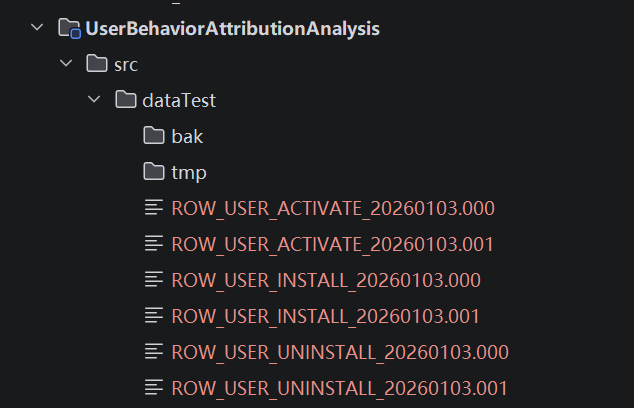
gitee代码仓地址:DataWareHouse: UserBehaviorAttributionAnalysis
一、主方法-应用起点
ProductionOdsDataToHdfs
功能:
读取hive表中的设备信息和应用信息,从全量的设备id和应用id中随机获取
作为用户行为数据的关键信息,然后根据获取到的应用信息和设备信息生成三类用户行为数据并生成文件上传到hdfs中
主要调用功能实现类ProductOdsData
Scala
package com.dw.application
import com.dw.service.ProductOdsData
object ProductionOdsDataToHdfs {
//生产数据
//五类数据需要生产,其中安装激活卸载数据是每日生产,应用信息和设备信息,在本次项目中设计为不更新
private val productOdsData = new ProductOdsData
def main(args: Array[String]): Unit = {
//获取dim_device_info中的device_id,获取dim_app_info中的app_id,模拟用户行为数据
val cnt = 180
val deviceIds: Seq[String] = productOdsData.getDeviceId(cnt)
val appIds: Seq[String] = productOdsData.getAppId
//安装数据
println("####################安装数据准备##########################")
productOdsData.userInstallData(deviceIds, appIds, cnt)
//激活数据
println("####################激活数据准备##########################")
productOdsData.userActivateData(deviceIds, appIds, cnt)
//卸载
println("####################卸载数据准备##########################")
productOdsData.userUninstallData(deviceIds, appIds, cnt)
}
}二、功能实现类ProductOdsData
包含方法:
getDeviceId :从hive表获取所有的设备id
getAppId:从hive表获取所有的应用id
userInstallData :获取安装的配置数据,再调用dataToFile生成用户安装行为数据
userActivateData 获取激活的配置数据,再调用dataToFile生成用户激活行为数据
userUninstallData 获取卸载的配置数据,再调用dataToFile生成用户卸载行为数据
dataToFile 根据输入的设备id和应用id,分别生成三种用户数据,并生成文件上传到hdfs的row层下的对应目录
Scala
package com.dw.service
import com.dw.common.utils.ConfigUtil
import com.dw.dao.{HdfsFileWriter, HiveSqlExecute}
import com.dw.util.DateUtils
import java.time.LocalDate
import java.time.format.DateTimeFormatter
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
class ProductOdsData {
// private val dwdHiveTableName = ConfigUtil.getHiveTableName.getConfig("dwd")
// private val dwsHiveTableName = ConfigUtil.getHiveTableName.getConfig("dws")
// private val adsHiveTableName = ConfigUtil.getMysqlTableName.getConfig("ads")
//加载相关hive表明和hdfs路径名
private val dimHiveTableName = ConfigUtil.getHiveTableName.getConfig("dim")
private val odsFilePath = ConfigUtil.getHdfsFilePath.getConfig("hdfs_file_path")
private val odsFilePrefix = ConfigUtil.getHdfsFilePath.getConfig("hdfs_file_Prefix")
private val hiveSqlExecute = new HiveSqlExecute
private val dateRadom = new DateUtils
private val hdfsFileWriter = new HdfsFileWriter
/**
* 获取备id
*
* @param dataCnt 需要获取的id数,默认0
* @return Seq[String]
*/
def getDeviceId(dataCnt: Int = 0): Seq[String] = {
val TABLE_NAME = dimHiveTableName.getString("dim_device_info")
hiveSqlExecute.selectOpt(s"select device_id from ${TABLE_NAME} limit ${dataCnt}").map(
rows => rows("device_id")
)
}
/**
* 获取全部的应用id
*
* @return Seq[String]
*/
def getAppId: Seq[String] = {
val TABLE_NAME = dimHiveTableName.getString("dim_app_info")
hiveSqlExecute.selectOpt(s"select app_id from ${TABLE_NAME}").map(
rows => rows("app_id")
)
}
/**
* 生成用户安装行为信息数据,并生成文件,上传到hdfs上的row层
*
* @param deviceIds 获取到的设备id序列
* @param appIds 获取到的引用id序列
* @param cnt 需要生成的数据条数
* @return Seq[String]
*/
def userInstallData(deviceIds: Seq[String], appIds: Seq[String], cnt: Int): Unit = {
// 1. 前置校验(避免空值/非法参数)
if (deviceIds.isEmpty || appIds.isEmpty) {
throw new IllegalArgumentException("deviceIds和appIds不能为空!")
}
val filePath = odsFilePath.getString("user_install_path")
val filePrefix = odsFilePrefix.getString("user_install_file_Prefix")
dataToFile(deviceIds, appIds, cnt, filePath, filePrefix)
}
/**
* 生成用户激活行为信息数据,并生成文件,上传到hdfs上的row层
*
* @param deviceIds 获取到的设备id序列
* @param appIds 获取到的引用id序列
* @param cnt 需要生成的数据条数
* @return Seq[String]
*/
def userActivateData(deviceIds: Seq[String], appIds: Seq[String], cnt: Int): Unit = {
// 1. 前置校验(避免空值/非法参数)
if (deviceIds.isEmpty || appIds.isEmpty) {
throw new IllegalArgumentException("deviceIds和appIds不能为空!")
}
val filePath = odsFilePath.getString("user_activate_path")
val datePrefix = odsFilePrefix.getString("user_activate_file_Prefix")
dataToFile(deviceIds, appIds, cnt, filePath, datePrefix)
}
/**
* 生成用户卸载行为信息数据,并生成文件,上传到hdfs上的row层
*
* @param deviceIds 获取到的设备id序列
* @param appIds 获取到的引用id序列
* @param cnt 需要生成的数据条数
* @return Seq[String]
*/
def userUninstallData(deviceIds: Seq[String], appIds: Seq[String], cnt: Int): Unit = {
// 1. 前置校验(避免空值/非法参数)
if (deviceIds.isEmpty || appIds.isEmpty) {
throw new IllegalArgumentException("deviceIds和appIds不能为空!")
}
val filePath = odsFilePath.getString("user_uninstall_path")
val datePrefix = odsFilePrefix.getString("user_uninstall_file_Prefix")
dataToFile(deviceIds, appIds, cnt, filePath, datePrefix)
}
/**
* 将生成的数据加载成文件,文件命名为ODS_USER_INSTALL_20251231.000
* 按照每天数据生成的日期作为文件名一部分
* 每一百条数据为一个文件,文件序号递增,三位数不足前面补0
*
* @param deviceIds 获取到的设备id序列
* @param appIds 获取到的引用id序列
* @param cnt 需要生成的数据条数
* @param filePath hdfs上对应业务的row层目录
* @param filePrefix 需要上传的文件前缀(eg:ODS_USER_INSTALL_20251231)
* @return Seq[String]
*/
private def dataToFile(deviceIds: Seq[String], appIds: Seq[String], cnt: Int, filePath: String, filePrefix: String): Unit = {
val today = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))
val datePrefix = filePrefix + today
//检查目录是否存在
if (hdfsFileWriter.existsHdfsDir(filePath)) {
if (hdfsFileWriter.createHdfsDir(filePath + "/" + today)) { //创建今天的目录,如果存在就不会再次创建了
var currentGroup = ArrayBuffer[List[String]]() // 存储当前分组的100条数据
(1 to cnt).foreach(i => {
val groupNum = (i - 1) / 100
val fileNameSuffix = f"$groupNum%03d" //文件名后缀000-999
val fullFileName = s"${datePrefix}.${fileNameSuffix}"
if (filePrefix == odsFilePrefix.getString("user_install_file_Prefix")) {
currentGroup += List(
deviceIds(Random.nextInt(deviceIds.length)), //随机获取一个设备id
appIds(Random.nextInt(appIds.length)), //随机获取一个应用id
dateRadom.getSpecifiedDayInLastYear(), //数据加载时间,一天前的任意时间,格式: yyyy-MM-dd HH:mm:ss
fullFileName //文件名
)
} else {
currentGroup += List(
deviceIds(Random.nextInt(deviceIds.length)), //随机获取一个设备id
appIds(Random.nextInt(appIds.length)), //随机获取一个应用id
appIds(Random.nextInt(appIds.length)), //随机获取一个应用id,安装数据多一个安装来源渠道
dateRadom.getSpecifiedDayInLastYear(), //数据加载时间,一天前的任意时间,格式: yyyy-MM-dd HH:mm:ss
fullFileName //文件名
)
}
//若当前分组满100条则封组,重置当前分组
if (currentGroup.size == 100 || i == cnt) { // 满100条 或 到最后一条时封组
hdfsFileWriter.writeToCsvFile(currentGroup.toList, fullFileName, "|") //生成文件
currentGroup = ArrayBuffer.empty // 重置当前分组
}
}
)
}
hdfsFileWriter.putBatchFiles(datePrefix, filePath)
}
}
}至此我们项目架构中的数据生产层已经完成
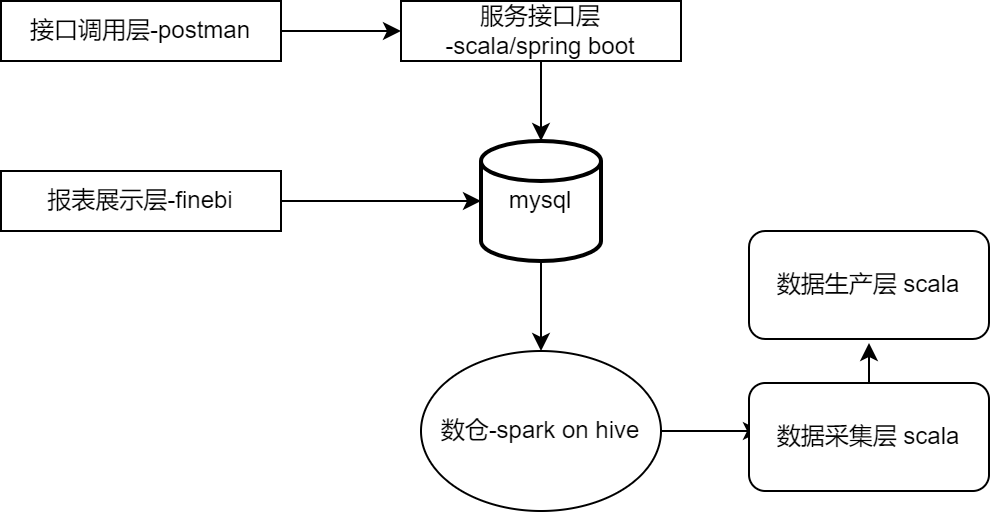
三、功能验证
1、DIM层设备、应用数据验证
通过日志验证
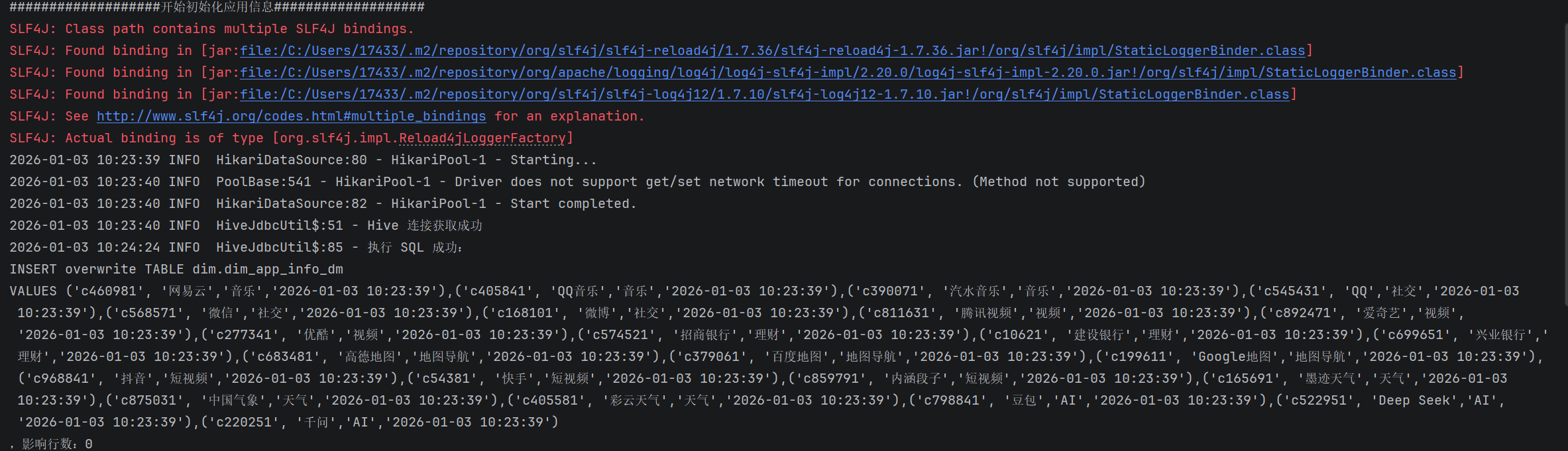
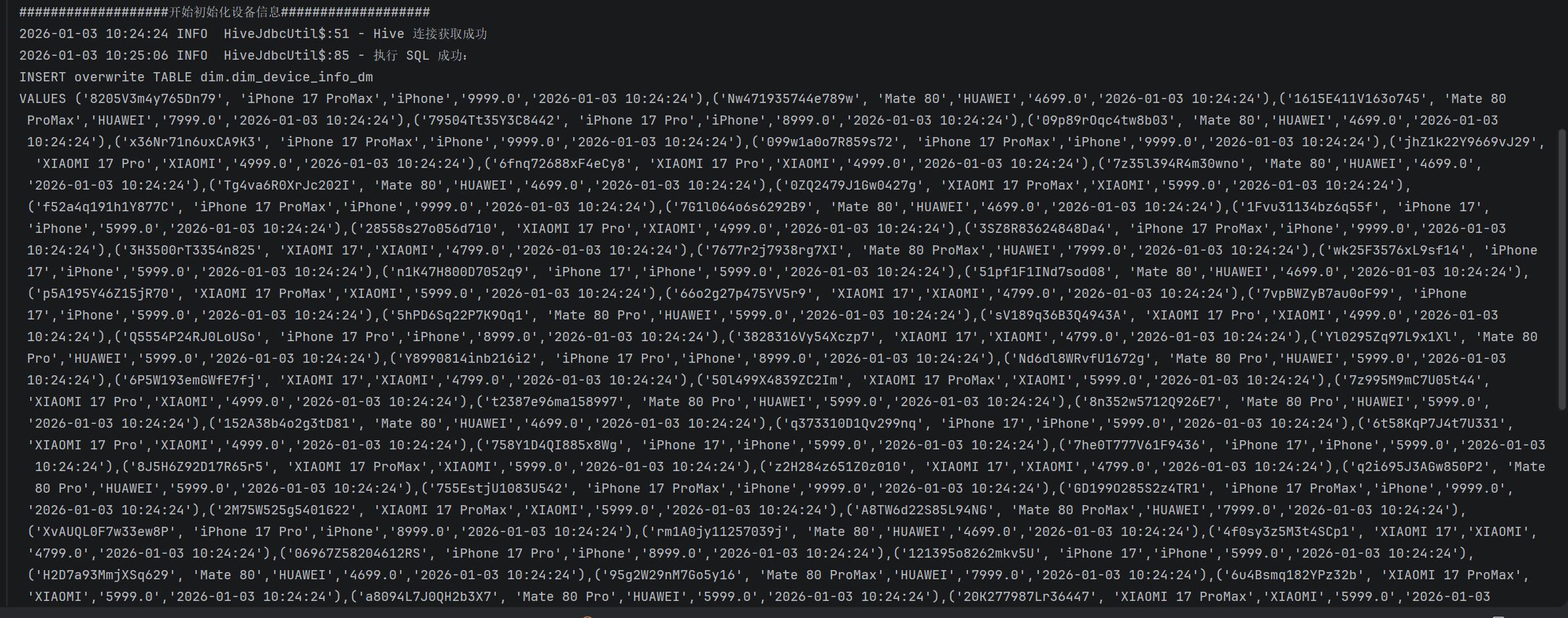
通过结果验证
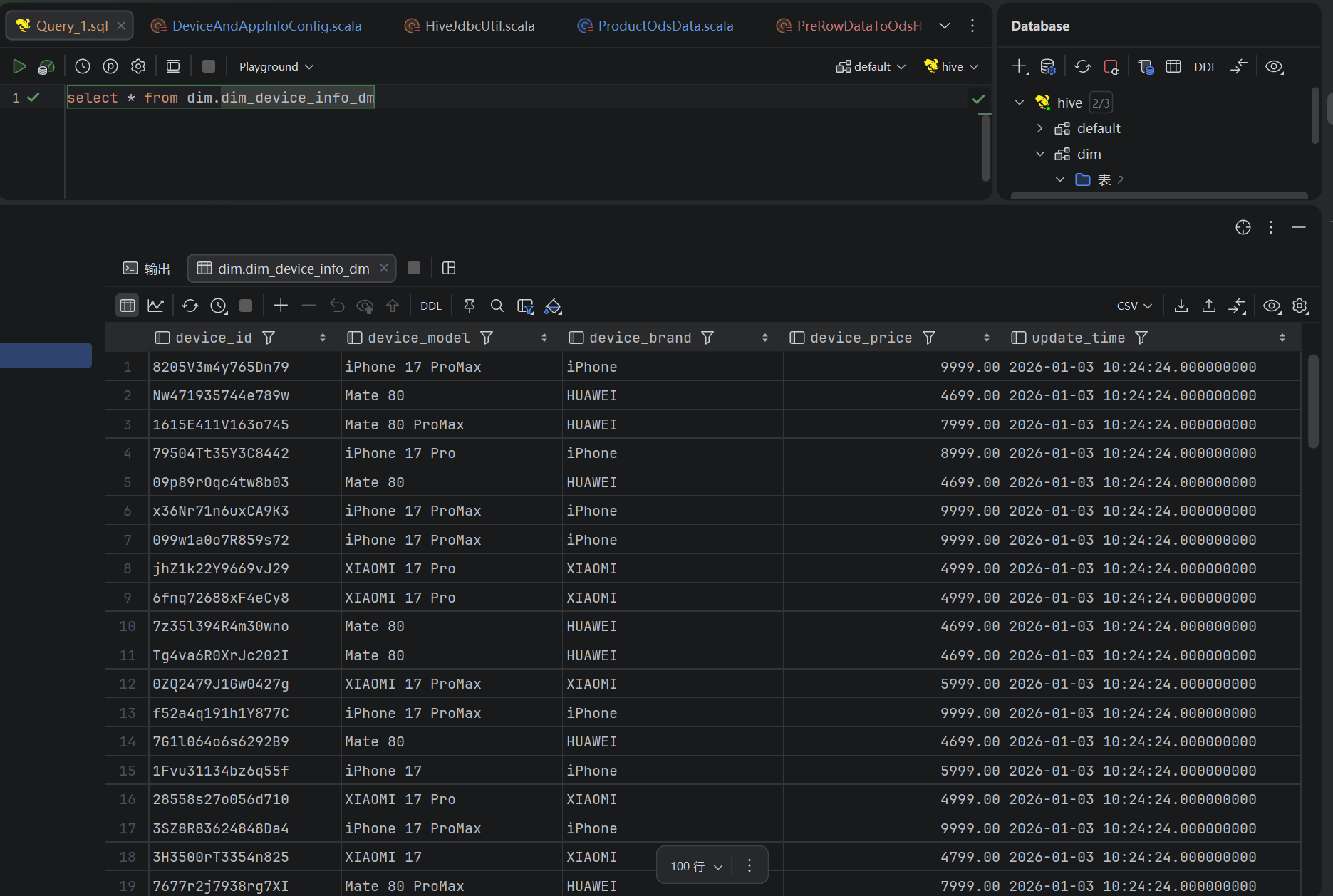
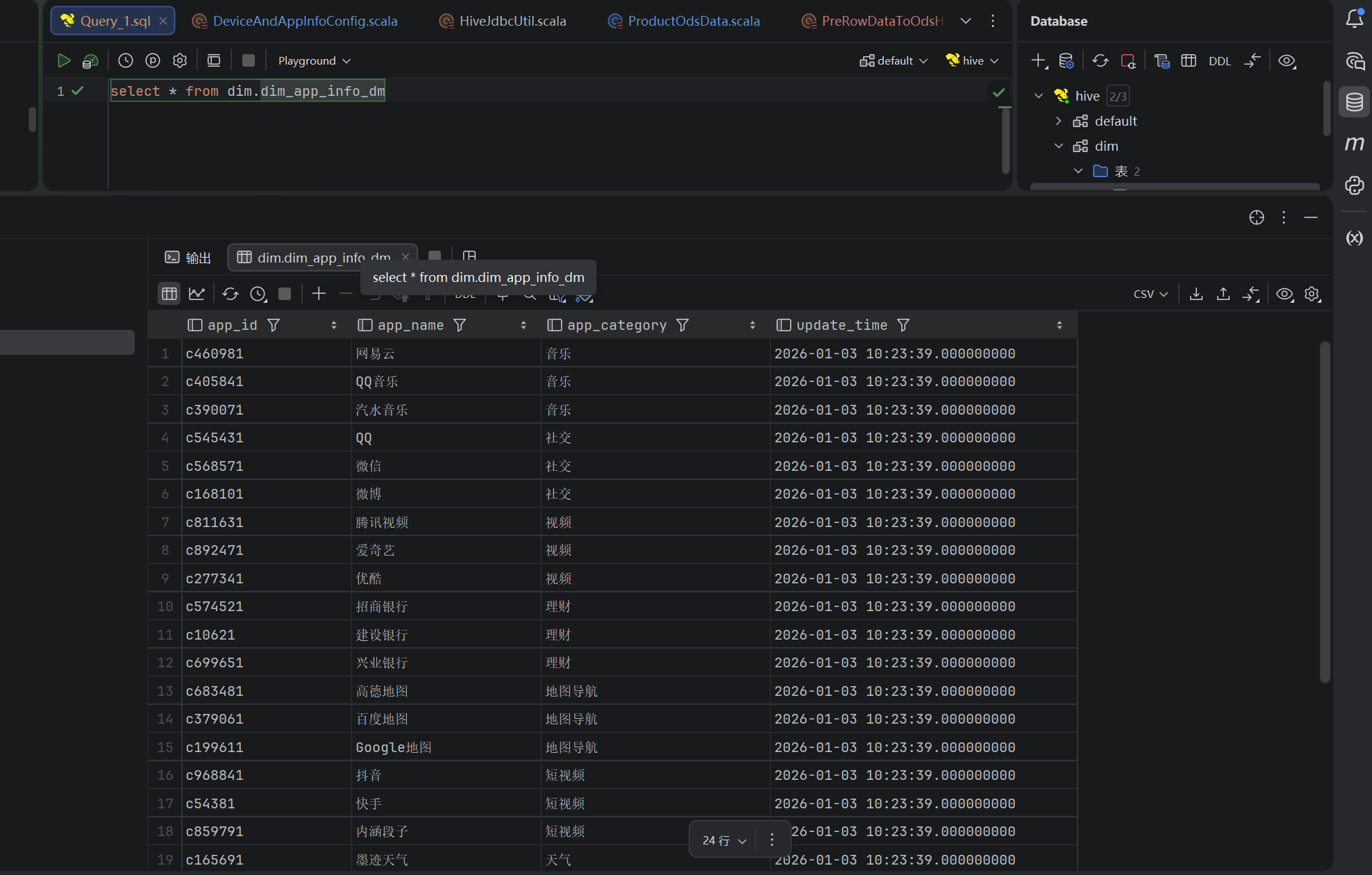
2、用户行为数据验证
报错
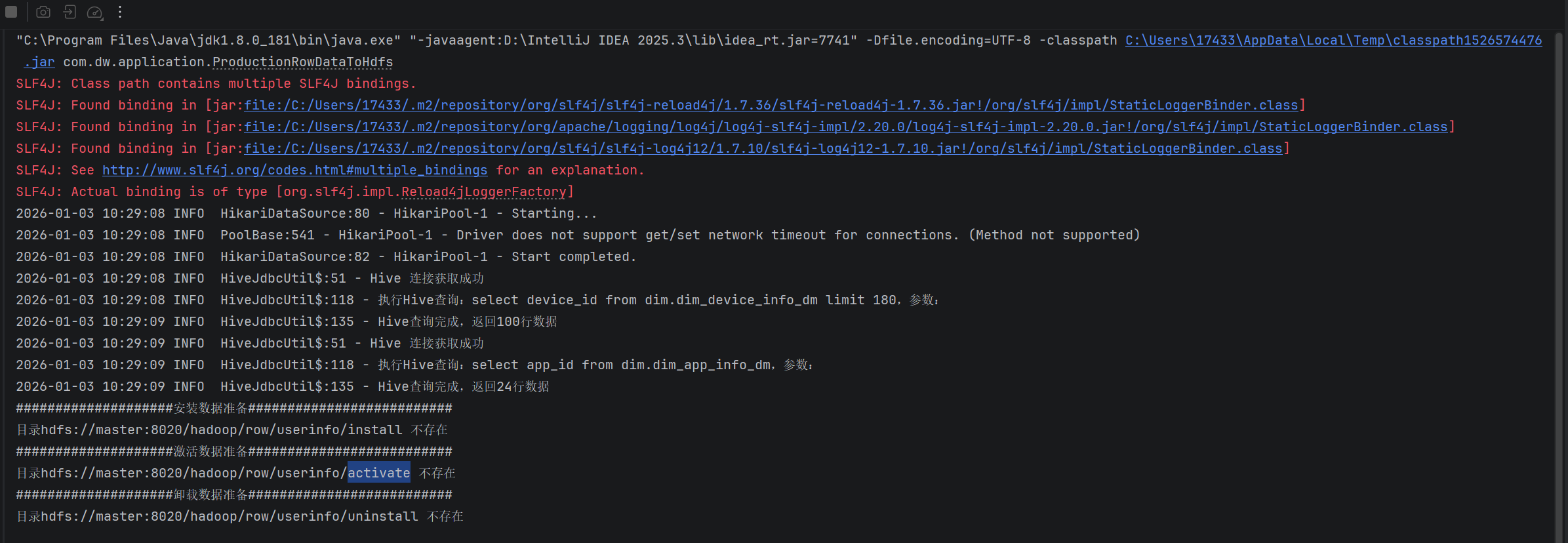
hdfs建目录

通过日志验证
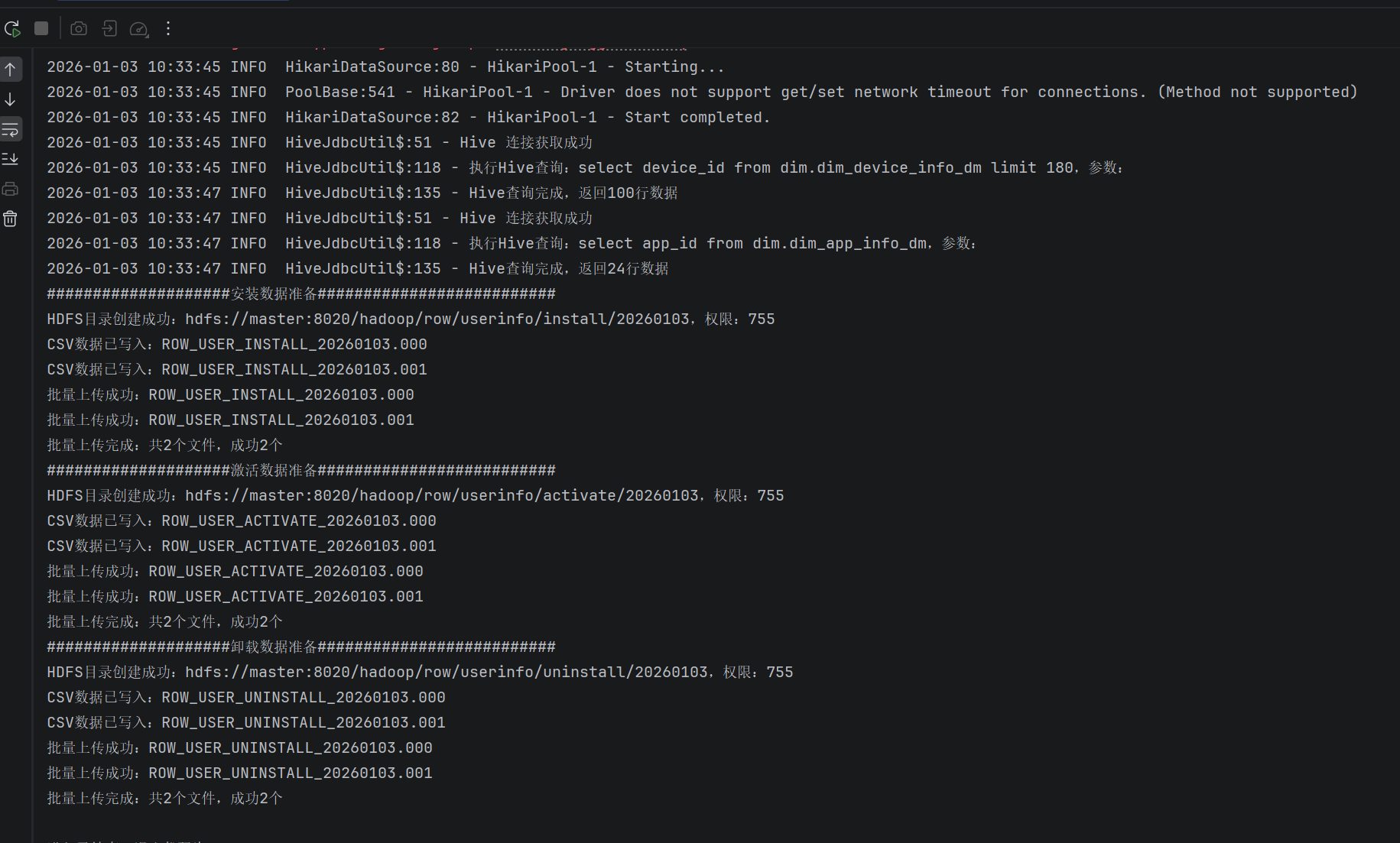
通过结果验证