目录
- 计算机视觉的研究社区(computer vision research community)非常喜欢把许多数据集上传到网上,比如ImageNet、MS COCO、Pascal类型的数据集,它们都是由大家上传到网络的,并且有大量的计算机视觉研究者已经用这些数据集训练过他们的算法了。有时候这些训练过程需要花费好几周,并且需要很多的GPU。你可以下载花费了别人好几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化用在你自己的神经网络上。用迁移学习把公共的数据集的知识迁移到你自己的问题上。
1.迁移学习示例:猫检测器
-
假如你要建立一个猫咪检测器,用来检测你自己的宠物猫(pet cat)。假如你的两只猫叫Tigger和Misty,那检测结果有三种:Tigger,Misty或者两者都不是,所以是一个三分类问题。现在你可能没有Tigger或者Misty的大量的图片,所以你的训练集会很小,你该怎么办呢?
-
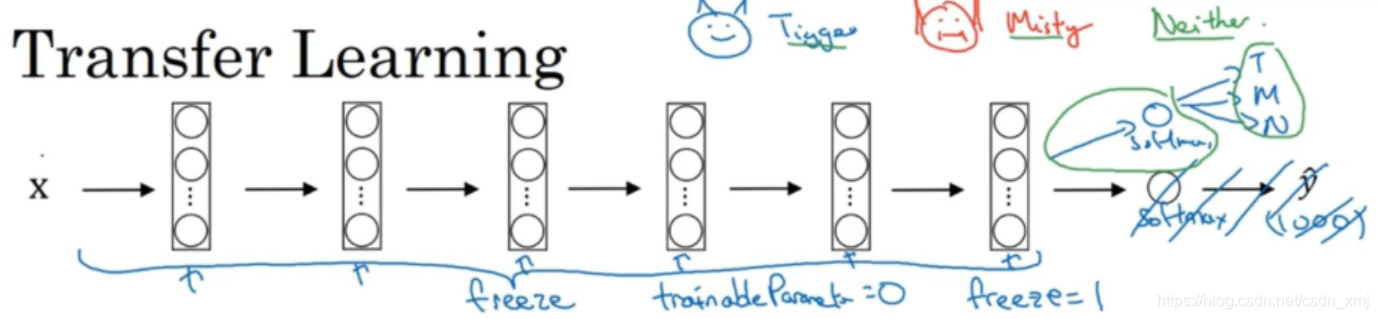
-
我们可以先从网上下载一些神经网络开源的实现,把代码和权重都下载下来。例如,ImageNet数据集,它有1000个不同的类别,因此这个网络会有一个Softmax单元,它可以输出1000个可能类别之一。你可以去掉这个Softmax层,创建自己的Softmax单元,用来输出Tigger、Misty和neither三个类别。就网络而言,建议把所有的层看作是冻结的,冻结网络中所有层的参数,只需要训练和你的Softmax层有关的参数。
-
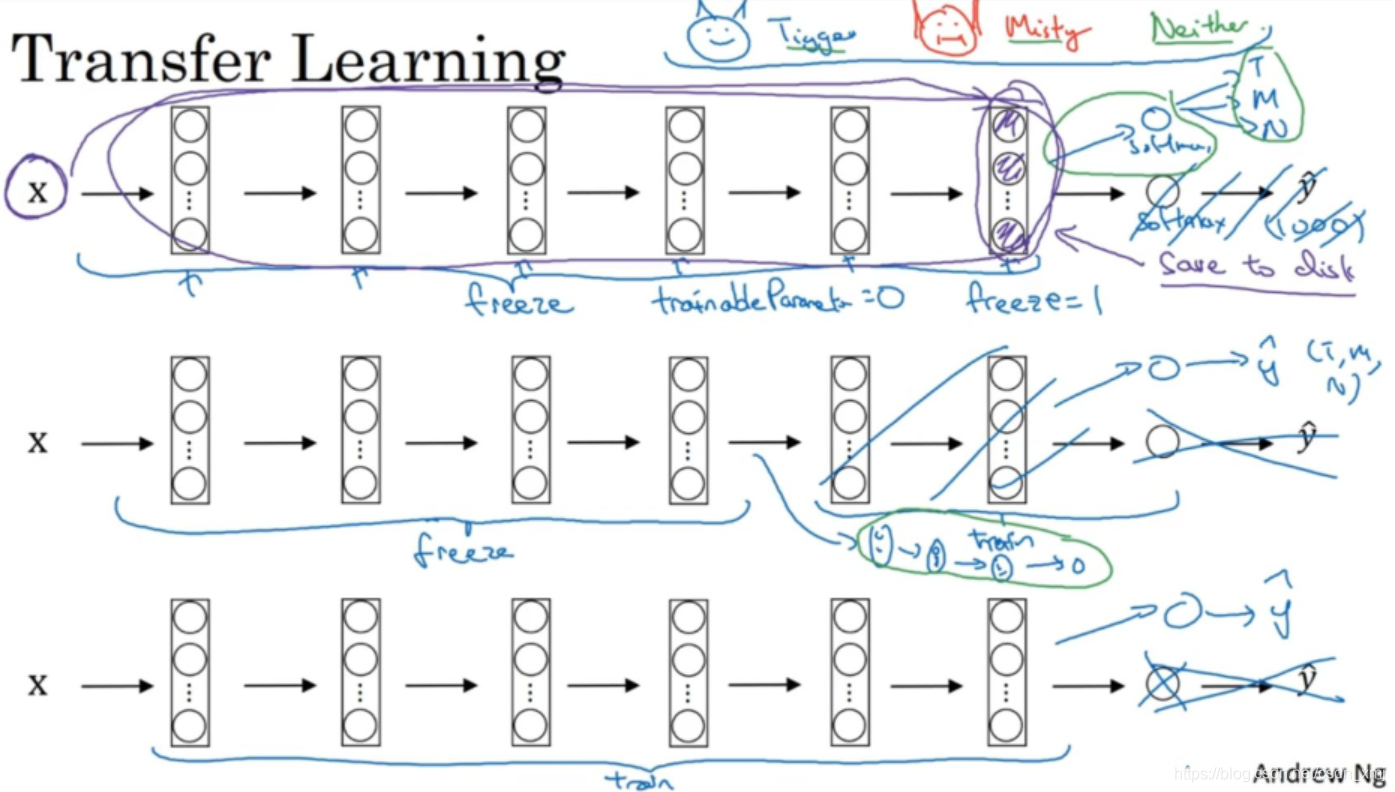
-
(1)当你的数据集很小的时候,有一个技巧(上图第一行紫色部分),由于前面的层都冻结了,相当于一个固定的函数,不需要改变。可以把输入图像直接映射到这层(softmax的前一层)的激活函数。所以这个能加速训练的技巧就是,如果我们先计算这一层(紫色箭头标记),计算特征或者激活值,然后把它们存到硬盘里(softmax层之前的所有层视为一个固定映射),这样你训练的就是一个很浅的softmax模型。对你的训练集中所有样本的这一层的激活值进行预计算,然后存储到硬盘里,然后在此之上训练softmax分类器,不需要每次遍历训练集再重新计算这个激活值了。
-
(2)如果你有一个稍大的数据集 ,也许你有大量的Tigger和Misty以及两者都不是的照片,你应该冻结更少的层,比如只把这些层冻结(括号中的层),然后训练后面的层。然后构建自己的输出单元。有很多方式可以实现,你可以取后面几层的权重,用作初始化,然后从这里开始梯度下降。或者也可以直接去掉后面这几层,换成你自己的隐藏单元和你自己的softmax输出层。注意有一个规律:你自己的数据越多,你需要冻结的层数越少,能够训练的层数就越多。
-
(3)如果你有大量数据,(上图第三行)你应该做的就是用开源的网络和它的权重,把所有的权重当作初始化,然后训练整个网络。然后构建自己的输出层。如果你有越多的标定的数据,你可以训练越多的层。极端情况下,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
2.数据增强
(1)前言
- 当下计算机视觉的主要问题是没有办法得到充足的数据。这就意味着训练计算机视觉模型的时候,使用数据增强这个技巧可以提高我们使用少量数据训练模型的效率。
(2)数据增强的方法
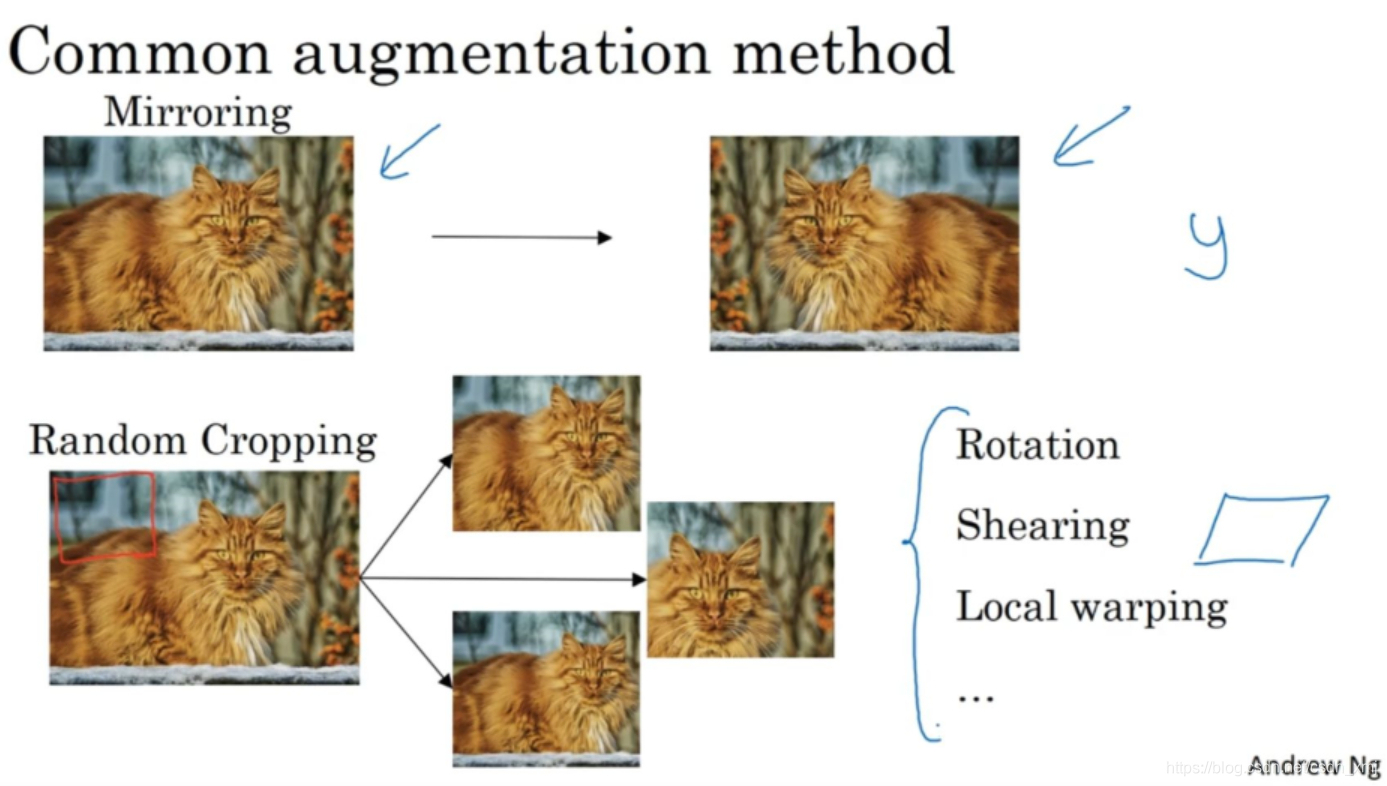
- 镜像对称:上图第一行
- 随机裁剪:上图第二行
- 旋转,弯曲等
- 颜色转换:然后给R、G和B三个通道上加上不同的失真值