一、模型构建
GPT-2模型的核心架构基于Transformer解码器,采用自回归方式生成文本。
模型构建部分定义了GPTConfig配置类,包含关键参数如block_size(序列长度)、vocab_size(词表大小)、n_layer(层数)、n_head(注意力头数)和n_embd(嵌入维度)。
CausalSelfAttention类实现了带掩码的多头自注意力机制,通过线性变换生成QKV矩阵,并使用PyTorch内置的scaled_dot_product_attention函数(Flash Attention)优化计算效率,替代了传统的手动实现softmax和掩码操作。
MLP类包含两层线性变换和GELU激活函数,Block类将LayerNorm、注意力和MLP组合成完整的Transformer块。
GPT类整合了词嵌入、位置编码、多层Transformer块和输出层,通过_init_weights方法实现参数初始化,其中线性层的初始化标准差会根据是否标记GPT_SCALE_INIT进行调整,这是为了缓解深度网络的梯度问题。
模型还支持从HuggingFace加载预训练权重,通过严格的参数形状检查和转置操作确保兼容性。
python
import math
import inspect
import torch
import torch.nn as nn
from torch.nn import functional as F
from dataclasses import dataclass
from set_ddp import *
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50257
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super(CausalSelfAttention, self).__init__()
# 确保嵌入维度可以被注意力头整除
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.c_proj.GPT_SCALE_INIT = 1
self.n_head = config.n_head
self.n_embd = config.n_embd
# 做一个mask
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
# bs, seq_len, embd
B, T, C = x.size()
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
#*-=======================flash attention============================-*
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)
# att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# att = att.masked_fill(self.bias[:, :, :T, :T] == 0 , float("-inf"))
# att = F.softmax(att, dim=-1)
# y = att @ v # (B, nh, T, T) X (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.c_proj(y)
return y
class MLP(nn.Module):
def __init__(self, config):
super(MLP, self).__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate="tanh")
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
self.c_proj.GPT_SCALE_INIT = 1
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x
class Block(nn.Module):
def __init__(self, config):
super(Block, self).__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class GPT(nn.Module):
def __init__(self, config):
super(GPT, self).__init__()
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd),
))
# softmax前的linear层
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# 权重共享方案,实现了词嵌入层 (wte) 和语言模型头 (lm_head) 之间的权重共享
self.transformer.wte.weight = self.lm_head.weight
# 初始化参数
self.apply(self._init_weights)
def _init_weights_old(self, module):
if isinstance(module, nn.Linear):
std = 0.02
torch.nn.init.normal_(module.weight, mean=0.0, std=std)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
std = 0.02
# 缩放初始化,目的是缓解深度网络中的梯度消失或爆炸问题,并提高训练的稳定性。
# 如果具有该属性,则使用 std *= (2 * self.config.n_layer) ** -0.5 对标准差进行缩放。
if hasattr(module, 'GPT_SCALE_INIT'):
# 2 是因为在每个 Transformer 块中,有两处残差连接(一个在注意力层之前,一个在 MLP 层之前)。
std *= (2 * self.config.n_layer) ** -0.5
torch.nn.init.normal_(module.weight, mean=0.0, std=std)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
"""
GPT 模型的前向传播函数。
Args:
idx: 输入 token 索引张量,形状为 (B, T),其中 B 是批次大小,T 是序列长度。
targets: 目标 token 索引张量,形状为 (B, T),用于计算损失。如果为 None,则不计算损失。
Returns:
一个包含 logits 和 loss 的元组。
logits: 模型输出的 logits,形状为 (B, T, vocab_size),其中 vocab_size 是词汇表大小。
loss: 计算得到的交叉熵损失。如果 targets 为 None,则 loss 为 None。
"""
B, T = idx.size() # batch_size, seq_len
assert T <= self.config.block_size, f"不能让seq_len {T} 大于 block_size {self.config.block_size}"
pos = torch.arange(0, T, dtype=torch.long, device=idx.device) # 创建位置索引张量
pos_emb = self.transformer.wpe(pos) # (T, n_embd) # 获取位置嵌入
tok_emb = self.transformer.wte(idx) # (B, T, n_embd) # 获取 token 嵌入
x = pos_emb + tok_emb # 将位置嵌入和 token 嵌入相加
for block in self.transformer.h: # 通过 Transformer 的所有 Block 层
x = block(x)
x = self.transformer.ln_f(x) # 应用 Layer Normalization
logits = self.lm_head(x) # (B, T, vocab_size) # 通过线性层得到 logits
loss = None # 初始化损失为 None
if targets is not None: # 如果提供了目标值,则计算损失
# 计算交叉熵损失
# logits.view(-1, logits.size(-1)) 将 logits 重塑为 (B*T, vocab_size)
# targets.view(-1) 将 targets 重塑为 (B*T)
# 这样做是为了符合 F.cross_entropy 的输入要求
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
# 等价于下面的代码,更容易理解
# B, T, C = logits.shape
# loss = F.cross_entropy(logits.view(B*T, C), targets.view(B*T))
return logits, loss
@classmethod
def from_pretrained(cls, model_type):
assert model_type in {"gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl"}
from transformers import GPT2LMHeadModel
print("从预训练的GPT中加载模型:", model_type)
# 根据模型类型确认参数
config_args = {
"gpt2": dict(n_layer=12, n_head=12, n_embd=768), # 124M param
"gpt2-medium": dict(n_layer=24, n_head=16, n_embd=1024), # 350M param
"gpt2-large": dict(n_layer=36, n_head=20, n_embd=1280), # 774M param
"gpt2-xl": dict(n_layer=48, n_head=25, n_embd=1600), # 1558M param
}[model_type]
config_args["vocab_size"] = 50257
config_args["block_size"] = 1024
# 创建GPT模型
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith(".attn.bias")]
# 从huggingface/transformers模型中初始化
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# 将参数逐一对齐并复制
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.masked_bias")]
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.bias")]
transposed = ["attn.c_attn.weight", "attn.c_proj.weight", "mlp.c_fc.weight", "mlp.c_proj.weight"]
assert len(sd_keys_hf) == len(sd_keys), f"键不匹配, {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
# openai使用了一个叫conv1d的模型,功能与linear一致,我们使用linear,需要单独处理它。需要转置
if any(k.endswith(w) for w in transposed):
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else: # 其余的直接复制
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model
#*-=======================参数正则化-1===========================-*
def configure_optimizers(self, weight_decay, learning_rate, device_type):
# self.named_parameters() 返回模型中所有参数的名称和参数 tensor 的迭代器。
# 第一个 param_dict 存储了所有参数。
# 第二个 param_dict 过滤掉了 requires_grad=False 的参数,即不需要计算梯度的参数。
param_dict = {pn: p for pn, p in self.named_parameters()}
param_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}
# 根据参数的维度进行分组。
# dim() >= 2 的参数通常是权重矩阵(例如全连接层、卷积层、embedding 层),需要进行权重衰减。
# dim() < 2 的参数通常是偏置 (bias) 和 LayerNorm 的参数,不需要进行权重衰减。
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
# 创建优化器参数组。
# 每个组是一个字典,包含 'params' 和 'weight_decay' 两个键。
# 第一个组包含需要进行权重衰减的参数,其 weight_decay 设置为传入的 weight_decay 值。
# 第二个组包含不需要进行权重衰减的参数,其 weight_decay 设置为 0.0。
optim_groups = [
{'params': decay_params, 'weight_decay': weight_decay},
{'params': nodecay_params, 'weight_decay': 0.0}
]
# 打印需要进行权重衰减和不需要进行权重衰减的参数数量,用于调试和信息展示。numel() 返回 tensor 中元素的总个数。
num_decay_params = sum(p.numel() for p in decay_params)
num_nodecay_params = sum(p.numel() for p in nodecay_params)
if master_process:
print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")
print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")
# 检查 AdamW 是否支持 fused 版本(fused 版本通常在 CUDA 设备上速度更快)。
# fused 是将多个操作合并成一个优化的 CUDA kernel
# inspect.signature() 用于获取函数的签名,parameters 属性返回函数的参数。
fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
use_fused = fused_available and device_type == "cuda"
if master_process:
print(f"using fused AdamW: {use_fused}")
# 创建 AdamW 优化器。
# optim_groups:参数组,用于分别设置不同参数组的 weight_decay。
# lr:学习率。
# betas:Adam 优化器的 beta 值。
# eps:用于数值稳定性的 epsilon 值。
# fused:是否使用 fused 版本。
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=(0.9, 0.95), eps=1e-8, fused=use_fused)
return optimizer二、数据加载
DataLoaderLite类负责文本数据的预处理和批量生成。
初始化时使用BERT分词器处理文本文件,将长文本分块编码为token序列。
在分布式训练环境下,每个进程根据rank和world_size获取不同的数据分片,避免重复处理。
next_batch方法生成输入-目标对,通过视图操作将一维token序列转换为形状为(B, T)的批次数据,并实现环形缓冲区逻辑确保数据遍历完成后自动从头开始。
关键设计包括:进程感知的数据分片策略、高效的token到batch转换、以及自动重置的数据迭代机制,这些共同支撑了分布式训练的高效数据供给。
python
import tiktoken
from transformers import AutoTokenizer, BertTokenizer
from set_ddp import *
class DataLoaderLite:
"""
这个类用于从文本文件中加载数据并生成批次 (batch)。它主要用于语言模型的训练。
参数:
B (int): 批次大小 (batch size)
T (int): 序列长度 (sequence length)
"""
def __init__(self, B, T, process_rank, num_processes):
"""
初始化数据加载器
该函数读取文本文件,将文本转换为 token 序列,并存储相关信息。
参数:
B (int): 批次大小 (batch size)
T (int): 序列长度 (sequence length)
"""
self.B = B
self.T = T
self.process_rank = process_rank
self.num_processes = num_processes
max_len = 1024
tokens = []
# tokenizer = AutoTokenizer.from_pretrained("model/Qwen/Qwen2___5-0___5B-Instruct")
tokenizer = BertTokenizer.from_pretrained('model/tiansz/bert-base-chinese')
with open("doup.txt", "r") as f:
text = f.read()
for i in range(0, len(text), max_len):
chunk = text[i: i+max_len]
tokenized_chunk = tokenizer([chunk])["input_ids"][0]
tokens.extend(tokenized_chunk)
self.tokens = torch.tensor(tokens)
# 打印加载信息
if master_process:
print(f"loaded {len(self.tokens)} tokens")
print(f"1 epoch = {len(self.tokens)//(B * T)} batches")
# 初始化当前读取位置
self.current_position = self.B * self.T * self.process_rank
def next_batch(self):
"""
获取下一个批次数据
该函数从 token 序列中获取一个批次的数据,并返回输入 (x) 和目标 (y) 序列。
返回值:
tuple: 包含两个元素的元组,分别为输入序列 (x) 和目标序列 (y)
"""
B, T = self.B, self.T
# 创建一个包含 B * T + 1 个 token 的缓冲区 (buffer)
# +1 是为了获取下一个 token 作为目标序列的第一个 token
buf = self.tokens[self.current_position: self.current_position + B * T + 1]
x = (buf[:-1]).view(B, T) # 获取输入序列 (x), 剔除最后一个 token,并转换为 (B, T) 形状
y = (buf[1:]).view(B, T) # 获取目标序列 (y),取出剩下的 token,并转换为 (B, T) 形状
# 更新当前读取位置
self.current_position += B * T * self.num_processes
# 处理数据溢出问题
# 如果下一个批次超出文本范围,则将 current_position 归零,重新从头开始读取
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
self.current_position = self.B * self.T * self.process_rank
return x, y三、学习率调度器
学习率调度器采用线性预热与余弦退火组合策略。get_lr函数根据当前训练步数动态调整学习率:前warmup_steps步线性增加学习率至max_lr,随后在max_steps步内按余弦曲线衰减到min_lr(max_lr的10%)。
这种策略既能避免训练初期的大梯度扰动,又能平滑地收敛到最优解。数学实现上,余弦阶段通过decay_ratio计算衰减系数,使用cosine函数实现非线性变化,相比线性衰减能更好地保留模型后期微调能力。调度器与优化器配合,通过直接修改param_group'lr'实现实时更新。
python
import math
#*-=======================学习率调度器-1===========================-*
# 实现一个学习率调度器(learning rate scheduler),它根据训练的迭代次数(iteration)动态调整学习率。
# 结合了线性预热(linear warmup)和余弦衰减(cosine decay)两种策略。
max_lr = 6e-4 # 最大学习率
min_lr = max_lr * 0.1 # 最小学习率,是最大学习率的 10%
warmup_steps = 10 # 线性预热的迭代次数
max_steps = 50 # 总的训练迭代次数(或衰减到最小学习率的迭代次数)
def get_lr(it):
"""
根据迭代次数 it 返回当前的学习率。
Args:
it: 当前的迭代次数。
Returns:
当前的学习率。
"""
# 1) 线性预热阶段 (Linear Warmup)
if it < warmup_steps:
# 在 warmup_steps 步内,学习率从 0 线性增加到 max_lr
# it 从 0 开始,所以 (it + 1) 从 1 开始,到 warmup_steps。
# 因此,学习率从 max_lr / warmup_steps 线性增加到 max_lr。
return max_lr * (it + 1) / warmup_steps
# 2) 达到最大迭代次数后,保持最小学习率 (Minimum Learning Rate after Max Steps)
if it > max_steps:
# 超过 max_steps 后,学习率保持在 min_lr
return min_lr
# 3) 余弦衰减阶段 (Cosine Decay)
# 计算衰减比例。
# it 从 warmup_steps + 1 开始,到 max_steps。
# decay_ratio 从 (warmup_steps + 1 - warmup_steps) / (max_steps - warmup_steps) = 1/(max_steps - warmup_steps) 线性增加到 (max_steps - warmup_steps) / (max_steps - warmup_steps) = 1。
decay_ratio = (it - warmup_steps) / (max_steps - warmup_steps)
assert 0 <= decay_ratio <= 1 # 确保衰减比例在 0 到 1 之间,这是一个良好的编程习惯,用于检查代码的正确性
# 计算余弦衰减系数。
# 当 decay_ratio = 0 时,coeff = 0.5 * (1 + cos(0)) = 1。
# 当 decay_ratio = 1 时,coeff = 0.5 * (1 + cos(pi)) = 0。
# 因此,coeff 从 1 线性减小到 0。
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))
# 计算当前学习率。
# 当 coeff = 1 时,学习率为 min_lr + (max_lr - min_lr) = max_lr。
# 当 coeff = 0 时,学习率为 min_lr + 0 = min_lr。
# 因此,学习率从 max_lr 按照余弦曲线衰减到 min_lr。
return min_lr + coeff * (max_lr - min_lr)四、DDP
DDP模块构建完整的分布式训练环境。通过检测RANK环境变量判断是否启用分布式模式,使用NCCL后端初始化进程组。
关键设计包括:按LOCAL_RANK绑定GPU设备、区分master进程处理日志和检查点、封装模型为DDP实现自动梯度同步。
代码中特别处理了梯度累积场景,通过require_backward_grad_sync控制在最后微步才触发梯度同步,减少通信开销。
损失值使用all_reduce进行进程间平均,确保监控指标的一致性。设备类型(device_type)的显式记录为后续混合精度等设备相关优化提供依据。
python
# 设置分布式数据并行 (DDP) 环境,如果不是 DDP 运行,则选择可用的设备(CPU、CUDA 或 MPS)。
# simple launch:
# python 15DDP.py
# DDP launch for e.g. 2 GPUs:
# torchrun --standalone --nproc_per_node=2 15DDP.py
import os
import torch
from torch.distributed import init_process_group, destroy_process_group
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 设置 DDP (分布式数据并行)。
# torchrun 命令会设置环境变量 RANK、LOCAL_RANK 和 WORLD_SIZE
ddp = int(os.environ.get('RANK', -1)) != -1 # 判断是否是 DDP 运行。如果设置了 RANK 环境变量,则认为是 DDP 运行。
if ddp:
# # 如果是 DDP 运行,目前需要 CUDA,根据 rank 设置设备
assert torch.cuda.is_available(), "DDP 的运行需要 CUDA"
init_process_group(backend='nccl') # 初始化进程组,使用 nccl 后端(适用于 NVIDIA GPU)
ddp_rank = int(os.environ['RANK']) # 当前进程的全局 rank(在所有进程中的排名)
ddp_local_rank = int(os.environ['LOCAL_RANK']) # 当前进程在当前节点上的本地 rank
ddp_world_size = int(os.environ['WORLD_SIZE']) # 总共有多少个进程
device = f'cuda:{ddp_local_rank}' # 根据本地 rank 设置设备,例如 cuda:0, cuda:1
torch.cuda.set_device(device) # 设置当前进程使用的 GPU 设备
master_process = ddp_rank == 0 # # 判断当前进程是否是 master 进程(rank 为 0 的进程),master 进程负责日志记录、保存检查点等
else:
# 非 DDP 运行(单卡或 CPU 运行)
ddp_rank = 0 # 设置 rank 为 0
ddp_local_rank = 0 # 设置本地rank为0
ddp_world_size = 1 # 设置世界大小为1
master_process = True # 单进程,所以是 master 进程
# 尝试自动检测设备
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
if master_process:
print(f"using device: {device}")
# 设备是CUDA:1等具体执行的设备,添加device_type 标识用来区分运行设备是CPU还是CUDA等
device_type = "cuda" if device.startswith("cuda") else "cpu"五、模型训练
训练脚本整合了前述所有组件,并添加多项优化:
-
通过grad_accum_steps实现大batch训练,计算总tokens数时考虑并行进程数;
-
使用torch.compile编译模型加速计算;
-
混合精度训练通过autocast上下文管理自动转换精度;
-
梯度裁剪限制最大范数为1.0稳定训练;
-
主进程负责记录日志和保存检查点,检查点包含模型参数、配置、步数和验证损失。
关键性能指标tokens_per_sec的计算综合了batch大小、序列长度、累积步数和并行进程数,真实反映系统吞吐量。
python
import time
import torch
import torch.nn.functional as F
from chatgpt2_model import GPT,GPTConfig
from data_loader import DataLoaderLite
from lr_scheduler import get_lr
from set_ddp import *
#*-=======================日志=============================-*
# 创建写入检查点和日志的目录
log_dir = "log"
os.makedirs(log_dir, exist_ok=True)
log_file = os.path.join(log_dir, f"log.txt")
with open(log_file, "w") as f:
pass
#*-=======================设置随机数种子===========================-*
torch.manual_seed(1337)
if torch.cuda.is_available():
torch.cuda.manual_seed(1337)
#*-=======================检测cuda===========================-*
device='cuda' if torch.cuda.is_available() else 'cpu'
#*-=======================加载模型===========================-*
# model = GPT(GPTConfig())
#*-=======================修改vocab_size===========================-*
# 使用2的幂次方的数 50257--->50304 词表大小是50257 50304=128*393
model = GPT(GPTConfig(vocab_size=50304))
print("模型加载成功")
model.to(device)
#*-=======================torch_compile加速===========================-*
model=torch.compile(model)
#*-=======================DDP-1===========================-*
if ddp:
model = DDP(model, device_ids=[ddp_local_rank])
# 当使用 torch.nn.parallel.DistributedDataParallel (DDP) 封装模型时,DDP 会在原始模型 (model) 的外面包装一层,创建一个新的模型对象。
# 这个新的模型对象负责在多个进程之间同步梯度、管理数据分发等。
# 原始模型会被存储在新模型的 module 属性中。因此,如果你想访问原始模型的属性或方法,你需要通过 model.module 来访问。
raw_model = model.module if ddp else model # always contains the "raw" unwrapped model
#*-=======================梯度累计-1===========================-*
total_batch_size= 524288 # 期望的总批量大小,以 token 数量计。这里是 524288,约为 0.5M。GPT-3论文中的数据
B = 8 # 小 batch size,每个 GPU 或设备的本地批量大小。这里是 8
T = 1024 # sequence length
#ddp_world_size在有ddp时需要添加
assert total_batch_size % (B * T*ddp_world_size)== 0, "确保 total batch_size 可以被 B * T 整除。"
grad_accum_steps = total_batch_size // (B *T) # 梯度累积的步数,计算 total_batch_size 除以 (B * T) 的整数部分。
if master_process:
print(f"total batch size: {total_batch_size}")
# 表示需要累积多少个小批次的梯度才能达到期望的总批量大小。
# 524288 // (8 * 1024) = 64,即需要累积 64 个小批次的梯度才能达到 0.5M 的总批量大小。
# 现在一个step是72毫秒,如果我们累积64个step,那么一个step就是64*72=4608毫秒,约等于5秒
print(f"=> 梯度累计批次的数量: {grad_accum_steps}")
#*-=======================数据集加载===========================-*
# train_loader = DataLoaderLite(B=8, T=1024)
#*-=======================DDP-3===========================-*
train_loader = DataLoaderLite(B=B, T=T, process_rank=ddp_rank, num_processes=ddp_world_size)
#*-=======================tensor_core加速===========================-*
# 设置张量核心算法的精度级别为TF32
torch.set_float32_matmul_precision("high")
#*-=======================优化器===========================-*
# optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
#*-=======================权重衰减-2===========================-*
# optimizer = model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device=device)
#*-=======================DDP-2===========================-*
optimizer = raw_model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device_type=device)
max_steps=1000
#*-=======================模型训练============================-*
for step in range(max_steps):
t0 = time.time()
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
last_step = (step == max_steps - 1)
optimizer.zero_grad()
#*-=======================梯度累计-2===========================-*
loss_accum = 0.0
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
#*-=======================混合精度============================-*
with torch.autocast(device_type=device, dtype=torch.bfloat16):
logits, loss = model(x, y)
# 如果不将 loss 除以 grad_accum_steps,那么累积的梯度将会是实际梯度的 grad_accum_steps 倍。
loss = loss / grad_accum_steps
loss_accum += loss.detach()
#*-=======================DDP-4===========================-*
if ddp:
model.require_backward_grad_sync =(micro_step == grad_accum_steps -1)
loss.backward()
#*-=======================DDP-5===========================-*
if ddp:
dist.all_reduce(loss_accum, op=dist.ReduceOp.AVG)
#*-=======================梯度裁剪===========================-*
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
#*-=======================学习率调度器-2===========================-*
# 确定并设置此迭代的学习率
lr = get_lr(step)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
optimizer.step()
# 强制 CPU 等待 GPU 完成所有已提交的任务。它会阻塞 CPU 的执行,直到 GPU 完成所有排队的操作。
torch.cuda.synchronize()
t1 = time.time()
dt = (t1 - t0) * 1000
# tokens_per_sec = (train_loader.B * train_loader.T) / (t1 - t0) # 计算每秒训练的token数量
#*-=======================DDP-6===========================-*
tokens_processed = train_loader.B * train_loader.T * grad_accum_steps * ddp_world_size
tokens_per_sec = tokens_processed / dt # 计算每秒训练的token数量
# print(f"step {step},loss:{loss.item()}, dt:{dt:.2f}ms, tokens/s:{tokens_per_sec:.2f}")
#*-=======================DDP-7===========================-*
if master_process:
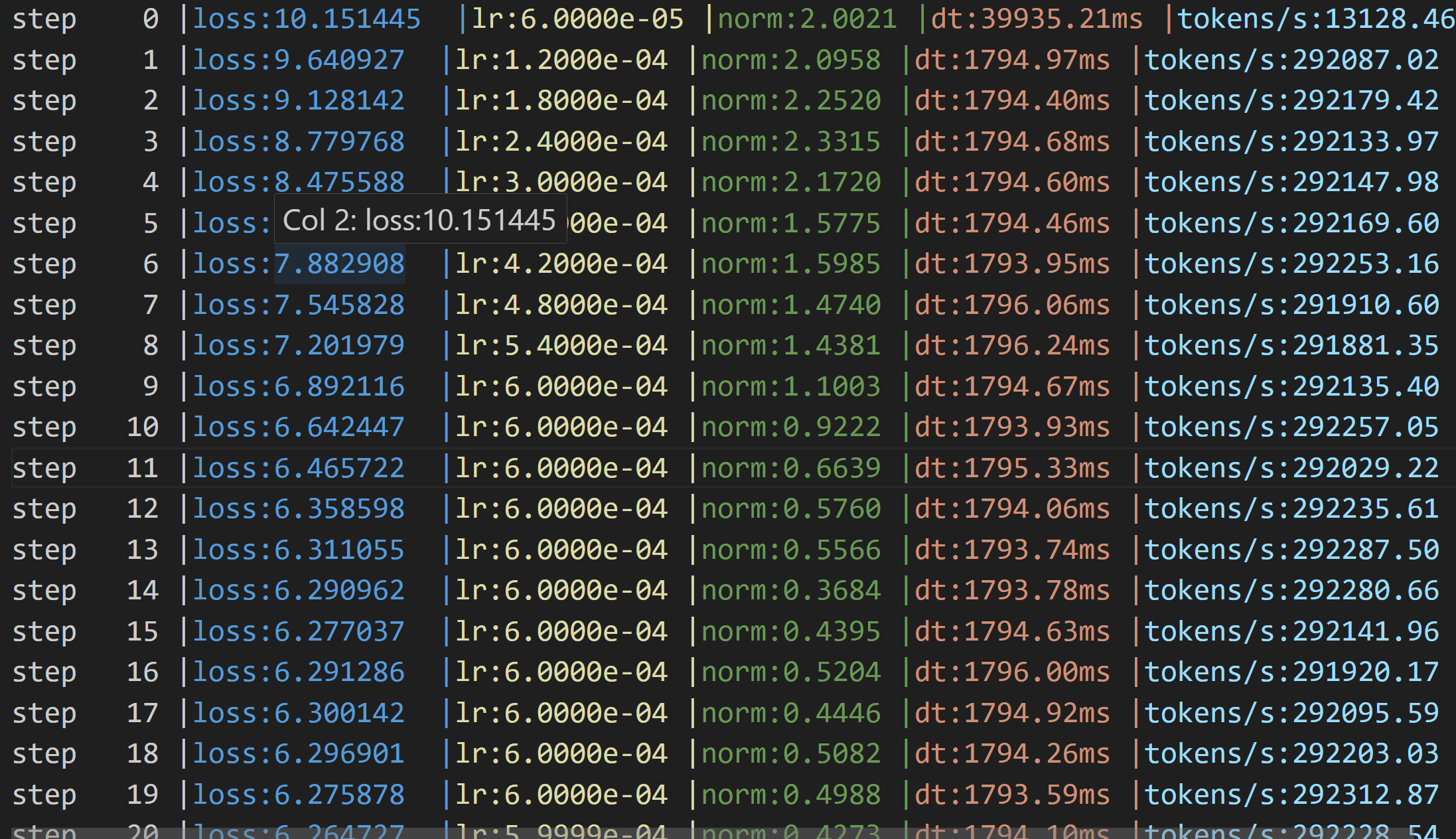
print(f"step{step:4d} | loss: {loss_accum.item():.6f} | lr: {lr:.4e} | norm: {norm:.4f}| dt:{dt*1000:.2f}ms | tokens/s:{tokens_per_sec:.2f}")
with open(log_file, "a") as f:
f.write(f"step{step:4d} | loss: {loss_accum.item():.6f} | lr: {lr:.4e} | norm: {norm:.4f}| dt:{dt*1000:.2f}ms | tokens/s:{tokens_per_sec:.2f}\n")
if step > 0 and (step % 50 == 0 or last_step):
# optionally write model checkpoints
checkpoint_path = os.path.join(log_dir, f"model_{step:05d}.pt")
checkpoint = {
'model': raw_model.state_dict(),
'config': raw_model.config,
'step': step,
'val_loss': loss_accum.item()
}
# 保存模型
torch.save(checkpoint, checkpoint_path)
if ddp:
destroy_process_group()
# torchrun --standalone --nproc_per_node=2 15DDP.py
# watch -n 0,1 nvidia-smi六、模型预测
预测流程加载训练好的模型检查点,处理可能的参数名前缀问题(如_orig_mod.)。
使用BERT分词器将输入文本编码为token,通过自回归方式生成序列:每次取最后位置的logits,采样top-50候选token,使用多项式采样保证多样性,直到达到max_length限制。
解码时跳过特殊token保证输出可读性。该实现展示了GPT-2的核心推理机制,包括温度采样(通过softmax)和序列扩展技术。
python
import torch
from chatgpt2_model import GPT,GPTConfig
import torch.nn.functional as F
# 尝试自动检测设备
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
print(f"using device: {device}")
torch.manual_seed(1337)
if torch.cuda.is_available():
torch.cuda.manual_seed(1337)
model = GPT(GPTConfig(vocab_size=21504))
model.to(device)
checkpoint = torch.load("/home/GPT2_train/log/model_00850.pt", map_location=device)
# 2. 处理 'module.' 或 '_orig_mod.' 前缀
# 去掉 '_orig_mod.' 前缀
state_dict = {k.replace('_orig_mod.', ''): v for k, v in checkpoint['model'].items()}
model.load_state_dict(state_dict)
# create the log directory we will write checkpoints to and log to
log_dir = "log"
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('/home/GPT2_train/models/tiansz/bert-base-chinese')
text = "你是谁?"
tokens = tokenizer([text])["input_ids"][0]
tokens = torch.tensor(tokens)
print(tokens)
tokens = tokens.unsqueeze(0)
x = tokens.to(device)
max_length = 100
while x.size(1) < max_length:
with torch.no_grad():
logits, loss = model(x)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
topk_probs, topk_indices = torch.topk(probs, 50, dim=-1)
ix = torch.multinomial(topk_probs, 1)
xcol = torch.gather(topk_indices, -1, ix)
x = torch.cat((x, xcol), dim=1)
tokens = x[0, :max_length].tolist()
print(tokens)
decoded = tokenizer.decode(tokens, skip_special_tokens=True)
print(">", decoded)