这篇题为《FlashWorld: High-quality 3D Scene Generation within Seconds》的研究论文,提出了一种名为FlashWorld的高效高质量三维场景生成方法。以下是其主要研究内容的概括:
一、核心问题与动机
-
问题 :当前三维场景生成方法存在两大瓶颈:速度慢 (从几分钟到几小时)和质量低(多视图不一致、模糊或存在伪影)。
-
动机 :克服传统多视图导向方法 (先生成多视图图像再重建三维场景)的三维一致性差的问题,以及三维导向方法 (直接生成三维表示)视觉质量低的问题,实现快速(秒级)、高质量、高一致性的三维场景生成。
二、核心创新方法
FlashWorld的核心是一个双阶段训练框架,结合了多视图导向(高视觉质量)和三维导向(高三维一致性)两种范式的优点。
1. 双模式预训练
-
使用多视图数据集,训练一个双模式多视图潜在扩散模型。
-
多视图导向模式:直接预测去噪后的多视图潜在表示,优化视觉质量。
-
三维导向模式 :从多视图特征解码出三维高斯表示,通过渲染新视图计算损失,强制模型学习三维一致性。
-
关键改进 :使用视频扩散模型(而非图像扩散模型)进行初始化,支持更多视图(24个)和更高分辨率(480P),收敛更快。
2. 跨模式后训练(蒸馏)
-
目标 :将多视图导向模式的高视觉质量 蒸馏到三维导向模式的少步生成器中,同时保持三维一致性。
-
机制:
-
教师模型:冻结的多视图导向模式,提供高质量分数梯度。
-
学生模型 :三维导向的少步生成器,通过分布匹配蒸馏(DMD2) 学习教师的分布。
-
-
引入跨模式一致性损失:约束三维导向模式与多视图导向模式的输出一致性,减少由渲染梯度不稳定引起的漂浮伪影。
3. 分布外数据协同训练
-
问题:多视图数据有限,影响模型泛化能力。
-
策略 :在后训练阶段,引入单视图图像、文本提示与随机相机轨迹的组合数据,增强模型对多样化输入和相机轨迹的适应能力。
-
注意:此阶段省略GAN损失,避免分布不匹配。
三、实验验证
1. 图像到三维场景生成
-
对比方法:CAT3D、Bolt3D、WonderLand等。
-
结果:FlashWorld能生成细节更丰富、结构更完整的三维场景,尤其是在复杂物体(如叶子、栅栏、触手)上表现优异。
2. 文本到三维场景生成
-
对比方法:Director3D、Prometheus、SplatFlow、VideoRFSplat等。
-
结果:
-
定性:生成结果细节更精细、语义更一致。
-
定量 :在T3Bench、DL3DV、WorldScore数据集上,在Q-Align、CLIP IQA+、CLIP Score等多个质量评估指标上领先。
-
速度 :生成一个场景仅需9秒,显著快于其他方法(最快13秒)。
-
3. WorldScore基准测试
-
对比方法:WonderJourney、LucidDreamer、WonderWorld。
-
结果:
-
在风格一致性 上排名第一,在光度一致性、物体控制、主观质量上排名第二。
-
平均得分最高,推理速度最快(9秒)。
-
在"三维一致性"和"内容对齐"上得分略低,主要是因为方法不依赖于深度估计或直接操作锚定帧内容,而是纯RGB监督。
-
4. 消融实验
-
验证了各组件(双模式预训练、跨模式蒸馏、分布外数据)的必要性。
-
移除任一组件都会导致质量下降、伪影增多或泛化能力减弱。
四、主要贡献总结
-
提出FlashWorld框架 :首次通过跨模式蒸馏将高质量多视图生成与三维一致生成有效结合。
-
双模式预训练策略:使模型同时具备高视觉质量和内在三维一致性。
-
分布外数据协同训练:显著提升模型对多样化输入的泛化能力。
-
实现高速高质量生成 :在多个任务上达到最先进性能,速度快10--100倍,且支持更高分辨率、更多视图。
五、未来展望
-
引入自回归生成机制。
-
扩展到动态4D场景生成任务。
-
结合深度先验 和三维结构信息进一步提升几何细节质量。
FlashWorld为实时、高质量三维内容生成 (如游戏、VR/AR、机器人仿真)提供了切实可行的技术路径,在速度、质量、一致性 三者之间取得了突破性平衡。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目主页地址在这里,如下所示:
项目地址在这里,如下所示:

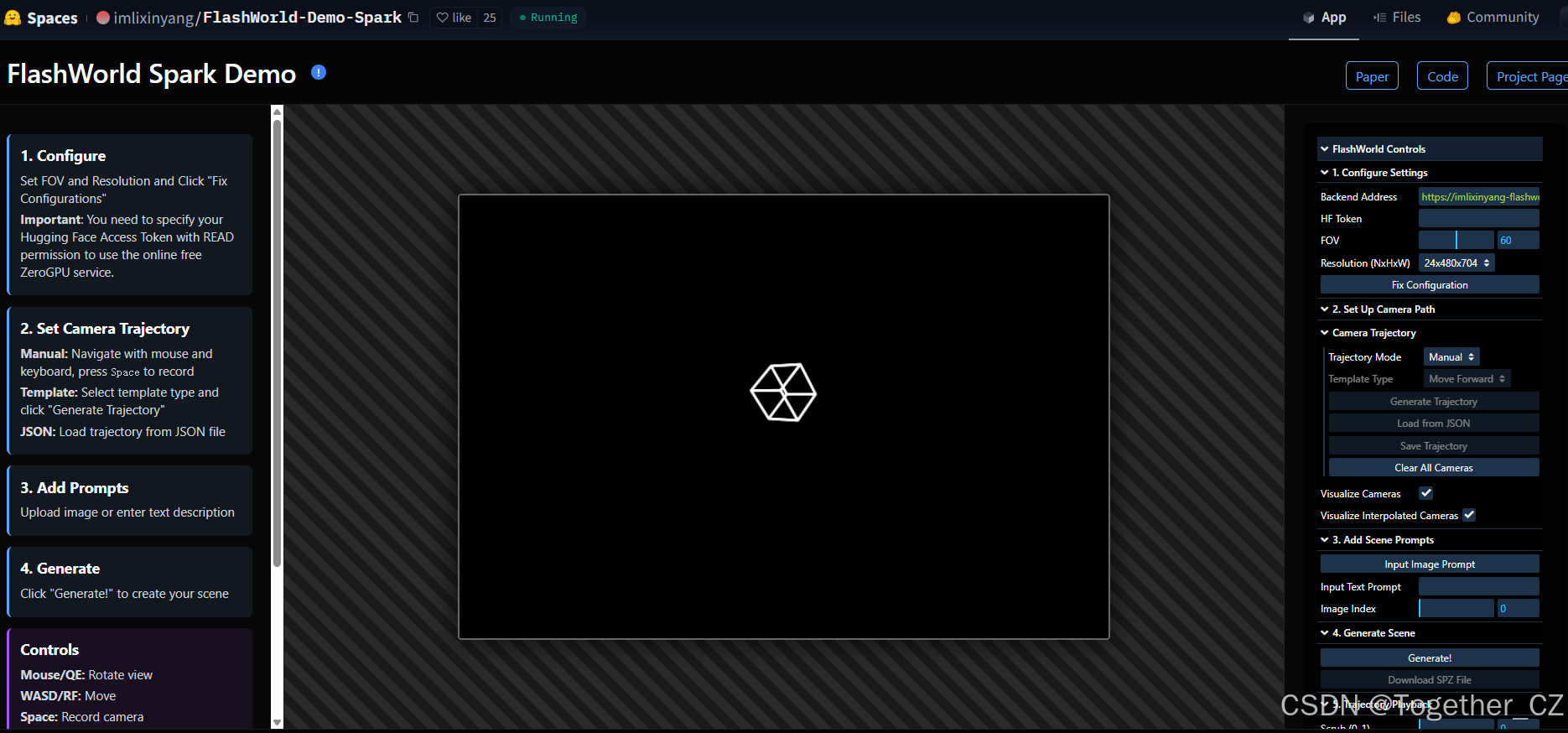
在线Demo地址在这里,如下所示:
摘要
我们提出了 FlashWorld,一种从单张图像或文本提示在数秒内生成三维场景的生成模型,比先前工作快 10∼100 倍,同时具备更优的渲染质量。我们的方法从传统的多视图导向范式转向三维导向范式。传统范式先生成多视图图像用于后续三维重建,而我们的方法在多视图生成过程中直接生成三维高斯表示。在确保三维一致性的同时,三维导向方法通常视觉质量较差。FlashWorld 包含一个双模式预训练阶段和一个跨模式后训练阶段,有效整合了两种范式的优势。具体来说,借助视频扩散模型的先验知识,我们首先预训练一个双模式多视图扩散模型,该模型同时支持多视图导向和三维导向的生成模式。为了弥合三维导向生成的质量差距,我们进一步提出了一种跨模式后训练蒸馏,通过将一致的三维导向模式的分布匹配到高质量的多视图导向模式。这不仅在保持三维一致性的同时提升了视觉质量,还减少了推理所需的去噪步骤。此外,我们提出了一种策略,在此过程中利用海量单视图图像和文本提示,以增强模型对分布外输入的泛化能力。大量实验证明了我们方法的优越性和高效性。
1 引言
三维生成在游戏、机器人和 VR/AR 领域显示出巨大的应用前景。然而,与生成单个三维物体相比,生成完整的三维场景在质量和效率方面仍然是一个重大挑战。

图 1:FlashWorld 能够在多样化的场景中实现快速且高质量的三维场景生成。
这些挑战源于两个核心障碍:高质量三维场景数据的稀缺性以及对真实世界场景建模的指数级复杂性。
早期方法通常依赖于组装现有的三维资产(Xu 等人,2002;Yu 等人,2011;Wu 等人,2018;Feng 等人,2023;Celen 等人,2024;Yang 等人,2024a;Deng 等人,2025)或从修复图像和深度图迭代重建场景(Cai 等人,2023;Fridman 等人,2023;Hollein 等人,2023;Lei 等人,2023;Yu 等人,2024;Zhang 等人,2024c;Chung 等人,2023;Yu 等人,2025;Shriram 等人,2025;Ni 等人,2025)。然而,由于缺乏整体的场景级理解或多视图一致性约束,这些方法往往难以产生语义连贯且视觉逼真的场景。为了解决这个问题,可扩展的数据驱动方法应运而生。主导范式是一个两阶段、多视图导向的流程(Gao 等人,2024;Sun 等人,2024;Wallingford 等人,2024;Zhao 等人,2025;Szymanowicz 等人,2025;Yang 等人,2025;Go 等人,2025a, 2025b):扩散模型首先从文本或参考图像生成多个视图,然后进行三维重建。然而,视图合成过程中缺乏明确的三维约束,通常会导致生成视图在几何和语义上不一致,使得合成视图与重建的三维场景之间存在明显的视觉质量差距。此外,扩散和重建两个阶段的巨大计算开销导致生成延迟达到数分钟到数小时,如图 2 所示。这些限制损害了当前三维场景生成方法的有效性和效率,阻碍了其应用。
一个前景广阔但相对较少探索的方向是三维导向的场景生成流程(Xu 等人,2023;Li 等人,2024a, 2024b;Tang 等人,2025;Cai 等人,2024)。这些方法将可微分渲染(Mildenhall 等人,2020;Wang 等人,2021;Kerbl 等人,2023)与扩散模型相结合,无需额外的重建阶段即可直接生成三维场景。然而,这些生成的三维场景通常存在视觉伪影和模糊内容。因此,它们通常需要一个额外的细化阶段,这会显著降低生成效率。

图 2:不同三维场景生成方法的简要比较 。多视图导向扩散方法(即 CAT3D (Gao 等人, 2024),Bolt3D (Szymanowicz 等人, 2025),Wonderland (Liang 等人, 2025) 和 Ours w/ MV-Diff)由于多视图不一致而产生噪声纹理。多视图导向蒸馏进一步加剧了此缺陷(即 Ours w/ MV-Dist)。三维导向扩散方法(即 Ours w/ 3D-Diff)存在模糊的视觉效果。我们的跨模式蒸馏模型(即 Ours)同时解决了这些问题,使得新视角的质量接近输入视角。每个场景的时间成本(在单 GPU 上测试)显示在每个方法的底部。
为了提高扩散模型的效率,后训练蒸馏技术(如一致性模型蒸馏(Song 等人,2023)和分布匹配蒸馏(Yin 等人,2024a;Xie 等人,2024))常被使用。然而,直接应用蒸馏会放大每个框架固有的局限性:例如,在多视图导向流程中会加剧多视图不一致性。
在这项工作中,我们引入了一个新颖的框架,通过蒸馏结合了两种范式的优势,在显著加速推理速度的同时,在三维一致性和视觉保真度方面取得了实质性收益。我们的贡献简要总结如下:
∙∙ 我们引入了一种基于视频扩散模型的双模式预训练策略,以训练一个能够同时运行在多视图导向和三维导向模式下的多视图扩散模型。
∙∙ 我们提出了一种跨模式后训练策略,其中多视图导向模式充当教师以提升视觉质量,而三维导向模式则作为学生以确保三维一致性。
∙∙ 为了提高分布外泛化能力,我们引入了一种新颖的策略,可以在后训练期间利用海量未标注图像数据和带有随机模拟相机轨迹的文本提示,从而增强模型对多样化输入的适应性,如图 1 所示。
2 预备知识


3 方法
我们框架的核心在于利用 DMD 将知识从一个为高视觉质量而建立的多视图导向多视图扩散模型,转移到一个天生具备三维一致性的三维导向少步多视图生成器。然而,这种范式引入了两个关键挑战:首先,对于开放世界三维场景生成,三维导向的少步生成器从一开始就需要足够鲁棒的先验知识和强大的生成能力。否则,训练过程容易崩溃。其次,由于高质量多视图数据集在数量和多样性上的限制,开发一个能有效处理多样化风格、物体类别和相机轨迹场景的策略变得至关重要。具体来说,为了解决这些挑战,我们首先设计了一个双模式预训练策略,详见第 3.1 节。该策略产生一个能在两种不同模式下运行的多视图扩散模型:用于高视觉保真度的多视图导向模式和用于天生三维一致性的三维导向模式。随后,在第 3.2 节,我们提出了一个跨模式后训练框架来桥接这两种模式:多视图导向模式充当 教师 ,提供分数蒸馏梯度以确保视觉质量;三维导向模式作为 学生,学习继承教师的分布同时保持三维一致性。此外,为了明确解决分布外泛化问题,我们在第 3.3 节引入了一种策略,能够利用单视图图像数据、文本提示和预定义的相机轨迹,从而提升模型对多样化场景的适应性。
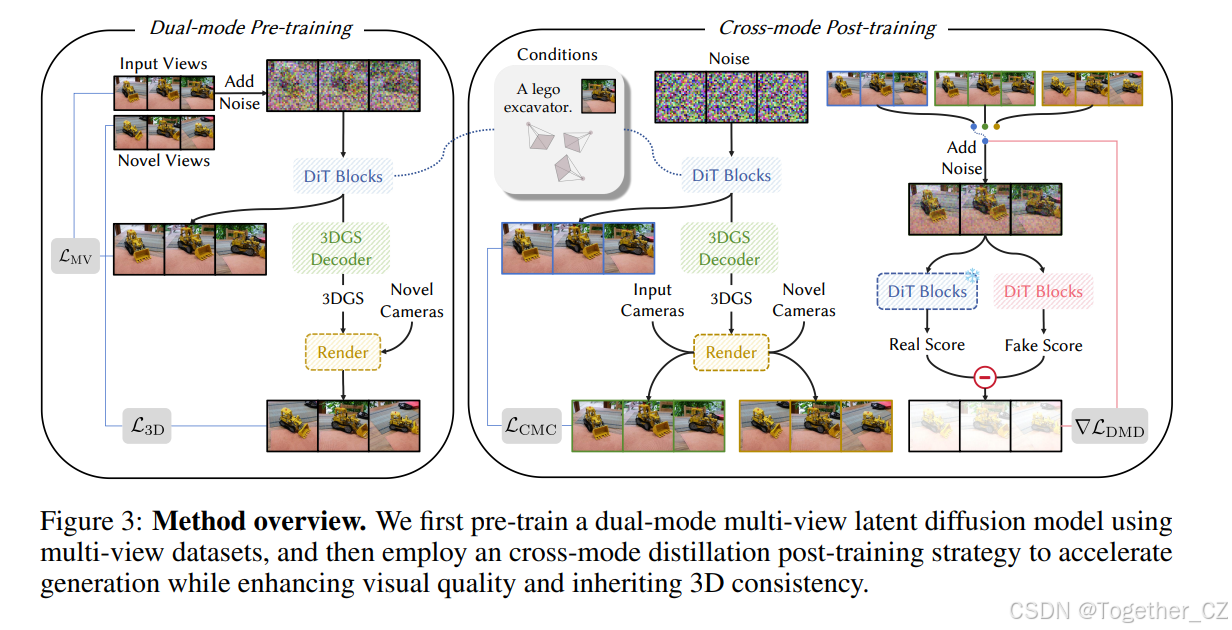
3.1 双模式预训练

与之前从图像扩散模型(Rombach 等人,2022)初始化的方法(Li 等人,2024a;2024b)不同,我们用视频扩散模型(Wan 等人,2025)初始化我们的框架。我们观察到这个视频模型不仅收敛更快,而且拥有一个压缩率更高的强大 VAE,能够支持更多的视图数量(即 24 个)和更高的输出分辨率(即 480P)。
3.2 跨模式后训练
预训练后,我们采用一种非对称蒸馏策略来加速生成,同时提升视觉质量并继承三维一致性,如图 3(右)所示。具体来说,我们观察到虽然多视图导向模式一致性较差,但它可以生成具有高视觉质量的多视图图像;因此,我们利用双模式多视图潜在扩散模型的多视图导向模式作为真实教师 μreal:此教师模型被冻结,负责计算真实分数梯度。模型的另一个副本 μfake 动态更新,以估计与当前蒸馏生成器分布相对应的虚假分数。同时,我们的少步学生模型使用双模式多视图潜在扩散模型的三维导向模式进行初始化。

3.3 分布外数据协同训练
在预训练阶段,通常会在图像和视频生成任务上进行联合训练,以增强模型的泛化能力。虽然这种方法有益于 DiT 骨干网络,但它并没有优化 3DGS 解码器,可能限制了 3DGS 解码器能有效处理的输入范围。
为了解决这个问题,在后训练阶段,我们引入了一种策略来拓宽模型的输入分布并提升对多样化场景的泛化能力,即使多视图数据在数量和种类上有限。具体来说,我们将从图像数据集采样的图像或文本条件与随机相机轨迹相结合,这些轨迹可以来自多视图序列或一组预定义的轨迹。重要的是,我们在这种协同训练过程中省略了 GAN 损失,以防止分布不匹配。这种方法不仅增强了模型对各种输入图像和文本提示的泛化能力,还提高了其在遇到分布外相机轨迹时的鲁棒性。该策略的详细信息见附录 A。

4 实验
本节中,我们在多个基准测试上评估我们方法的性能,包括图像到三维场景生成、文本到三维场景生成以及 WorldScore 基准测试。实现细节请参考附录 A。
4.1 图像到三维场景生成对比
我们在图 4 中展示了与最先进的图像到三维场景生成方法的定性比较。这些基线是多视图导向的,包括:CAT3D(Gao 等人,2024),它通过多视图扩散生成新视角,然后进行基于优化的三维重建;Bolt3D(Szymanowicz 等人,2025),它为新视角合成外观和几何,然后应用前馈三维重建;以及 Wonderland(Liang 等人,2025),这是一种领先的方法,利用了强大的视频扩散模型和基于潜在的前馈三维重建。由于这些方法未开源,我们利用其各自项目页面提供的视频结果进行可视化。我们使用 ViPE(Huang 等人,2025a)从基线视频中估计相机位姿和内部参数。CAT3D 难以生成复杂场景,导致输出模糊且缺失几何细节。Bolt3D 也表现出不准确的几何细节,例如不精确的树枝和针状叶子。Wonderland 存在重复和扭曲的高斯伪影,尤其是在相机位姿变化较大时。总体而言,这些多视图导向方法由于多视图一致性不足,未能成功生成复杂场景。相比之下,我们的模型产生了高保真度、细节丰富的场景,并成功恢复了复杂的结构(例如叶子、铁栅栏和触手),突出了我们三维导向流程的优势。
4.2 文本到三维场景生成对比

我们将我们的方法与几种最先进的文本到三维场景生成方法进行比较,包括 Director3D(Li 等人,2024b)、Prometheus(Yang 等人,2025)、SplatFlow(Go 等人,2025a)和 VideoRFSplat(Go 等人,2025a)。定性比较见图 5。Director3D 依赖于逐场景细化,这经常在生成的结果中引入模糊和波浪状伪影。相比之下,我们的模型生成的对象准确,具有细粒度细节(如动物毛发),同时保留了逼真的背景。Prometheus 不使用细化,由于其多视图导向流程固有的不一致性,生成的场景常常模糊,并可能出现错误的物体几何(例如椅子腿)。然而,我们的方法能够在复杂场景中生成结构丰富且精确的物体,即使在大范围相机运动下也是如此。SplatFlow 和 VideoRFSplat 也受到模糊伪影的影响,难以再现精细细节,例如地板和草地上的细节。相比之下,我们的模型生成了逼真的细节,同时保持了与输入文本提示的语义一致性。
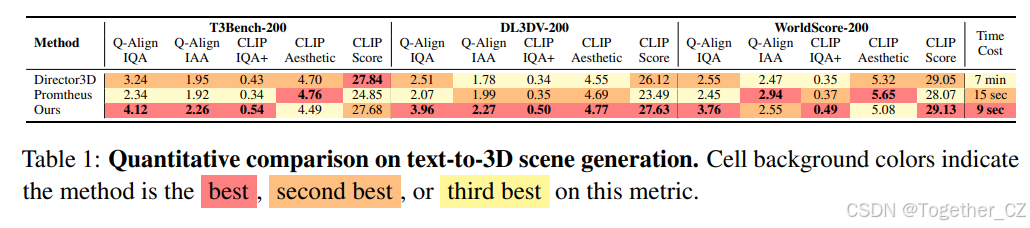
我们进一步对该任务进行了全面的定量评估。具体来说,我们从 T3Bench(He 等人,2023)、DL3DV(Ling 等人,2024)和 WorldScore(Duan 等人,2025)中采样了 600 个文本提示,涵盖以物体为中心和一般场景。由于所有比较方法都基于三维高斯表示,与相机控制和三维一致性相关的指标在此设置下不适用。因此,我们专注于所采用的质量评估指标,包括 CLIP IQA+(Wang 等人,2023)、CLIP Aesthetic(Schuhmann,2022)、文本-图像对齐分数(CLIP Score)(Hessel 等人,2021),以及最新的基于 LMM 的 Q-Align(Wu 等人,2024)图像质量度量。定量结果总结在表 1 中。显然,我们的模型在大多数质量评估指标上取得了优越的性能。对于 CLIP-Aesthetic,我们注意到该指标有时偏向平滑的输出,这可能并不总是与我们方法产生的细节丰富且逼真的结果一致。我们的方法在两个子集上也获得了最高的 CLIP Score,表明了我们方法强大的文本对齐能力。此外,我们报告了在单块 H20 GPU 上每种方法生成单个场景所需的平均时间。我们的方法相对于其他方法展现出显著的速度优势。值得注意的是,即使我们的方法以更高分辨率和更多帧数生成结果,这种效率依然得以保持。此外,我们的方法利用一个统一的模型,能够无缝处理图像到三维和文本到三维任务,无需单独的训练过程。这种统一框架不仅简化了整体工作流程,还大大降低了训练成本。


4.3 WorldScore 基准测试对比
我们进一步在最近的 WorldScore(Duan 等人,2025)基准测试上进行了全面评估。WorldScore 的静态子集包含 2000 个测试样例,涵盖了各种风格、场景和物体的多样化世界。每个测试用例提供一个输入图像、一个文本提示和一个相机轨迹作为生成条件。评估方案旨在评估世界生成的两个主要方面:可控性和质量。对于基线,我们选择了三种最先进的三维生成方法:WonderJourney(Yu 等人,2024),它基于点云迭代完成新视角图像和深度图;LucidDreamer(Chung 等人,2023),它也执行迭代新视角完成,但使用 3DGS 进行渲染;以及 WonderWorld(Yu 等人,2025),它通过使用分层高斯面元来提高生成质量。由于我们的比较专注于三维生成方法,"相机控制"指标主要反映了每种方法评估方案的鲁棒性,因此在此背景下信息量较小。因此,我们在比较中省略了这一指标。此外,原始的 WorldScore 基准测试仅在锚定帧上评估大多数指标,这对于需要新视角合成的三维世界生成任务来说不是最优的。为了确保更公平的比较,我们通过在特定间隔内随机采样帧来重新评估这些指标。定性和定量比较分别如图 6 和表 2 所示。在所有比较方法中,我们的方法获得了最高的平均分和最快的推理速度。特别是,我们的模型在"风格一致性"上表现最佳,并在"光度一致性"、"物体控制"和"主观质量"上获得第二名,反映了在可控性和质量方面均衡且鲁棒的能力。虽然我们的方法在"三维一致性"和"内容对齐"上得分相对较低,但这些结果可归因于方法差异:对于"三维一致性",所有基线都使用了与评估方案紧密对齐的单目深度估计模型,而我们的方法仅依赖 RGB 监督,没有显式的深度指导;对于"内容对齐",我们的方法不像基线那样直接操作锚定帧内容。定性分析进一步显示,基线方法在生成的场景中经常表现出不自然的过渡、不连续的内容和可见的孔洞,这可能未被当前指标充分反映。总体而言,我们的方法在一致性和忠实生成方面优于现有方法。

4.4 消融研究
在图 2 中,我们展示了各种消融模型在图像到三维场景生成上的生成结果。结果与我们的预期非常吻合:多视图导向扩散模型(_w/_MV-Diff)和多视图导向蒸馏模型(_w/_MV-Dist)都因多视图不一致性而表现出嘈杂的三维重建,而三维导向扩散模型(_w/_3D-Diff)则产生模糊的视觉结果。为了进一步验证每个提出策略的有效性,我们在文本到三维场景生成上进行了更全面的消融研究。定量和定性结果分别总结在表 3 和图 7 中。一致地,前三个消融模型继续表现出更差的视觉质量和更弱的文本对齐能力。与我们的完整模型相比,没有跨模式一致性损失的模型(_w/o_CMC)在大多数定量指标上取得了有竞争力的、在某些情况下甚至更高的分数。然而,定性分析显示该模型容易产生漂浮和重复伪影。没有分布外数据的模型(_w/o_OOD)更容易出现语义错位(例如"field"),并且在定量文本对齐指标上有所下降。这个问题在分布上与原始多视图数据不同的 T3Bench 和 WorldScore 上更为突出,突出了纳入 OOD 数据以改善泛化的重要性。
5 结论
我们提出了一种高效而强大的三维场景生成模型,命名为 FlashWorld。我们方法的核心是一个新颖的蒸馏策略,它将高视觉保真度从多视图导向的扩散模型转移到具有完美三维一致性的三维导向多视图生成模型。为了实现这一点,我们设计了一个双模式预训练阶段和一个跨模式后训练阶段,并引入了一种分布外数据协同训练策略以提升模型的泛化能力。我们的方法在多项任务上实现了最先进的性能,同时在推理速度上具有显著优势。我们方法的效率和有效性有助于推动三维场景生成的应用。未来的工作包括纳入自回归生成(Zhang 等人,2024d;2025;Huang 等人,2025b;Chen 等人,2024),并将我们的框架扩展到动态 4D 场景生成任务(Wu 等人,2023;Zhang 等人,2024a)。