}\bigT(V_\\mathcal{O})\\big} \le \theta_\mathrm{p}, \tag{2} cardT(VO)cardT(VO)∩PR≤θp,(2)
其中, card ⋅ \operatorname{card}\\cdot card⋅ 表示集合的基数, θ p \theta_\mathrm{p} θp 是用于补偿传感器噪声和标定误差的允许重叠阈值。
3) 约束 2:穿透约束(Penetration Constraint)------机器人和物体不能互相穿进去
这就是你玩 3D 游戏时最熟悉的问题: 穿模是不允许的。
3.1 为什么用体素网格 V O V_\mathcal{O} VO 来做?
因为"点云-点云"做碰撞需要大量最近邻查询,慢。 体素能把"是否撞进物体"变成一次查表,快得多。
V O V_\mathcal{O} VO:物体体素网格(占据集合)
T ( V O ) T(V_\mathcal{O}) T(VO):把物体体素网格也用位姿 T T T 变换到相机坐标系(或等价坐标系) 本质上是:物体在当前估计姿态下占据了哪些体素
P R P_\mathcal{R} PR:机器人下采样点云,作为"探针点"(query points)
3.2 公式 (2) 的人话解释
card T ( V O ) ∩ P R card T ( V O ) ≤ θ p \frac{\operatorname{card}\bigT(V_\\mathcal{O}) \\cap P_\\mathcal{R}\\big}{\operatorname{card}\bigT(V_\\mathcal{O})\\big} \le \theta_\mathrm{p} cardT(VO)cardT(VO)∩PR≤θp
先拆开每个符号:
- card ⋅ \operatorname{card}\\cdot card⋅:集合里有多少元素(基数)
- T ( V O ) ∩ P R T(V_\mathcal{O}) \cap P_\mathcal{R} T(VO)∩PR: "机器人点云里有多少点落在物体占据体素里" 这就是"穿透的证据"
所以整条约束的意思是:
机器人点落在物体占据区域里的比例不能太高。 允许一点点重叠(噪声/标定误差),但不能大面积穿进去。
为什么要允许重叠阈值 θ p \theta_p θp? 现实系统不可能零误差:
- 标定偏一点,点就可能落进体素
- 下采样让表面变粗糙,边界点会抖动
- 触觉/视觉噪声会导致位姿略偏
所以 θ p \theta_p θp 是"容错带"。
最容易卡的点:他们并不是做"精确几何碰撞",而是在做"快速可行性筛查"。体素 + 点云就是为了快。
3)运动学约束: 物体的运动必须在物理上是可行的。 通过对物体位置施加如下的一阶微分约束,可防止不现实的运动行为(例如对称物体在相邻帧之间发生姿态翻转),从而保证物体运动符合真实动力学特性:
∥ P n − P n − 1 ∥ ≤ θ d , (3) \lVert P_n - P_{n-1} \rVert \le \theta_\mathrm{d}, \tag{3} ∥Pn−Pn−1∥≤θd,(3)
其中, P n ⊂ P O P_n \subset P_\mathcal{O} Pn⊂PO 表示第 n n n 帧中物体模型上的接触区域。
4) 约束 3:运动学约束(这里更像"时间连续性/一阶微分约束")------相邻帧接触区域不能乱跳
这段是专门防一个很典型的灾难: 对称物体会有多个姿态在几何上看起来一样(或几乎一样),算法可能在两帧之间突然"跳到另一个等价解"。
比如:
- 圆柱体、方块、某些对称零件
- 你从接触点很难区分它到底是哪一面朝上
- 于是上一帧估计"这面朝上",下一帧突然估计"翻转 180° 那面朝上"
- 视觉上可能都解释得通,但物理上不可能一瞬间翻过去
他们用一个"一阶微分约束"来抑制这种不现实跳变。
4.1 公式 (3) 在说什么?
∥ P n − P n − 1 ∥ ≤ θ d \lVert P_n - P_{n-1} \rVert \le \theta_\mathrm{d} ∥Pn−Pn−1∥≤θd
这里的关键是:
- P n ⊂ P O P_n \subset P_\mathcal{O} Pn⊂PO 表示第 n n n 帧物体模型上的接触区域 也就是:在当前位姿估计下,哪些物体表面点"正在接触"
这条式子的直觉是:
相邻两帧中,"接触发生在物体表面的哪个区域"不能跳太远。 接触区域应该平滑移动,而不是瞬间跑到物体另一侧。
这为什么能防"姿态翻转"?
如果你突然把姿态翻到对称解:
- 原来接触在"物体的这一面"
- 翻转后等价成"物体另一面"
- 接触区域在物体表面上的对应点会发生巨大的变化 → ∥ P n − P n − 1 ∥ \lVert P_n - P_{n-1}\rVert ∥Pn−Pn−1∥ 立刻变大 → 被这条约束否掉
θ d \theta_d θd 是什么?
还是"允许的变化上限",容忍真实运动带来的接触滑移,但不允许瞬间大跳。
最容易卡的点:这里的"运动学约束"不是机器人关节约束,而是物体接触区域的时间连续性约束(用一阶差分限制不现实跳变)。
5) 把三条约束放一起,你就能理解它的"算法结构"了虽然你贴的段落没写具体求解器,但从这三条式子可以推断它的结构一定是这种模式:
5.1 输入(每帧)
- 触觉点云 P S P_\mathcal{S} PS
- 物体点云 P O P_\mathcal{O} PO + 体素 V O V_\mathcal{O} VO
- 机器人点云 P R P_\mathcal{R} PR
- 上一帧接触区域 P n − 1 P_{n-1} Pn−1(用于时间约束)
5.2 输出
- 当前帧物体位姿 T T T
5.3 估计方式(典型)
对候选位姿 T T T 做检查:
- 接触约束 :触觉点必须能在物体表面找到近邻(<= θ c \theta_c θc)
- 穿透约束 :机器人点落入物体体素的比例不能超过 θ p \theta_p θp
- 时间连续性 :当前接触区域与上一帧差异不能超过 θ d \theta_d θd
能同时满足(或违反最少)的候选 T T T 就是合理解。 你可以把它想成:
用触觉把物体"吸"到正确位置(接触贴合), 用体素防止"穿模", 用时间约束防止"跳解"。
C. Test-time Optimization
如果视觉位姿估计 T T T 未能满足任一约束条件,我们将采用测试时优化方法对其进行修正。 我们采用一个由吸引弹簧和排斥弹簧组成的弹簧---质点模型。 根据胡克定律,弹簧会产生形式为 1 2 k x 2 \frac{1}{2}kx^2 21kx2 的弹性势能,其中 x x x 表示弹簧的位移。 不同于以往将弹簧---质点模型用于手部抓取合成的研究 57--59,我们将其重新用于基于触觉与本体感知反馈的物体位姿修正。 该优化的目标是求解一个相对位姿 T Δ T_\Delta TΔ,使吸引弹簧和排斥弹簧产生的总势能最小。
1) 这一步什么时候触发?------视觉位姿 T T T 不靠谱,就用触觉+机器人几何把它"掰回来"
你前面已经有一个视觉估计的物体位姿 T T T(来自视觉 pose estimator)。 但作者说:如果这个 T T T 没通过三条约束 (接触/穿透/运动学),说明它在当前帧不可信。 于是他们不重新训练网络,也不换模型,而是做一个很现实的策略:
测试时优化(test-time optimization) :
把 T T T 当成初值,然后用触觉反馈和机器人几何约束,直接在测试时"微调"出一个更合理的位姿。
这里要记住一个核心结构:
- T T T:视觉给的"初始位姿"
- T Δ T_\Delta TΔ:要优化出来的"修正量"(相对位姿)
- T ∗ = T Δ ∘ T T^*=T_\Delta\circ T T∗=TΔ∘T:最终修正后的位姿
也就是说他们不直接从零求 T ∗ T^* T∗,而是求一个小修正 T Δ T_\Delta TΔ,让结果更稳定、更容易收敛。
2) 他们用什么模型来优化?------把"物体位姿修正"变成"弹簧势能最小化"
作者用一个非常直观的物理类比:弹簧---质点模型。 你可以把它想成:
物体是一个能被拉动/推开的"刚体"
触觉接触点像一堆"挂钩"
机器人几何像"不能穿透的硬墙"
于是:
- 吸引弹簧把物体拉到该接触的位置
- 排斥弹簧在物体与机器人发生穿透时把它推开
弹簧的能量来自胡克定律: E = 1 2 k x 2 E=\frac12 kx^2 E=21kx2 意思是:
- 弹簧拉得越长(或压得越深)→ 能量越大
- 系统会倾向于让能量变小 → 回到"更自然"的状态
所以他们的优化目标就是:
找到 T Δ T_\Delta TΔ,使得"吸引 + 排斥 + 正则化"的总能量最小。
吸引弹簧会将物体拉向处于接触状态的触觉传感器,当物体与所有这些传感器达到理想接触时,弹簧达到其自然长度。 吸引弹簧的势能定义为:
E a = 1 2 k a min i , j ∥ T Δ ( p O i ) − p S j ∥ 2 . E_a=\frac{1}{2}k_a\min_{i,j}\left\lVert T_\Delta(\mathbf{p}^i_\mathcal{O})-\mathbf{p}^j_\mathcal{S}\right\rVert^2. Ea=21kai,jmin TΔ(pOi)−pSj 2.
排斥弹簧用于防止机器人模型 P R P_\mathcal{R} PR 与物体模型 P O P_\mathcal{O} PO 之间发生穿透。
3) 吸引弹簧能量 E a E_a Ea:让物体表面"贴"到触觉接触点附近
吸引弹簧的定义: E a = 1 2 k a min i , j ∥ T Δ ( p O i ) − p S j ∥ 2 . E_a=\frac{1}{2}k_a\min_{i,j}\left\lVert T_\Delta(\mathbf{p}^i_\mathcal{O})-\mathbf{p}^j_\mathcal{S}\right\rVert^2. Ea=21kai,jmin TΔ(pOi)−pSj 2.
先解释每个量:
- p O i \mathbf{p}^i_\mathcal{O} pOi:物体模型点云中的第 i i i 个点(物体表面采样点)
- p S j \mathbf{p}^j_\mathcal{S} pSj:触觉点云的第 j j j 个点(哪个 taxel 被激活对应的 3D 点)
- T Δ ( p O i ) T_\Delta(\mathbf{p}^i_\mathcal{O}) TΔ(pOi):把物体点用"修正位姿"挪一下之后的位置
这项能量在做的事是:
让修正后的物体表面点,尽量靠近触觉接触点。 越靠近,距离越小,能量越小。
关键直觉
- 触觉点表示"我在这里碰到了物体"
- 那么物体表面就应该出现在这里附近
- 优化会把物体朝着这些触觉点"拉过去"
容易卡的点:为什么又是 min i , j \min_{i,j} mini,j?
它表示"找最近的一对物体点和触觉点"。从严格语义上,文章前面强调"每个触觉点都要接触",但这里能量写成最小值形式,是一种简化写法(实际实现中常见的是对每个触觉点取最近物体点再求和/平均)。但不管形式如何,原意是:触觉接触提供吸引力,把物体拉到接触处。
我们将排斥弹簧的势能定义为
E r = 1 2 k r max ( 0 , γ ) 2 , E_r=\frac{1}{2}k_r\max(0,\gamma)^2, Er=21krmax(0,γ)2,
4) 排斥弹簧能量 E r E_r Er:只要发生穿透,就把它"顶出来"
排斥弹簧能量:
E r = 1 2 k r max ( 0 , γ ) 2 , E_r=\frac{1}{2}k_r\max(0,\gamma)^2, Er=21krmax(0,γ)2,
这句非常关键:只有当 γ > 0 \gamma>0 γ>0 时才惩罚。
- 如果 γ ≤ 0 \gamma\le 0 γ≤0:认为没穿透或在安全侧 → 排斥能量为 0
- 如果 γ > 0 \gamma>0 γ>0:认为有穿透 → 能量随穿透程度平方增长 → 强力推开
所以 E r E_r Er 是一个典型的"ReLU式惩罚":
- 不违反约束:不管
- 一违反:立刻罚,而且罚得越来越重
其中 γ \gamma γ 表示穿透距离,其定义为:
γ = 1 card ( P R ) ∑ i ( p ~ O i − p R i ) ⋅ n ~ O i . (4) \gamma=\frac{1}{\operatorname{card}(P_\mathcal{R})}\sum_i(\tilde{\mathbf{p}}{\mathcal{O}}^i-\mathbf{p}{\mathcal{R}}^i)\cdot \tilde{\mathbf{n}}_\mathcal{O}^i. \tag{4} γ=card(PR)1i∑(p~Oi−pRi)⋅n~Oi.(4)
其中, p ~ O i = arg min p ∈ P O ∣ ∣ p − T Δ ( p R i ) ∣ ∣ \tilde{\mathbf{p}}{\mathcal{O}}^i=\arg\min{\mathbf{p}\in P_\mathcal{O}}||\mathbf{p}-T_\Delta(\mathbf{p}^i_\mathcal{R})|| p~Oi=argp∈POmin∣∣p−TΔ(pRi)∣∣
表示机器人第 i i i 个修正后点在物体点云 P O {P}{\mathcal{O}} PO 中的最近邻点; 而 n ~ O i \tilde{\mathbf{n}}\mathcal{O}^i n~Oi 表示该最近邻点在物体表面上的单位外法向量。 因此, γ \gamma γ 表示机器人点云 P R P_\mathcal{R} PR 与其在物体点云 P O {P}_{\mathcal{O}} PO 中最近邻点之间,沿法向方向的带符号距离的平均值。
5) 最关键、最容易卡的点: γ \gamma γ 到底是什么?公式(4)到底在算啥?
γ = 1 card ( P R ) ∑ i ( p ~ O i − p R i ) ⋅ n ~ O i . (4) \gamma=\frac{1}{\operatorname{card}(P_\mathcal{R})}\sum_i(\tilde{\mathbf{p}}{\mathcal{O}}^i-\mathbf{p}{\mathcal{R}}^i)\cdot \tilde{\mathbf{n}}_\mathcal{O}^i. \tag{4} γ=card(PR)1i∑(p~Oi−pRi)⋅n~Oi.(4)
别怕,这个式子其实只在算一种东西:
机器人点到物体表面最近点的"沿法向的带符号距离",然后对所有机器人点取平均。
我们一步步拆开:
5.1 机器人点 p R i \mathbf{p}_\mathcal{R}^i pRi 是什么?
- P R P_\mathcal{R} PR 是机器人下采样点云(机器人表面许多点)
- p R i \mathbf{p}_\mathcal{R}^i pRi 是第 i i i 个机器人点
注意:这里实际用的是 修正后的位置,它写在最近邻定义里:
p ~ O i = arg min p ∈ P O ∣ ∣ p − T Δ ( p R i ) ∣ ∣ \tilde{\mathbf{p}}{\mathcal{O}}^i=\arg\min{\mathbf{p}\in P_\mathcal{O}}||\mathbf{p}-T_\Delta(\mathbf{p}^i_\mathcal{R})|| p~Oi=argp∈POmin∣∣p−TΔ(pRi)∣∣
这句话是:
- 先把机器人点 p R i \mathbf{p}^i_\mathcal{R} pRi 用 T Δ T_\Delta TΔ 变换一下(你可以理解为"在当前修正假设下,它相对物体的位置改变了")
- 然后在物体点云 P O P_\mathcal{O} PO 里找一个最近的物体表面点 这个最近点就是 p ~ O i \tilde{\mathbf{p}}_{\mathcal{O}}^i p~Oi
5.2 n ~ O i \tilde{\mathbf{n}}_\mathcal{O}^i n~Oi 是什么?
- 它是这个最近邻物体点处的单位外法向量
- "外法向"就是"从物体表面朝外指"的方向
直觉:
- 法向告诉你表面朝哪边是外面,哪边是里面
5.3 点积 ( p ~ O i − p R i ) ⋅ n ~ O i (\tilde{\mathbf{p}}{\mathcal{O}}^i-\mathbf{p}{\mathcal{R}}^i)\cdot \tilde{\mathbf{n}}_\mathcal{O}^i (p~Oi−pRi)⋅n~Oi 在干嘛?
这是最核心的一步。
- 向量 ( p ~ O i − p R i ) (\tilde{\mathbf{p}}{\mathcal{O}}^i-\mathbf{p}{\mathcal{R}}^i) (p~Oi−pRi):从机器人点指向物体最近点的方向与距离
- 点积 " ⋅ n ~ \cdot \tilde{\mathbf{n}} ⋅n~":只取这段距离在"法向方向上的分量"
所以它得到的是一个沿法向方向的带符号距离:
- 如果机器人点在物体表面的外侧(没有穿透),这个值通常是 非正(或负,取决于符号约定)
- 如果机器人点跑进了物体内部(穿透),沿外法向方向看就会变成 正值(表示"你从里面往外走才能到表面")
作者总结得很清楚:
γ \gamma γ 是机器人点与物体最近表面点之间沿法向方向的带符号距离的平均值。
5.4 为什么要对所有机器人点取平均?
- 单个点可能是噪声、偶然靠近
- 平均能更稳,也更像"整体穿透程度"
但也要注意:平均意味着它是一个"整体指标",不是"最坏点"。这也是为什么前面还要用阈值式的穿透约束做筛查;而这里用于优化时,用平均值给一个平滑的梯度更利于 Adam 收敛。
我们将相对位姿 T Δ T_\Delta TΔ 参数化为相对旋转 R Δ R_\Delta RΔ(使用 RoMa 库 60 以角轴形式表示)和相对平移 t Δ \mathbf{t}_\Delta tΔ。 我们在参数上施加 L 2 L_2 L2 正则化,以稳定优化过程。 修正后的位姿 T ∗ T^* T∗ 通过如下方式获得:
T Δ = arg min R Δ , t Δ ( E a + E r + λ L 2 ) , T ∗ = T Δ ∘ T , (5) \begin{aligned} T_\Delta &= \argmin_{R_\Delta,\mathbf{t}_\Delta}(E_a+E_r+\lambda \mathcal{L}2),\\ T^* &= T\Delta\circ T, \end{aligned} \tag{5} TΔT∗=RΔ,tΔargmin(Ea+Er+λL2),=TΔ∘T,(5)
其中 L 2 \mathcal{L}_2 L2 表示 L 2 L_2 L2 正则化损失项。 在后续帧中,我们基于 T ∗ T^* T∗ 进行位姿跟踪。
6) 相对位姿 T Δ T_\Delta TΔ 怎么参数化?------旋转 + 平移,旋转用角轴(RoMa)
他们把:
- T Δ T_\Delta TΔ 表示成 ( R Δ , t Δ ) (R_\Delta,\mathbf{t}_\Delta) (RΔ,tΔ)
旋转 R Δ R_\Delta RΔ 用 角轴(axis-angle) 表示,并用 RoMa 库来做(这通常是为了:
- 参数连续、易优化
- 能把旋转放进 PyTorch 的计算图里求梯度)
你可以这样理解角轴:
- 一根轴 u \mathbf{u} u(单位向量)
- 一个角度 ϕ \phi ϕ
- 含义是:绕轴 u \mathbf{u} u 旋转 ϕ \phi ϕ
这样优化变量就是:
- 3 个旋转参数(角轴向量常用 3D 向量编码)
- 3 个平移参数 t Δ \mathbf{t}_\Delta tΔ
合起来 6 个自由度(刚体位姿的标准形式)。
7) 为什么要加 L 2 L_2 L2 正则化?------让修正不要"发疯"
他们优化的是:
T Δ = arg min R Δ , t Δ ( E a + E r + λ L 2 ) , T ∗ = T Δ ∘ T , (5) \begin{aligned} T_\Delta &= \argmin_{R_\Delta,\mathbf{t}_\Delta}(E_a+E_r+\lambda \mathcal{L}2),\\ T^* &= T\Delta\circ T, \end{aligned} \tag{5} TΔT∗=RΔ,tΔargmin(Ea+Er+λL2),=TΔ∘T,(5)
这里 L 2 \mathcal{L}_2 L2 是对参数的 L 2 L_2 L2 正则化,直觉就是:
不要让 T Δ T_\Delta TΔ 变得过大。 你只是"修正视觉的错误",不是把物体瞬移到另一个世界。
它的作用:
- 抑制不稳定的大旋转/大平移
- 避免优化被某些噪声触觉点"带偏"
- 让解更像"局部微调"
λ \lambda λ 就是调节力度的旋钮:
- 太小:正则化没用,可能抖
- 太大:修正量太小,修不回来
我们使用 PyTorch 61 框架并采用 Adam 62 优化器实现该算法。 为了促进优化过程的收敛,我们利用被激活的触觉单元(taxel)的平均平移变化来初始化 T Δ T_\Delta TΔ。 这种初始化策略能够平滑优化过程,并提升整体性能。
8) 他们怎么优化?------PyTorch + Adam(能量函数可微 → 梯度下降)
他们用 PyTorch 的好处是:
- E a E_a Ea、 E r E_r Er 都是连续函数(距离平方、ReLU平方)
- 只要最近邻查询那部分处理得可微/近似可微(或者把最近邻当作固定匹配来迭代更新),就可以用梯度法
Adam 是一种很常见的自适应学习率优化器:
- 对这种非凸、小规模参数(6D 位姿)优化很常用
- 收敛更稳一些
所以整体就是:
初始化 T Δ T_\Delta TΔ
重复若干步:
- 计算 E a , E r , L 2 E_a, E_r, L_2 Ea,Er,L2
- 反向传播算梯度
- Adam 更新 ( R Δ , t Δ ) (R_\Delta, t_\Delta) (RΔ,tΔ)
得到 T ∗ = T Δ ∘ T T^*=T_\Delta\circ T T∗=TΔ∘T
后续帧用 T ∗ T^* T∗ 作为跟踪起点
9) 初始化为什么用"激活 taxel 的平均平移变化"?------给优化一个"朝正确方向的第一脚油门"
这一句在工程上非常重要:
用被激活 taxel 的平均平移变化初始化 T Δ T_\Delta TΔ
直觉是:
- taxel 亮的位置在相机系里是点云 P S P_\mathcal{S} PS
- 这些点相对上一帧或相对当前预测会有一个整体偏移趋势
- 你先用它估一个"物体大概应该往哪儿挪"的平移初值 → 优化就不会从完全随机的方向开始 → 更容易收敛,过程更平滑
你可以把它理解为: 先用"接触点整体移动了多少"给一个粗平移,然后再让 Adam 精修旋转和平移。
10) 把整个 Test-time Optimization 总结
当视觉位姿 T T T 不满足约束时:
准备数据
- 触觉点云 P S P_\mathcal{S} PS(接触发生在哪些 3D 点)
- 物体点云 P O P_\mathcal{O} PO(物体表面)+ 法向
- 机器人点云 P R P_\mathcal{R} PR(机器人表面)
建一个能量函数
- 吸引能量 E a E_a Ea:把物体拉向触觉接触点
- 排斥能量 E r E_r Er:只要穿透就推开
- 正则项:不让修正过猛
优化 6D 修正位姿 T Δ T_\Delta TΔ
- 变量:角轴旋转 + 平移
- 工具:PyTorch 自动求导 + Adam
- 初值:用激活 taxel 的平均平移做一个平移初始化
输出修正结果
- T ∗ = T Δ ∘ T T^*=T_\Delta\circ T T∗=TΔ∘T
后续跟踪
- 下一帧从 T ∗ T^* T∗ 开始跟踪,更稳
V. EXPERIMENTS
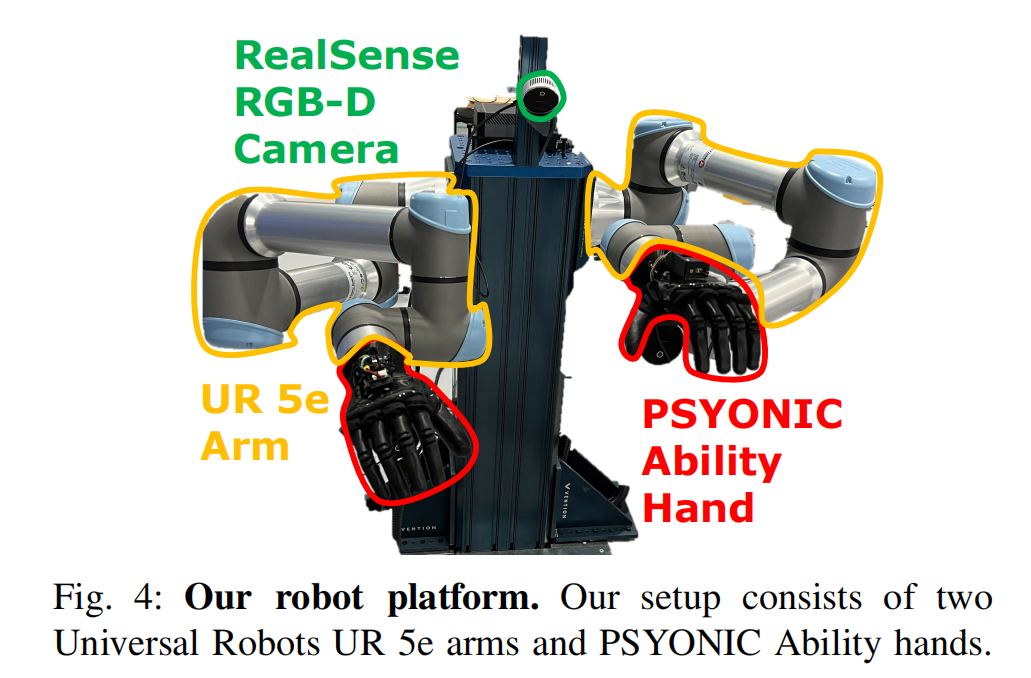
我们在一个真实机器人平台上对所提出的方法进行了评估(见图 4),该平台由两台 Universal Robots UR5e 机械臂和两只 PSYONIC Ability 灵巧手组成。 该类人灵巧手具有五根手指,每根手指的指尖均配备六个 FSR 传感器,用于提供触觉感知。 有关该平台的更多细节可参见文献 46。 视觉感知由 RealSense RGB-D 相机提供,具体使用的是 D455 与 L515 型号的组合。 尽管我们的框架旨在跨不同机器人形态和触觉传感器实现泛化,本文的实验主要聚焦于 Ability 灵巧手平台。 我们在五个日常物体上进行了测试(见图 5),这些物体购自 Amazon.com,能够被 Ability 灵巧手轻松抓取,并且据我们所知并未包含在 Objaverse 63 和 GSO 数据集 64 中。 因此,这五个物体在后续实验中被视为新物体。
在可行性检查阶段,我们将接触阈值设置为 θ c = 0.05 \theta_c=0.05 θc=0.05, 允许穿透阈值设置为 θ p = 0.008 \theta_p=0.008 θp=0.008, 运动学阈值设置为 θ d = 0.03 \theta_d=0.03 θd=0.03。 对于测试时优化算法,优化器的学习率设置为 10 − 3 10^{-3} 10−3, 迭代次数通过经验调节为 10 次。 损失函数的参数设置如下:吸引势能权重 k a = 1 k_a=1 ka=1, 排斥势能权重 k r = 1000 k_r=1000 kr=1000, L 2 L_2 L2 正则化参数 λ = 1000 \lambda=1000 λ=1000。
在随后的实验中,我们将所提出的方法与当前最先进的新物体位姿估计模型进行对比:MegaPose(RGB)和 FoundationPose(RGB-D) 这些模型所需的分割掩码与边界框由现成的模型获得 65, 66。
A. Qualitative Results
图 3 展示了拾取(object picking)与双臂交接(bimanual handover)任务的定性结果。 我们观察到,视觉模型在操控过程中(例如抓取)经常会丢失跟踪,从而导致灾难性的失败。 相比之下,我们的方法能够有效利用触觉与本体感知来修正视觉估计结果,并维持对物体的跟踪。
B. Quantitative Results
由于缺乏公开的视触觉物体位姿估计数据集 ,我们为测试目的自行采集了一个数据集。 我们使用位置误差(PE)以及 ADD 和 ADD-S 的曲线下面积(AUC)来评估性能 9, 16, 24, 25。 PE 定义为真实平移与估计平移之间的 L 2 L_2 L2 范数,即二者差的欧氏范数。
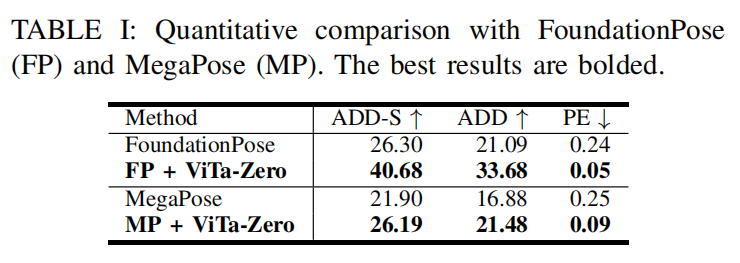
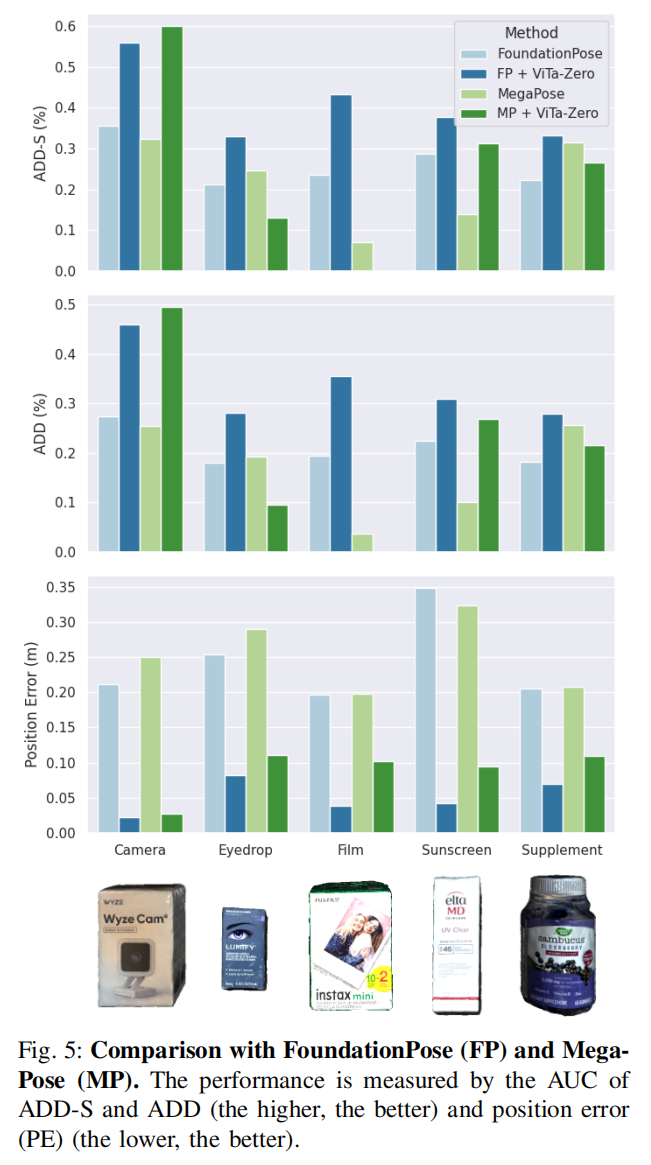
1)与基线方法对比: 我们以 FoundationPose 16 和 MegaPose 17 作为视觉骨干模型,并与它们进行性能对比(见图 5 和表 I)。 由于 MegaPose 缺少深度信息,MegaPose 以及 MP + ViTa-Zero 的性能低于 FoundationPose 以及 FP + ViTa-Zero。 尽管如此,我们的框架在其视觉骨干之上表现出一致的性能提升:与 FoundationPose 相比,ADD-S 的 AUC 平均提升 55%,ADD 平均提升 60%,同时 PE 下降 80%。 尽管取得了显著提升,与其他计算机视觉基准相比,该任务的错误率仍然相对较高 67,这凸显了在操控任务中进行位姿估计所固有的挑战性。
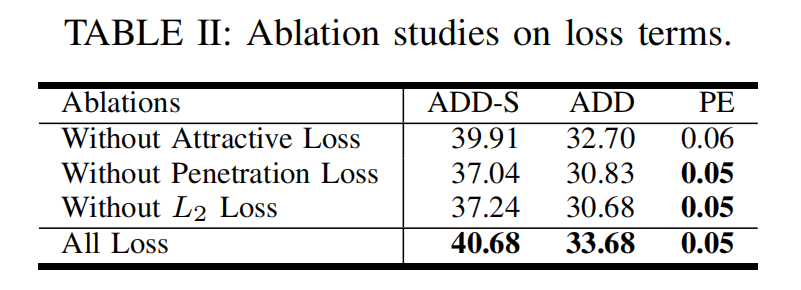
2)各损失项的消融实验: 我们进行消融实验,以评估每一项损失对方法的影响(见表 II)。 当去除吸引项损失时,修正后的位姿将保持静止,不再利用触觉反馈。 不过,只要仍保留穿透损失,位姿仍会在手部模型运动时被"推着"发生变化。 若去除穿透损失,优化往往会得到物体模型穿透机器人模型的解。 若去除 L2 正则化损失,优化过程会变得不稳定,且更难收敛。
总体而言,实验结果表明:在这三项损失中任意去掉一项,都会导致性能下降(以 ADD 与 ADD-S 指标衡量)。
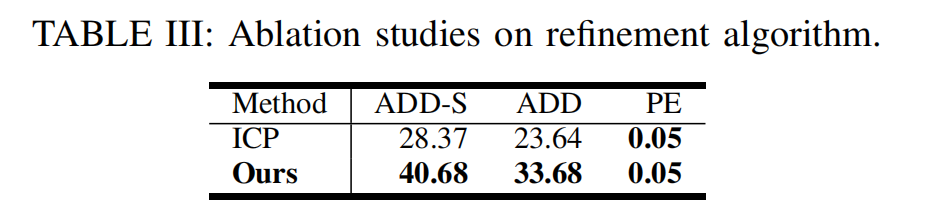
3)修正算法的消融实验: 我们测试时优化算法的一个早期版本可以被视为在触觉点云与物体表面局部区域之间进行点云配准 35。 在本研究中,我们考察将 ICP 算法 68 作为修正算法的效果(见表 III)。 具体而言,我们通过将作为源点云的物体点云 P O P_\mathcal{O} PO 与作为目标点云的触觉点云 P S P_\mathcal{S} PS 进行配准,来计算 T Δ T_Δ TΔ。在本文中,我们采用点到点(point-to-point)的 ICP 估计方法,其目标是最小化对应点之间的欧氏距离。
实验表明,ICP 算法能够通过将视觉位姿 T T T 对齐到最近的触觉点,从而有效地修正视觉估计。 然而,由于缺少穿透惩罚项,得到的解经常会出现与机器人模型发生非预期相互穿透的情况。
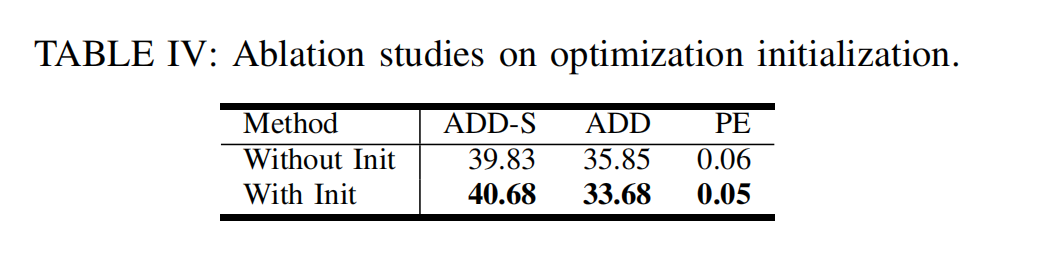
4)优化初始化的消融实验: 在表 IV 中,我们研究移除测试时优化算法初始化步骤所带来的影响。 回顾前述方法,我们使用被激活的触觉单元(taxel)的平均平移量来初始化待优化参数 T Δ T_Δ TΔ 。 鉴于该优化问题具有高度非凸的性质,我们发现这种初始化策略能够使优化过程更加稳定,并促进收敛。
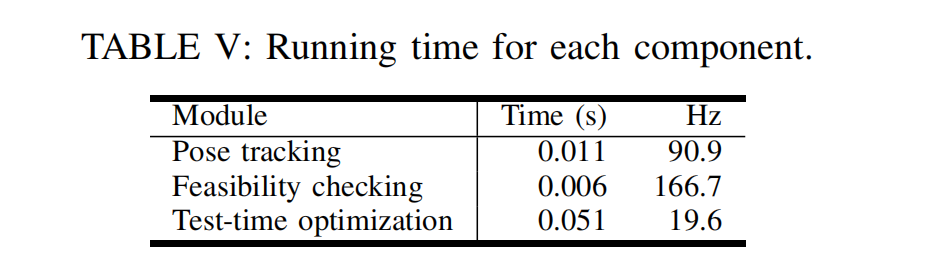
5)运行时间: 鉴于我们关注操控应用,我们评估了框架中各个关键组件的运行时间。 我们的平台配置为 Intel i9-14900K CPU 和 NVIDIA RTX 4090 GPU。 在评估 FoundationPose 的位姿跟踪速度时,我们将其精炼(refinement)迭代次数设置为 2 次。 总体而言,在测试时优化阶段采用 10 次迭代的情况下,我们的框架可达到约 20 Hz 的在线刷新率。
VI. CONCLUSION
在本文中,我们提出了一种新颖的零样本视触觉物体 6D 位姿估计框架。 我们的方法无需采集触觉数据集,并在新物体的真实世界实验中展现出稳健的性能。 所提出的测试时优化算法利用弹簧---质点模型,基于触觉与本体感知观测,对不可行的视觉估计结果进行修正。 实验结果表明,我们的框架能够在视觉模型的基础上实现持续且显著的性能提升。 尤其值得注意的是,在 FoundationPose 上,我们在 ADD-S 的曲线下面积(AUC)上平均提升了 55%,在 ADD 上提升了 60%,同时将位置误差降低了 80%。 此外,我们还进行了大量消融实验,以评估不同设计选择的影响,包括不同的损失函数、修正算法以及优化初始化策略。 在未来工作中,我们计划评估更多种类的物体形状,并将该位姿估计器集成到操控策略中,以评估其对整体操控任务性能的影响。
Limitations. 我们识别出该框架的两个局限性: i)遵循新物体位姿估计的设定,我们假设物体的三维 CAD 模型是已知的,或可以通过参考视角进行重建。 然而,在"野外"操控应用中,这一假设可能较为苛刻,此时可借助主动式视触觉物体重建技术 23 来缓解这一问题。 ii)我们的方法依赖机器人的正向运动学信息,而这一信息在大多数商用夹爪中是可获得的。 然而,在处理可变形或柔性夹爪时,这一假设可能并不容易满足 69。 近期的一些研究 70, 71 为解决这一问题提供了潜在的解决思路。