
(注:文章由 TDengine 连接器团队出品)
前言
TDengine 作为云原生时序数据库,其分布式架构的核心优势之一便是通过原生负载均衡与故障转移(failover)机制,实现集群的高可用、高吞吐与资源高效利用。本文基于 TDengine 官方架构文档(https://docs.taosdata.com/tdinternal/arch/),从架构底层逻辑出发,系统拆解客户端负载均衡的实现原理、failover 的核心流程及落地配置方案。
有两种连接方式可以访问 TDengine:WebSocket 连接和原生连接。我们会给出两种连接方式对负载均衡和 failover 的支持,以及最佳配置实践。限于篇幅,本文以 JDBC 连接器为例进行介绍,其他连接器相关配置请参考 官网连接器。
WebSocket 连接
WebSocket 连接是我们推荐的连接方式,具体可以参考 连接器开发。WebSocket 连接方式有两种比较常见负载均衡的实现方式:连接器配置多 adapter 地址和 Nginx 反向代理方式。
相对于 Nginx 反向代理方式,连接器配置多 adapter 地址方式有如下优点:
- 连接器可以实现底层物理连接的自动切换,而 Nginx 反向代理不能。因为切换底层连接需要重新鉴权认证。
- 连接器可以实现故障节点恢复后的空闲连接迁移,可以支持应用使用连接池场景下的自动负载重平衡。
- 减少了 Nginx 和 keepalived 组件的部署和维护成本。
- 减少了一层转发,降低时延。
连接器配置多 adapter 地址方式
下面我们以 JDBC 连接器为例来介绍如何支持负载均衡和 failover 以及节点故障恢复之后的连接重平衡。
我们可以在 JDBC URL 中配置多个端点地址,如:jdbc:TAOS-WS://adapter1:6041,adapter2:6041,adapter3:6041/power?user=root&password=taosdata&enableAutoReconnect=true
多个端点地址用英文逗号隔开。端点地址既支持 IPv4,也支持 IPv6,具体可以参考 java 连接器
负载均衡
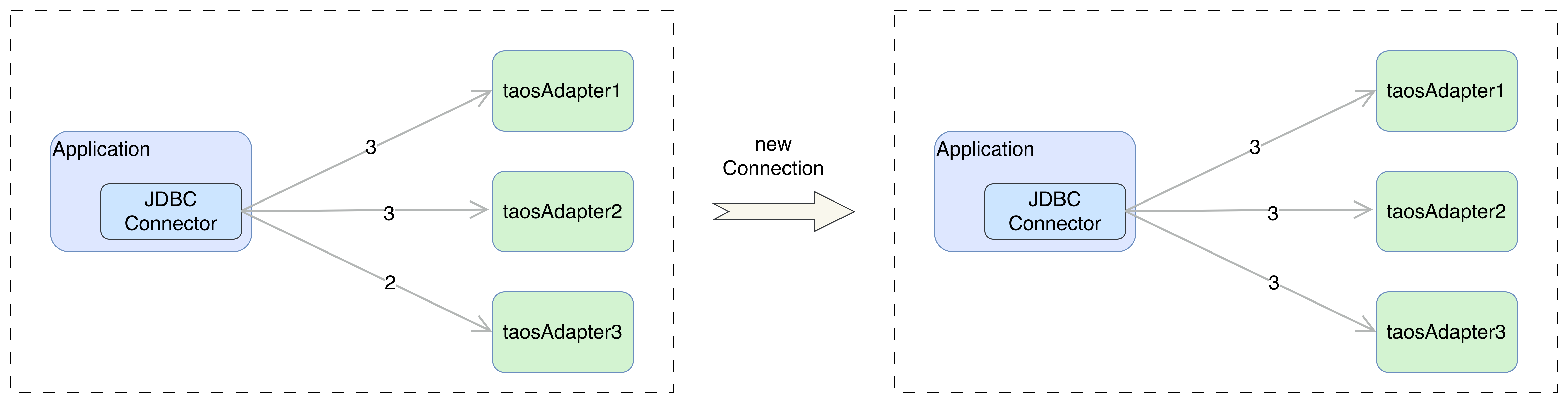
连接器采用最最小连接数算法来保证连接数在各 adapter 实例的均衡。其核心逻辑为:JDBC 建立新连接时,连接器会实时统计集群中各节点(adapter1:6041、adapter2:6041、adapter3:6041)当前的活跃连接数,优先选择连接数最少的节点发起连接;若多个节点连接数相同(如初始均为 0),则按配置顺序选取其一,新连接建立后对应节点连接数加 1;当连接释放时,该节点连接数同步减 1,以此动态均衡各节点的连接负载。
下图说明了新连接建立的时候,会选择连接数最少的 taosAdapter。
failover
当当前连接对应的 adapter 因连接断开无法访问时,JDBC 连接器会自动尝试与 adapter 端点列表中其他可用节点建立连接(同样遵循最小连接数规则)。如果能够连接成功,则会切换底层物理连接到新的端点。此过程对应用透明,因为应用使用的是逻辑连接。
对于下面场景,应用无感知连接的切换:sql 写入,参数绑定写入,无模式写入,sql 查询执行时。
对于下面场景,应用仍需处理异常:查询获取结果集时。
无论如何,应用都需要处理超时异常,因为 JDBC 连接器无法区别超时是否是因为连接断开导致还是命令执行太久导致。
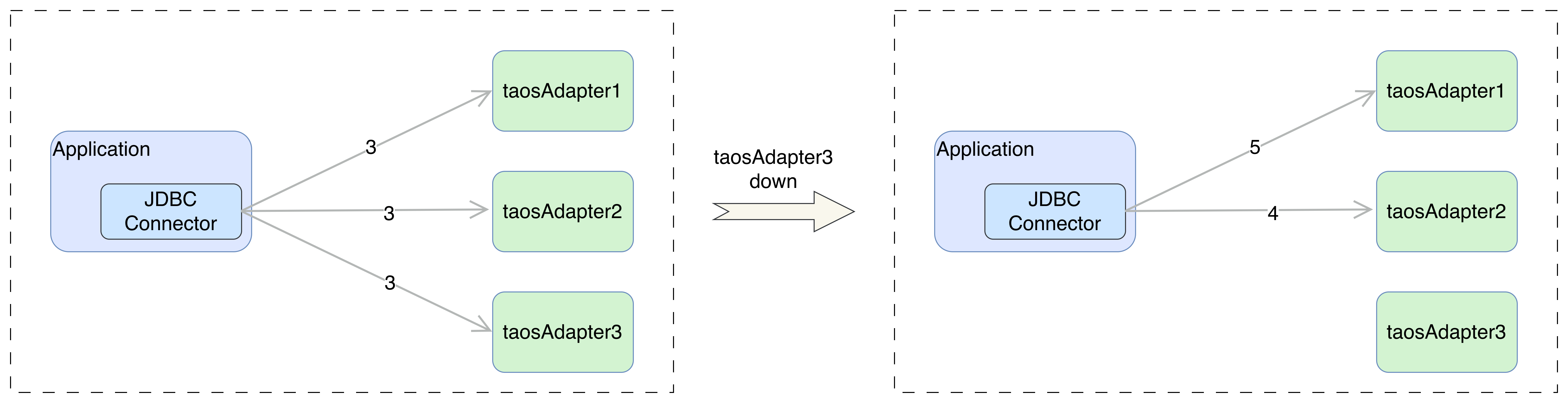
下图说明了当 taosAdapter3 节点故障导致连接断开时,JDBC 连接器自动迁移连接到 taosAdapter1 和 taosAdapter2。对于集群服务端选举或网络抖动造成的短时不可用,会通过 taosAdapter 调用的 taosc 客户端内部重试解决,具体可以参考原生连接 failover 部分。
重平衡
连接重平衡是节点恢复后流量均匀分配的核心,JDBC 连接器考虑了连接池场景适配,确保平滑无感知。
JDBC 连接器采用后台探活线程来探测故障节点的恢复,并迁移空闲连接到恢复节点,等达到相关阈值时迁移停止。具体可以参考 这里
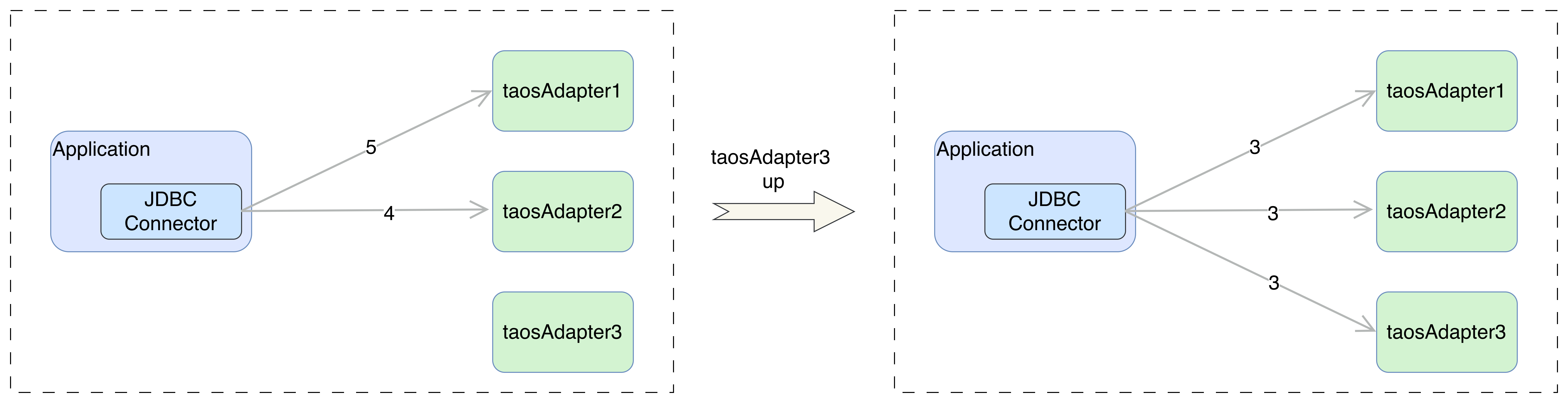
下图说明了当故障节点 taosAdapter3 恢复后,没有新连接建立,但是已有连接进行重平衡后的情况。
Nginx 反向代理方式
Nginx 是一款高性能的反向代理服务器 ,同时也支持邮件代理、负载均衡、缓存等功能,以高并发、低内存消耗、模块化设计著称,广泛用于互联网架构的前端流量入口。
Keepalived 是一款基于 VRRP(虚拟路由冗余协议) 的高可用软件,核心目标是防止单点故障,常与 Nginx、LVS 等服务配合使用。
下面我们给出 Nginx+keepalived 双机主备模式的配置方案,此方案对于大多数企业的应用场景够用,配置也比较简单。正常情况下,主服务器绑定一个虚拟 IP,提供负载均衡服务,热备服务器处于空闲状态;当主服务器发生故障时,热备服务器接管主服务器的虚拟 IP,提供负载均衡服务。
下图是 taosAdapter3 故障后,新连接将只会使用 taosAdapter1 和 taosAdapter2。

下图是主 Nginx 故障后,备 Nginx 机器接管虚拟 IP,此时已有连接会全部断开,新连接会通过备 Nginx 建立。

这是相关 Nginx 和 keepalived 配置。
Markdown
user nobody; ## nginx 运行用户,建议使用nobody,避免权限过大
worker_processes auto;
worker_rlimit_nofile 65535;
error_log /var/log/nginx_error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
use epoll;
worker_connections 4096;
multi_accept on; ## 允许多连接
}
http {
access_log off;
server_tokens off; ## 关闭版本信息
tcp_nodelay on; ## 关闭Nagle算法
keepalive_timeout 180s; ## 应大于2倍 WebSocket ping/pong包的间隔时间(59s)
keepalive_requests 1000; ## 允许的最大请求数,仅用于Restful请求,WebSocket不受此限制
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
proxy_read_timeout 3600s; ## 允许的最大响应时间,DB 默认 900s
proxy_connect_timeout 15s; ## 连接超时
proxy_send_timeout 3600s;
proxy_buffering off; ## 关闭缓存,防止 WebSocket ping/pong 包被缓存
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_next_upstream error http_502 http_500 non_idempotent;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_next_upstream_tries 3;
server {
listen 6041;
location ~* {
proxy_pass http://dbserver;
proxy_read_timeout 3600s;
}
}
server {
listen 6043;
location ~* {
proxy_pass http://keeper;
proxy_read_timeout 60s;
}
}
server {
listen 6060;
location ~* {
proxy_pass http://explorer;
proxy_read_timeout 600s;
}
}
upstream dbserver {
least_conn;
keepalive 32; ## 用于Restful,对WebSocket无效
server 192.168.1.101:6041 max_fails=1 fail_timeout=60s;
server 192.168.1.102:6041 max_fails=1 fail_timeout=60s;
server 192.168.1.103:6041 max_fails=1 fail_timeout=60s;
}
upstream keeper {
least_conn;
server 192.168.1.101:6043 max_fails=1 fail_timeout=60s;
server 192.168.1.102:6043 max_fails=1 fail_timeout=60s;
server 192.168.1.103:6043 max_fails=1 fail_timeout=60s;
}
upstream explorer{
least_conn;
server 192.168.1.101:6060 max_fails=1 fail_timeout=60s;
server 192.168.1.102:6060 max_fails=1 fail_timeout=60s;
server 192.168.1.103:6060 max_fails=1 fail_timeout=60s;
}
}
Plain
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.1.129
smtp_connect_timeout 30
router_id nginxmaster # 主nginx服务器名
}
vrrp_script chk_http_port {
script "/usr/local/src/nginx_check.sh"
interval 3 # 检测脚本执l行的间隔
weight 2
}
vrrp_instance VI_1 {
state MASTER # 备份服务器上将 MASTER 改为 BACKUP
interface ens33 # 网卡
virtual_router_id 51 # 主、备机的 virtual_router_id 必须相同
priority 100 # 主、备机取不同的优先级,主机值较大,备份机值较小
advert_int 1 # 主备机心跳检测间隔
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.200 # VRRP 虚拟地址
}
track_script {
chk_http_port
}
}
Plain
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.1.129
smtp_connect_timeout 30
router_id nginxbackup # 备nginx服务器名
}
vrrp_script chk_http_port {
script "/usr/local/src/nginx_check.sh"
interval 3
weight 2
}
vrrp_instance VI_1 {
state BACKUP # 备份服务器上将 MASTER 改为 BACKUP
interface ens33
virtual_router_id 51 # 主、备机的 virtual_router_id 必须相同
priority 90 # 备份机值较小
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.200
}
track_script {
chk_http_port
}
}
Bash
#!/bin/bash
A=`ps -C nginx --no-heading |wc -l`
if [ $A -eq 0 ];then
sudo /usr/local/nginx/sbin/nginx
sleep 2
if [ `ps -C nginx --no-heading |wc -l` -eq 0 ];then
pkill keepalived
fi
fi原生连接
taosc 是 TDengine TSDB 客户端驱动,所有原生连接都会依赖这个客户端库。详细配置请参考 配置介绍。
高可用连接方式
原生连接方式建议使用客户端配置文件 taos.cfg 去连接 TDengine 集群。此时 taosc 会自动连接我们配置好的 firstEP 节点,如果连接 firstEP 失败,则会继续尝试连接 secondEP。只要这两个节点有一个连接成功,客户端的使用就已经没有问题了。因为 firstEP 和 secondEP 只在连接的瞬间会被使用,它提供的并不是完整服务列表,只是连接目标。只要在这短暂的零点几秒内集群连接成功,taosc 就会自动获取管理节点的地址信息。而只在连接的这一瞬间,两个节点同时宕机的可能性是极低的。后续,即使 firstEP 和 secondEP 两个节点全都宕机,只要集群可以对外服务的基本规则没有被打破,就仍然可以正常使用。
负载均衡
下面简单介绍一下原理,详情请参考 TDengine 构架。
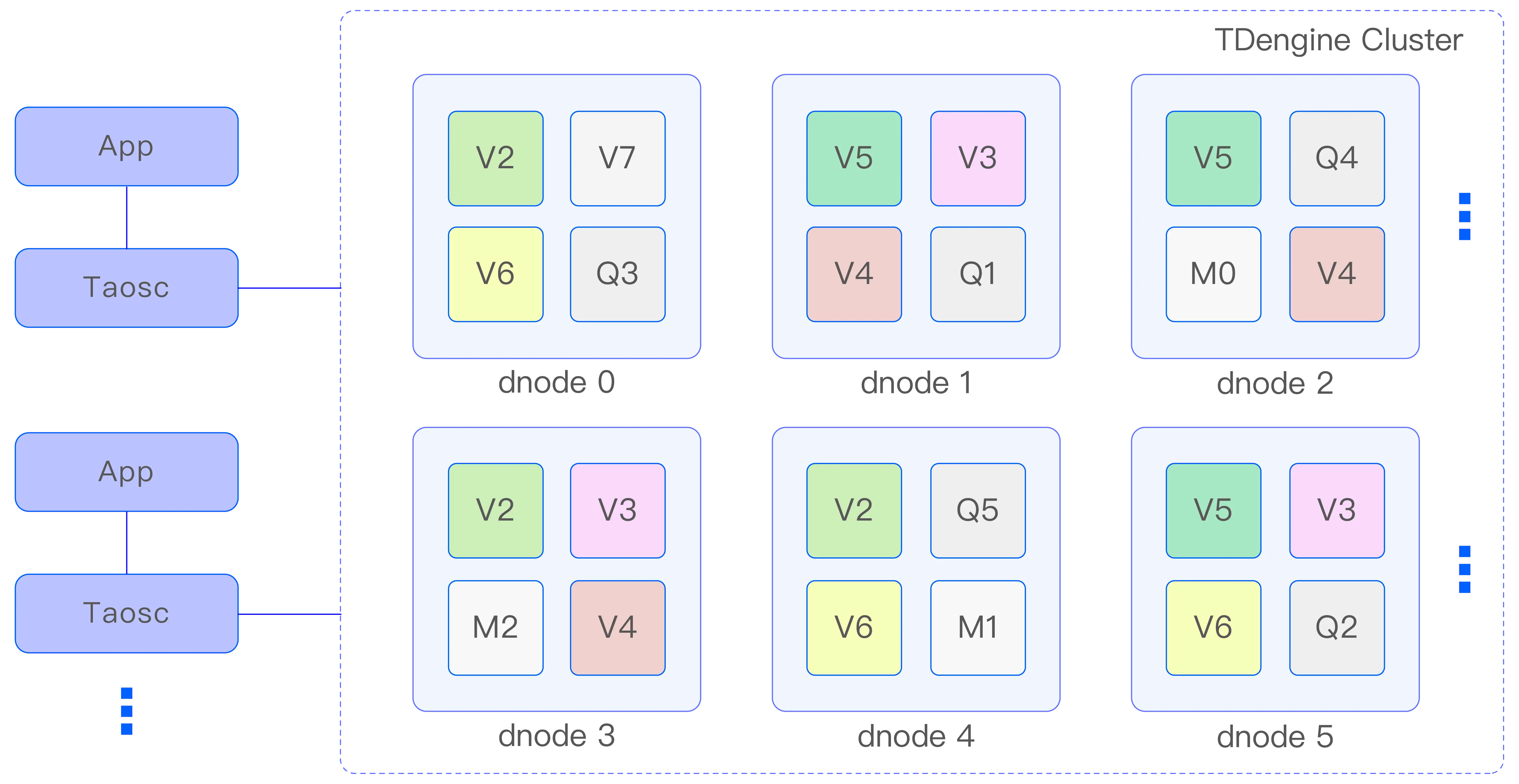
由上图 TDengine 架构图,我们知道:
- TDengine TSDB 集群包含多个 dnode 和 mnode,dnode 存储数据,mnode 存储元数据。
- 一个 dnode 上可以创建多个 vnode(图中 V2,V3 等),每个 vnode 属于一个数据库。
- 一个采集点的数据属于一张子表,一个 vnode 负责管理多张子表。
- TDengine TSDB 采用 vGroup 来管理副本(如图中相同的 V2 属于同一个 vGroup),一个 vGroup 有多个来自不同 dnode 的 vnode 组成。其中一个是 leader,其他是 follower,采用 raft 算保证一致性。每个 vgroup 是单独选举的,因此 vGroup leader 也会分布在所有 dnode 上。
- taosc 会与 TDengine TSDB 集群所有节点进行通信,taosc 会缓存集群信息并保持更新。不管写入还是查询,taosc 会与当前 DB 的 vGroup 中的 vnode leader 进行通信。taosc 即使通信的节点不是 leader,也会通过重定向的方式找到 leader 进行通信。
这样由于数据是分片的,应用访问不同数据库的不同子表,自然会负载均衡。
failover
原生连接的 failover 主要依赖 taosc 实现。taosc 会对非用户使用原因导致的失败请求进行重试。下图说明了 taosd3 不可访问的时候,其请求的数据副本重新选举后 leader 在 taosd2 上,那么 taosc 会向 taosd2 重试请求。

显然 taosc 实现 failover 也离不开 taosd 的高可用,因为如果 taosd 没有做好分片和副本,存在单点故障,那么 taosc 的重试就无法解决问题。
总结
TDengine 的客户端负载均衡与故障转移可通过 WebSocket 和原生两种连接方式落地:WebSocket 优先推荐连接器配置多 adapter 地址方案,兼顾低时延与无感知重平衡;原生连接依赖 taos.cfg 配置双 EP 保障初始连接,依托 vGroup 与 Raft 机制实现数据层面负载均衡与重试容错。我们推荐客户采用 WebSocket 连接方式,配置多 adapter 地址方案。
关于 TDengine
TDengine 专为物联网IoT平台、工业大数据平台设计。其中,TDengine TSDB 是一款高性能、分布式的时序数据库(Time Series Database),同时它还带有内建的缓存、流式计算、数据订阅等系统功能;TDengine IDMP 是一款AI原生工业数据管理平台,它通过树状层次结构建立数据目录,对数据进行标准化、情景化,并通过 AI 提供实时分析、可视化、事件管理与报警等功能。