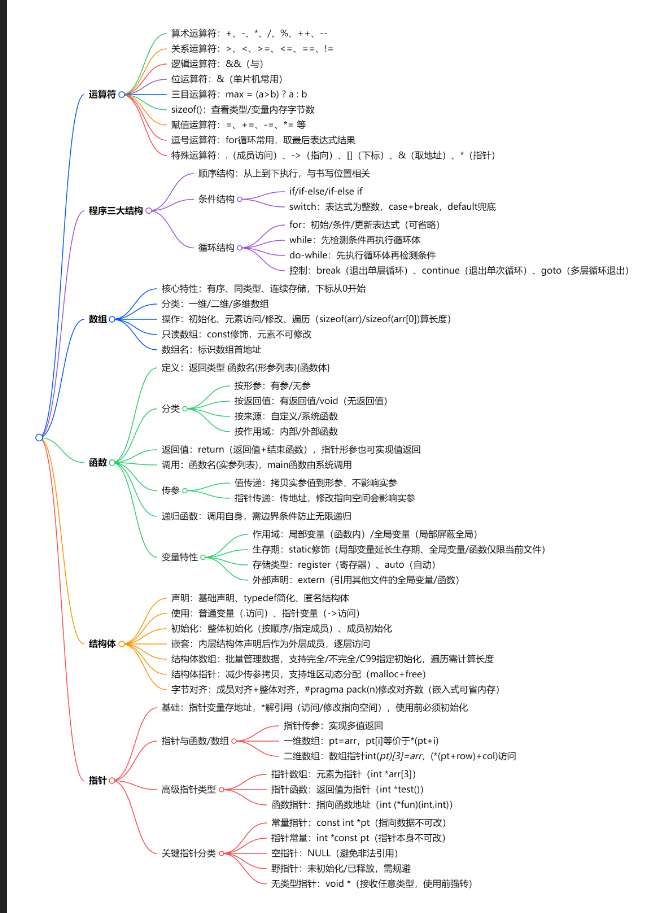
运算符
算术运算符
+、-、*、/、%、++、--
关系运算符
>、<、>=、<=、==、!=
逻辑运算符
&&(与)、
主要用来连接多个条件表达式
位运算符
&
单片机程序开发,一般使用较多
三目运算符
max = (a>b) ? a : b;
sizeof()
主要用来查看指定类型或变量占用内存的字节数
sizeof(变量名)sizeof(类型名或常量)
赋值运算符
=、+=、-=、*= 等
逗号运算符
多用在for循环中
int s = (a++,a+b,a+5);(s 取 a+5)
特点:将最后一个表达式结果当做整个表达式的结果
如果在写表达式的时候,如果要体现优先级,可以使用()来改变优先级
. 成员访问运算符
->指向运算符
\[\]下标运算符
&取地址运算符 *指针运算符
标准输入与输出
printf scanf
scanf("%s%d",&a,&b);
程序的三大结构
顺序结构
特点:程序从上往下依次进行,语句的执行与书写的位置有关
条件结构
if
if else
if else if
switch(常量表达式) //switch后小括号中的表达式的计算结果必须是一个整数
{
case 常量表达式:语句块:break;
...
default:
语句块n+1;
}
循环结构
for
for(初始表达式;条件表达式;更新表达式)
{
循环体
}
初始表达式:在运行for的循环过程中,只执行一次,可以省略
条件表达式:检测结果作为是否退出循环的标准,可以省略
更新表达式:每次执行完循环体,会执行更新表达式,它可以省略
while构建的循环
while(条件表达式) //执行时先检测条件,根据结果来确定是否进入循环体
{
循环体
}
do
{
}while(条件表达式);
break,coninnue
主要用在循环体中
break:退出当前的单层循环
continue:退出当前循环中的一次循环
goto也可以用来实现构建环循环结构
注意:一般多用来退出多层循环的场景
数组
存放同类型数据的有序集合
特点:有序的,元素在逻辑和物理上连续的
可以通过下标对数组中的元素进行访问,下标从0开始
它是一个可以容纳多个数据个体的集合
一维数组
数据类型 数组名常量表达式
二维数组
数据类型 数组名行 列
多维数组
数组的初始化
数组元素的访问
数组元素的修改
数组的遍历
通过下标或指针访问,遍历需要先计算长度:int arr_size = sizeof(arr)/sizeof(arr0)
只读数组
const int arr3 = {11,22,33},元素不可修改
数组名
函数funcation
什么是函数
为了实现特定功能按照一定结构所组织起来的代码集合
复用代码
分解过程
函数是构成c程序的一个最基本的单位
函数的定义格式
返回类型 函数名(形参列表)
{
函数体
}
函数的分类
按照有无形参:有参函数,无参函数
按照有无返回值:有返回值,无返回值 void
从用户的角度自定义函数,系统函数
按照作用域的角度:内部函数,外部函数
函数的返回值
主要通过return进行值的返回
return的作用:
返回一个特定的值
结束我们整个函数
通过指针类型的形参
函数调用
格式:函数名(实参列表);
main函数比较特殊,不需要用户主动去调用,而是由系统的引导程序完成主函数的调用
函数传参
值传递:适合传递较小的对象,特点:将实参的值拷贝一份到形参
指针传递:传递大集合或大的对象 特点:只是将其地址形参,在函数中指向空间的修改会影响实参
递归函数
在一个函数,直接或间接的调用自身
住:
调用自身的语句要放在结束语句的后边
要有边界条件,防止无限递归,当边界条件不成立 递归函数进入前进阶段,成立后进入后退阶段
局部变量与全局变量
从作用域的角度:
变量分局部变量和全局变量
如果函数内局部变量和全局变量出现重名,局部会屏蔽全局
生存期
static
可以用来修饰变量和函数
如果修饰局部变量,它没有改变该变量的作用域,但是延长了变量的生存期,只被函数初始化一次
如果修饰全局变量,就意味着该变量只能在当前文件使用
修饰函数:该函数就变成了内部函数,只限在当前文件使用
extern:
可以修饰变量和函数
多用来修饰全局变量,用来声明,用来告诉编译器,不要在当前找该变量,而是该变量定义在其他位置。
a.c:定义全局变量int a;
b.c:需要使用:
extern int a; //先声明后使用
register:主要用来修饰局部变量,告诉系统,尽量把该变量放在CPU内部的寄存器,从而提供对该变量的访问
auto:自动存储类型
结构体
自定义数据类型
结构体声明
// 声明结构体类型(仅定义模板,不占用内存)
struct Stu {
char name[20]; // 成员1:字符数组(学生姓名)
int age; // 成员2:整型(学生年龄)
float score; // 扩展:浮点型(学生成绩)
};-
规则:
struct是关键字,Stu是 "结构体标签(tag)",需与struct配合使用(如struct Stu才是完整类型名); -
注意:声明仅描述结构,未分配内存,成员末尾必须加
;。// 方式1:先声明再typedef
struct Stu {
char name[20];
int age;
};
typedef struct Stu Student; // 给struct Stu起别名Student
// 方式2:声明+typedef合并(推荐)
typedef struct Stu {
char name[20];
int age;
} Student;
// 使用:直接用别名定义变量
Student stu1;
// 匿名结构体:仅能在声明时定义变量,无法复用类型
struct {
char name[20];
int age;
} stu2, stu3; // 仅stu2、stu3可用该结构,后续无法再定义
上述三种形式:基础,typedef,匿名
使用结构体
struct 结构体类型 变量名;
// 方式1:声明类型后,单独定义变量
struct Stu stu1;
// 方式2:声明类型时,直接定义变量
struct Stu {
char name[20];
int age;
} stu2, stu3; // 同时定义stu2、stu3两个变量
// 方式3:typedef简化后定义(最常用)
typedef struct Stu {
char name[20];
int age;
} Student;
Student stu4;-
普通变量:用
.(成员访问运算符),格式:结构体变量名.成员名; -
指针变量:用
->(指向运算符),格式:结构体指针->成员名;// 普通变量访问
struct Stu stu1;
stu1.age = 18; // 给age赋值
strcpy(stu1.name, "Tom"); // 字符数组需用strcpy赋值(不可直接=)
// 指针变量访问
struct Stu *p = &stu1;
p->age = 20; // 等价于 (*p).age = 20
strcpy(p->name, "Jerry");
初始化结构体变量
整体初始化
// 方式1:完全初始化(按成员顺序赋值)
struct Stu stu1 = {"Tom", 18};
// 方式2:不完全初始化(未赋值的成员默认置0)
struct Stu stu2 = {"Jerry"}; // age默认=0
// 方式3:typedef简化类型的初始化
Student stu3 = {"Alice", 19};成员初始化
// 格式:.成员名 = 值,可打乱顺序、仅初始化部分成员
struct Stu stu4 = {
.age = 20, // 先初始化age
.name = "Bob" // 后初始化name(顺序无关)
};
// 仅初始化部分成员,其余默认置0
struct Stu stu5 = {.name = "Lisa"}; // age=0结构体从嵌套
结构体成员可以是另一个结构体(需保证内层结构体已声明),核心是 "逐层访问成员"。
// 步骤1:声明内层结构体(地址)
struct Address {
char province[20]; // 省份
char city[20]; // 城市
};
// 步骤2:声明外层结构体(学生,包含地址)
struct Stu {
char name[20];
int age;
struct Address addr; // 成员为内层结构体类型
};嵌套结构体初始化与访问
// 初始化:内层结构体需用{}包裹
struct Stu stu = {
"Tom",
18,
{"广东省", "深圳市"} // 内层Address的初始化
};
// 访问:逐层用.访问
printf("省份:%s\n", stu.addr.province); // 输出:广东省
printf("城市:%s\n", stu.addr.city); // 输出:深圳市
// 指针访问嵌套成员
struct Stu *p = &stu;
printf("年龄:%d\n", p->age); // 外层成员
printf("城市:%s\n", p->addr.city); // 内层成员(p->addr等价于(*p).addr)结构体数组
结构体数组是 "存储结构体变量的数组",用于批量管理同类型复杂数据(如全班学生信息)。
// 方式1:基础定义
struct Stu class[3]; // 定义长度为3的结构体数组,存储3个学生
// 方式2:typedef简化定义
Student class[3];
// 完全初始化:每个数组元素对应一个结构体{}
Student class[3] = {
{"Tom", 18},
{"Jerry", 17},
{"Alice", 19}
};
// 不完全初始化:未赋值的元素默认置0
Student class[3] = {
{"Tom", 18}, // 第1个元素
{"Jerry"} // 第2个元素(age=0),第3个元素全0
};
// C99指定初始化:指定数组下标+成员
Student class[3] = {
[1] = {.name = "Bob", .age = 20}, // 仅初始化第2个元素
[0] = {.age = 18} // 第1个元素name=0,age=18
};
// 遍历结构体数组,打印所有学生信息
Student class[3] = {{"Tom",18},{"Jerry",17},{"Alice",19}};
int len = sizeof(class) / sizeof(class[0]); // 计算数组长度
for (int i = 0; i < len; i++) {
printf("第%d个学生:姓名=%s,年龄=%d\n", i+1, class[i].name, class[i].age);
}结构体类型的指针
结构体指针是指向结构体变量的指针(存储结构体变量的首地址),核心用途:
-
减少函数传参的内存拷贝(仅传地址,而非整个结构体);
-
遍历结构体数组;
-
动态分配结构体内存(堆区)。
struct Stu stu = {"Tom", 18};
struct Stu *p = &stu; // 定义结构体指针,指向stu// 访问成员(两种等价方式)
printf("姓名:%s\n", p->name); // 推荐:指针专用->
printf("年龄:%d\n", (*p).age); // 等价写法:先解引用再用.
// 函数:修改学生年龄(指针传参,仅传地址)
void updateAge(struct Stu *p, int newAge) {
p->age = newAge; // 直接修改原变量的成员
}// 主函数调用
struct Stu stu = {"Tom", 18};
updateAge(&stu, 20); // 传入stu的地址
printf("修改后年龄:%d\n", stu.age); // 输出:20
// 步骤1:动态分配1个结构体的内存
Student *p = (Student *)malloc(sizeof(Student));
if (p == NULL) { // 判空:避免内存分配失败
printf("内存分配失败\n");
return -1;
}// 步骤2:初始化堆区结构体
p->age = 20;
strcpy(p->name, "Bob");// 步骤3:使用后释放内存(避免内存泄漏)
free(p);
p = NULL; // 置空,避免野指针
结构体的字节对齐
字节对齐的目的
计算机内存按 "字节块" 访问,字节对齐可:
-
提升内存访问效率(避免跨块读取);
-
兼容硬件架构(部分硬件仅支持特定字节数的内存访问)。
字节对齐规则(编译器默认)
C 语言结构体对齐遵循 3 条核心规则(以 32 位编译器为例,默认对齐数为 4):
-
成员对齐:每个成员的偏移量(相对于结构体首地址)必须是 "该成员所占字节数" 的整数倍;
-
整体对齐:结构体总大小必须是 "结构体中最大基本类型成员字节数" 的整数倍;
-
默认对齐数:编译器默认对齐数(如 VS=8、GCC=4),成员对齐取 "成员字节数" 和 "默认对齐数" 的较小值。
// 示例1:未优化的结构体(存在内存空洞)
struct A {
char a; // 1字节,偏移0(符合1的整数倍)
int b; // 4字节,偏移需为4的整数倍 → 偏移0+1=1 → 补3字节空洞,偏移4
char c; // 1字节,偏移8(4+4=8,符合1的整数倍)
};
// 总大小计算:
// 成员占比:1(a) + 3(空洞) + 4(b) + 1(c) = 9字节
// 整体对齐:最大基本类型是int(4) → 9向上取整为12 → 总大小=12字节// 示例2:优化后的结构体(调整成员顺序,减少空洞)
struct B {
char a; // 1字节,偏移0
char c; // 1字节,偏移1
int b; // 4字节,偏移2 → 补2字节空洞,偏移4
};
// 总大小:1+1+2(空洞)+4=8字节(符合最大成员4的整数倍)
可通过编译器指令#pragma pack(n)修改对齐数(n 为 2、4、8 等),#pragma pack()恢复默认。
#pragma pack(1) // 设置对齐数为1(按1字节对齐,无空洞)
struct A {
char a;
int b;
char c;
};
#pragma pack() // 恢复默认对齐
// 对齐数=1时,总大小=1+4+1=6字节(无空洞)
printf("struct A大小:%zu\n", sizeof(struct A)); // 输出:6注意事项
-
结构体嵌套时,内层结构体的偏移量需是 "内层最大成员字节数" 的整数倍;
-
指针成员(如
char *p)的字节数:32 位系统 = 4,64 位系统 = 8,对齐按指针字节数计算; -
开发单片机 / 嵌入式时,可通过
#pragma pack(1)节省内存(牺牲少量访问效率)。
指针
指针变量:存放地址的变量,数据类型 *变量名(int *a=&b)
对指针变量:pt=&a(赋值地址)、printf("%p",pt)(打印地址); 对指向空间:*pt=10(修改值)、printf("%d", *pt)(读取值),指针使用前必须初始化。
指针与函数/数组
指针传参:可实现多值返回(如void add(int *a,int *b,int result){ result=a+ b}); 指针与一维数组:int *pt=arr,pti等价于 * (pt+i),函数接收数组可写成void test(int arr\[\])或void test(int * arr); 指针与二维数组:需用数组指针(int(* pt)3=arr2),访问方式*(*(pt+row)+col)等价于ptrow col。
高级指针类型
-
指针数组:
int *arr[3]={&a,&b,&c},数组元素为指针; -
指针函数:返回类型为指针(
int *test(){}); -
函数指针:指向函数入口地址(
int (*fun)(int,int)=add),可作为形参接收不同函数(实现行为复用)。
关键指针分类
-
常量指针:
const int *pt,指向的数据不可修改; -
指针常量:
int *const pt,指针变量本身不可修改; -
空指针:
int *pt=NULL(等价于(void*)0),用于状态比较、避免非法引用; -
野指针:未初始化或已释放堆内存的指针,需规避;
-
无类型指针:
void *,可接收任意类型指针赋值,使用前需强转(如int *arr=(int*)malloc(100)),不可直接解引用。 -