本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

模型结构上的创新
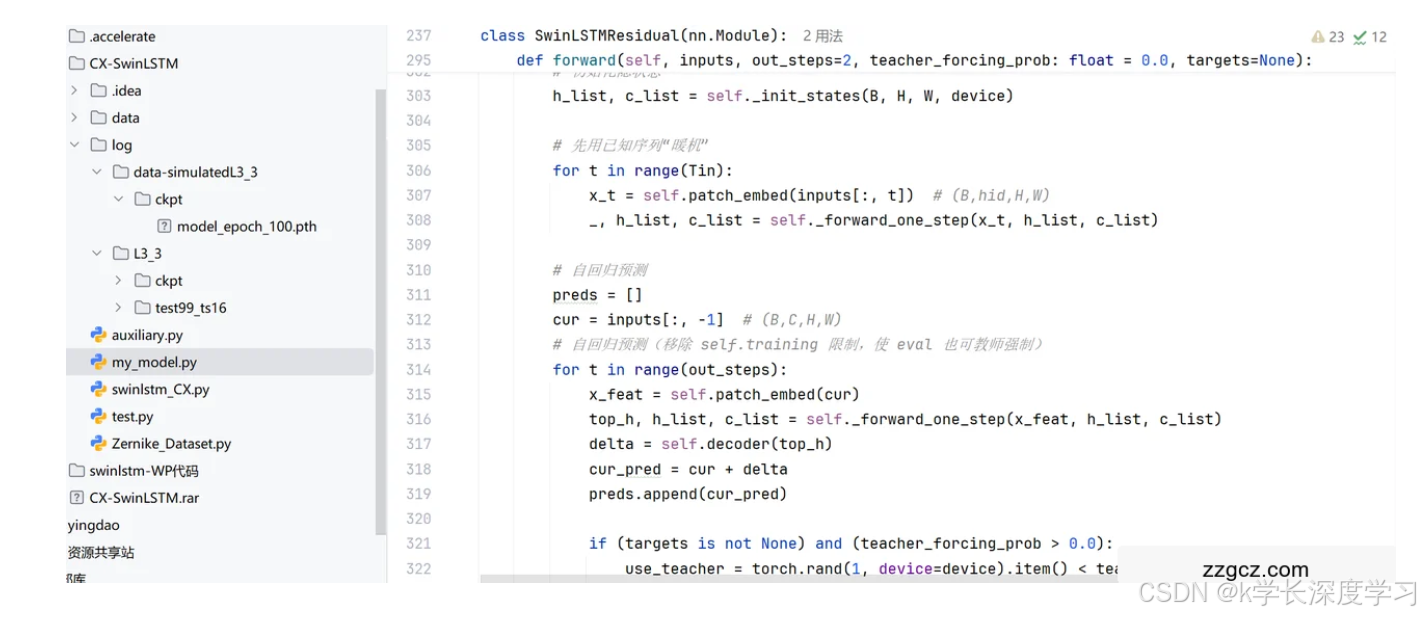
把 Swin-Transformer 融进 LSTM"细胞"内部,做门控前的时空融合 传统 ConvLSTM 用卷积做"输入×隐状态"的局部融合,你这里先把 xxx 与上一时刻 hhh 相加(z=x+hz=x+hz=x+h),在 Swin 窗口注意力(含相对位置偏置与移位窗口) 里做空间-上下文交互,再用 1×1 卷积一次性产生四个门,从而更新 (h,c)(h,c)(h,c)。这等于用注意力替换了卷积的局部感受野,提升了远程依赖建模能力,同时保持了 LSTM 的时间记忆。
单个 SwinLSTMCell 内部交替使用「不移位/半窗移位」的两层 Swin block 在一个细胞里用 depth_per_cell=2 堆两层 Swin block,第一层 shift=0、第二层 shift=window_size//2,复现 Swin 的 SW-MSA 机制,但封装到循环单元内部,形成"先注意力、再门控"的最小时空单元。
自回归的"残差预测"框架(delta 形式) 顶层隐藏态经 1×1 卷积输出 Δ\DeltaΔ,预测帧由 cur_pred = cur + delta 得到。对光学波前这类随时间缓慢演化的信号更稳、更易训练。
无下采样的 Patch-Embed + 可变多头策略 用 3×3 Conv 作为"等分辨率"的特征映射,既保细节又能升通道;注意力头数默认 hidden_dim//32 自适配隐藏维度,工程上更省心。
完整实现了 Swin 的相对位置偏置与移位窗口掩码 自行构建 relative_position_bias_table/index 与跨窗 mask,注意力计算后再窗口反拼接与反移位,保证了块内/块间信息流通。
训练与推理策略上的创新/用心点
教师强制(Schedule Sampling)做成"前向可控",评估也可选择开启 forward 支持 teacher_forcing_prob,并显式去掉对 self.training 的依赖------因此测试脚本里可以用较高的 TF 概率做诊断或可视化。 训练端用 线性退火(但退到 0.9,保持强监督,用于稳定自回归残差学习),并与 SmoothL1 与梯度裁剪组合,提升鲁棒性。
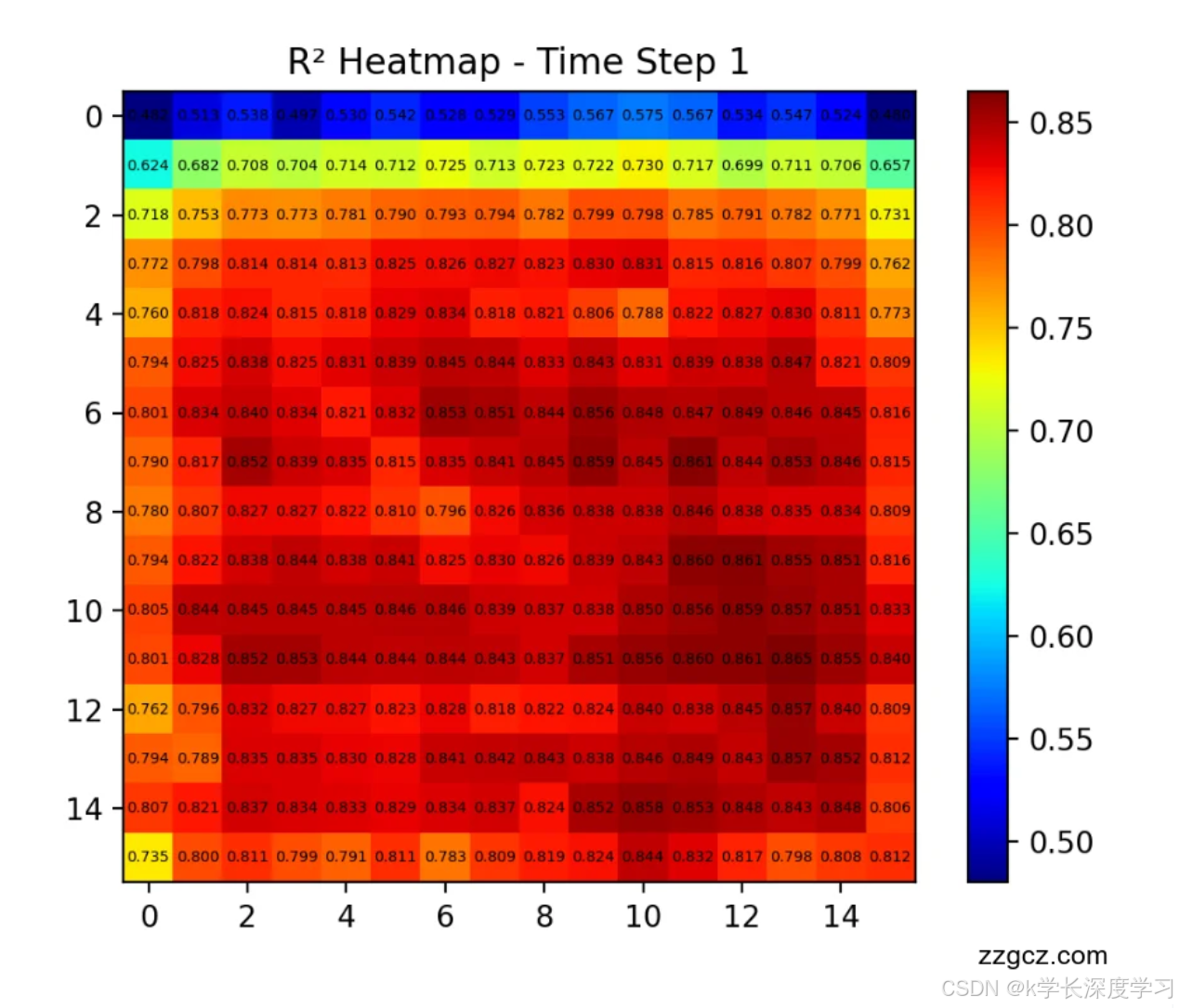
逐时间步 R² 指标,并提供"像素级 R² 热力图" 除了整体 R²,你增加了 (T,H,W) 的空间 R²,可直观看到哪里预测好/哪里差,加速模型与光机误差源的定位。
数据与可视化侧的创新/贴合领域的设计
面向 Zernike 系数序列的流水线 + 统一归一化 按 set 与帧号排序、按时间切分、指定 Zernike 通道范围与空间 patch;归一化用"训练段最大绝对值"的全局因子,训练/测试一致,便于稳定学习。
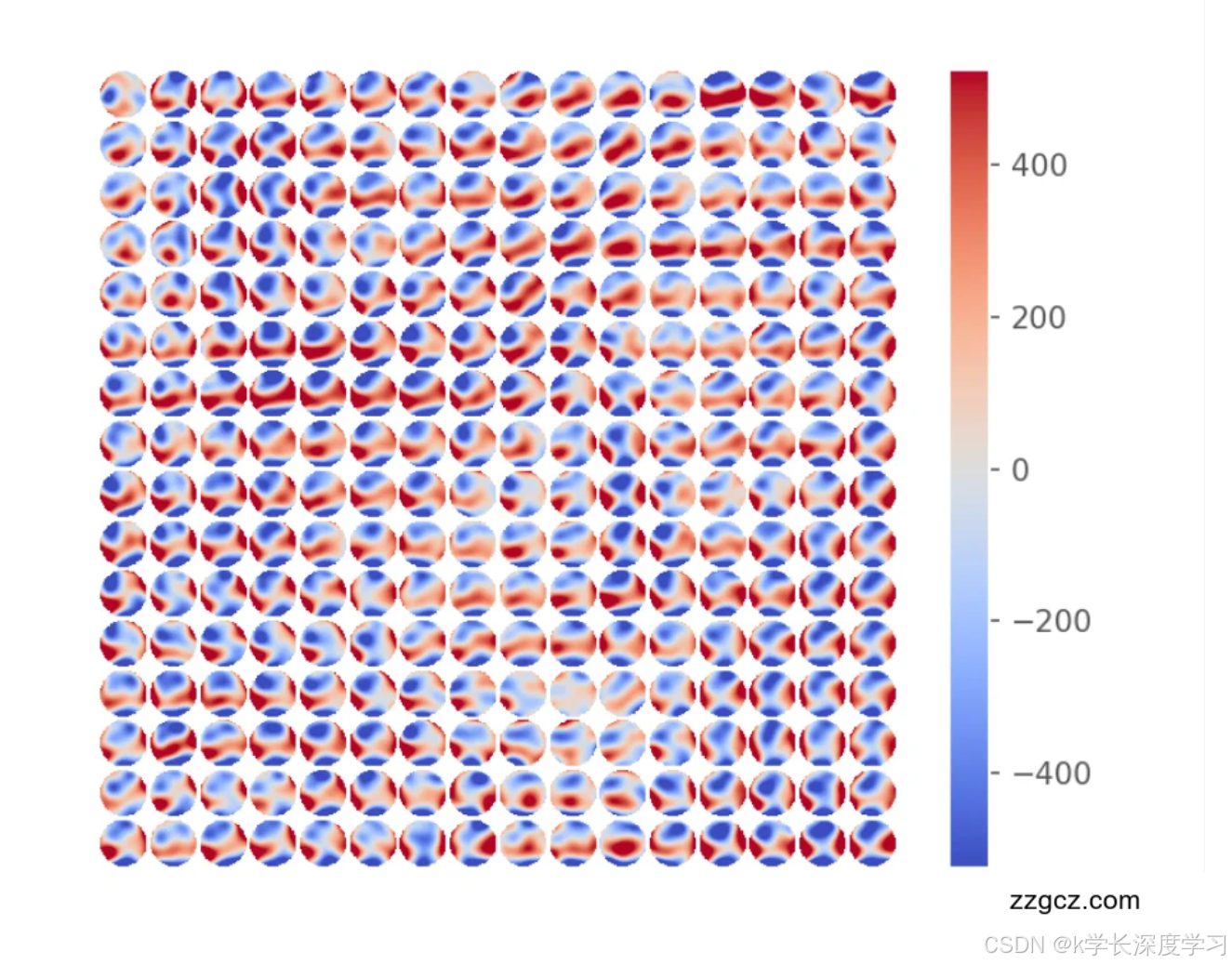
从 Zernike → 相位图的可视化打通 在测试阶段把每帧系数与预置的 Z → Z!\to!Z→phase 变换矩阵相乘,还原出 拼接后的相位分布图 并保存,便于与物理系统联调与直觉验证。
这些设计各自带来的价值
SwinLSTM 细胞:注意力×记忆 在门控前做局部-全局的自适应聚合,继承 LSTM 的时间建模与 SWin 的空间非局部性,在低分辨率 patch 上也能捕获跨子孔径/跨 Zernike 模式的耦合;与纯 ConvLSTM 相比,对高速湍流/高阶像差的长程依赖更友好。
残差式自回归 把"变化量"作为学习目标,贴合光学波前的连续性与平滑性,可减小尺度误差并提高多步稳定性。
可控教师强制 & 评估同构 训练/测试共用一个前向接口,便于做诊断性可视化(例如空间 R²),在工程上极大降低了"训练逻辑与评测逻辑不一致"的风险。
面向 Zernike 的端到端评测 数据→系数→相位图一条龙,可以直接对比相位误差热力图与硬件成像现象,形成闭环。
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。