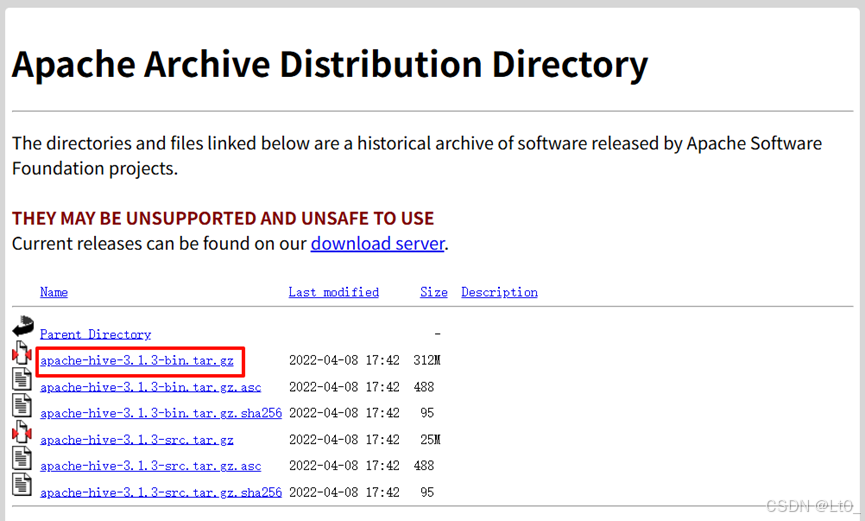
1. 下载
下载:https://archive.apache.org/dist/hive/hive-3.1.3/
2. 准备
2.1 解压
将下载的压缩包解压到指定目录,并改个简单的名字
shell
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/module/
cd /opt/module/
mv apache-hive-3.1.3-bin hive-3.1.32.2 Hadoop准备
提前在 Hadoop HDFS 中提前创建 /user 目录,并授权
Hadoop的搭建可以参考:https://blog.csdn.net/wanzijy/article/details/156113091
shell
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod -R 777 /user2.3 mysql准备
下载 mysql 连接 java 的 jar 包:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.tar.gz
解压后,将这个包放到 Hive 的 lib 目录
shell
tar -zxvf mysql-connector-j-8.0.33.tar.gz -C /opt/module/
cp mysql-connector-j-8.0.33.jar /opt/module/hive-3.1.3/lib/提前在 mysql 建好名为 Hive 的数据库
3. 修改配置文件
shell
cd /opt/module/hive-3.1.3/conf/3.1 hive-env.sh
shell
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
xml
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export HIVE_CONF_DIR=/opt/module/hive-3.1.3/conf
export HIVE_AUX_JARS_PATH=/opt/module/hive-3.1.3/lib3.2 hive-site.xml
shell
vim hive-site.xml因为是本地学习测试使用,所以这次连接数据库时,就直接使用 root 了
大家也可以建 Hive 数据库的专属用户,然后授权,使用专属用户去连接
增加配置
xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.195.10:3306/hive?useSSL=false&allowPublicKeyRetrieval=true</value>
<description>mysql链接地址</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>mysql用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root666*</value>
<description>mysql密码</description>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/opt/module/hive-3.1.3/tmp</value>
<description>修改生成的临时文件目录</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>Hive 数据仓库目录</description>
</property>3.3 /etc/profile
配置 Hive 的环境变量
shell
export HIVE_HOME=/opt/module/hive-3.1.3/
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile4. 初始化
shell
cd /opt/module/hive-3.1.3/bin
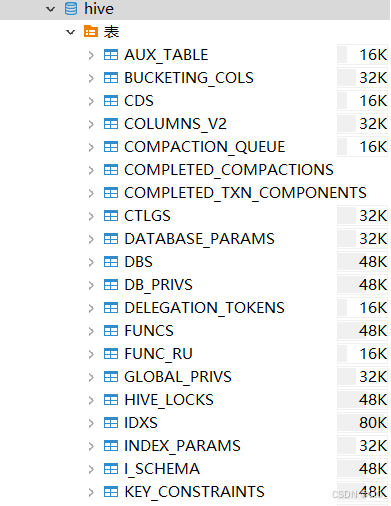
schematool -dbType mysql -initSchema然后就能看到初始化好的表了