1. 基本参数
- --master:指定集群主节点,决定Spark程序运行环境。可以设置为:local、localK、local\*、spark://HOST:PORT、yarn等。
- --deploy-mode:指定Driver部署模式,可选Client(默认)、Cluster。
- --class :指定Application运行主类(包含包名和类名),仅适用于Java或者Scala程序。
- --name:指定Application的名称。
- --jars:以逗号分割的本地jar包列表,这些jar将包含在Driver和Executor端。
- --files:以逗号分割的文件列表,这些文件会分发到集群中的每个Worker节点。
- --conf:以key=value形式指定Spark配置属性。
- --supervise:只适用于Standalone和Mesos集群中。指定该参数,在cluster模式下如果 Driver 失败,会自动重启。
2. 资源相关参数
- --driver-memory:设置 Driver 程序的内存大小,默认1024M。
- --executor-memory:设置每个Executor的内存,默认1G。
- --driver-cores :只适用在Cluster模式中。设置Driver使用的core数,默认1。
- --total-executor-cores :只适用于Standalone和Mesos集群中。设置所有Executor使用的总core数,默认Standalone中会使用所有集群中的core。
- --executor-cores :只适用于Standalone、Yarn和K8s集群中 。设置每个Executor使用的核数。Yarn和K8s集群中默认为1。Standalone集群中默认为当前Worker节点的所有core数。
- --num-executors :只适用于Yarn和K8s集群中。设置启动executor的个数,默认2个。
- --queue:只适用于Yarn集群中。指定使用的资源队列。
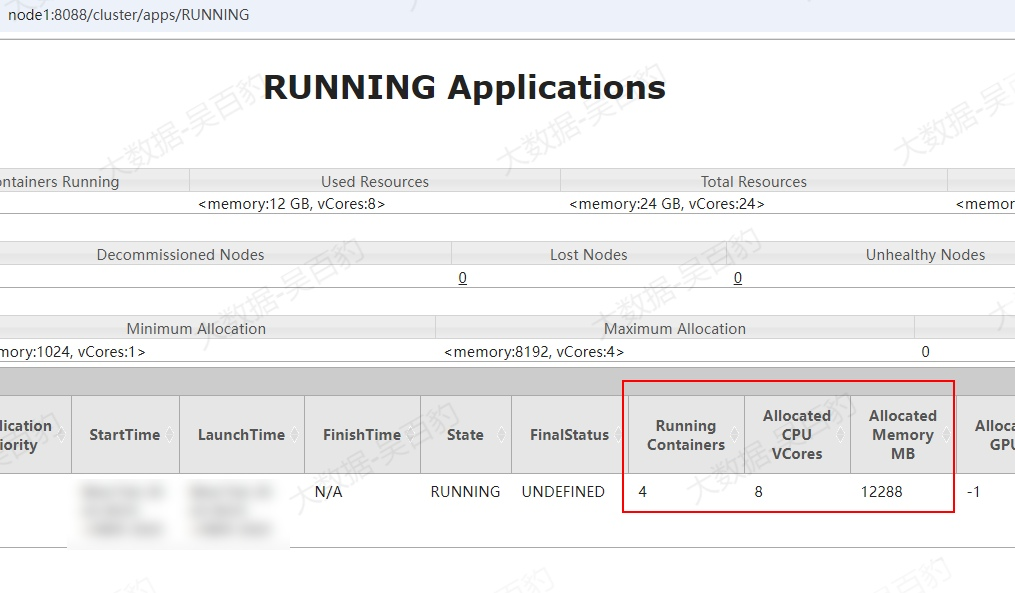
3. Spark任务资源使用测试
下面以向Standalone集群和Yarn集群中提交Spark Pi任务为例,演示集群资源使用情况。
3.1 Standalone集群测试
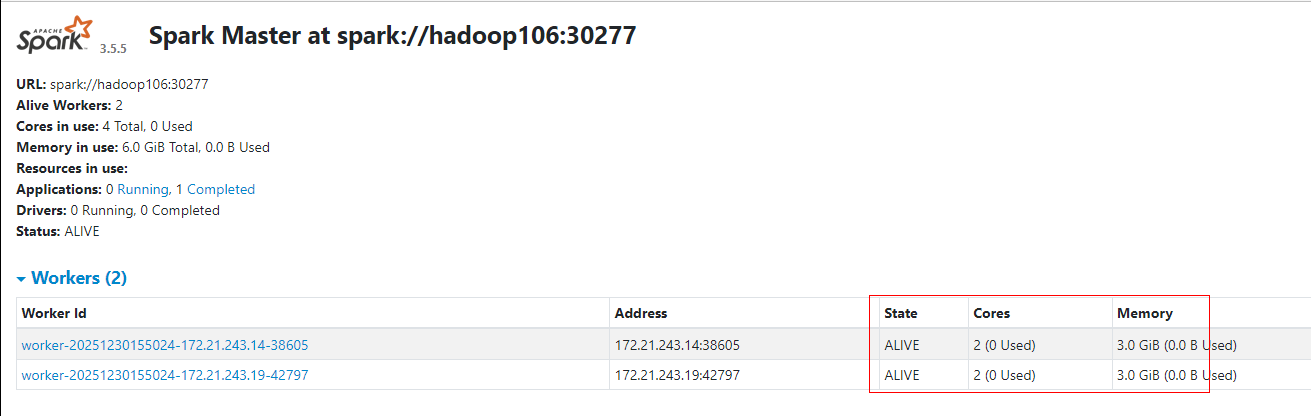
启动Standalone集群,集群中包含2台Worker节点,每台Worker节点配置2core和3G内存:
通过WebUI查看Standalone集群资源如下:
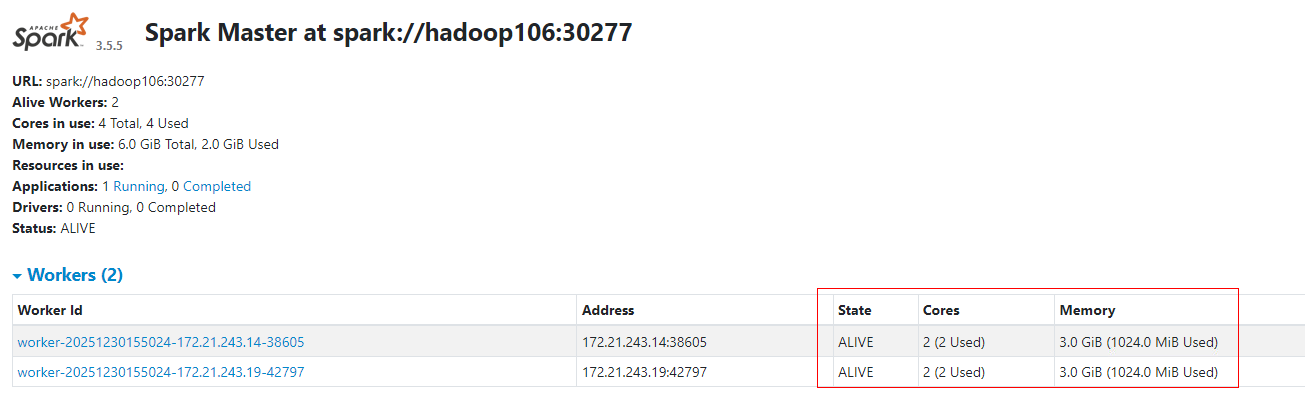
3.1.1 Standalone-client默认
Standalone Client模式中默认提交Spark Application,Driver在客户端启动,默认会使用集群中所有core启动Executor,每个Executor会使用集群中所有core和1G内存。
Standalone-client提交Spark Pi命令如下:
#在node4节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:30277 \
--class org.apache.spark.examples.SparkPi \
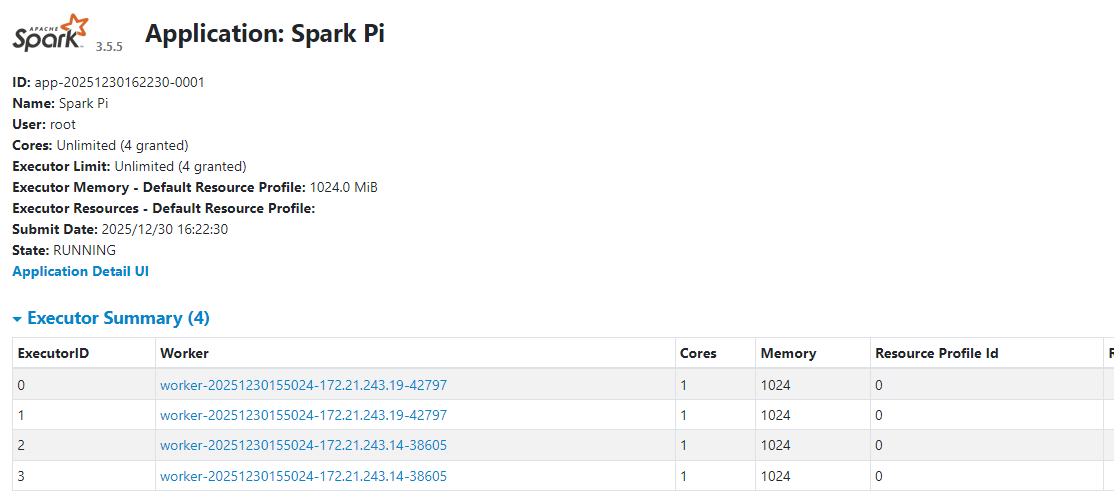
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:
3.1.2 standalone-client指定每个executor使用1core和1G内存
通过参数"--executor-cores"指定启动一个executor使用多少core,这种情况下,Spark Application还会使用集群中所有core资源。通过参数"--executor-memory"指定启动一个Executor使用多少内存。
Standalone-client提交Spark Pi命令如下:
#在hadoop106节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:30277 \
--executor-cores 1 \
--executor-memory 1G \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况,可以看到程序使用了集群中所有worker的core资源,在每个Worker节点上启动了2个Executor,每个Executor按照指定的参数使用了1core和1G内存。
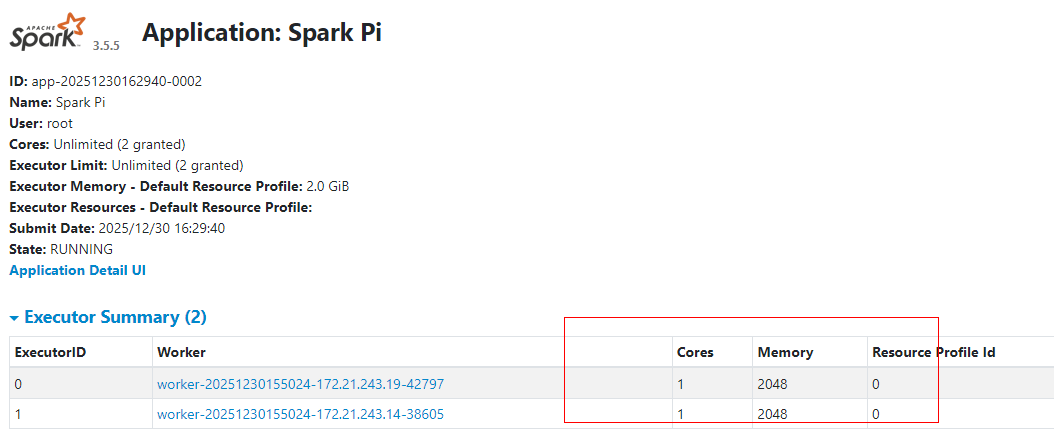
3.1.3 standalone-client指定每个executor使用1core和2G内存
Standalone-client提交Spark Pi命令如下:
#在hadoop106节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:7077 \
--executor-cores 1 \
--executor-memory 2G \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况,可以看到程序尝试使用每台Worker全部的core资源,但是由于指定启动每个Executor使用2G内存,此刻每台Worker节点内存只能启动1个Executor(1core+2G),每个Worker节点剩余1Core和1G内存。
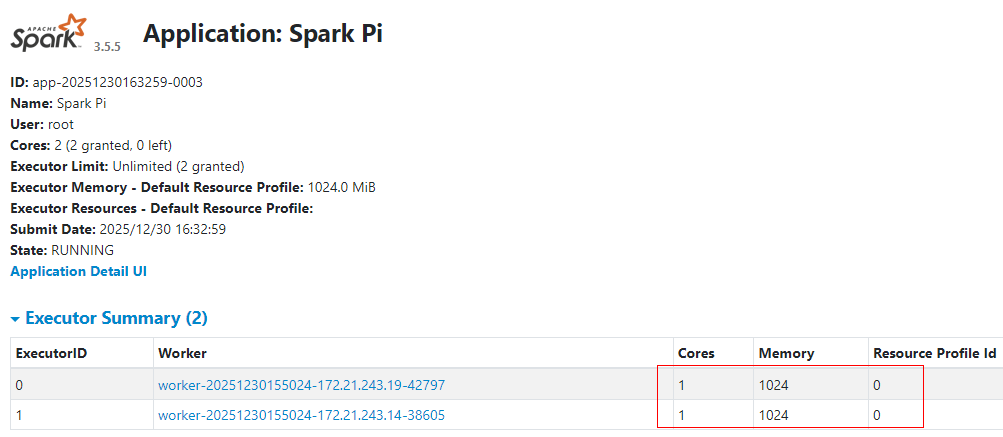
3.1.4 standalone-client指定最多使用集群中2个core用于启动executor
可以通过参数"--total-executor-cores"来限制应用程序使用集群中最多的core。
Standalone-client提交Spark Pi命令如下:
#在hadoop106节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:7077 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000Standalone集群中指定了程序最多使用2个core用于启动Executor,Spark会均衡的在每个Worker节点启动Executor,每个Executor使用1core和1G内存。
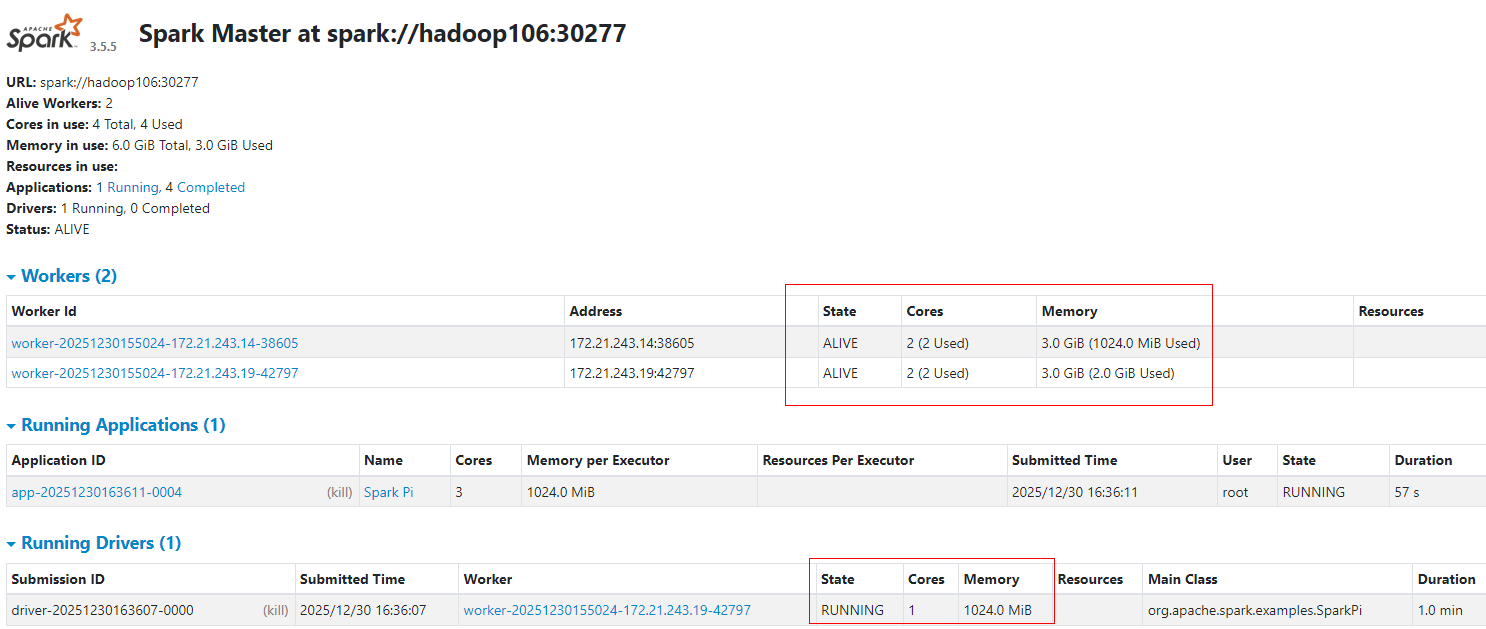
3.1.5 Standalone-cluster默认
Standalone-cluster模式中,Driver会在一台Worker节点启动,默认使用1Core和1G内存;集群中Worker剩余的core都会被用来启动Executor,每个Executor默认使用当前Worker节点所有core和1G内存。
Standalone-Cluster提交Spark Pi命令如下:
#在hadoop106节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况,Driver在其中一台Worker节点启动,使用1core和1G内存。Executor分别在Worker节点启动,使用当前Worker所有core和1G内存。
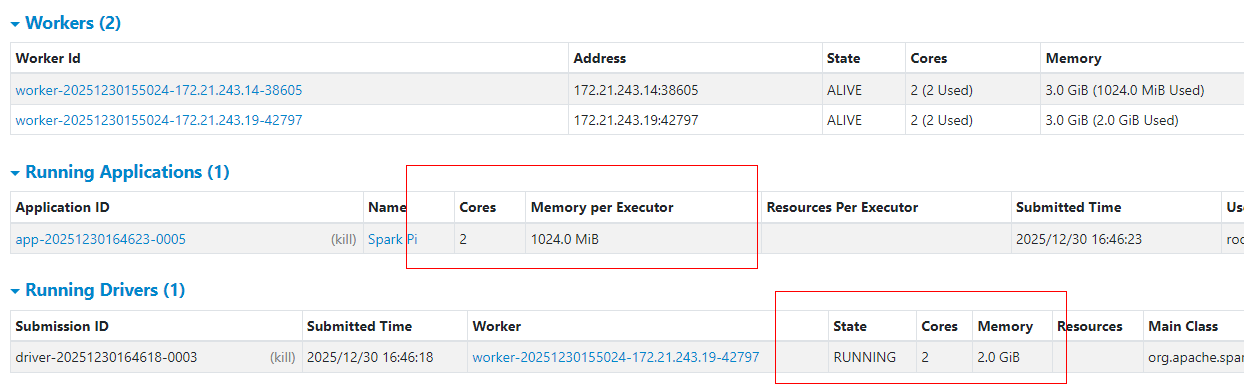
3.1.6 Standalone-cluster指定Driver使用2Core和2G内存
通过参数"driver-cores"指定Driver使用多少core;参数"driver-memory"指定Driver使用多少内存。
Standalone-Cluster提交Spark Pi命令如下:
#在hadoop106节点提交Spark Pi任务
[root@hadoop106 bin]# ./spark-submit \
--master spark://hadoop106:7077 \
--deploy-mode cluster \
--driver-cores 2 \
--driver-memory 2G \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况,Driver在其中一台Worker节点启动,使用2core和2G内存。
3.2 Yarn集群测试
在基于YARN集群提交Spark任务时,为了在YARN的WebUI中正确显示所使用的 CPU核心数量,需要在Hadoop的各个节点上配置 HADOOP_HOME/etc/hadoop/capacity-scheduler.xml文件中的 yarn.scheduler.capacity.resource-calculator 参数。该参数指定YARN Capacity Scheduler在进行资源计算时使用的计算器类。默认值为 org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator,表示仅基于内存(Memory)计算资源,不考虑 CPU 核心,适用于简单场景。为了使调度器同时考虑CPU和内存资源,可以将该值修改为 org.apache.hadoop.yarn.util.resource.DominantResourceCalculator。在Hadoop的node1至node5节点上,编辑 HADOOP_HOME/etc/hadoop/capacity-scheduler.xml 文件,添加以下配置:
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>然后,启动 Hadoop 集群:
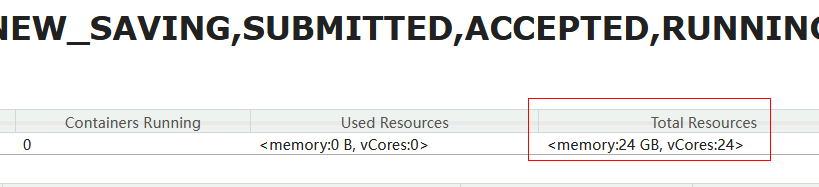
在我们的 YARN 集群中,有 3 个 NodeManager 节点。默认情况下,每个节点的资源为 8GB 内存(由 yarn.nodemanager.resource.memory-mb 配置)和 8 个 CPU 核心(由 yarn.nodemanager.resource.cpu-vcores 配置)。通过 YARN 的 Web UI,可以看到集群的总资源为 24 核 CPU 和 24GB 内存。
在 YARN 上运行 Spark 任务时,除了为 Driver 和 Executor 分配相应的内存外,还需要为每个 Driver 或 Executor 进程分配 memoryOverhead(非堆内存),非堆内存用于 JVM 开销、字符串常量池等。其计算方式如下:
memoryOverhead = max(Driver/Executor 内存 * 0.1, 384MB)因此,在 YARN 上运行 Spark 任务时,为 Driver 或 Executor 分配的总内存为:
总内存 = Driver/Executor 内存 + max(Driver/Executor 内存 * 0.1, 384MB)YARN 在计算上述总内存时,会自动向上取整到最接近的 1024MB(1GB)的整数倍。此外,YARN 的 Client 模式和 Cluster 模式在 ApplicationMaster 内存分配上有所不同:
- Client模式:YARN 启动 ExecutorLauncher 进程,该进程使用固定的 1 核 CPU 和 1GB 内存。
- Cluster模式:YARN 启动 ApplicationMaster 进程,其 CPU 和内存的分配由 --driver-cores 和 --driver-memory 参数决定,且内存分配遵循上述公式。
3.2.1 yarn-client默认
yarn-client模式中,Yarn集群负责为"ExecutorLauncher"进程分配固定的1G+1Core资源;没有指定"--num-executors"参数则默认为Spark任务启动2个Executor;没有指定"--executor-memory"参数则默认为每个Executor分配1G内存资源;没有指定"--executor-cores"参数则默认为每个Executor分配1Core资源。
yarn-client提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]# ./spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:"ExecutorLauncher"使用1G+1Core资源,启动2个Executor,每个Executor使用2G内存(1024M+384M=1408M,向上取整为2048M)+1Core资源,所以总共在Yarn中使用3Core和5G内存(5120M)。

3.2.2 yarn-client指定executor使用2G内存
yarn-client模式中,通过指定"--executor-memory"参数则默认为每个Executor分配2G内存资源;Yarn集群负责为"ExecutorLauncher"进程分配固定的1G+1Core资源;没有指定"--num-executors"参数则默认为Spark任务启动2个Executor;没有指定"--executor-cores"参数则默认为每个Executor分配1Core资源。
yarn-client提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]# ./spark-submit \
--master yarn \
--executor-memory 2G \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:"ExecutorLauncher"使用1G+1Core资源,启动2个Executor,每个Executor使用3G内存(2048M+384M=2432M,向上取整为3072M)+1Core资源,所以总共在Yarn中使用3Core和7G内存(7168M)。
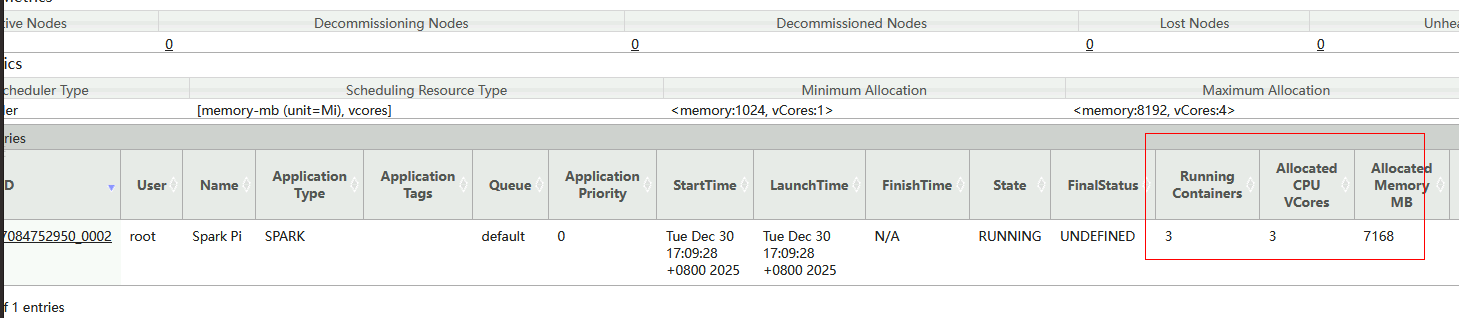
3.2.3 yarn-client指定启动3个executor,每个executor使用2G内存和2个core
yarn-client模式中,通过指定"--num-executors"参数则默认为Spark任务启动2个Executor;指定"--executor-memory"参数则为每个Executor分配2G内存资源;指定"--executor-cores"参数为每个Executor分配2Core资源;Yarn集群负责为"ExecutorLauncher"进程分配固定的1G+1Core资源。
yarn-client提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]# ./spark-submit \
--master yarn \
--num-executors 3 \
--executor-memory 2G \
--executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:"ExecutorLauncher"使用1G+1Core资源,启动3个Executor,每个Executor使用3G内存(2048M+384M=2432M,向上取整为3072M)+2Core资源,所以总共在Yarn中使用7Core和10G内存(10240M)。
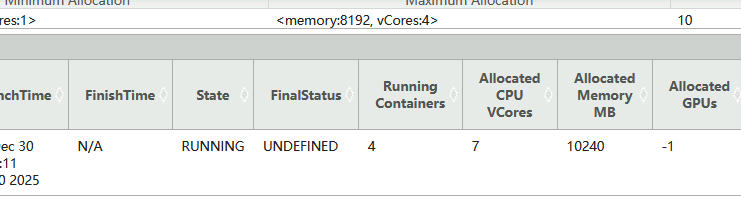
3.2.4 yarn-cluster默认
yarn-cluster模式中,Driver就是ApplicationMaster,Yarn集群根据指定driver参数为ApplicationMaster分配资源。没有指定"--driver-memory"参数则为AM默认分配1G资源;没有指定"--driver-cores"参数则为AM默认分配1core;没有指定"--num-executors"参数则默认为Spark任务启动2个Executor;没有指定"--executor-memory"参数则默认为每个Executor分配1G内存资源;没有指定"--executor-cores"参数则默认为每个Executor分配1Core资源。
yarn-cluster提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]#./spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:ApplicationMaster使用2G(1024M+384M=1048M,向上取整为2048M)+1Core资源,启动2个Executor,每个Executor使用2G内存(1024M+384M=1408M,向上取整为2048M)+1Core资源,所以总共在Yarn中使用3Core和6G内存(6144M)。
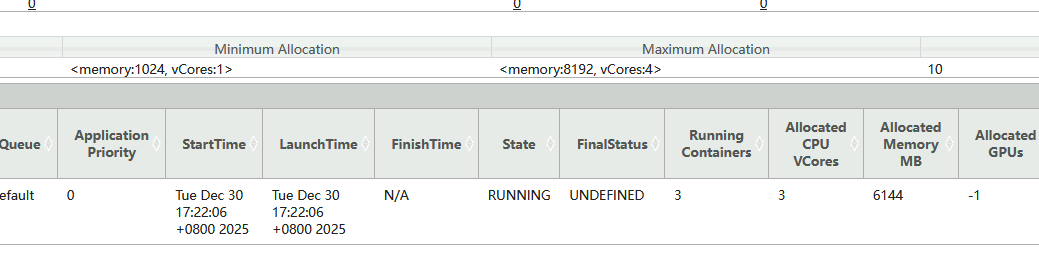
3.2.5 yarn-cluster指定Driver使用2G+2Core资源
yarn-cluster模式中,Driver就是ApplicationMaster,Yarn集群根据指定driver参数为ApplicationMaster分配资源。指定"--driver-memory"参数为AM分配2G资源;指定"--driver-cores"参数为AM分配2core;没有指定"--num-executors"参数则默认为Spark任务启动2个Executor;没有指定"--executor-memory"参数则默认为每个Executor分配1G内存资源;没有指定"--executor-cores"参数则默认为每个Executor分配1Core资源。
yarn-cluster提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]#./spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--driver-cores 2 \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:ApplicationMaster使用3G(2048M+384M=2432M,向上取整为3072M)+2Core资源,启动2个Executor,每个Executor使用2G内存(1024M+384M=1408M,向上取整为2048M)+1Core资源,所以总共在Yarn中使用4Core和7G内存(7168M)。
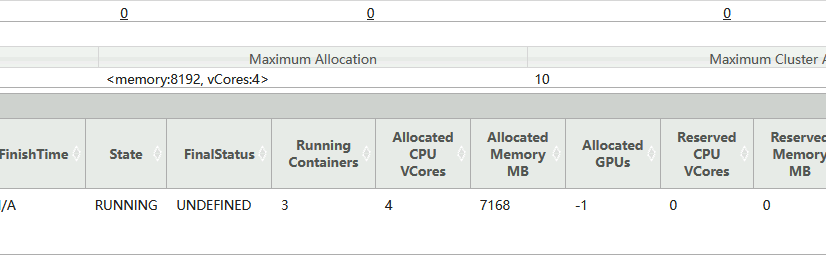
3.2.6 yarn-cluster指定Driver使用2G+2Core资源,启动3个executor,每个executor使用2G内存和2个core
yarn-cluster模式中,Driver就是ApplicationMaster,Yarn集群根据指定driver参数为ApplicationMaster分配资源。指定"--driver-memory"参数为AM分配2G资源;指定"--driver-cores"参数为AM分配2core;指定"--num-executors"参数为Spark任务启动3个Executor;指定"--executor-memory"参数为每个Executor分配2G内存资源;指定"--executor-cores"参数为每个Executor分配2Core资源。
yarn-cluster提交Spark Pi命令如下:
#在hadoop105节点提交Spark Pi任务
[root@hadoop105 bin]#./spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--driver-cores 2 \
--num-executors 3 \
--executor-memory 2G \
--executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
../examples/jars/spark-examples_2.13-3.5.5.jar 100000提交任务后,可以通过WebUI查看当前Application使用资源情况:ApplicationMaster使用3G(2048M+384M=2432M,向上取整为3072M)+2Core资源,启动3个Executor,每个Executor使用3G内存(2048M+384M=2432M,向上取整为3072M)+2Core资源,所以总共在Yarn中使用8Core和12G内存(12288M)。